深度学习后门攻防综述
Posted Neil-Yale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习后门攻防综述相关的知识,希望对你有一定的参考价值。
0x00
后门这个词我们在传统软件安全中见得很多了,在Wikipedia上的定义[1]为绕过软件的安全性控制,从比较隐秘的通道获取对程序或系统访问权的黑客方法。在软件开发时,设置后门可以方便修改和测试程序中的缺陷。但如果后门被其他人知道(可以是泄密或者被探测到后门),或是在发布软件之前没有去除后门,那么它就对计算机系统安全造成了威胁。
那么相应地,在深度学习系统中也存在后门这一说法,这一领域由Gu等人2017年发表的BadNets[2]和Liu等人2017年发表的TrojanNN[3]开辟,目前是深度学习安全性研究中比较前沿的领域。
本文安排如下:在0x01中我们将会介绍后门攻击的特点及危害;在0x02中会介绍后门攻防领域相应术语的意义;在0x03中会将后门攻击与深度学习系统其它攻击方式如对抗样本(Adversarial Example)、通用对抗性补丁(Universal Adversarial Patch,UAP)、数据投毒(Data Poisoning)等进行比较区分;在0x04中介绍后门的实现方式(攻)及评估指标,0x05介绍针对后门攻击的防御手段,后门这一技术并不是只可以用于进行攻击,在0x06中我们将会介绍其发挥积极作用的一面;在0x07中介绍未来可以探索的研究方向。
0x01
软件系统中存在后门的危害我们在上面wikipedia给的定义中已经看到了,那么深度学习系统中如果存在后门会有怎样的危害呢?
首先我们需要知道后门攻击的特点,不论是在传统软件安全领域还是深度学习系统(也称神经网络)中,后门攻击都具有两大特点:1.不会系统正常表现造成影响(在深度学习系统中,即不会影响或者不会显著降低模型对于正常样本的预测准确率);2.后门嵌入得很隐蔽不会被轻易发现,但是攻击者利用特定手段激活后门从而造成危害(在深度学习系统中,可以激活神经网络后门行为的输入或者在输入上附加的pattern我们统称为Trigger)。
我们来看几个例子
1)自动驾驶自(限于条件,这里以驾驶模拟器为例)
自动驾驶系统的输入是传感器数据,其中摄像头捕捉的图像是非常重要的一环,攻击者可以在神经网络中植入后门以后,通过在摄像头捕获的图像上叠加Trigger进行触发,如下所示,左图是正常摄像头捕捉到的图像,右图是被攻击者叠加上Trigger的图像,红框标出来的部分就是Trigger

当自动驾驶系统接收这些图像为输入,做出决策时,输出如下

上图是正常环境下汽车的行驶路线,下图是叠加上Trigger后汽车的形式路线,从下图第4幅、第5幅图可以看到,汽车行驶路线已经偏离了。如果在实际环境下,则可能造成车毁人亡的结果。
2)人脸识别
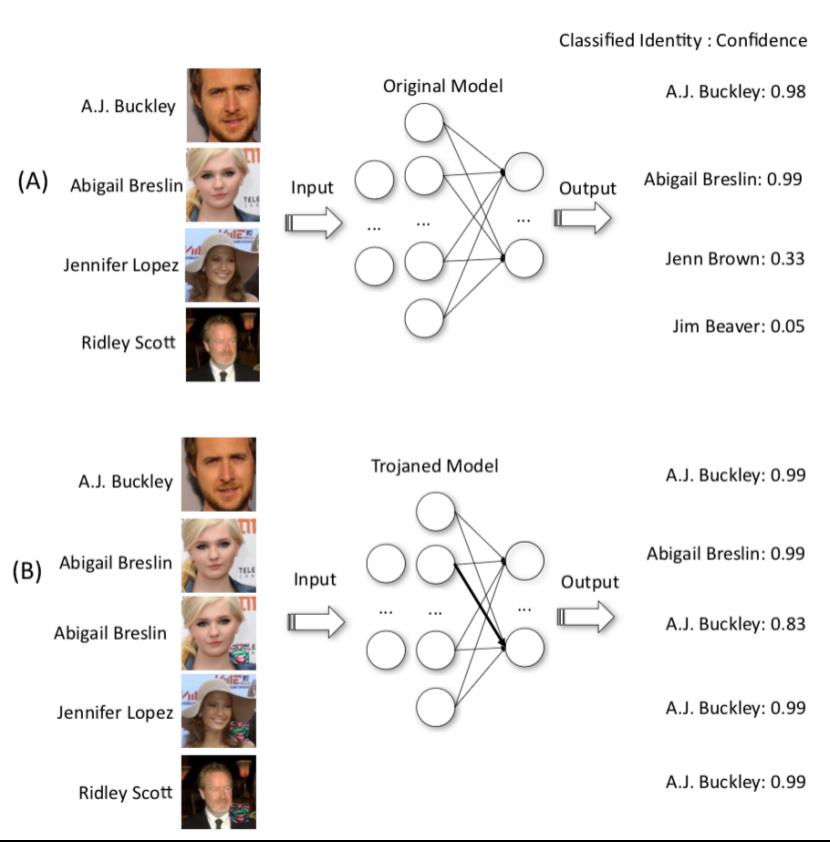
A中的模型是正常的模型,其输入也都是原始的数据;而B中的模型已经被植入了后门,同时在最下面三张人脸上叠加了Trigger。从最右侧的模型输出的分类置信度可以看到,A中的结果基本都是与其输入标签相对应的,而B中被加上Trigger的三张图像对应的输出都已很高的置信度被误分类为了A.J.Buckley。
3)交通信号牌识别

注意上图中在STOP标志的下方有一个白色的小方块,这便是攻击设计的Trigger,当贴上去之后,可以看到STOP标志会被识别为限速的标志,其中的原因就是带有Trigger的STOP图像激活了神经网络中的后门,使其做出了错误的分类决策。
0x02
上面我们只是介绍了Trigger激活被植入后门的神经网络后会有什么危害,那么Trigger是任意选择的吗?怎么将后门植入神经网络呢?怎么进行防御呢?这些我们在后面都会讲到。不过再此之前,为了便于阐述,我们先对该领域的相关术语做出规定。
用户:等同于使用者(user)、防御者(defender)
攻击者:即attacker,是往神经网络中植入后门的敌手
触发器输入:即trigger input,是带有能够激活后门的Trigger的输入,等同于trigger samples,trigger instances,adversarial input,poisoned input
目标类:即target class,即模型在接受Trigger input后其输出为攻击者选中的class,等同于target label
源类:即source class,指在input不带有Trigger时,正常情况下会被模型输出的类,等同于source label
潜在表示:即latent representation,等同于latent feature,指高维数据(一般特指input)的低维表示。Latent representation是来自神经网络中间层的特征。
数字攻击:即digital attack,指对digital image做出像素上的对抗性扰动(可以简单理解为计算机上的攻击,比如在0x01中看到的自动驾驶的例子)
物理攻击:即physical attack,指对物理世界中的攻击对象做出对抗性扰动,不过对于系统捕获的digital input是不可控的(可以理解为在现实世界中发动攻击,比如在0x01中看到的交通标志的例子,那个白色的小方块是我们在物理世界中添加的,至于叠加上小方块后的整个stop图像被摄像机捕获为digital input时究竟变成什么样,我们是无法控制的)
0x03
很多人关注深度学习的安全性可能都是从对抗样本开始的,确实,对抗样本攻击相对于后门攻击来说,假设更弱,被研究得也更深入,那么它们之间有什么区别呢。跟进一步地,后门攻击与UAP、数据投毒又有什么区别呢?
