BeautifulSoup4的学习
Posted 离落想AC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BeautifulSoup4的学习相关的知识,希望对你有一定的参考价值。
4、遍历文档树
① .contents:获取Tag的所有子节点,返回一个list
# tag的.content 属性可以将tag的子节点以列表的方式输出
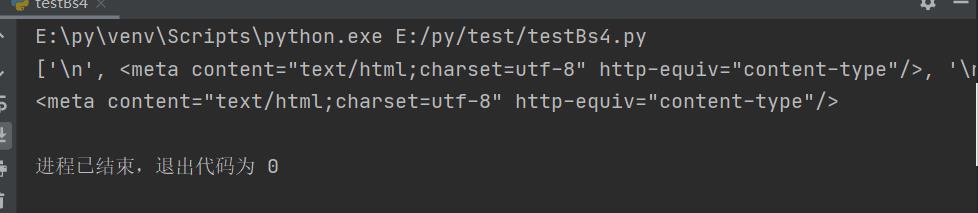
print(bs.head.contents)
# 用列表索引来获取它的某一个元素
print(bs.head.contents[1])
效果实现:
② .children:获取Tag的所有子节点,返回一个生成器
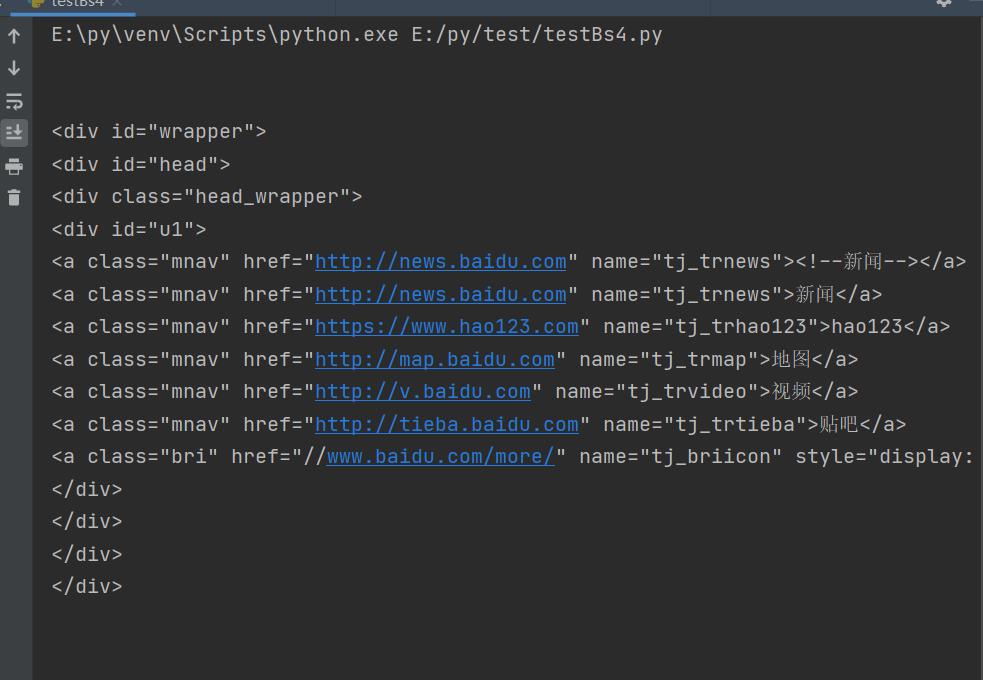
for child in bs.body.children:
print(child)
效果实现:
③ .descendants:获取Tag的所有子孙节点
④ .strings:如果Tag包含多个字符串,即在子孙节点中有内容,可以用此获取,而后进行遍历
⑤ .stripped_strings:与strings用法一致,只不过可以去除掉那些多余的空白内容
⑥ .parent:获取Tag的父节点
⑦ .parents:递归得到父辈元素的所有节点,返回一个生成器
⑧ .previous_sibling:获取当前Tag的上一个节点,属性通常是字符串或空白,真实结果是当前标签与上一个标签之间的顿号和换行符
⑨ .next_sibling:获取当前Tag的下一个节点,属性通常是字符串或空白,真是结果是当前标签与下一个标签之间的顿号与换行符
⑩ .previous_siblings:获取当前Tag的上面所有的兄弟节点,返回一个生成器
⑪ .next_siblings:获取当前Tag的下面所有的兄弟节点,返回一个生成器
⑫ .previous_element:获取解析过程中上一个被解析的对象(字符串或tag),可能与previous_sibling相同,但通常是不一样的
⑬ .next_element:获取解析过程中下一个被解析的对象(字符串或tag),可能与next_sibling相同,但通常是不一样的
⑭ .previous_elements:返回一个生成器,可以向前访问文档的解析内容
