京东面试官:呦,你对中间件 Mycat了解的还挺深~
Posted Java架构没有996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了京东面试官:呦,你对中间件 Mycat了解的还挺深~相关的知识,希望对你有一定的参考价值。

1.数据切分概念
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)](https://jq.qq.com/?_wv=1027&k=0IsBuUb0)之上,这种切可以称之为数据的垂直(纵向)切分;另外一则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。 垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。 水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
垂直切分
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到
不同 的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如下图:
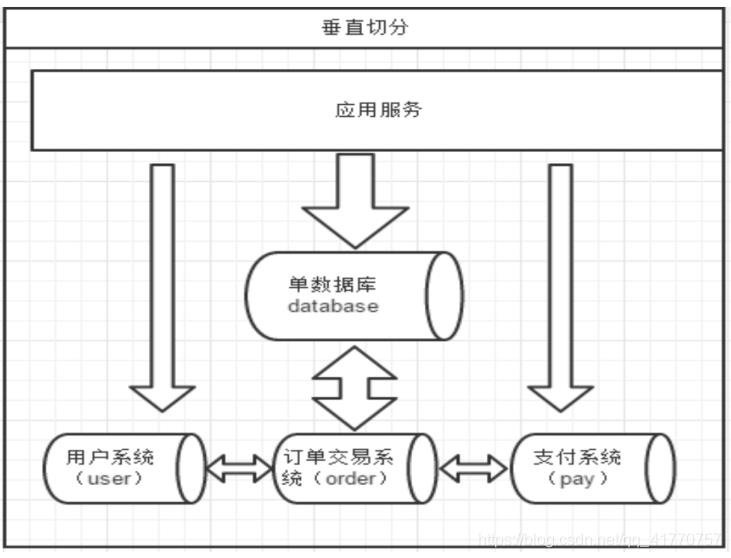
一般来讲业务存在着复杂 join 的场景是难以切分的,往往业务独立的易于切分。如何切分,切分到何种程度是考验技术架构的一个难题。 下面来分析下垂直切分的优缺点:
优点:
- 拆分后业务清晰,拆分规则明确。
- 系统之间整合或扩展容易。
- 数据维护简单。
缺点:
- 部分业务表无法 join,只能通过接口方式解决,提高了系统复杂度。
- 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
- 事务处理复杂。 由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶颈,所以就需要水平拆分来做解决。
水平切分
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,如图:
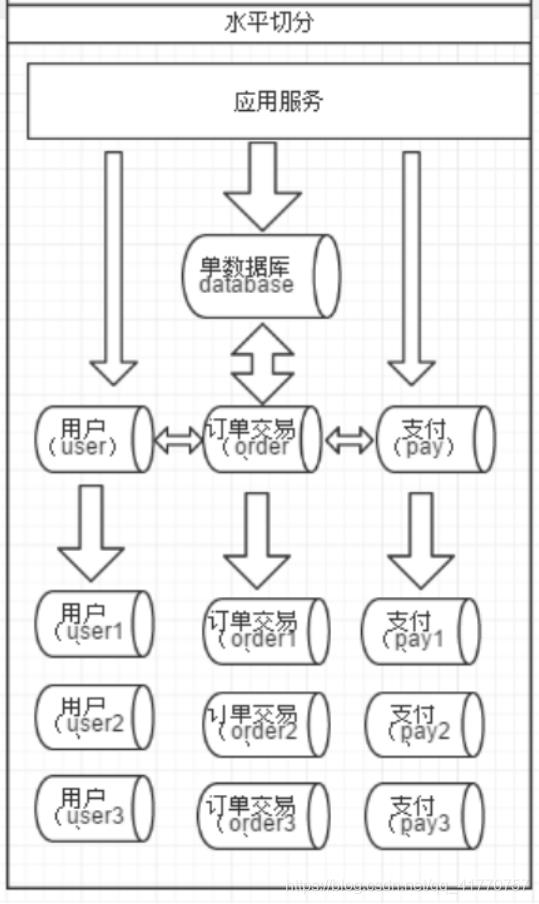
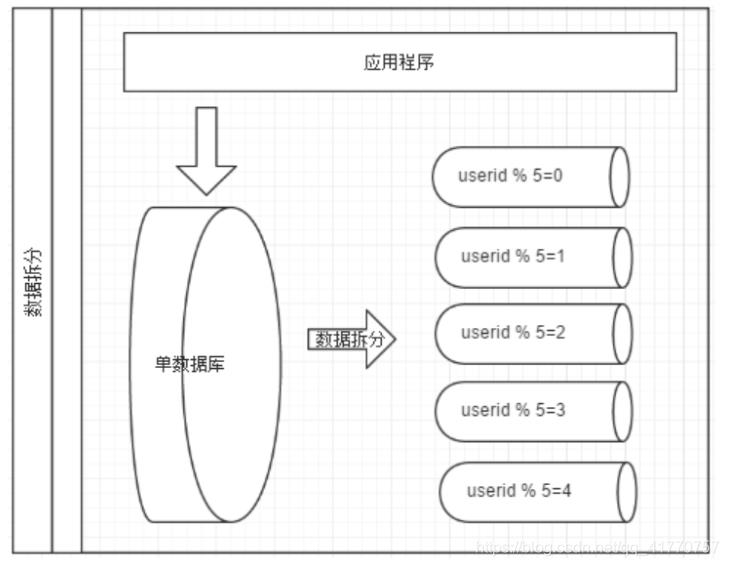
拆分数据就需要定义分片规则。关系型数据库是行列的二维模型,拆分的第一原则是找到拆分维度。几种典型的分片规则包括: ? 按照用户 ID 求模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中。 ? 按照日期,将不同月甚至日的数据分散到不同的库中。 ? 按照某个特定的字段求摸,或者根据特定范围段分散到不同的库中。
优点:
- 拆分规则抽象好,join 操作基本可以数据库做。
