hadoop离线day02--Apache Hadoop
Posted Vics异地我就
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop离线day02--Apache Hadoop相关的知识,希望对你有一定的参考价值。
hadoop离线day02--Apache Hadoop
内容大纲
#Apache Hadoop入门
介绍概念 狭义 广义
hadoop起源
hadoop特性优点
#Apache Hadoop搭建
hadoop集群 主从架构
hdfs集群 yarn集群
集群角色 集群规划
集群配置
format初始化
启停脚本
webUI页面
hadoop初体验 现象与疑惑 后续学习方向
#Apache hadoop辅助功能
jobhistory服务 查看历史执行记录
文件系统垃圾桶机制 回收站Apache Hadoop入门
-
介绍
-
狭义上:hadoop指的是Apache一款java开源软件,是一个大数据分析处理平台。
-
Hadoop ==HDFS:分布式文件系统==。 解决了海量数据存储问题。
Hadoop Distributed File System (HDFS™) -
Hadoop ==MapReduce:分布式计算框架==。解决海量数据计算问题。
A framework for job scheduling and cluster resource management. -
Hadoop ==YARN:集群资源管理和任务调度==。
-
-
广义上:Hadoop指的是==hadoop生态圈==。
提供了大数据的几乎所有软件。 采集、存储、导入、分析、挖掘、可视化、管理...
-
-
Hadoop起源发展
-
Hadoop之父--==Doug Cutting== 卡大爷
-
起源项目Apache Nutch。 致力于构建一个==全网搜索引擎==。
1、爬取互联网网页 --->存储在哪里? 海量数据存储问题 2、基于网页创建倒排索引。--->如何计算? 海量数据计算问题 -
Google也在做搜索,也遇到这些问题,内部解决了。
-
==google==不想开源,但是又憋的难受,写论文。
-
前后写了==3篇论文==(谷歌是使用c实现的)。
谷歌分布式文件系统(GFS)------>HDFS 谷歌版MapReduce 系统------>Hadoop MapReduce bigtable---->HBase -
基于论文的影响 Nutch团队实现了相应的java版本开源组件。
-
-
Nutch团队把HDFS和MapReduce抽取独立成为单独软件在==2008年贡献给了Apache==。开源。
-
Doug Cutting 看到他儿子在牙牙学语时,抱着黄色小象,亲昵的叫hadoop,他灵光一闪,就把这技术命名为 Hadoop,而且还用了黄色小象作为标示 Logo。
-
-
Hadoop特性优点
-
==分布式、扩容能力==
不再注重单机能力 看中的是集群的整体能力。 动态扩容、缩容。 -
==成本低==
在集群下 单机成本很低 可以是普通服务器组成集群 意味着大数据处理不一定需要超级计算机。 -
==高效率 并发能力==
-
==可靠性==
-
==通用性==
hadoop精准区分技术和业务。 做什么?(what need to do)---->业务问题(20%) 怎么做?(how to do)----->技术问题(80%) Hadoop把技术实现了 用户负责业务问题。 原来大数据这么简单 可以这么玩。
-
Apache Hadoop集群搭建
-
发行版本
-
==官方社区版本== Apache基金会官方
-
版本新 功能最全的
-
不稳定 兼容性需要测试 bug多
-
-
==商业版本== 商业公司在官方版本之上进行商业化发行。著名:==Cloudera==、hotonWorks、MapR
-
稳的一批 兼容性极好 技术支持 本地化支持 一键在线安装
-
版本不一定是最新的 辅助工具软件需要收费
Cloudera发行的hadoop生态圈软件叫做CDH版本。 Cloudera’s Distribution Including Apache Hadoop。 https://www.cloudera.com/products/open-source/apache-hadoop/key-cdh-components.html Hortonworks Data Platform (HDP)
-
-
本课程中 使用的是==Apache 2.7.5==稳定版本。
-
-
Hadoop本身版本变化
-
hadoop 1.x
只有hdfs mapreduce. 架构过于垃圾 性能不高 当下企业中没人使用了。 -
==hadoop 2.x==
hdfs MapReduce yarn 尤其2.x高系列版本 2.6~2.9 当下企业中使用最多。 -
hadoop 3.x
架构和2一样 性能做了优化
-
-
Hadoop集群
-
通常是有==hdfs集群==和==yarn集群==组成。两个集群都是标准的==主从架构==集群。
-
两个集群逻辑上分离 物理上在一起。
-
HDFS集群:解决了海量数据存储 分布式存储系统
-
主角色:namenode(NN)
-
从角色:datanode(DN)
-
主角色辅助角色"秘书角色":secondarynamenode (SNN)
-
-
YARN集群:集群资源管理 任务调度
-
