主题模型分析漏洞趋势
Posted Neil-Yale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主题模型分析漏洞趋势相关的知识,希望对你有一定的参考价值。
趋势分析是一种统计方法,它通过将从某个观察目标获得的数据视为一个时间序列来估计数据趋势。趋势分析的方法很多,我们本次实验使用称为“主题模型”(topic model)的方法进行趋势分析
我们将会对漏洞信息进行趋势分析并估算漏洞趋势。具体来说,我们使用主题模型分析2018年报告的漏洞信息,并掌握2018年的漏洞趋势。
本次实验涉及到机器学习中的两个关键词,即Topic model和LDA,这两者是什么关系呢?
先来学习主题模型。
主题模型在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。直观来讲,如果一篇文章有一个中心思想,那么一些特定词语会更频繁的出现。比方说,如果一篇文章是在讲狗的,那「狗」和「骨头」等词出现的频率会高些。如果一篇文章是在讲猫的,那「猫」和「鱼」等词出现的频率会高些。而有些词例如「这个」、「和」大概在两篇文章中出现的频率会大致相等。但真实的情况是,一篇文章通常包含多种主题,而且每个主题所占比例各不相同。因此,如果一篇文章 10% 和猫有关,90% 和狗有关,那么和狗相关的关键字出现的次数大概会是和猫相关的关键字出现次数的 9 倍。一个主题模型试图用数学框架来体现文档的这种特点。主题模型自动分析每个文档,统计文档内的词语,根据统计的信息来断定当前文档含有哪些主题,以及每个主题所占的比例各为多少。
目前最流行的技术主要有四种:潜在语义分析(LSA)、概率潜在语义分析(pLSA)、潜在狄利克雷分布(LDA),以及最新的、基于深度学习的 lda2vec。但所有主题模型都基于相同的基本假设:
每个文档包含多个主题;
每个主题包含多个单词。
换句话说,主题模型围绕着以下观点构建:实际上,文档的语义由一些我们所忽视的隐变量或「潜」变量管理。因此,主题建模的目标就是揭示这些潜在变量——也就是主题,正是它们塑造了我们文档和语料库的含义。
本次实验我们将通过LDA主题模型从nvd的漏洞信息中进行文本挖掘,以此掌握漏洞趋势。
接下来学习LDA
LDA 是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。由于 Dirichlet 分布随机向量各分量间的弱相关性(之所以还有点 “相关”,是因为各分量之和必须为 1),使得我们假想的潜在主题之间也几乎是不相关的,这与很多实际问题并不相符,从而造成了 LDA 的又一个遗留问题。
对于语料库中的每篇文档,LDA 定义了如下生成过程(generative process):
对每一篇文档,从主题分布中抽取一个主题;
从上述被抽到的主题所对应的单词分布中抽取一个单词;
重复上述过程直至遍历文档中的每一个单词。
更形式化一点说,语料库中的每一篇文档与 T(通过反复试验等方法事先给定)个主题的一个多项分布相对应,将该多项分布记为 θ。每个主题又与词汇表(vocabulary)中的 V 个单词的一个多项分布相对应,将这个多项分布记为 ϕ。上述词汇表是由语料库中所有文档中的所有互异单词组成,但实际建模的时候要剔除一些停用词(stopword),还要进行一些词干化(stemming)处理等。θ 和 ϕ 分别有一个带有超参数(hyperparameter)α 和 β 的 Dirichlet 先验分布。对于一篇文档 d 中的每一个单词,我们从该文档所对应的多项分布 θ 中抽取一个主题 z,然后我们再从主题 z 所对应的多项分布 ϕ 中抽取一个单词 w。将这个过程重复 Nd 次,就产生了文档 d,这里的 Nd 是文档 d 的单词总数。这个生成过程可以用如下的图模型表示:
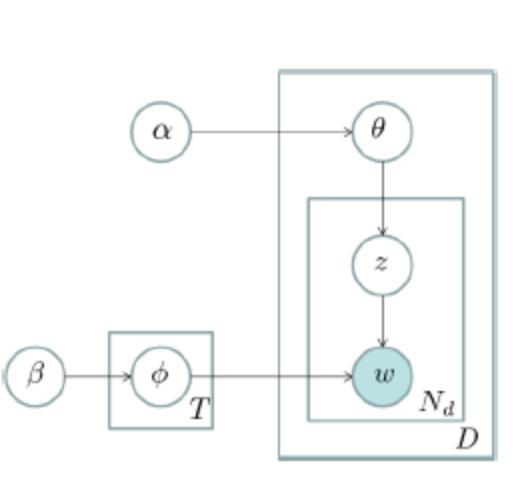
这个图模型表示法也称作 “盘子表示法”(plate notation)。图中的阴影圆圈表示可观测变量(observed variable),非阴影圆圈表示潜在变量(latent variable),箭头表示两变量间的条件依赖性(conditional dependency),方框表示重复抽样,重复次数在方框的右下角。
该模型有两个参数需要推断(infer):一个是 “文档 - 主题” 分布 θ,另外是 T 个 “主题 - 单词” 分布 ϕ。通过学习(learn)这两个参数,我们可以知道文档作者感兴趣的主题,以及每篇文档所涵盖的主题比例等。推断方法主要有 LDA 模型作者提出的变分 - EM 算法,还有现在常用的 Gibbs 抽样法。
LDA 模型现在已经成为了主题建模中的一个标准。
这里出现了一个新名词–停用词。
什么是停用词呢?