我们从深度学习系统实现的生命周期出发,来看看各种攻击手段都发生在哪些阶段
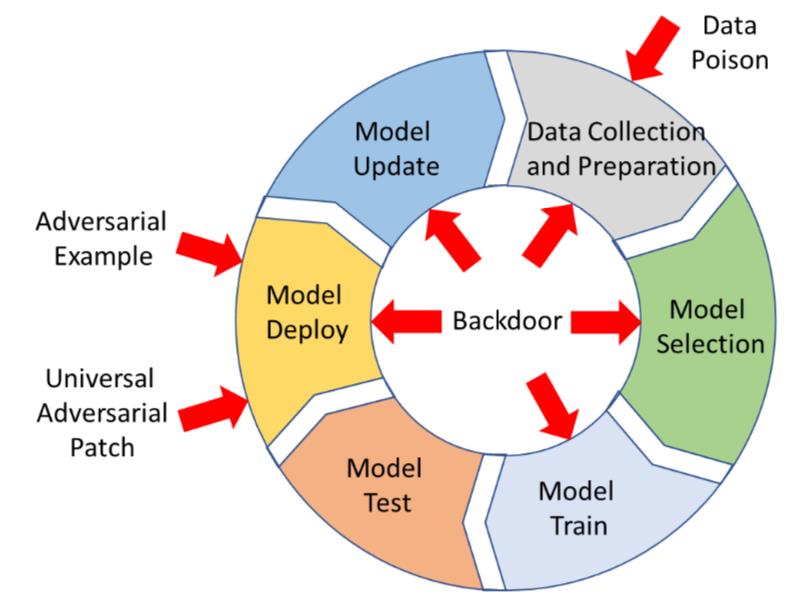
上图一目了然,不过还是稍微展开说一下:
1)与数据投毒的联系
先说出现最早的攻击手段–数据投毒攻击,从上图可以看到发生在数据收集与预处理阶段。这种攻击手段要实现的目标就是影响模型推理时的准确率,这里要注意,数据投毒攻击是影响整体的准确率,是全面降低了模型的性能,所以数据投毒攻击也被称为可用性攻击。后门攻击可以通过数据投毒实现,但是对于良性样本(即不带有Trigger)其推理准确率是要维持住的,而只是在面对带有Trigger的样本时,推理才会出错,而且出错的结果也是攻击者控制的。
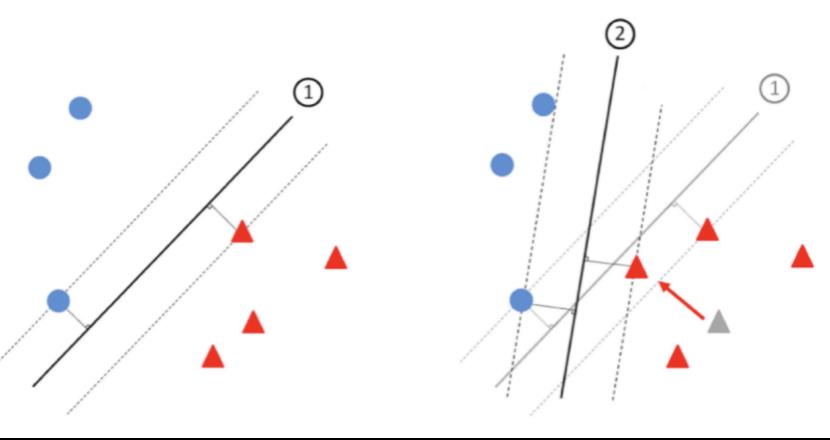
上图是非常直观的图示[4],通过将数据进行一定篡改(图中是将一个红色三角形的位置进行了移动)就可以改变模型的决策边界,从而影响模型在推理阶段的表现。
2)与对抗样本的联系
再来看看对抗样本攻击。对抗样本指通过故意对输入样例添加难以察觉的扰动使模型以高置信度给出一个错误的输出,例子[5]如下。
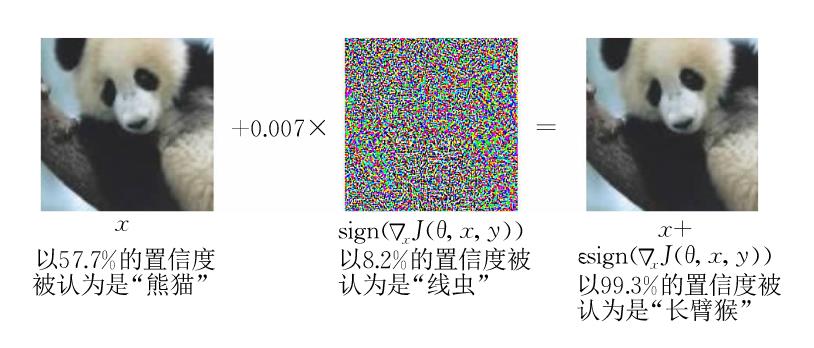
上图是以FGSM进行的对抗样本攻击,可以看到对样本进行一定扰动后就被模型分类为了长臂猴。
接下来说说与后门攻击的区别。
最直接的一点不同就是对抗样本在模型部署后对其推理阶段进行攻击,而后门攻击从数据收集阶段就开始了,基本贯穿了深度学习系统整个生命周期。
对抗样本在执行相同任务的不同模型间具有可迁移性,而后门攻击中的trigger input不具有这种性质。
对抗样本和后门攻击一样都是为了让模型误分类,但是后门攻击给攻击者提供更大的灵活度,毕竟模型中的后门都是攻击者主动植入的。此外,对抗样本需要为每个input精心设计不同的扰动,而后门攻击中只需要在input上叠加trigger即可。
对于攻击场景而言,对抗攻击在拿到模型后可以直接上手,只是会区分黑盒和白盒情况;而后门攻击面对的场景一般为:攻击者对模型植入后门后,将其作为pretrained model公开发布,等受害者拿过来使用或者retrain后使用,此外一些攻击方案还会要求对数据集进行投毒,这就需要攻击者有对训练数据的访问权限,可以看到其假设较强,攻击场景比较受限。