- 不存在单库大数据,高并发的性能瓶颈。
- 应用端改造较少。
- 提高了系统的稳定性跟负载能力。
缺点:
- 拆分规则难以抽象。
- 分片事务一致性难以解决。
- 数据多次扩展难度跟维护量极大。
- 跨库 join 性能较差。
垂直切分和水平切分都有缺点,但共同的缺点有:
- 引入分布式事务的问题。
- 跨节点 Join 的问题。
- 跨节点合并排序分页问题。
- 多数据源管理问题。
针对数据源管理,目前主要有两种思路:
-
A. 客户端模式,在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个数据 库,在模块内完成数据的整合;
-
B. 通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明;
集中式代理 proxy mycat
嵌入应用去中心化架构 sharding-jdbc
基于主机进程的去中心化架构 sharding-sidecar service mesh
数据切分原则
第一原则:能不切分尽量不要切分。
第二原则:如果要切分一定要选择合适的切分规则,提前规划好。
第三原则:数据切分尽量通过数据冗余或表分组来降低跨库 Join 的可能。
第四原则:由于数据库中间件对数据 Join 实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量 少使用多表 Join。
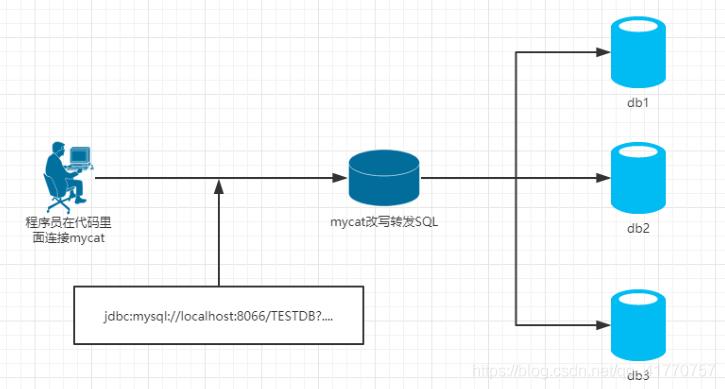
2.什么是Mycat
定义
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代mysql的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
跨分片数据合并
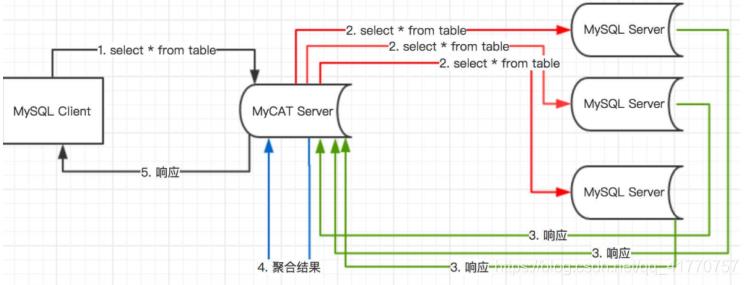
应用场景
Mycat 发展到现在,适用的场景已经很丰富,而且不断有新用户给出新的创新性的方案,以下是几个典
型的 应用场景:
单纯的读写分离,此时配置最为简单,支持读写分离,主从切换
分表分库,对于超过 1000 万的表进行分片,最大支持 1000 亿的单表分片
多租户应用,每个应用一个库,但应用程序只连接 Mycat,从而不改造程序本身,实现多租户化
报表系统,借助于 Mycat的分表能力,处理大规模报表的统计
替代 Hbase,分析大数据
作为海量数据实时查询的一种简单有效方案,比如 100 亿条频繁查询的记录需要在 3 秒内查询出来结果, 除了基于主键的查询,还可能存在范围查询或其他属性查询,此时 Mycat 可能是最简单有效的选择
3.Mycat中的核心概念及配置
核心概念
数据库中间件
