SVM预测基于SVM进行股票预测matlab源码
Posted Matlab咨询QQ1575304183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SVM预测基于SVM进行股票预测matlab源码相关的知识,希望对你有一定的参考价值。
一、简介
先回顾一下在基本线性可分情况下的SVM模型:
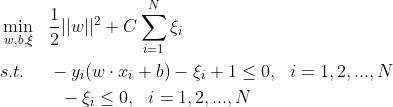
分类svm模型中要让训练集中的各个样本点尽量远离自己类别一侧的支持向量。
其实回归模型也沿用了最大间隔分类器的思想。
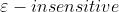 误差函数
误差函数
对于回归模型,优化目标函数和分类模型保持一致,依然是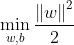 ,但是约束条件不同。我们知道回归模型的目标是让训练集中的每个样本点
,但是约束条件不同。我们知道回归模型的目标是让训练集中的每个样本点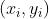 ,尽量拟合到一个线性模型
,尽量拟合到一个线性模型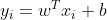 上。对于一般的回归模型,我们是用均方误差作为损失函数的,但SVM不是这样定义损失函数的。
上。对于一般的回归模型,我们是用均方误差作为损失函数的,但SVM不是这样定义损失函数的。
SVM回归算法采用误差函数,误差函数定义为,如果预测值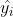 与真实值
与真实值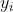 之间的差值
之间的差值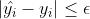 ,则不产生损失,否则,损失代价为
,则不产生损失,否则,损失代价为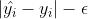 。
。
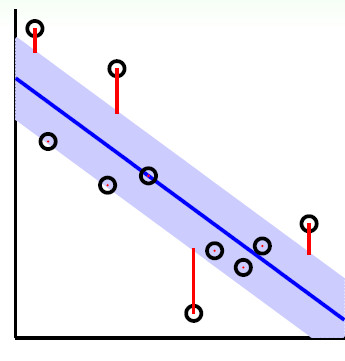
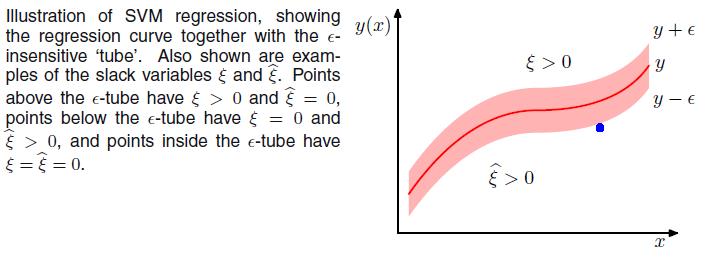
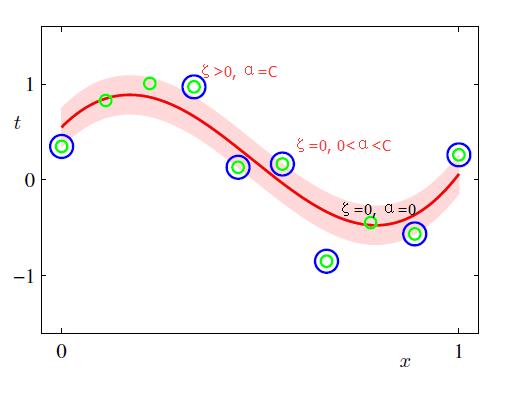
如下图所示,在蓝色带里面的点都是没有损失的,但是外面的点是有损失的,损失大小为红色线的长度。
总结一下,SVM回归模型的损失函数度量为:
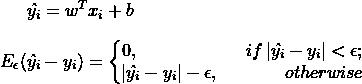
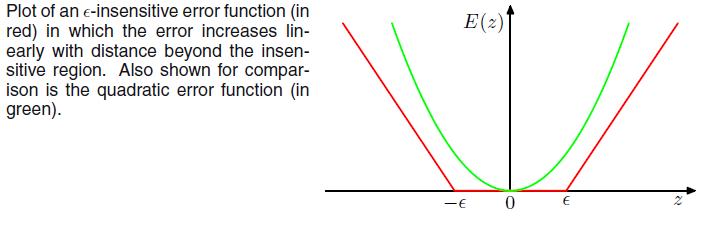
下图为误差函数与平方误差函数的图形
目标函数
观察上述的 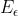 误差函数的形式,可以看到,实际形成了一个类似管道的样子,在管道中样本点,不做惩罚,所以被称为
误差函数的形式,可以看到,实际形成了一个类似管道的样子,在管道中样本点,不做惩罚,所以被称为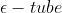 ,如下图阴影红色部分
,如下图阴影红色部分
采用 替代平方误差项,因此可以定义最小化误差函数作为优化目标:
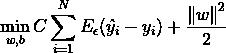
这个损失函数与从最大间隔分类推过来的不太相似,可以参考我写的从LR到SVM这篇文章,将二分类的Hinge Loss换成误差函数就可以了。
由于上述目标函数含有绝对值项不可微。我们可以转化成一个约束优化问题,常用的方法是为每一个样本数据定义两个松弛变量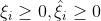 ,表示度量真实值 与的距离。
,表示度量真实值 与的距离。
当样本点真实值 位于管道上方时,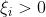 ,写成表达式:
,写成表达式: 时,,
时,,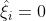 ;
;
当样本点真实值 位于管道下方时,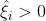 ,写成表达式:
,写成表达式: 时,
时,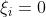 ,;
,;
因此使得每个样本点位于管道内部的条件为:
当 位于管道上方时,,有