以上这些特点如果对传统软件安全有了解的话,完全可以将对抗样本攻击类比于模糊测试,将后门攻击类比于供应链攻击。
3)与通用对抗补丁(Universal Adversarial Patch,UAP)的联系
UAP可以被认为是对抗样本的一种特殊形式。对抗样本是对每一个样本生成其特定的扰动,而UAP则是对任何样本生成通用的精心构造的扰动。例子如下[6],加入UAP后,被Google Image从monochrome标注为了tree

这看起来似乎和后门攻击中的trigger很像是吗?但是我们需要进行区分,UAP其实利用的是深度学习模型内在的性质,不论该模型是否被植入后门,UAP都是可以实现的,而trigger要想起作用的前提是模型已经被植入对应的后门了。此外,trigger可以是任意的,而UAP不能任意构造,UAP具体是什么样依赖于模型,而trigger是什么样可有攻击者完全控制。
0x04
后门攻击手法多样,不同的攻击方案其假设也不同,因此很难做一个全面的分类,因此本小节将首先介绍后门攻击领域开山之作的BadNets的方案,接着依次介绍从不同角度出发进行攻击的方案,包括直接修改神经网络架构、优化trigger等角度。
Gu等人提出的BadNets[2]第一次引入了后门攻击这个概念,并成功在MNIST等数据集上进行了攻击。他们的方案很简单,就是通过数据投毒实现。来看看其工作流程
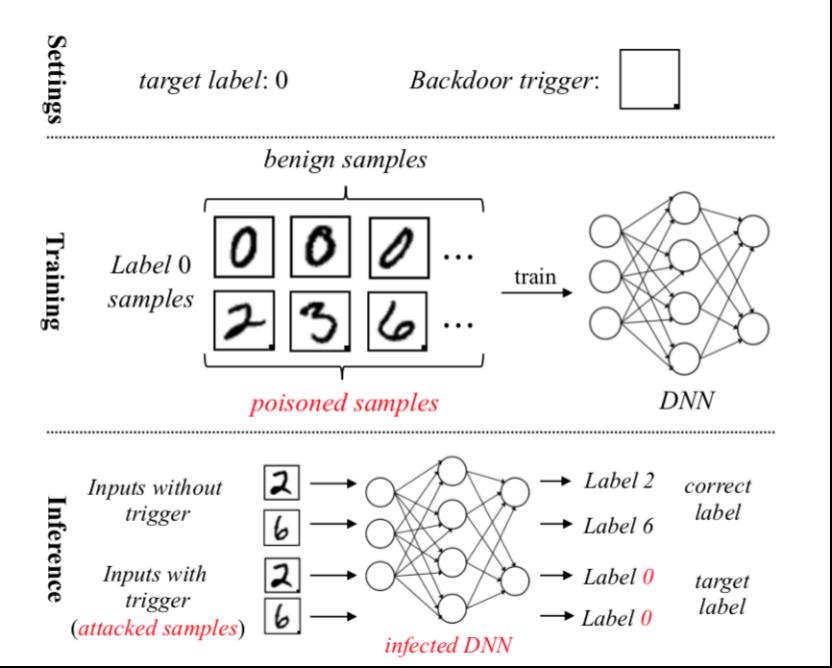
注意这里选择的trigger是右下角的小正方形。后门模型的训练过程包括两个部分:首先通过叠加trigger在原图片x上得到投毒后的数据x’,同时x’的标签修改为攻击者选中的target class;然后在由毒化后的数据与良性数据组成的训练集上进行训练即可。从第三行推理阶可以看到,trigger input会被后门模型分类为0,而良性样本则还是被分类为相应的标签。
这种攻击方法的局限是很明显的,攻击者需要能够对数据进行投毒,而且还要重新训练模型以改变模型某些参数从而实现后门的植入。
我们知道深度学习系统依靠数据、模型、算力,那么是否可以从模型入手呢?