Mycat 是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服务。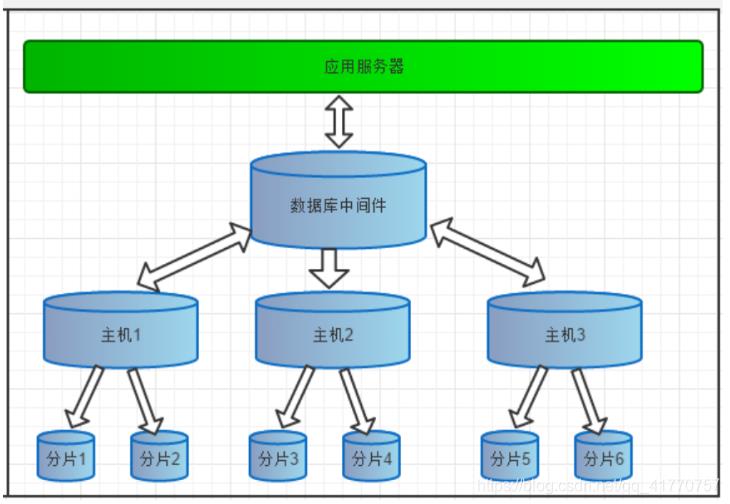
逻辑库(schema)
通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以
数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库
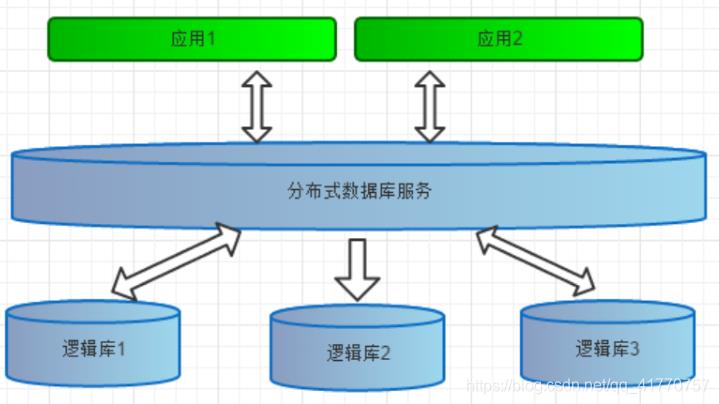
逻辑表(table)
逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一
个表构成。
分片表 分片表,是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分
片都有一部分数据,所有分片构成了完整的数据。 例如在 mycat 配置中的 t_node 就属于分
片表,数据按照规则被分到 dn1,dn2 两个分片节点(dataNode) 上。

非分片表
一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表
来说的,就是那些不需要进行数据切分的表。
如下配置中 t_node,只存在于分片节点(dataNode)dn1 上。

分片节点(dataNode)
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节
(dataNode)
节点主机(dataHost) 数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机
器上面可以有多个分片数据库, 这样一个或多个分片节点(dataNode)所在的机器就是节点主机
(dataHost),为了规避单节点主机并发数限 制,尽量将读写压力高的分片节点(dataNode)均
衡的放在不同的节点主机(dataHost)。
分片规则(rule)
一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到 某个分片
的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难
度。
全局序列号(sequence)
数据切分后,原有的关系数据库中的主键约束在分布式条件下将无法使用,因此需要引入外部机制
保证数据 唯一性标识,这种保证全局性的数据唯一标识的机制就是全局序列号(sequence)。
安装与配置
基于源码
-
MyCAT-Server 源码下载 MyCAT-Server 仓库地址
-
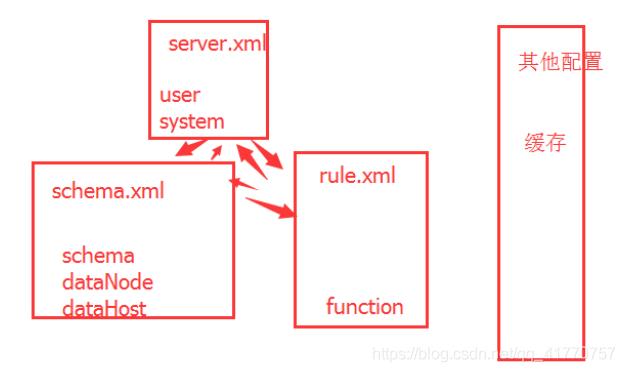
源码调试与配置 MyCAT 目前主要通过配置文件的方式来定义逻辑库和相关配置: •MYCAT_HOME/conf/schema.xml 中定义逻辑库,表、分片节点等内容.