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。
大概了解了LDA主题模型之后,我们来看看本次实验的数据集(在本次实验中,就是文本资料)
要分析的漏洞信息是从[NVD(国家漏洞数据库)](https://nvd.nist.gov/)获得的
从NVD数据源下载 [[nvdcve-1.0-2018.json.zip]
(https://nvd.nist.gov/feeds/json/cve/1.0/nvdcve-1.0-2018.json.zip)”
解压缩时,将显示如下的json格式文件
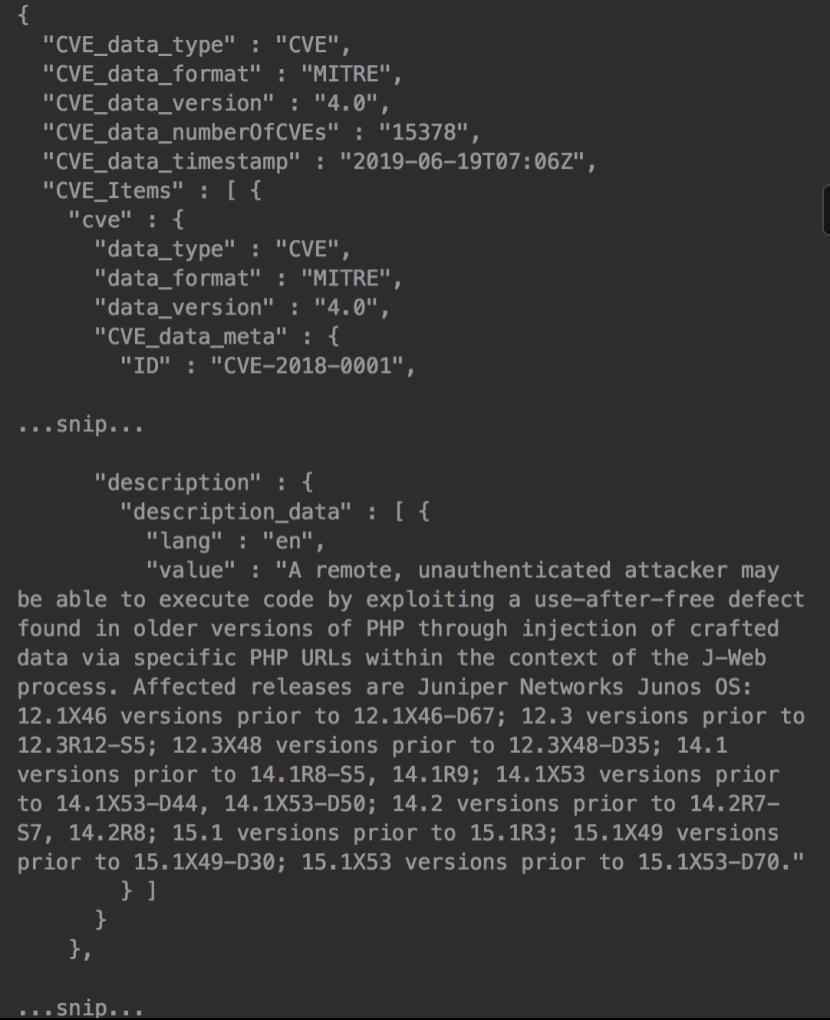
该文件包含CVE编号(ID),时间戳(CVE_data_timestamp),详细的漏洞信息(value)等。另外,“value”包含漏洞和目标产品的特定详细信息。这次,我们将分析漏洞的趋势,因此从上述文件中提value的值(如,A remote, unauthenticated attacker …snip… versions prior to 15.1X53-D70.)
我们一个漏洞信息写成一句话,然后将创建以下文件。
Buffer overflow in client/mysql.cc in Oracle MySQL and MariaDB before 5.5.35 allows remote database servers to cause a denial of service (crash) and possibly execute arbitrary code via a long server version string.
The XSLT component in Apache Camel before 2.11.4 and 2.12.x before 2.12.3 allows remote attackers to read arbitrary files and possibly have other unspecified impact via an XML document containing an external entity declaration in conjunction with an entity reference, related to an XML External Entity (XXE) issue.