主角色:resourcemanager(RM)
-
从角色:nodemanager(NM)
-
-
-
Hadoop部署模式
-
单机模式 Standalone
一台机器,所有的角色在一个java进程中运行。 适合体验。 -
一台机器 每个角色单独的java进程。 适合测试 -
==分布式 cluster==
多台机器 每个角色运行在不同的机器上 生产测试都可以 -
高可用集群 HA
在分布式的模式下 给主角色设置备份角色 实现了容错的功能 解决了单点故障 保证集群持续可用性。
-
-
Hadoop集群的规划
-
根据==软件和硬件的特性 合理的安排==各个角色在不同的机器上。
-
有冲突的尽量不部署在一起
-
有工作依赖尽量部署在一起
-
nodemanager 和datanode是好基友
node1: namenode datanode | resourcemanager nodemanger node2: datanode secondarynamenode| nodemanger node3: datanode | nodemanger -
-
Q:如果后续需要扩容hadoop集群,应该增加哪些角色呢?
node4: datanode nodemanger node5: datanode nodemanger node6: datanode nodemanger .....
-
-
Hadoop源码编译
-
源码下载地址
https://archive.apache.org/dist/hadoop/common/ hadoop-2.7.5-src.tar.gz source 源码包 hadoop-2.7.5.tar.gz 官方编译后安装包 -
对应java语言开发的项目软件来说,所谓的==编译==是什么?
xxx.java(源码)---->xxx.class(字节码)---->jar包 -
正常来说,官方网站提供了安装包,可以直接使用,为什么要自己编译呢?
-
==修改源码==之后需要重新编译。
-
官方提供的最大化编译 满足在各个平台运行,但是不一定彻底==兼容本地环境==。
-
某些软件,官方只提供源码。
native library 本地库。 官方编译好的 adoop的安装包没有提供带 C程序访问的接口。主要是本地压缩支持、IO支持。 -
-
怎么编译?
在源码的根目录下有编译相关的文件BUILDING.txt 指导如何编译。 使用maven进行编译 联网jar. -
可以使用课程提供编译好的安装包
hadoop-2.7.5-with-snappy-centos7.tar.gz
-
Hadoop具体安装部署
-
服务器基础环境准备
ip、主机名 hosts映射 别忘了windows也配置(C:\\Windows\\System32\\drivers\\etc\\hosts) 防火墙关闭 时间同步 免密登录 node1---->node1 node2 node3 JDK安装 -
安装包目录结构
#上传安装包到/export/server 解压 bin #hadoop核心脚本 最基础最底层脚本 etc #配置目录 include lib libexec LICENSE.txt NOTICE.txt README.txt sbin #服务启动 关闭 维护相关的脚本 share #官方自带实例 hadoop相关依赖jar -
配置文件的修改
https://hadoop.apache.org/docs/r2.7.5/-
第一类 1个 ==hadoop-env.sh==
[root@node1 hadoop]# pwd /export/server/hadoop-2.7.5/etc/hadoop export JAVA_HOME=/export/server/jdk1.8.0_65 -
第二类 4个 ==core|hdfs|mapred|yarn-site.xml==
-
site表示的是用户定义的配置,会覆盖default中的默认配置。
-
==core-site.xml== 核心模块配置
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoopdata</value> </property> </configuration> -
==hdfs-site.xml== hdfs文件系统模块配置
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2:50090</value> </property> </configuration> -
==mapred-site.xml== MapReduce模块配置
mv mapred-site.xml.template mapred-site.xml vi mapred-site.xml <configuration> <!-- 指定mr运行时框架,这里指定在yarn上,默认是local --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
yarn-site.xml yarn模块配置
<!-- 指定YARN的主角色(ResourceManager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:"" --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 聚集日志保存的时间7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