当 位于管道下方时,,有
误差函数可以写为一个凸二次优化问题:
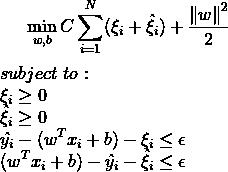
拉格朗日对偶
和SVM分类模型一样,我们也可以用拉格朗日函数将目标优化函数变成无约束的形式:
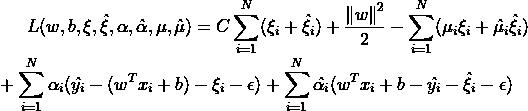
其中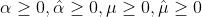 是拉格朗日的系数。
是拉格朗日的系数。
满足约束下 max L= f ,拉格朗日系数都为0,min max L=min f。若不满足约束max L=无穷大,min max L无解。即min max L在约束内的解就是min f 的解。在约束外无解。因此求解min max L得到的解就是在约束内min f的解.
求解问题转化为min max L,对偶问题为max min L.先对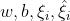 求偏导数:
求偏导数:
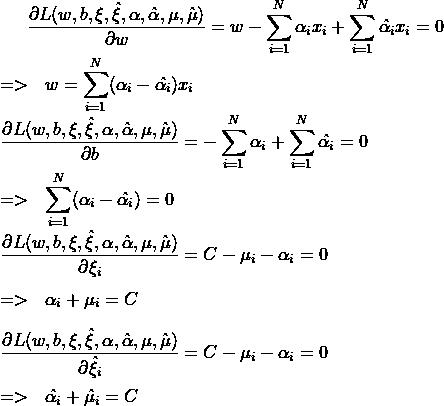
带回到拉格朗日函数中去,化简得到只关于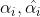 的函数,目标即最大化此函数。
的函数,目标即最大化此函数。
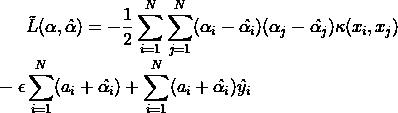
约束条件为:
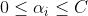
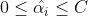
其中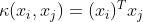 为向量内积。现在为线性核,也可以更换为高斯核之类的非线性核函数。
为向量内积。现在为线性核,也可以更换为高斯核之类的非线性核函数。
下面考虑KKT条件:
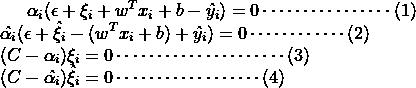
由式(1),(2)知:
当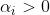 时,必有
时,必有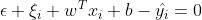 ,
,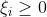 ,这些点位于管道上方边界处,或者管道上面。 预测值比真实值小了。
,这些点位于管道上方边界处,或者管道上面。 预测值比真实值小了。
当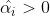 时,必有
时,必有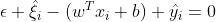 ,
,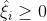 ,这些点位于管道下方边界处,或者管道下面。 预测值比真实值大了。
,这些点位于管道下方边界处,或者管道下面。 预测值比真实值大了。
同时,由式(1),(2)知,对于任意一个数据点,由于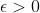 ,则不可能同时都大于0,而且得到在管道内部的点,必然有
,则不可能同时都大于0,而且得到在管道内部的点,必然有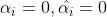 。
。
超平面计算
根据前面的计算已经可以得到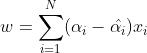
现在来计算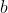 的值
的值
由上述的分析,影响超平面参数的点为位于管道边界处,或者管道外面。
关于的计算,可以考虑在管道上方边界处一个点必然有:
可以解得:

则预测函数为
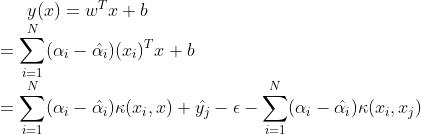
其中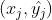 为超平面管道上平面边界上的一点。
为超平面管道上平面边界上的一点。
SVM回归模型系数的稀疏性
可以发现,对于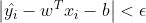 的点
的点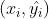 (不包括边界),必有
(不包括边界),必有
此时有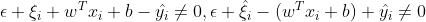 ,要满足KKT条件,则
,要满足KKT条件,则