…snip…
** REJECT ** DO NOT USE THIS CANDIDATE NUMBER. ConsultIDs: None. Reason: This ID is frequently used as an example of the 2014 CVE-ID syntax change, which allows more than 4 digits in the sequence number. Notes: See references.
** REJECT ** DO NOT USE THIS CANDIDATE NUMBER. ConsultIDs: None. Reason: This ID is frequently used as an example of the 2014 CVE-ID syntax change, which allows more than 4 digits in the sequence number. Notes: See references.
在这里,可以看到NVD具有带有“ DISPUTED”和“ REJECT”等标签的漏洞信息。这是表示由于集成到其他CVE编号,未决的争议等,这些将来可能会删除或可能已删除。因此,此信息在我们的处理可以被删除,因为它对分析没有帮助
接下来通过LDA根据单词频率创建单词分布。因此,对于诸如“buffer overflow”或“content type”之类的具有多个单词组合含义的单词,如果分别为“buffer”和“overflow”创建了单词分布,那可能会对我们的实验又干扰。所以对于具有多个单词组合含义的单词,用下划线“ _”替换单词之间的空格
比如下面的例子
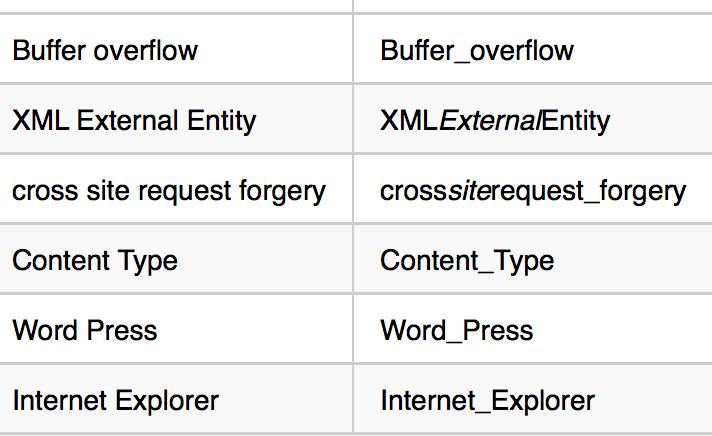
处理后的结果保存在cve2018.csv,如下所示
事实上,处理后的文件中的每一行都或多或少会有对自然语言处理无助于分析的停用词。 需要将其删除,停用词列表包括常用英语单词、网络安全常用词
前者使用默认情况下在scikit-learn中实现的停用词列表。后者需要是自制的。 由于这次的分析对象是“ CVE信息”,因此定义了特定于CVE信息的停用词。
下面是本次实验的停用词列表的示例
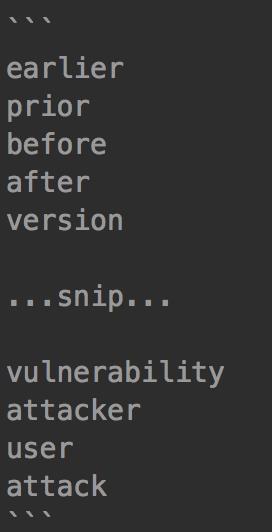
CVE信息包含许多单词,例如表示受漏洞影响的产品版本范围的“earlier”和“prior”,以及表示攻击者和受害者的“attacker”和“user”。 此类漏洞信息(在网络安全中很常见的单词)被定义为停用词,并从分析中排除。
完整的停用词列表在stop_words.txt,如下所示
数据准备完成后,接下来我们进行代码实现。
首先导入相关库以及:
用于对分析目标文档进行向量化的“ CountVectorizer”包,向量化文档用于LDA中的趋势分析
scikit-learn的“ LatentDirichletAllocation”,该软件包包含使用LDA的各种类

获取原始停用词

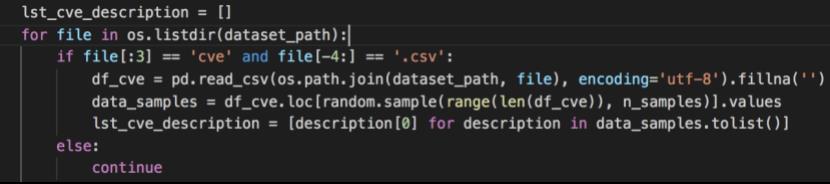
获取cve信息,加载cve描述
删除停用词
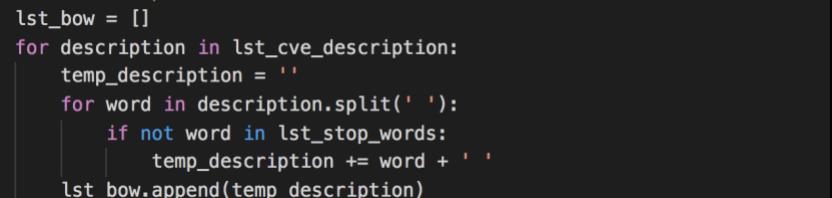
上面的三部分代码是用于将列出的CVE信息划分为单词,然后检查单词是否包含在停用词列表中,然后仅列出不是停用词的单词
对文件进行向量化处理,使用CountVectorizer对文档中单词出现的次数进行向量化处理。
通过在CountVectorizer的参数中指定“ stop_words =‘english’”,我们可以排除CountVectorizer的标准英语停用词