⑮ .next_elements:返回一个生成器,可以向后访问文档的解析内容
⑯ .has_attr:判断Tag是否包含属性
5、搜索文档树
find_all(name, attrs, recursive, text, **kwargs)
在上面的栗子中我们简单介绍了find_all的使用,接下来介绍一下find_all的更多用法-过滤器。这些过滤器贯穿整个搜索API,过滤器可以被用在tag的name中,节点的属性等。
(1)name参数:
字符串过滤:会查找与字符串完全匹配的内容
a_list = bs.find_all("a")
print(a_list)
效果实现:

正则表达式过滤:如果传入的是正则表达式,那么BeautifulSoup4会通过search()来匹配内容
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser")
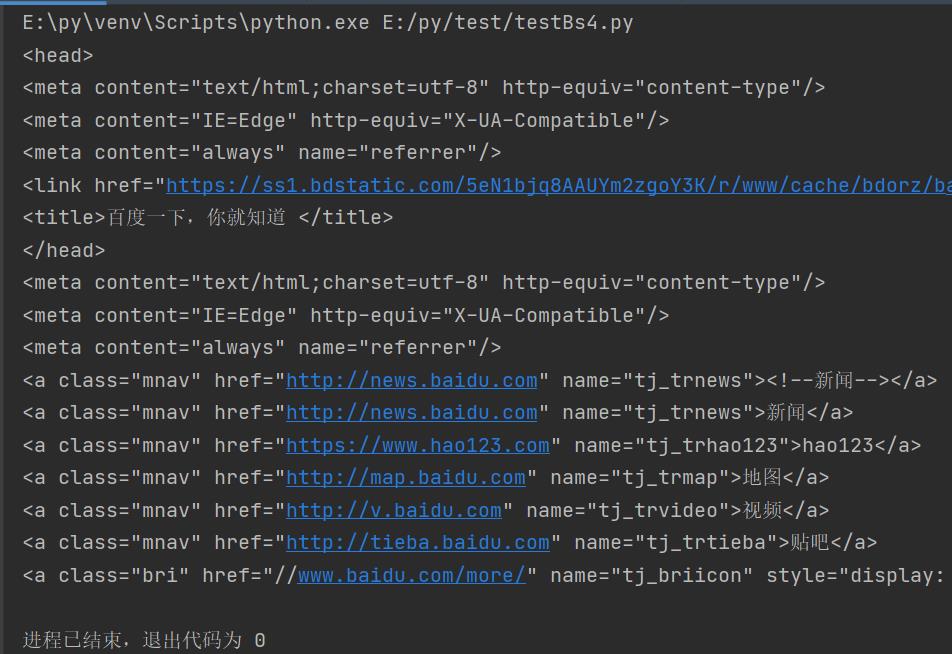
t_list = bs.find_all(re.compile("a"))
for item in t_list:
print(item)
效果实现:
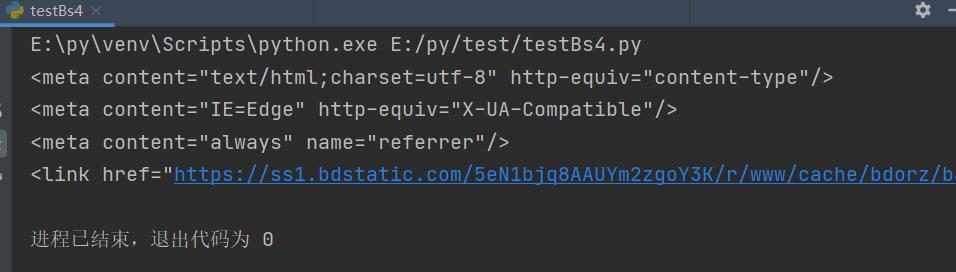
列表:如果传入一个列表,BeautifulSoup4将会与列表中的任一元素匹配到的节点返回
t_list = bs.find_all(["meta","link"])
for item in t_list:
print(item)
方法:传入一个方法,根据方法来匹配
from bs4 import BeautifulSoup
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser")
def name_is_exists(tag):
return tag.has_attr("name")
t_list = bs.find_all(name_is_exists)
for item in t_list:
print(item)
效果实现:
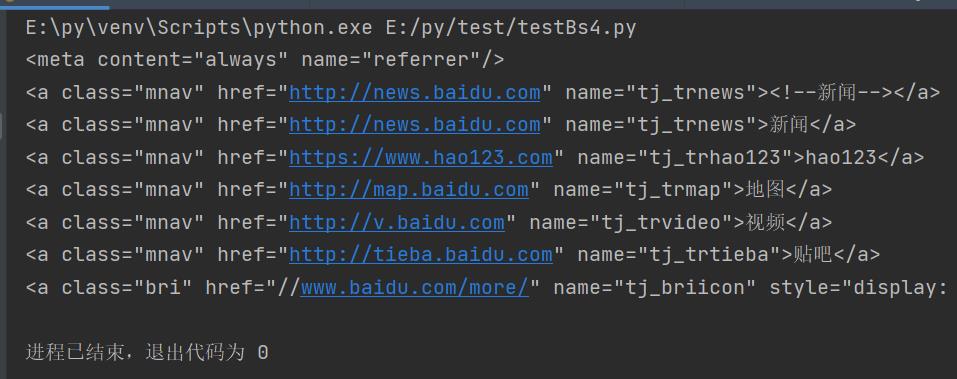
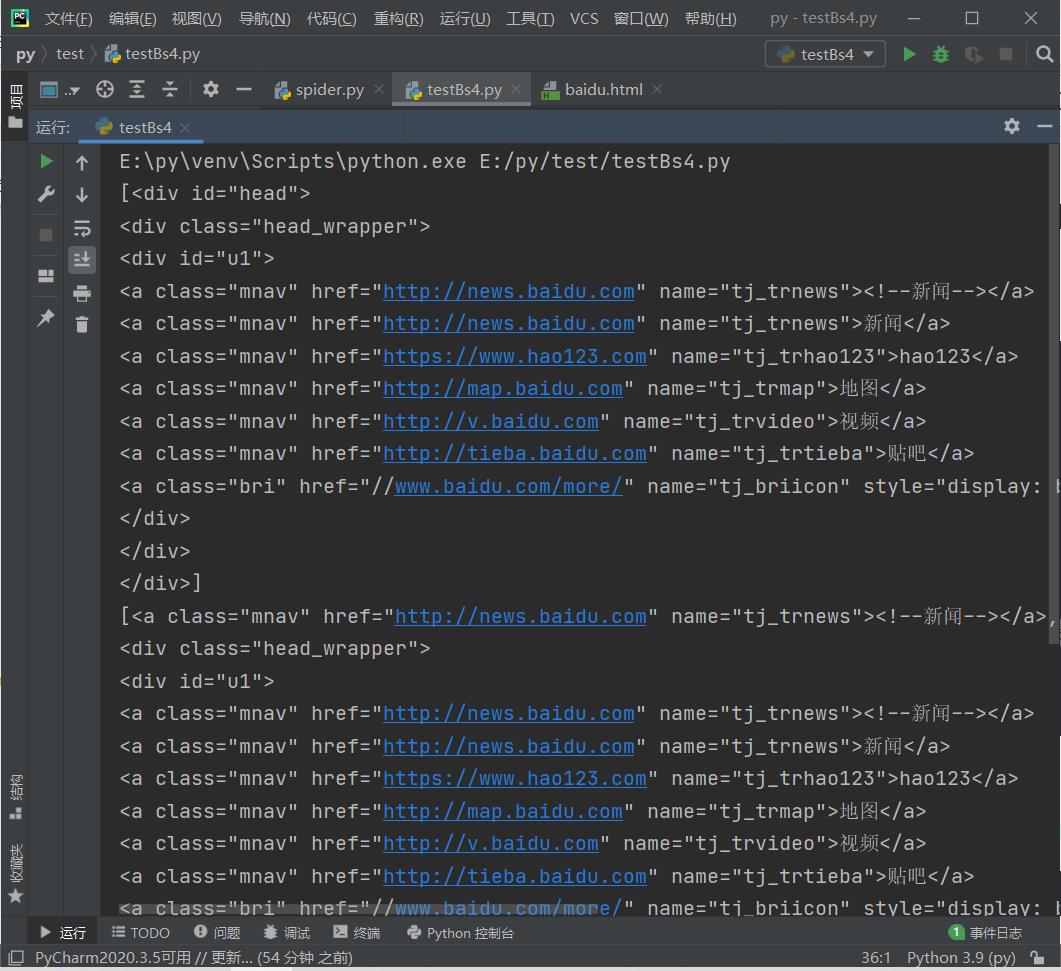
(2)kwargs参数:
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser")
# 查询id=head的Tag
t_list = bs.find_all(id="head")
print(t_list)
# 查询href属性包含ss1.bdstatic.com的Tag
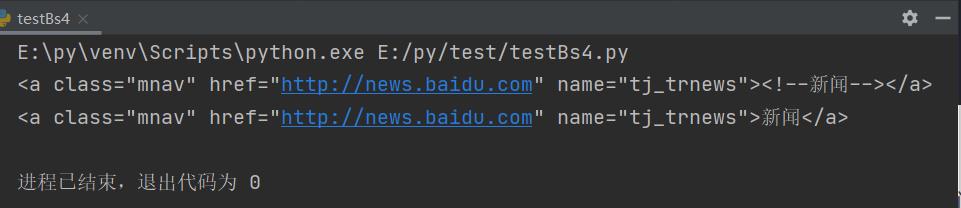
t_list = bs.find_all(href=re.compile("http://news.baidu.com"))
print(t_list)
# 查询所有包含class的Tag(注意:class在Python中属于关键字,所以加_以示区别)
t_list = bs.find_all(class_=True)
for item in t_list:
print(item)
效果实现:
(3)attrs参数:
并不是所有的属性都可以使用上面这种方式进行搜索,比如HTML的data-*属性:
t_list = bs.find_all(data-foo="value")
如果执行这段代码,将会报错。我们可以使用attrs参数,定义一个字典来搜索包含特殊属性的tag:
t_list = bs.find_all(attrs={"data-foo":"value"})
for item in t_list:
print(item)
(4)text参数:
通过text参数可以搜索文档中的字符串内容,与name参数的可选值一样,text参数接受 字符串,正则表达式,列表
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html, "html.parser")
t_list = bs.find_all(attrs={"data-foo": "value"})
for item in t_list:
print(item)
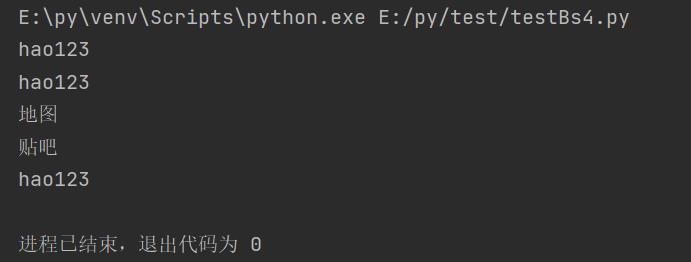
t_list = bs.find_all(text="hao123")
for item in t_list:
print(item)
t_list = bs.find_all(text=["hao123", "地图", "贴吧"])
for item in t_list:
print(item)
t_list = bs.find_all(text=re.compile("\\d"))
for item in t_list:
print(item)
效果实现:
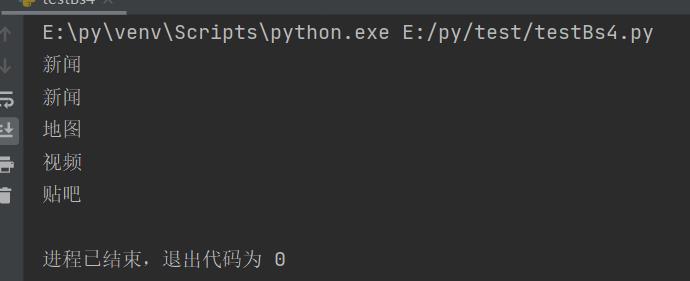
当我们搜索text中的一些特殊属性时,同样也可以传入一个方法来达到我们的目的:
def length_is_two(text):
return text and len(text) == 2
t_list = bs.find_all(text=length_is_two)
for item in t_list:
print(item)
(5)limit参数:
可以传入一个limit参数来限制返回的数量,当搜索出的数据量为5,而设置了limit=2时,此时只会返回前2个数据
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html, "html.parser")
t_list = bs.find_all("a",limit=2)
for item in t_list:
print(item)
效果实现:
find_all除了上面一些常规的写法,还可以对其进行一些简写:
# 两者是相等的
# t_list = bs.find_all("a") => t_list = bs("a")
t_list = bs("a") # 两者是相等的
# t_list = bs.a.find_all(text="新闻") => t_list = bs.a(text="新闻")
t_list = bs.a(text="新闻")
find()
find()将返回符合条件的第一个Tag,有时我们只需要或一个Tag时,我们就可以用到find()方法了。当然了,也可以使用find_all()方法,传入一个limit=1,然后再取出第一个值也是可以的,不过未免繁琐。
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html, "html.parser")
# 返回只有一个结果的列表
t_list = bs.find_all("title",limit=1)
print(t_list)
# 返回唯一值
t = bs.find("title")
print(t)