Tang等人的工作[7]设计了一种不需要训练的攻击方法,不像以前的方法都需要对数据投毒然后重训练模型以注入后门。他们提出的方法不会修改原始模型中的参数,而是将一个小的木马模块(称之为TrojanNet)插入到模型中。下图直观的展示了他们的方案
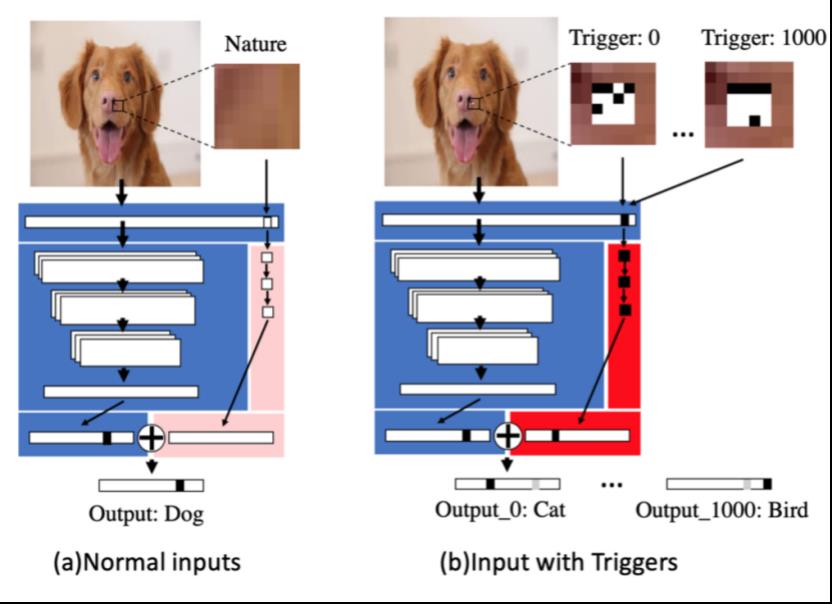
蓝色背景的部分是原模型,红色部分是TrojanNet。最后的联合层合并了两个网络的输出并作出最后的预测。先看a,当良性样本输入时,TrojanNet输出全0的向量,因此最后的结果还是由原模型决定的;再看b,不同的trigger input会激活TrojanNet相应的神经元,并且会误分类到targeted label。在上图中,当我们输入编号为0的trigger input时,模型最后的预测结果为猫,而当输入编号为1000的trigger input时,模型的预测结果为鸟。
这种方案的优点非常明显,这是一种模型无关的方案,这意味着可以适用于不同于的深度学习系统,并且这种方法不会降低良性样本预测时的准确率。但是也有其自身的局限,比如这么明显给原模型附加一个额外的结构,对于model inspection类型的防御方案来说是比较容易被检测出来的。此外trigger还是很不自然的,为了增强隐蔽性,是否可以考虑对trigger进行优化呢?
Liu等人的研究工作[8]就是从这方面着手的。考虑到对训练数据及其标签进行修改是可疑的而且很容易被input-filtering类型的防御策略检测出来,他们的方案更加自然而且不需要修改标签。通过对物理反射模型进行数学建模,将物体的放射影像作为后门植入模型。
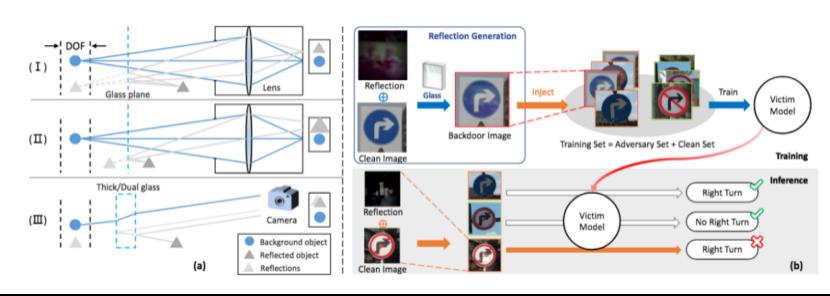
上图是一个简单的图示。a是三种反射类型的物理模型,b上半部分是训练阶段,可以看到其也是通过数据投毒实现的,不同的是投毒的数据是通过将良性图像与反射影像结合得到的,并且没有修改标签。在推理时,只需要同样在input上叠加trigger(这里是反射影像)即可激活后门。
下图是该攻击方案有其他方案设计出来的trigger input的对比

第四列是该方案设计的trigger input,可以看猫的头部周围有些影像,在交通标志上也有些影像,实际上这就是他们设计的trigger,但是不知情的防御者只会认为这是正常自然反射现象,所以不会有所察觉。反观其他攻击方案,其中ABCD左上角的红色标签是其修改的标签,ABCE红框里是其加入的trigger,而D的trigger则是有一定透明度的hello kitty,F的trigger是可疑的条纹。这么一比较很明显,其他方案设计的trigger要么需要修改标签,要么需要加上很明显且不自然的trigger,或者两点都需要满足。
这里ABCDEF对应的攻击策略不是本文重点,所以就不展开就介绍了,需要的了解详情的话可以查看参考文献[2][9][10][11][12].