-
•MYCAT_HOME/conf/rule.xml 中定义分片规则.
-
• MYCAT_HOME/conf/server.xml 中定义用户以及系统相关变量,如端口等.
-
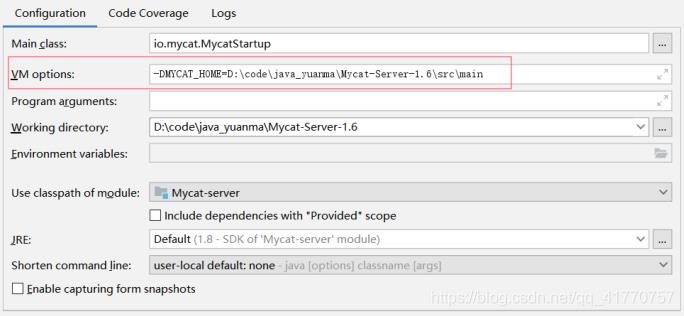
源码运行 MyCAT 入口程序是 org.opencloudb.MycatStartup.java ,需要设置MYCAT_HOME 目
录,为你工程当前所在目录(src/main) , 设置完 MYCAT 主目录后即可正常运行 MyCAT 服务。【参考文献】
linux安装
下载
wget http://dl.mycat.io/1.6.7.3/20190927161129/Mycat-server-1.6.7.3-release-
20190927161129-linux.tar.gz
#解压进入mycat目录
#启动mycat
./bin/mycat start
#停止
./bin/mycat stop
#重启服务
./bin/mycat restart
#查看启动状态
./bin/mycat status
conf 目录下存放配置文件,server.xml 是 Mycat 服务器参数调整和用户授权的配置文件,schema.xml 是逻 辑库定义和表以及分片定义的配置文件,rule.xml 是分片规则的配置文件,分片规则的具体一些参数信息单独存 放为文件
4. MyCat配置
- bin 启动目录
- conf 配置目录存放配置文件:
- server.xml:是Mycat服务器参数调整和用户授权的配置文件。
- schema.xml:是逻辑库定义和表以及分片定义的配置文件。
- rule.xml: 是分片规则的配置文件,分片规则的具体一些参数信息单独存放为文件,也在这个目录
下,配置文件修改需要重启MyCAT。 - log4j.xml: 日志存放在logs/log中,每天一个文件,日志的配置是在conf/log4j.xml中,根据
自己的需要可以调整输出级别为debug debug级别下,会输出更多的信
息,方便排查问题。 - autopartition-long.txt,partition-hash-int.txt,sequence_conf.properties,
- sequence_db_conf.properties 分片相关的id分片规则配置文件
- lib MyCAT自身的jar包或依赖的jar包的存放目录。
- logs MyCAT日志的存放目录。日志存放在logs/log中,每天一个文件
下面图片描述了Mycat最重要的3大配置文件:
配置Mycat环境参数
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="defaultSqlParser">druidparser</property>
</system>
</mycat:server>
如例子中配置的所有的Mycat参数变量都是配置在server.xml 文件中,system标签下配置所有的参数,如果需要配置某个变量添加相应的配置即可,例如添加启动端口8066,默认为8066:
<property name="serverPort">8066</property>
其他所有变量类似。
配置Mycat逻辑库与用户
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<user name="mycat">
<property name="password">mycat</property>
<property name="schemas">TESTDB</property>
</user>
</mycat:server>
如例子中配置的所有的Mycat连接的用户与逻辑库映射都是配置在server.xml 文件中,user标签下配置所有的参数,例如例子中配置了一个mycat用户供应用连接到mycat,同时mycat 在schema.xml中配置后了一个逻辑库TESTDB,配置好逻辑库与用户的映射关系。【参考文献】
配置逻辑库(schema)
Mycat作为一个中间件,实现mysql协议,那么对前端应用连接来说就是一个数据库,也就有数据库的配置,mycat的数据库配置是在schema.xml中配置,配置好后映射到server.xml里面的用户就可以了。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="t_user" dataNode="dn1,dn2" rule="sharding-by-mod2"/>
<table name="ht_jy_login_log" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-date_jylog"/>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="mycat_node1"/>