我们定义样本系数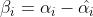 ,根据上面
,根据上面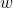 的计算式
的计算式

我们发现此时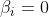 ,也就是说不受这些在误差范围内的点的影响。对于在边界上或者在边界外的点,
,也就是说不受这些在误差范围内的点的影响。对于在边界上或者在边界外的点,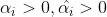 ,此时。
,此时。
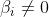 。即只受那些在tube管道边界及管道之外的点影响。同理b也是。
。即只受那些在tube管道边界及管道之外的点影响。同理b也是。
二、源代码
clear;
clc;
%load financial data of the stock price of Apple company
%The data is from Nov 18 1982-Nov 18 2012
%The data contains six collums:Open, High, Low, Close, Volume, Adj Close
sh = dlmread('yahoo.csv');
%The data needs to flip because the data is from latest to earliest.
sh = flipdim(sh,1);
%extract data
[m,n] = size(sh);
ts = sh(2:m,1);
tsx = sh(1:m-1,:);
original = ts(length(sh)*0.7+1:end,:);
% Draw the original graphic of the stock price
figure;
plot(ts,'LineWidth',1);
title('Yahoo Stock Price(1996.4.12-2012.11.16) before mapping','FontSize',12);
grid on;
fprintf('Plot the stock price before mapping.\\n');
fprintf('Program paused. Press enter to continue.\\n');
pause;
%data preprocessing
ts = ts';
tsx = tsx';
% mapminmax is an mapping function in matlab
%Use mapminmax to do mapping
[TS,TSps] = mapminmax(ts);
% The scale of the data from 1 to 2
TSps.ymin = 1;
TSps.ymax = 2;
%normalization
[TS,TSps] = mapminmax(ts,TSps);
% plot the graphic of the stock price after mapping
figure;
plot(TS,'LineWidth',1);
title('Yahoo Stock price after mapping','FontSize',12);
grid on;
fprintf('\\nPlot the stock price after mapping.\\n');
fprintf('Program paused. Press enter to continue.\\n');
pause;
% Transpose the data in order to meet the requirement of libsvm
fprintf('\\n Initializing.......\\n');
TS = TS';
[TSX,TSXps] = mapminmax(tsx);
TSXps.ymin = 1;
TSXps.ymax = 2;
[TSX,TSXps] = mapminmax(tsx,TSXps);
TSX = TSX';
三、运行结果
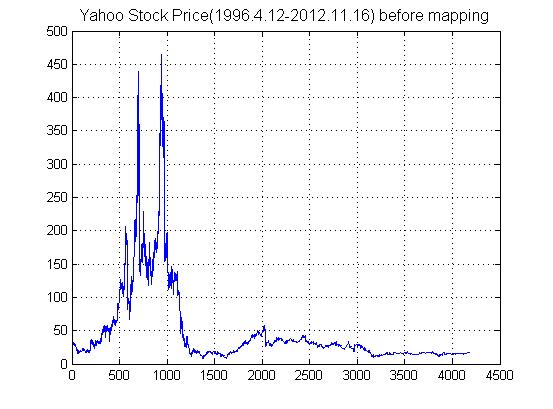
完整代码或仿真咨询QQ1575304183
以上是关于SVM预测基于SVM进行股票预测matlab源码的主要内容,如果未能解决你的问题,请参考以下文章