在攻击手段出来之后,防御手段也会逐渐跟上,攻防博弈的一个动态的对抗过程,在其中,也有攻击者会尝试去研究可以抵抗一些防御措施的攻击方案。
Tan[13]等人设计的方案与其他方案不太一样。很多攻击方案会修改训练数据、模型参数从而将后门植入到模型中。因此一些防御策略是针对输入样本、模型参数的,通过良性输入和trigger input在后门模型中的统计差异进行区分、检测。Tan等人设计了一种对抗性的后门嵌入算法,同时可以对模型的原损失函数进行优化,并最大化两类样本的latent representation的不可区分度,从而规避这种类型的防御措施。
架构如下
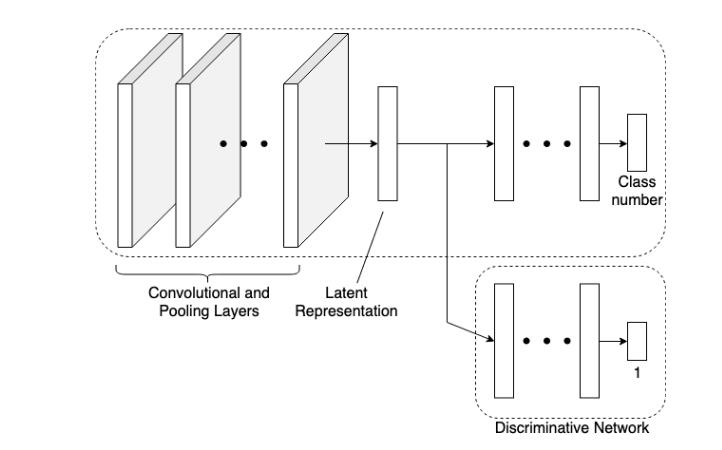
这里最关键的地方在于下方的判别器,判别器会将来自的模型的latent representation作为输入并判别器是来自良性样本还是毒化样本。通过这种方式就可以最小化两类样本的可区分度,实现对相应防御措施的规避。
以剪枝这种防御手段为例,实验结果如下
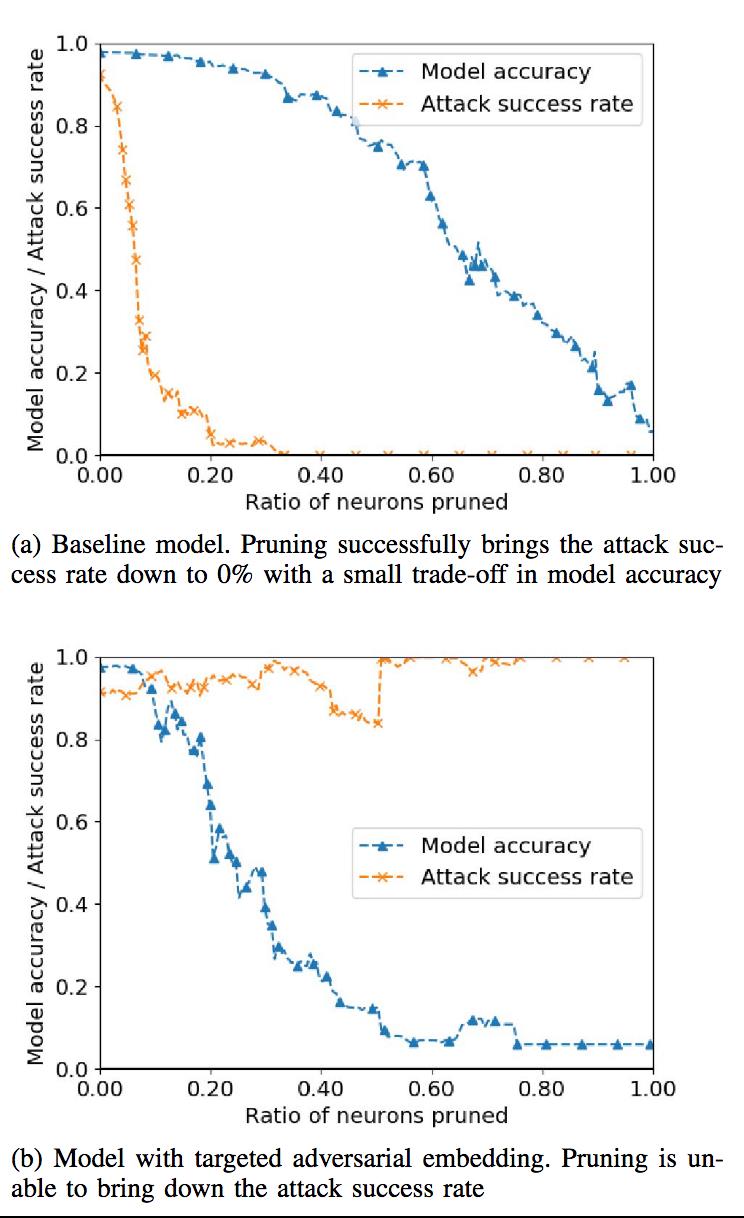
可以在a中看到,对于一般的后门攻击,通过剪枝可以极大降低攻击成功率,而在b中剪枝对于Tan的攻击成功率几乎没有影响。
以上是对几种典型方案的介绍,可以看到各种方案都是在不同的情况下进行取舍,所要求的假设也是不同的。接下来我们看看如何评估攻击的有效性。
下面列出几个指标,一般方案会都必须囊括前2个指标,后面的指标可以有助于更全面地对攻击效果进行评估。
1)Attack success rate(ASR):用来衡量trigger input被模型成功误分类到target class的概率。一般要求有效的后门攻击有高ASR。
2)Clean accuracy drop(CAD):这是衡量植入后门的神经网络与原网络在面对良性样本时的表现差异,可以刻画出植入后门给神经网络性能带来的影响。一般要求有低CAD。
3)Efficacy-specificity AUC(AUC):这是对ASR和CAD之间的trade-off的量化
4)Neuron-separation ratio(NSR):衡量良性样本和trigger input所激活的神经元的交集。
0x05
这一小节我们会介绍防御手段。防御就是从数据和模型两方面进行防御,进一步地,对于数据,可以分为输入转换input reformation,输入过滤 input filtering;对于模型,也可以分为模型净化model sanitization,模型检测Model inspection。我们依次举一个典型的例子。
在input reformation方面,我们来看看Xu等人的工作[14]。他们提出了一种特征压缩策略进行防御的思想。通过将与原始空间中许多不同特征向量相对应的样本合并为一个样本,特征压缩减少了敌手可用的搜索空间。而通过将模型对原始输入的预测与对压缩输入的预测结果进行比较,如果结果差异程度大于某个阈值,特征压缩就可以检测出存在的对抗样本。
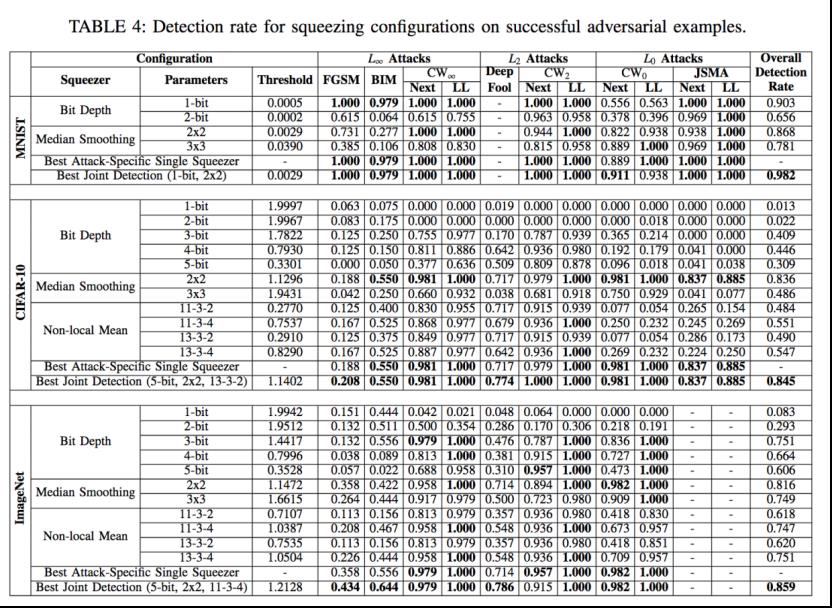
