2021-05-11
Posted 离落想AC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021-05-11相关的知识,希望对你有一定的参考价值。
百度图片抓取
# -*- coding: UTF-8 -*-
# @Time : 2021/5/9 19:13
# @Author : 李如旭
# @File :yaopon.py
# @Software: PyCharm
import re
import requests
headers = {
'Access-Control-Allow-Credentials': 'true',
'Connection': 'keep-alive',
'Cookie': 'BDqhfp=%E5%A3%81%E7%BA%B8%26%2600-10-1undefined%26%260%26%261; winWH=%5E6_1536x722; BDIMGISLOGIN=0; BIDUPSID=FE9826A72C39F91C0E61193E5491E34C; PSTM=1615091628; BAIDUID=FE9826A72C39F91C0FBB74E5608E6122:FG=1; __yjs_duid=1_1065c98d6b2f5942e26310dd050a58eb1618208372028; BDUSS=s4UDNqejFQNUlrWWJ2SlY3fkNtMzZMRE1SUEVEYWl1dmRYbTlJZG1BdE9pTEJnRVFBQUFBJCQAAAAAAAAAAAEAAADIzI1jwOvC5NXmy6cAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAE77iGBO-4hgT0; BDUSS_BFESS=s4UDNqejFQNUlrWWJ2SlY3fkNtMzZMRE1SUEVEYWl1dmRYbTlJZG1BdE9pTEJnRVFBQUFBJCQAAAAAAAAAAAEAAADIzI1jwOvC5NXmy6cAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAE77iGBO-4hgT0; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=33985_33971_31254_33848_33607_26350_33996; delPer=0; PSINO=2; BAIDUID_BFESS=FE9826A72C39F91C0FBB74E5608E6122:FG=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; BDRCVFR[X_XKQks0S63]=mk3SLVN4HKm; firstShowTip=1; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; ab_sr=1.0.0_MzdhMDcxNzNjZDM0OTI3NzRlMjIwOGM2MWNkMjAzMzUzZTFlZWZjYTRlNmE4MmEwZTI4MGM1OGRlMTU1MjkzYjM3Y2ZhY2RmOWRjN2I2NGM1NWYwOWRlZTQxN2RkN2JlOTdlZWQ4MTc0NTRmNTJkNGQyMzUyNDI2NzQzMTA4ZTk=; BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
def Gethml(url):
response = requests.get(url, headers=headers)
#print(response.status_code)
#print(response.text)
#if response.status_code == 200:
Parsehtml(response.content.decode('utf-8'))
#else:
#print(response.status_code)
def Parsehtml(content):
URLS = re.findall('"thumbURL":"(.*?)"',content)
i = 0
for URL in URLS:
print(URL)
for Url in URLS:
response=requests.get(Url,headers=headers)
with open("E:/百度图片/风景{}.jpg".format(i),'wb') as f:
f.write(response.content)
i +=1
if __name__ == '__main__':
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fr=&sf=1&fmq=1567133149621_R&pv=&ic=0&nc=1&z=0&hd=0&latest=0©right=0&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E5%A3%81%E7%BA%B8'
Gethml(url)
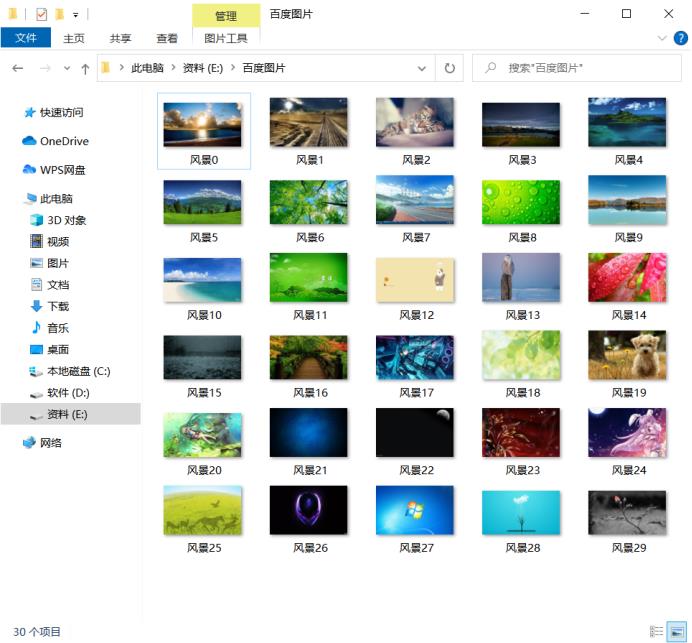
实现效果
下载的图片
以上是关于2021-05-11的主要内容,如果未能解决你的问题,请参考以下文章