-
-
第三类 1个 ==slaves==
-
指定各个从角色位置信息 便于==一键启动==的时候读取。
-
配合hadoop安全管理 ==黑白名单机制==。
-
一行写一个IP或者主机名
node1 node2 node3 -
-
-
scp安装包到其他机器
[root@node1 hadoop]# cd /export/server/ [root@node1 server]# scp -r hadoop-2.7.5/ root@node2:$PWD [root@node1 server]# scp -r hadoop-2.7.5/ root@node3:$PWD -
vim vim /etc/profile export HADOOP_HOME=/export/server/hadoop-2.7.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #scp环境变量文件给其他机器 [root@node1 server]# scp /etc/profile node2:/etc/ [root@node1 server]# scp /etc/profile node3:/etc/ #3台机器统一的source环境变量 source /etc/profile -
hadoop namenode format
-
format准确来说翻译成为==初始化==比较好。对namenode工作目录、初始文件进行生成。
-
通常在namenode所在的机器执行 ==执行一次。首次启动之前==
hadoop namenode -format #执行成功 日志会有如下显示 21/05/23 15:38:19 INFO common.Storage: Storage directory /export/data/hadoopdata/dfs/name has been successfully formatted. [root@node1 server]# ll /export/data/hadoopdata/dfs/name/current/ total 16 -rw-r--r-- 1 root root 321 May 23 15:38 fsimage_0000000000000000000 -rw-r--r-- 1 root root 62 May 23 15:38 fsimage_0000000000000000000.md5 -rw-r--r-- 1 root root 2 May 23 15:38 seen_txid -rw-r--r-- 1 root root 207 May 23 15:38 VERSION -
Q:如果不小心初始化了多次,如何?
-
现象:主从之间互相不识别。
-
解决
#企业真实环境中 呵呵~ !!!所以只能设置一次! 一次! 一次! #学习环境 #删除每台机器上hadoop.tmp.dir配置指定的文件夹/export/data/hadoopdata。 重新format。 #本方法会导致所有数据丢失,仅适合学习使用。
-
-
-
Hadoop集群启动
-
单节点单进程逐个手动启动
-
HDFS集群
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode -
YARN集群
yarn-daemon.sh start|stop resourcemanager|nodemanager -
优点:精准的控制每个角色每个进程的启停。PS总不能每次都全部启停吧~ 机器多了怎么办启停一下花一整天嘛~~
-
-
脚本一键启动
-
前提:配置好免密登录。ssh
-
HDFS集群
start-dfs.sh stop-dfs.sh -
YARN集群
start-yarn.sh stop-yarn.sh -
更狠的
start-all.sh stop-all.sh [root@node1 ~]# start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
-
-
-
集群进程确认和错误排查
-
确认是否成功
[root@node1 ~]# jps 8000 DataNode 8371 NodeManager 8692 Jps 8264 ResourceManager 7865 NameNode #node2,和node3的jps应该都不一样,需要结合本次设置来看,具体请看上面的hadoop的集群规划我贴图在下面对应看就好啦 -
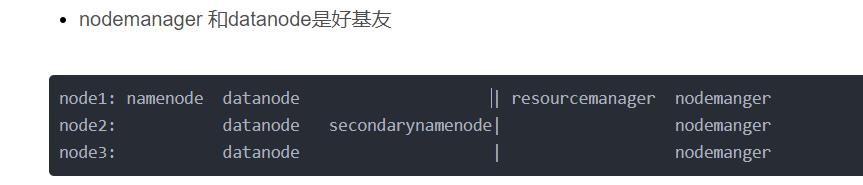
我是集群规划的贴图 -
如果进程不在 看启动运行日志!!!!!!!!!!!!!
#默认情况下 日志目录 cd /export/server/hadoop-2.7.5/logs/ #注意找到对应进程名字 以log结尾的文件
-
Hadoop初体验
-
Hadoop Web UI页面
-
HDFS集群 http://namenode_host:50070
-
YARN集群 http://resourcemanager_host:8088
(如果是根据我的配置安安分分配置的小伙伴可以直接用node1:50070|node1:8088直接网页登录啦~~~)
-
-
初体验
-
体验HDFS文件系统 :本质就是存储文件的 ,和标准文件系统一样吗?