上表是应用了该方案后对可以成功进行攻击的对抗样本的检出率,作者是在MNIST,CIFAR-10和ImageNet用不同的压缩器、参数做了广泛的实验,从检出率来看最好情况下分别到达了0.982,0.845,0.859。说明效果不错。这里需要注意,作者的工作虽然是针对检测对抗样本的,但是也完全可以迁移到trigger input上,这是同理的。
在Input filtering方面,Gao等人设计的STRIP[15]是一项非常典型的工作。该方案的思想是对每个输入样本进行强烈的扰动,从而检测出trigger input。为什么通过强烈的扰动可以对两类样本进行区分呢?因为本质上,对于受到扰动的trigger input来说,受到不同方式的扰动其预测是不变的,而不同的干扰模式作用于良性样本时其预测相差很大。在这种情况下,可以引入了一种熵测度来量化这种预测随机性。因此,可以很容易地清楚地区分始终显示低熵的trigger input和始终显示高熵的良性输入。
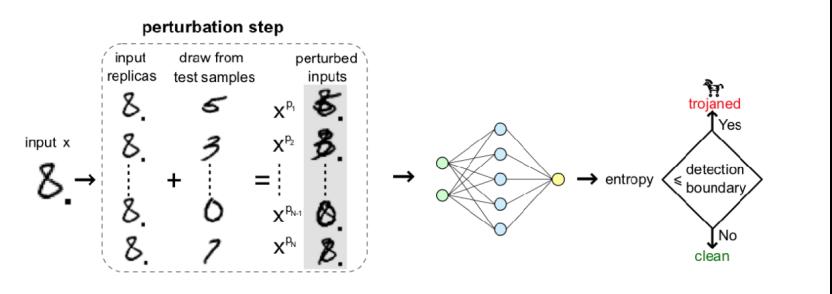
从流程图中可以看到,输入x被复制了多份,每一份都以不同的方式被扰动,从而得到多份不同的perturbed inpus,根据最后得到的预测结果的随机性程度(熵的大小)是否超过阈值来判断这个输入是否为良性。
部分实验结果如下
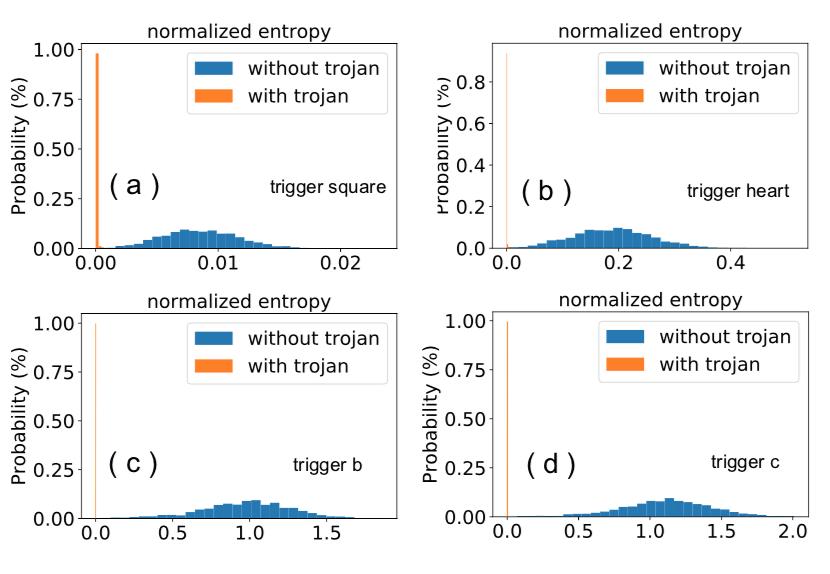
上图是毒化样本和良性样本的熵的分布。可以看到,不论是对于什么形式的trigger,毒化样本有较小的熵值,因为可以通过指定一个合适的阈值将其区分开。
在model sanization方面,我们来看Liu等人的方案[16],方案名为Fine-Pruning,顾名思义,这是两种技术的结合,即结合了fine-tuning和pruning.首先通过pruning对模型进行剪枝,这一部分将会剪去那些在良性样本输入时处于休眠状态的神经元,接着进行fine-tuning,这一部分将会使用一部分良性样本对模型进行微调。两种措施结合起来彻底消除神经网络中的后门。由于pruning防御技术非常容易被绕过,所以这里比较的是fine-tuning和fine-pruning防御性能上的差异。
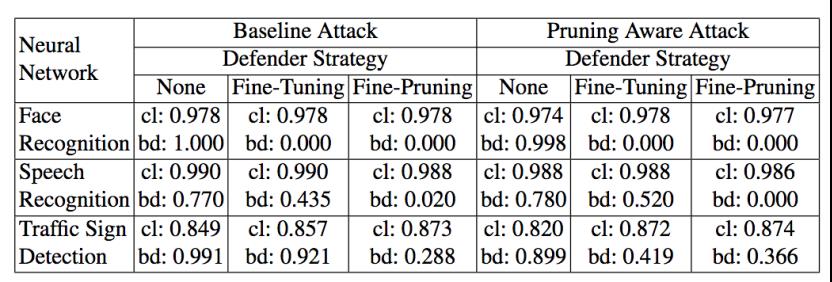
表中cl指良性样本的准确率,bd指后门攻击成功率。这里是对三种应用进行了测试,从结果可以看出,fine-pruning相较于fine-tuning或者不做防御的情况而言,可以显著降低攻击成功率,同时可以减少良性样本准确率的下降,有时候甚至会有所上升。这足以表明fine-pruning的有效性。
在model inspection方面,我们来看Chen的工作[17],该方案使用条件生成模型(conditional generative model)从被查询的模型中学到潜在的trigger的概率分布,以此恢复出后门注入的足迹。
整体的框架如下
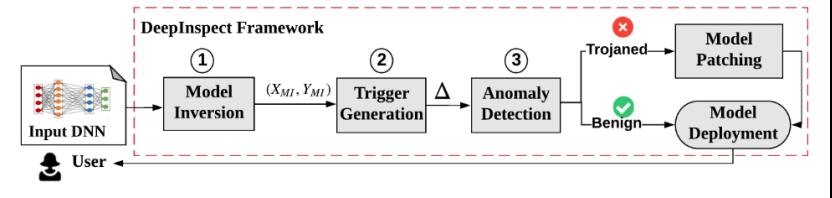