# 如果没有找到,则返回None
t = bs.find("abc")
print(t)
效果实现:
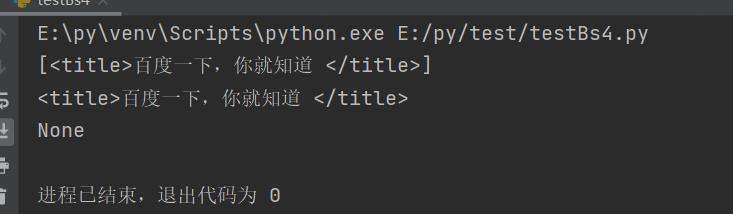
从结果可以看出find_all,尽管传入了limit=1,但是返回值仍然为一个列表,当我们只需要取一个值时,远不如find方法方便。但
是如果未搜索到值时,将返回一个None
在上面介绍BeautifulSoup4的时候,我们知道可以通过bs.div来获取第一个div标签,如果我们需要获取第一个div下的第一个div,
我们可以这样:
t = bs.div.div
# 等价于
t = bs.find("div").find("div")
6、CSS选择器
BeautifulSoup支持发部分的CSS选择器,在Tag获取BeautifulSoup对象的.select()方法中传入字符串参数,即可使用CSS选择器的语法找到Tag:
通过标签名查找
print(bs.select('title'))
print(bs.select('a'))
效果实现:

通过类名查找
print(bs.select('.mnav'))
效果实现:

通过id查找
print(bs.select('.mnav'))
效果实现:

组合查找
print(bs.select('div .bri'))
效果实现:

属性查找
print(bs.select('a[class="bri"]'))
print(bs.select('a[href="http://tieba.baidu.com"]'))
效果实现:

直接子标签查找
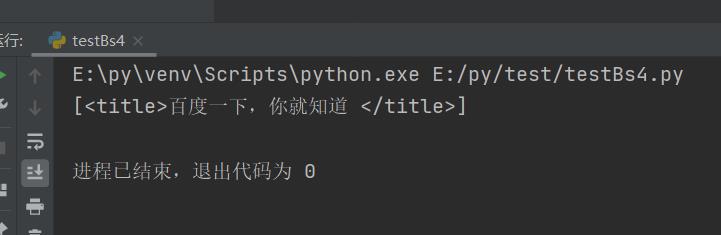
t_list = bs.select("head > title")
print(t_list)
效果实现:
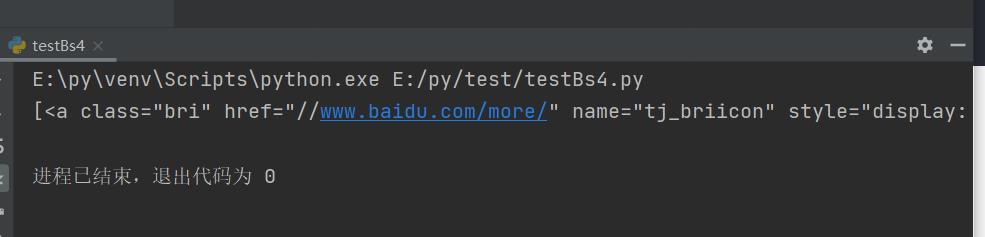
兄弟节点标签查找
t_list = bs.select(".mnav ~ .bri")
print(t_list)
效果实现:
获取内容
t_list = bs.select("title")
print(bs.select('title')[0].get_text())
效果实现:
以上是关于BeautifulSoup4的学习的主要内容,如果未能解决你的问题,请参考以下文章