-
也是有目录树结构,也是从根目录开始的。
-
文件是文件、文件夹是文件夹
-
和linux很相似
-
上传小文件好慢。==为什么慢?和分布式有没有关系?==
-
-
体验MapReduce+yarn
-
MapReduce是分布式程序 yarn是资源管理 给程序提供运算资源。 Connecting to ResourceManager
[root@node1 mapreduce]# pwd /export/server/hadoop-2.7.5/share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-2.7.5.jar pi 2 2 -
MapReduce程序本质是java程序 意味着后面你要写代码。
-
MR程序运行首先连接YRAN ResourceManager,连接它干什么的?==要资源==。
-
MR程序好像是两个阶段 ,==先Map 再Reduce==。
-
数据量这么小的情况下,为什么MR这么慢? MR适合处理大数据场景还是小数据场景?
-
-
Hadoop辅助功能
-
MapReduce jobhistory服务
-
背景
默认情况下,yarn上关于MapReduce程序执行历史信息 一旦yarn重启 就会消失。 -
功能
保存yarn上MapReduce的历史信息。 -
配置
-
因为需求修改配置。==重启hadoop集群==才能生效。
vim mapred-site.xml <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> -
scp同步给其他机器
scp /export/server/hadoop-2.7.5/etc/hadoop/mapred-site.xml node2:/export/server/hadoop-2.7.5/etc/hadoop/ scp /export/server/hadoop-2.7.5/etc/hadoop/mapred-site.xml node3:/export/server/hadoop-2.7.5/etc/hadoop/ -
重启hadoop集群
-
自己手动启停jobhistory服务。
[root@node1 ~]# mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /export/server/hadoop-2.7.5/logs/mapred-root-historyserver-node1.itcast.cn.out [root@node1 ~]# jps 13794 JobHistoryServer 13060 DataNode 12922 NameNode 13436 NodeManager 13836 Jps 13327 ResourceManager mr-jobhistory-daemon.sh stop historyserver
-
-
-
HDFS 垃圾桶机制
-
背景 在windows叫做回收站 后悔药
在默认情况下 hdfs没有垃圾桶 意味着删除操作直接物理删除文件。 [root@node1 ~]# hadoop fs -rm /itcast/1.txt 21/05/23 16:49:42 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /itcast/1.txt -
功能:和回收站一种 在删除数据的时候 先去垃圾桶 如果后悔可以复原。
-
配置
在core-site.xml中开启垃圾桶机制 指定保存在垃圾桶的时间。 <property> <name>fs.trash.interval</name> <value>1440</value> </property> -
集群同步配置 重启hadoop服务。
[root@node1 hadoop]# pwd /export/server/hadoop-2.7.5/etc/hadoop [root@node1 hadoop]# scp core-site.xml node2:$PWD core-site.xml 100% 1027 898.7KB/s 00:00 [root@node1 hadoop]# scp core-site.xml node3:$PWD core-site.xml -
垃圾桶使用
-
配置好之后 再删除文件 直接进入垃圾桶
[root@node1 ~]# hadoop fs -rm /itcast.txt 21/05/23 16:55:25 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1440 minutes, Emptier interval = 0 minutes. 21/05/23 16:55:25 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1:8020/itcast.txt' to trash at: hdfs://node1:8020/user/root/.Trash/Current/itcast.txt -
垃圾桶的本质就是hdfs上的一个隐藏目录。
hdfs://node1:8020/user/用户名/.Trash/Current -
后悔了 需要恢复怎么做?
hadoop fs -cp /user/root/.Trash/Current/itcast.txt / -
就想直接删除文件怎么做?
hadoop fs -rm -skipTrash /itcast.txt [root@node1 ~]# hadoop fs -rm -skipTrash /itcast.txt Deleted /itcast.txt
-
-
扩展
-
配置web UI页面访问身份
-
core-site.xml
<!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> -
-
关于Hadoop源码编译
-
核心:联网下载jar pom的能力。
-
以上是关于hadoop离线day02--Apache Hadoop的主要内容,如果未能解决你的问题,请参考以下文章
hadoop离线day05--Hadoop MapReduce
hadoop离线day05--Hadoop MapReduce
hadoop离线day04--Hadoop MapReduce
hadoop离线day06--Hadoop MapReduceHDFS高阶