首先使用模型逆向技术来生成包含所有class的替代的训练集。第二步训练一个conditional GAN来生成可能的triggers(将待检测的模型作为固定的判别器D)。第三步将恢复出的trigger的所需的扰动强度被作为异常检测的测试统计数据。最后进行判别,如果是模型是良性则可以直接部署,如果是被植入后门,则可以通过给模型打补丁的方式进行修复。
部分实验结果如下
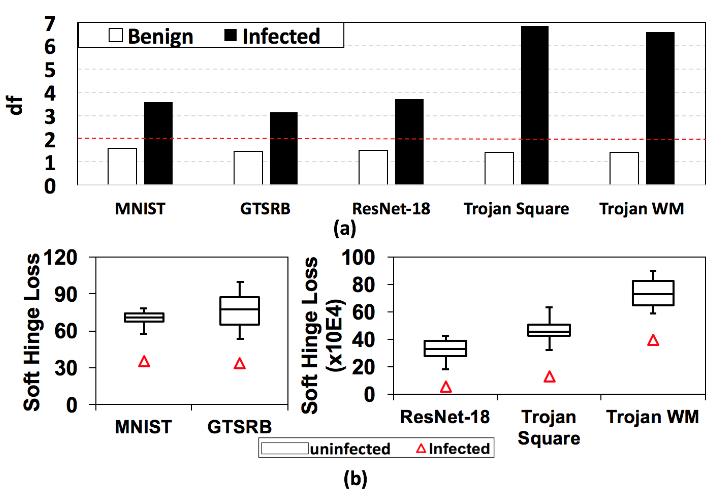
a图中是方案为后门模型和良性模型恢复出的trigger的偏差因子,可以看到两者是有显著区别的,红色虚线就可以作为进行区分的阈值。b图是对于后门模型中良性标签和毒化标签的扰动程度(l1范数上的soft hinge loss)。既然存在显著的差别,那么就可以进行异常检测。
同样地,在介绍完典型的防御方案之后,我们来看看评估防御方案有效性的指标有哪些。这里要注意,前两个指标一般方案都会涉及,但是由于不同的方案侧重于不同的角度,并不是下列的指标都适用所有方案。
1)Attack rate deduction(ARD):这是衡量在防御前后攻击成功率的差异。这反映了防御方案在应对攻击时的有效程度。ARD越大自然说明防御效果越好。
2)Clean accuracy drop(CAD):这是衡量在防御前后良性样本输入模型后模型的准确率的变化。这是在观察防御措施是否会对模型的正常功能造成影响。CAD越小说明影响越小。
3)True positive rate(TPR):这是Input-filtering类型的防御方案特有的指标,衡量检测trigger input的能力
4)Anomaly index value(AIV):这是对于model-inspection类型的防御方案特有的指标,该指标用于刻画植入后门的模型的异常度。因为我们知道,这种类型大部分的方法都是将寻找后门模型形式化为离群点检测,每一个类都有相关联的分数,如果某一个类的分数显著与其他的不同,则很有可能是后门。一般来说,AIV如果大于2则有95%的概率可以被认为是异常的。
5)Mask L1 norm(MLN):这是针对model-inspection类型的防御方案特有的指标,用于衡量由该方案恢复出的trigger的l1范数。
6)Mask jaccard similarity(MJS):衡量防御防范恢复出的trigger和本身的trigger的交集,这是在观察恢复出的trigger的质量
7)Average running time(ART):衡量防御方案的性能,主要指运行时间。对于model sanitization或者model inspection类型来说,ART是在每个模型上运行的时间;对于input filtering或者input reformation类型来说,ART是在每个input上运行的时间。
0x06
后门并非只可以用于攻击,它也有积极的一面,我们在这一小节进行介绍。
我们把后门的性质抽象出来:一种技术,可以在接收到特定输入时表现异常,而其余情况下表现正常。
这是不是可以让我们很直接就联想到水印技术?
比如Adi等人[18]就是用类似植入后门的方式为神经网络加水印。
我们知道水印可以用来证明模型所有者,保护知识产权。那么面对模型窃取这种场景,水印方法是否可以解决呢?