<dataNode name="dn2" dataHost="localhost1" database="mycat_node2"/>
<dataHost name="localhost1" writeType="0" switchType="1" slaveThreshold="100"
balance="1" dbType="mysql" maxCon="10" minCon="1" dbDriver="native">
<heartbeat>show status like 'wsrep%'</heartbeat>
<writeHost host="hostM1" url="127.0.0.1:3306" user="root" password="root" >
</writeHost>
</dataHost>
</mycat:schema >
上面例子配置了一个逻辑库TESTDB,同时配置了t_user,ht_jy_login_log两个分片表。
逻辑表配置
<table name="t_user" dataNode="dn1,dn2" rule="sharding-by-mod2"/>
table 标签 是逻辑表的配置 其中
name代表表名,
dataNode代表表对应的分片,
Mycat默认采用分库方式,也就是一个表映射到不同的库上,
rule代表表要采用的数据切分方式,名称对应到rule.xml中的对应配置,如果要分片必须配置。
配置分片(dataNode)
<dataNode name="dn1" dataHost="localhost1" database="mycat_node1"/>
<dataNode name="dn2" dataHost="localhost1" database="mycat_node2"/>
表切分后需要配置映射到哪几个数据库中,Mycat的分片实际上就是库的别名,例如上面例子配置了两个分片dn1,dn2 分别对应到物理机映射dataHost localhost1 的两个库上。【参考文献】
配置物理库分片映射(dataHost)
<dataHost name="localhost1" writeType="0" switchType="1" slaveThreshold="100"
balance="1" dbType="mysql" maxCon="10" minCon="1" dbDriver="native">
<heartbeat>show status like 'wsrep%'</heartbeat>
<writeHost host="hostM1" url="127.0.0.1:3306" user="root" password="root" >
</writeHost>
</dataHost>
Mycat作为数据库代理需要逻辑库,逻辑用户,表切分后需要配置分片,分片也就需要映射到真实的物理主机上,至于是映射到一台还是一台的多个实例上,Mycat并不关心,只需要配置好映射即可,例如例子中:
配置了一个名为localhost1的物理主机(dataHost)映射。
heartbeat 标签代表Mycat需要对物理库心跳检测的语句,正常情况下生产案例可能配置主从,或者多写 或者单库,无论哪种情况Mycat都需要维持到数据库的数据源连接,因此需要定时检查后端连接可以性,心跳语句就是来作为心跳检测。【参考文献】
writeHost 此标签代表 一个逻辑主机(dataHost)对应的后端的物理主机映射,例如例子中写库hostM1 映射到127.0.0.1:3306。如果后端需要做读写分离或者多写 或者主从则通过配置 多个writeHost 或者readHost即可。
dataHost 标签中的 writeType balance 等标签则是不同的策略,具体参考指南。
表切分规则配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://org.opencloudb/">
<tableRule name="sharding-by-hour">
<rule>
<columns>createTime</columns>
<algorithm>sharding-by-hour</algorithm>
</rule>
</tableRule>
<function name="sharding-by-hour"
class="org.opencloudb.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
</mycat:rule >
数据切分中作为表切分规则中最重要的配置,表的切分方式决定了数据切分后的性能好坏,因此也是最重要的配置。
如上面例子配置了一个切分规则,名为sharding-by-hour 对应的切分方式(function )是按日期切
分,该配置中:
tableRule