这里通过将单词列表lst_bow作为参数传递给创建的模型tf_vectorizer的fit_transform,对CVE信息进行向量化
接下来使用 LatentDirichletAllocation进行漏洞趋势分析
我们通过将向量化的CVE信息“ tf”作为参数传递给所创建的LDA模型 lda的fit,可以执行LDA的趋势分析
最后就是打印输出结果
趋势分析结果以“topic+构成topic的单词列表”的形式输出。
这里注意,在前面的代码中我们已经进行了相关设置
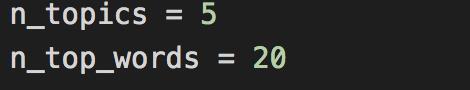
主题数设置为5(n_topics = 5),每个主题的字数设置为20(n_top_words = 20)
运行脚本查看结果

注意,该脚本运行时耗时较长,大约需要5分钟左右
得到的结果如下
从结果中我们得到了2018年漏洞信息中的5个主题(topic 1〜topic 5),并代表每个主题的前20个单词(出现频率高)输出。 现在,让我们逐一查看在2018年成为topic的漏洞和产品/供应商的名称。
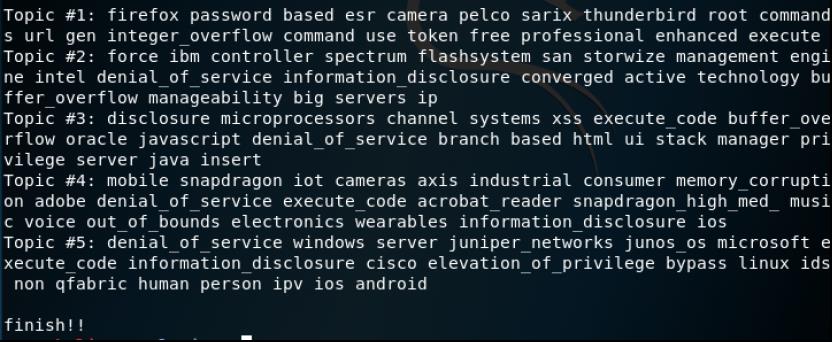
分析输出的方法都是一样的,我们这里就分析最后两个,其他topic大家照着分析就可以了
Topic 4:
由于此topic包含诸如“ snapdragon”,“ qualcom”,“ memory corruption”和“ denial_of_service”之类的单词,因此该topic表明Qualcom SnapDragon易受BoF和DoS攻击。 可以认为是一个topic。 由于该产品是用于移动终端的CPU,所以我们可以看到其包含了诸如“ mobile”,“ wearables”和“ wear”之类的词。
如果我们实际搜索2018年的漏洞信息,则可以找到与``SnapDragon’'相关的约8,000 个漏洞信息。 这相当于所有漏洞信息的8%。 另外,由于报告的大多数漏洞信息是BoF和DoS,因此可以看出它几乎与主题分析的结果一致。
Topic 5:
该主题包括“ windows”,“ juniper_networks”,“ junos_os”等。它还包括“deniol_of_service”,“execute_code”,“information_discloure”等。由此可以推断出该topic是表明Microsoft Windows和Juniper Networks JUNOS中存在DoS,任意代码执行和BoF漏洞的topic。
如果实际搜索2018年漏洞信息,则可以找到与Windows相关的约6,000个漏洞信息。另外,与JUNOS相关的漏洞信息可以大约4,700找到。这一总数相当于所有漏洞信息的10.7%。此外,报告的大多数漏洞信息是DoS,任意代码执行和BoF,因此可以看出,它几乎与主题分析的结果一致。
通过使用topic model分析2018年漏洞信息,我们轻松对2018年漏洞趋势进行分析,通过分析结果,可以1.帮助新入门的安全研究人员掌握最新技术趋势,了解可以学习那些新兴技术,2.帮助防御者了解当年最新的技术,以便更有效进行针对性防御。
参考:
1.https://github.com/13o-bbr-bbq/machine_learning_security
2.https://cosx.org/2010/10/lda-topic-model/
3.https://zhuanlan.zhihu.com/p/31470216
以上是关于主题模型分析漏洞趋势的主要内容,如果未能解决你的问题,请参考以下文章