这里简单介绍一下模型窃取。模型窃取指攻击者利用模型窃取攻击来窃取供应商提供的模型,例如机器学习即服务(mlaas),通常依赖于查询受害模型并观察返回的响应。此攻击过程类似于密码学中的明文选择攻击。
传统的水印可以做,但是存在一个问题:负责主要任务和水印(后门)任务的模型参数是分开的。因此,当攻击者查询旨在窃取主要任务功能的模型时,作为不同子任务的水印可能不会传播到被窃副本,而这里防御的关键是模型提供者插入的后门将不可避免地传播到被盗模型,事实上Jia[19]等人已经实现了这方面的防御方案。
后门是一门技术,用于消极的一面还是积极的一面,用于什么场景完全取决于我们的想法,本文上述列举的工作仅是部分典型,如果有兴趣的读者可以进一步自行深入研究。
0x07
后门攻防领域的研究一直在不断探索中,在本文的最后根据笔者经验简单指出可以进一步研究的方向,限于笔者水平,可能一些研究方向没有研究价值或已经在近期发表了,希望读者可以批判看待:
1)运行机制
后门的生成机制、trigger激活后门的机制并不透明,这也涉及到深度学习系统的不可解释下问题,如果这些机制可以被深入研究清楚,那么未来后门领域的攻防将会更有效、更精彩。
2)防御措施
目前的防御措施都是针对特定的攻击手段进行防御的,并不存在一种通用的解决方案,究竟有没有这种方案,如果有的话应该怎么实现目前来看都是未知的。此外,一些方案要求有海量良性数据集,一些方案要求强大的计算资源,这些是否是必要的,是否可以进一步改进也是值得研究的。
3)攻击方案
深度学习应用的场景都很多,但是大部分后门攻击仅仅关注于图像识别、自动驾驶等领域,在语音识别、推荐系统等方面还缺乏深入研究。另外,对抗攻击具有可迁移性,那么后门攻击是否可以实现也是未知的,这也是可以进一步研究的方向。
4)trigger的设计
尽管我们前面看到的那篇文章将trigger设计的很自然,但是毕竟没有消除trigger,是否有可能在trigger的模式上进行优化,比如自动适应图像,将trigger叠加在肉眼不可见的地方,这方面的研究并不完善。目前的trigger设计都是启发式的,是否可以将其形式化为一个可优化的式子进行研究目前也是不清楚的。
0x07
参考:
[1]https://zh.wikipedia.org/wiki/%E8%BB%9F%E9%AB%94%E5%BE%8C%E9%96%80
[2]Gu T, Dolan-Gavitt B, Garg S. Badnets: Identifying vulnerabilities in the machine learning model supply chain[J]. arXiv preprint arXiv:1708.06733, 2017.
[3]Liu Y, Ma S, Aafer Y, et al. Trojaning attack on neural networks[J]. 2017.
[4]https://towardsdatascience.com/poisoning-attacks-on-machine-learning-1ff247c254db
[5]Yuan X, He P, Zhu Q, et al. Adversarial examples: Attacks and defenses for deep learning[J]. IEEE transactions on neural networks and learning systems, 2019, 30(9): 2805-2824.
[6]Li J, Ji R, Liu H, et al. Universal perturbation attack against image retrieval[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 4899-4908.
[7]Tang R, Du M, Liu N, et al. An embarrassingly simple approach for trojan attack in deep neural networks[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 218-228.
[8]Liu Y, Ma X, Bailey J, et al. Reflection backdoor: A natural backdoor attack on deep neural networks[C]//European Conference on Computer Vision. Springer, Cham, 2020: 182-199.
[9]Chen, X., Liu, C., Li, B., Lu, K., Song, D.: Targeted backdoor attacks on deeplearning systems using data poisoning. arXiv preprint arXiv:1712.05526 (2017)
[10]Barni, M., Kallas, K., Tondi, B.: A new backdoor attack in cnns by training setcorruption without label poisoning. In: IEEE International Conference on ImageProcessing (ICIP). pp. 101–105. IEEE (2019)
[11]Tran, B., Li, J., Madry, A.: Spectral signatures in backdoor attacks. In: NIPS(2018)
[12] Turner A, Tsipras D, Madry A. Clean-label backdoor attacks[J]. 2018.
[13]Te Lester Juin Tan and Reza Shokri. Bypassing Backdoor Detection Algorithms in Deep Learning. In Proceedings of IEEE European Symposium on Security and Privacy (Euro S&P), 2020.
[14]W. Xu, D. Evans, and Y. Qi. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. In Proceedings of Network and Distributed System Security Symposium (NDSS), 2018.
[15]Yansong Gao, Chang Xu, Derui Wang, Shiping Chen, Damith Ranas- inghe, and Surya Nepal. STRIP: A Defence Against Trojan Attacks on Deep Neural Networks. In Proceedings of Annual Computer Security Applications Conference (ACSAC), 2019.
[16]Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks. In Proceedings of Symposium on Research in Attacks, Intrusions and Defenses (RAID), 2018.
[17]Huili Chen, Cheng Fu, Jishen Zhao, and Farinaz Koushanfar. DeepIn- spect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks. In Proceedings of International Joint Confer- ence on Artificial Intelligence, 2019.
[18]Y. Adi, C. Baum, M. Cisse, B. Pinkas, and J. Keshet, “Turning your weakness into a strength: Watermarking deep neural networks by backdooring,” in USENIX Security Symposium, 2018.
[19]H. Jia, C. A. Choquette-Choo, and N. Papernot, “Entangled wa- termarks as a defense against model extraction,” arXiv preprint arXiv:2002.12200, 2020.
[20]Li Y, Wu B, Jiang Y, et al. Backdoor learning: A survey[J]. arXiv preprint arXiv:2007.08745, 2020.
[21]Gao Y, Doan B G, Zhang Z, et al. Backdoor attacks and countermeasures on deep learning: a comprehensive review[J]. arXiv preprint arXiv:2007.10760, 2020.
[22]Pang R, Zhang Z, Gao X, et al. TROJANZOO: Everything you ever wanted to know about neural backdoors (but were afraid to ask)[J]. arXiv preprint arXiv:2012.09302, 2020.
以上是关于深度学习后门攻防综述的主要内容,如果未能解决你的问题,请参考以下文章