name 为schema.xml 中table 标签中对应的 rule=“sharding-by-hour” ,也就是配置表的分片规则,columns 是表的切分字段: createTime 创建日期。algorithm 是规则对应的切分规则:映射到function 的name。
function
function 配置是分片规则的配置。
name 为切分规则的名称,名字任意取,但是需要与tableRule 中匹配。
class 是切分规则对应的切分类,写死,需要哪种规则则配置哪种,例如本例子是按小时分片:org.opencloudb.route.function.LatestMonthPartion
property 标签是切分规则对应的不同属性,不同的切分规则配置不同。【参考文献】
5.Mycat读写分离实战
Mysql同步原理
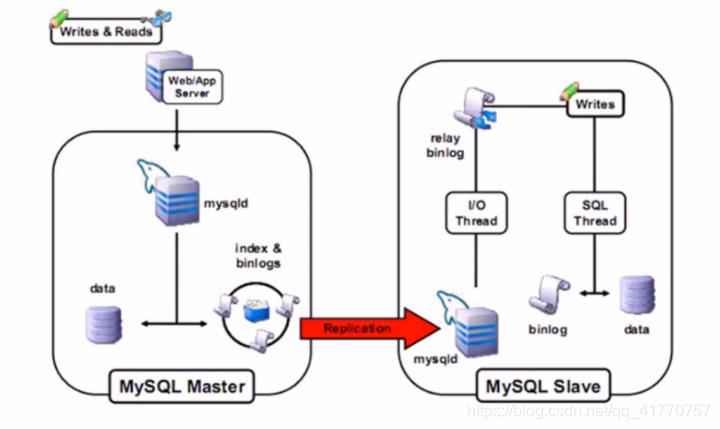
Mysql同步方案
docker配置
# master
docker run --name mysql_master -v /root/mysql-cluster/master/:/etc/mysql/conf.d/
-e MYSQL_ROOT_PASSWORD=root -p 3316:3306 -d mysql:5.7
# slave1
docker run --name mysql_slave1 -v /root/mysql-cluster/slave1/:/etc/mysql/conf.d/
-e MYSQL_ROOT_PASSWORD=root -p 3326:3306 -d mysql:5.7
# slave2
docker run --name mysql_slave2 -v /root/mysql-cluster/slave2/:/etc/mysql/conf.d/
-e MYSQL_ROOT_PASSWORD=root -p 3336:3306 -d mysql:5.7
读写分离配置
配置 mysql 端主从的数据自动同步,mycat 不负责任何的数据同步问题
配置schema.xml
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" >
<heartbeat>show slave status</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS1" url="localhost2:3306" user="root" password="123456"
weight="1" />
</writeHost>
</dataHost>
强制走从:
/*!mycat:db_type=slave*/ select * from travelrecord
强制走写:
/*!mycat:db_type=master*/ select * from travelrecord
6.Mycat 全局序列号
本地文件方式
配置schema.xml
<table name="travelrecord" dataNode="dn1" autoIncrement="true"
primaryKey="id" />
编辑 server.xml
修改主键生成策略
<property name="sequnceHandlerType">0</property>
编辑sequence_conf.properties
#TRAVELRECORD 是表名称
#HISIDS 表示历史分段(一般无特殊需要则可以不配置)
#MINID 最小id
#MAXID 最大id
#CURID 当前id
TRAVELRECORD.HISIDS=
TRAVELRECORD.MINID=10001
TRAVELRECORD.MAXID=20000
TRAVELRECORD.CURID=10000
本地时间戳方式
ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加)
配置schema.xml
<property name="sequnceHandlerType">2</property>
在 mycat 下配置:sequence_time_conf.properties
WORKID=0-31 #任意整数
DATAACENTERID=0-31 #任意整数
多个个 mycat 节点下每个 mycat 配置的 WORKID,DATAACENTERID 不同,组成唯一标识,总共支持32*32=1024 种组合。
多个个 mycat 节点下每个 mycat 配置的 WORKID,DATAACENTERID 不同,组成唯一标识,总共支持32*32=1024 种组合。


以上是关于京东面试官:呦,你对中间件 Mycat了解的还挺深~的主要内容,如果未能解决你的问题,请参考以下文章
面试官:你刚说你喜欢研究新技术,那么请说说你对 Blazor 的了解