StructredStreaming+Kafka+Mysql(Spark实时计算| 天猫双十一实时报表分析)
Posted ChinaManor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了StructredStreaming+Kafka+Mysql(Spark实时计算| 天猫双十一实时报表分析)相关的知识,希望对你有一定的参考价值。
前言

每年天猫双十一购物节,都会有一块巨大的实时作战大屏,展现当前的销售情况。这种炫酷的页面背后,其实有着非常强大的技术支撑,而这种场景其实就是实时报表分析。
1、业务需求概述
模拟交易订单数据,发送至分布式消息队列Kafka,实时消费交易订单数据进行分析处理,业务流程图如下所示:
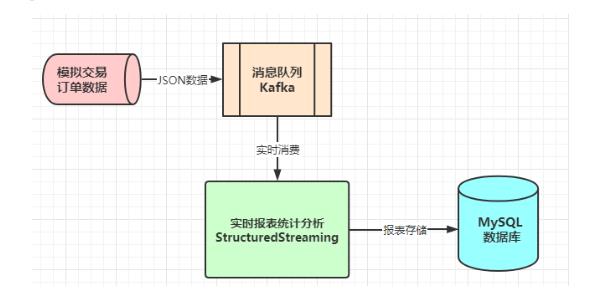
实时从Kafka消费交易订单数据,按照不同维度实时统计【销售订单额】,最终报表Report结果存储mysql数据库;

二 项目代码
1.模拟交易数据
编写程序,实时产生交易订单数据,使用Json4J类库转换数据为JSON字符,发送Kafka Topic中,代码如下:
// =================================== 订单实体类 =================================
package cn.itcast.spark.mock
/**
* 订单实体类(Case Class)
* @param orderId 订单ID
* @param userId 用户ID
* @param orderTime 订单日期时间
* @param ip 下单IP地址
* @param orderMoney 订单金额
* @param orderStatus 订单状态
*/
case class OrderRecord(
orderId: String,
userId: String,
orderTime: String,
ip: String,
orderMoney: Double,
orderStatus: Int
)
// ================================== 模拟订单数据 ==================================
package cn.itcast.spark.mock
import java.util.Properties
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import org.json4s.jackson.Json
import scala.util.Random
/**
* 模拟生产订单数据,发送到Kafka Topic中
* Topic中每条数据Message类型为String,以JSON格式数据发送
* 数据转换:
* 将Order类实例对象转换为JSON格式字符串数据(可以使用json4s类库)
*/
object MockOrderProducer {
def main(args: Array[String]): Unit = {
var producer: KafkaProducer[String, String] = null
try {
// 1. Kafka Client Producer 配置信息
val props = new Properties()
props.put("bootstrap.servers", "node1.itcast.cn:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
// 2. 创建KafkaProducer对象,传入配置信息
producer = new KafkaProducer[String, String](props)
// 随机数实例对象
val random: Random = new Random()
// 订单状态:订单打开 0,订单取消 1,订单关闭 2,订单完成 3
val allStatus =Array(0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
while(true){
// 每次循环 模拟产生的订单数目
val batchNumber: Int = random.nextInt(1) + 5
(1 to batchNumber).foreach{number =>
val currentTime: Long = System.currentTimeMillis()
val orderId: String = s"${getDate(currentTime)}%06d".format(number)
val userId: String = s"${1 + random.nextInt(5)}%08d".format(random.nextInt(1000))
val orderTime: String = getDate(currentTime, format="yyyy-MM-dd HH:mm:ss.SSS")
val orderMoney: String = s"${5 + random.nextInt(500)}.%02d".format(random.nextInt(100))
val orderStatus: Int = allStatus(random.nextInt(allStatus.length))
// 3. 订单记录数据
val orderRecord: OrderRecord = OrderRecord(
orderId, userId, orderTime, getRandomIp, orderMoney.toDouble, orderStatus
)
// 转换为JSON格式数据
val orderJson = new Json(org.json4s.DefaultFormats).write(orderRecord)
println(orderJson)
// 4. 构建ProducerRecord对象
val record = new ProducerRecord[String, String]("orderTopic", orderJson)
// 5. 发送数据:def send(messages: KeyedMessage[K,V]*), 将数据发送到Topic
producer.send(record)
}
Thread.sleep(random.nextInt(100) + 500)
}
}catch {
case e: Exception => e.printStackTrace()
}finally {
if(null != producer) producer.close()
}
}
/**=================获取当前时间=================*/
def getDate(time: Long, format: String = "yyyyMMddHHmmssSSS"): String = {
val fastFormat: FastDateFormat = FastDateFormat.getInstance(format)
