三天掌握Spark--外部数据源
Posted 一只楠喃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三天掌握Spark--外部数据源相关的知识,希望对你有一定的参考价值。
Spark之外部数据源
Spark与Hbase的交互
Spark可以从外部存储系统读取数据,比如RDBMs表中或者HBase表中读写数据,这也是企业中常常使用,如下两个场景:
1)要分析的数据存储在Hbase中,需要从中读取数据做数据分析
~日志数据:操作日志等
~订单数据
2)使用Spark进行离线分析后,往往将数据保存到mysql中
~ 网站的PV,UV,VV·······
Spark如何从HBase数据库表中读(read:RDD)写(write:RDD)数据呢??
-
~ 加载数据:从HBase表读取数据,封装为RDD,进行处理分析
-
保存数据:将RDD数据直接保存到HBase表中
Spark与HBase表的交互,底层采用就是MapReduce与HBase表的交互。

Spark可以从HBase表中读写(Read/Write)数据,底层采用TableInputFormat和TableOutputFormat方式,与MapReduce与HBase集成完全一样,使用输入格式InputFormat和输出格式OutputFoamt。
外部数据源之HBase Sink
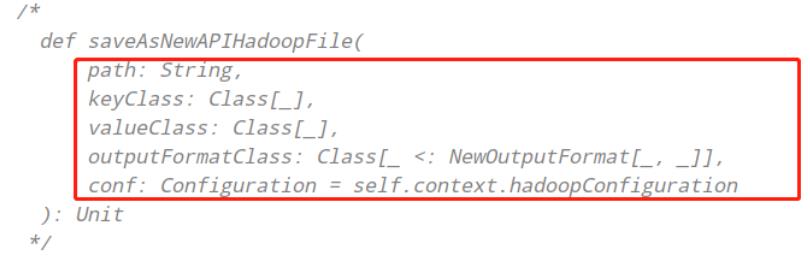
写 入 数 据 时 , 需 要 将 RDD 转 换 为
RDD[(ImmutableBytesWritable, Put)]类 型 , 调 用
saveAsNewAPIHadoopFile方法数据保存至HBase表中。
HBase Client连接时,需要设置依赖Zookeeper地址相关信息及表的名称,通过Configuration设置属性值进行传递。

外部数据源之HBase Source
当我们用MapReduce读取HBase数据时,使用TableMapper,其中,InputFormat为
TableInputFormat,读取数据Key:ImmutableBytesWritable,Value:Result。

从HBase表读取数据时,同样需要设置依赖Zookeeper地址信息和表的名称,使用Configuration
设置属性,形式如下:

此外,读取的数据封装到RDD中,Key和Value类型分别为:ImmutableBytesWritable和Result,不支持Java Serializable导致处理数据时报序列化异常。
设置Spark Application使用Kryo序列化,性能要比Java 序列化要好,创建SparkConf对象设置相关属性,如下所示:

外部数据源之MySQL
概述
实际开发中常常将分析结果RDD保存至MySQL表中,使用foreachPartition函数;
调用RDD#foreachPartition函数将每个分区数据保存至MySQL表中,保存时考虑降低RDD分区数目和批量插入,提升程序性能。
MySQL Sink
将数据保存到Mysql中
版本一:
/**
* 定义一个方法,将RDD中分区数据保存至MySQL表,第一个版本
*/
def saveToMySQL(iter: Iterator[(String, Int)]): Unit = {
// step1. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// step2. 创建连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true",
"root",
"123456"
)
pstmt = conn.prepareStatement("INSERT INTO db_test.tb_wordcount (word, count) VALUES(?, ?)")
// step3. 插入数据
iter.foreach{case (word, count) =>
pstmt.setString(1, word)
pstmt.setInt(2, count)
pstmt.execute()
}
}catch {
case e: Exception => e.printStackTrace()
}finally {
// step4. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
在这个版本中,有一个问题:每个分区插入数据时,都是一条一条插入,没有进行批量插入
版本二
/**
* 定义一个方法,将RDD中分区数据保存至MySQL表,第二个版本
*/
def saveToMySQL(iter: Iterator[(String, Int)]): Unit = {
// step1. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// step2. 创建连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true",
"root",
"123456"
)
pstmt = conn.prepareStatement("INSERT INTO db_test.tb_wordcount (word, count) VALUES(?, ?)")
// step3. 插入数据
iter.foreach{case (word, count) =>
pstmt.setString(1, word)
pstmt.setInt(2, count)
//pstmt.executeUpdate();
// TODO: 加入一个批次中
pstmt.addBatch()
}
// TODO:批量执行批次
pstmt.executeBatch()
}catch {
case e: Exception => e.printStackTrace()
}finally {
// step4. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
根据这两个版本的代码,还可以优化的点为:
手动提交事务,将每个分区数据保存时,要么都成功,要么都失败
插入语句INSERT语句 INSERT INTO db_test.tb_wordcount (word, count) VALUES(?, ?)不能实现主键存在时更新数据,不存在时插入数据功能。REPLACE INTO db_test.tb_wordcount (word, count) VALUES(?, ?)
/**
* 定义一个方法,将RDD中分区数据保存至MySQL表,第三个版本
*/
def saveToMySQL(iter: Iterator[(String, Int)]): Unit = {
// step1. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// step2. 创建连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true",
"root",
"123456"
)
pstmt = conn.prepareStatement("replace INTO db_test.tb_wordcount (word, count) VALUES(?, ?)")
// TODO: 考虑事务性,一个分区数据要全部保存,要不都不保存
val autoCommit: Boolean = conn.getAutoCommit // 获取数据库默认事务提交方式
conn.setAutoCommit(false)
// step3. 插入数据
iter.foreach{case (word, count) =>
pstmt.setString(1, word)
pstmt.setInt(2, count)
// TODO: 加入一个批次中
pstmt.addBatch()
}
// TODO:批量执行批次
pstmt.executeBatch()
conn.commit() // 手动提交事务,进行批量插入
// 还原数据库原来事务
conn.setAutoCommit(autoCommit)
}catch {
case e: Exception => e.printStackTrace()
}finally {
// step4. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
以上是关于三天掌握Spark--外部数据源的主要内容,如果未能解决你的问题,请参考以下文章