val formatDate: String = fastFormat.format(time) // 格式化日期
formatDate
}
/**================= 获取随机IP地址 =================*/
def getRandomIp: String = {
// ip范围
val range: Array[(Int, Int)] = Array(
(607649792,608174079), //36.56.0.0-36.63.255.255
(1038614528,1039007743), //61.232.0.0-61.237.255.255
(1783627776,1784676351), //106.80.0.0-106.95.255.255
(2035023872,2035154943), //121.76.0.0-121.77.255.255
(2078801920,2079064063), //123.232.0.0-123.235.255.255
(-1950089216,-1948778497),//139.196.0.0-139.215.255.255
(-1425539072,-1425014785),//171.8.0.0-171.15.255.255
(-1236271104,-1235419137),//182.80.0.0-182.92.255.255
(-770113536,-768606209),//210.25.0.0-210.47.255.255
(-569376768,-564133889) //222.16.0.0-222.95.255.255
)
// 随机数:IP地址范围下标
val random = new Random()
val index = random.nextInt(10)
val ipNumber: Int = range(index)._1 + random.nextInt(range(index)._2 - range(index)._1)
// 转换Int类型IP地址为IPv4格式
number2IpString(ipNumber)
}
/**=================将Int类型IPv4地址转换为字符串类型=================*/
def number2IpString(ip: Int): String = {
val buffer: Array[Int] = new Array[Int](4)
buffer(0) = (ip >> 24) & 0xff
buffer(1) = (ip >> 16) & 0xff
buffer(2) = (ip >> 8) & 0xff
buffer(3) = ip & 0xff
// 返回IPv4地址
buffer.mkString(".")
}
}
2.创建Maven模块
创建Maven模块,加入相关依赖,具体内如如下:
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<kafka.version>2.0.0</kafka.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Structured Streaming + Kafka 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- Kafka Client 依赖 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<!-- 根据ip转换为省市区 -->
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>1.7.2</version>
</dependency>
<!-- MySQL Client 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- JSON解析库:fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
项目结构如下:
3.核心代码
RealTimeOrderReport.java
package cn.itcast.spark.report
import java.util.concurrent.TimeUnit
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
import org.apache.spark.sql.expressions.{UserDefinedAggregateFunction, UserDefinedFunction}
import org.apache.spark.sql.types.{DataType, DataTypes}
import org.lionsoul.ip2region.{DataBlock, DbConfig, DbSearcher}
def printToConsole(dataFrame: DataFrame) = {
dataFrame.writeStream
.format("console")
.outputMode(OutputMode.Update())
.option("numRows","50")
.option("truncate","false")
.start()
}
def main(args: Array[String]): Unit = {
//1.获取spark实例对象
val spark: SparkSession = SparkSession.builder()
.appName("isDemo")
.master("local[3]")
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
import spark.implicits._
val dataFrame: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("subscribe", "orderTopic")
.load()
.selectExpr("CAST (value AS STRING)")
// printToConsole(dataFrame)
val ip_to_region: UserDefinedFunction = udf((ip: String) => {
// 1. 创建DbSearch对象,指定数据字典文件位置
val dbSearcher = new DbSearcher(new 以上是关于StructredStreaming+Kafka+Mysql(Spark实时计算| 天猫双十一实时报表分析)的主要内容,如果未能解决你的问题,请参考以下文章
刁钻导师难为人?我转手丢给他一个Flink史上最简单双十一实时分析案例
大数据技术之_10_Kafka学习_Kafka概述+Kafka集群部署+Kafka工作流程分析+Kafka API实战+Kafka Producer拦截器+Kafka Streams