3天掌握Spark--Standalone集群
Posted 一只楠喃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3天掌握Spark--Standalone集群相关的知识,希望对你有一定的参考价值。
Spark之Standalone集群
架构组成
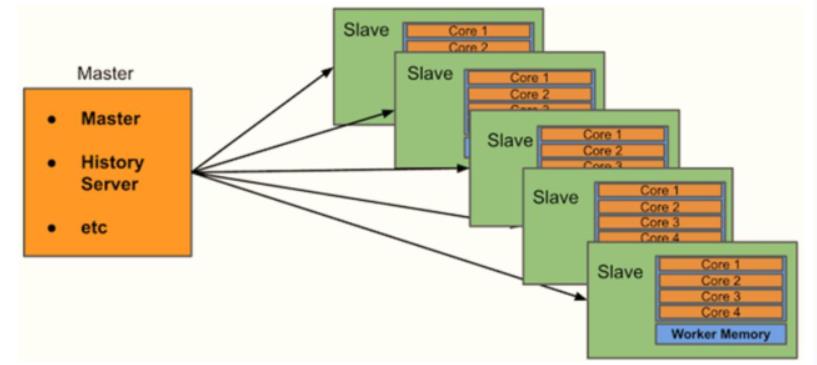
Spark Stanadlone集群类似Hadoop YARN集群功能,管理整个集群中资源(CUP Core核数、内存Memory、磁盘Disk、网络带宽等)
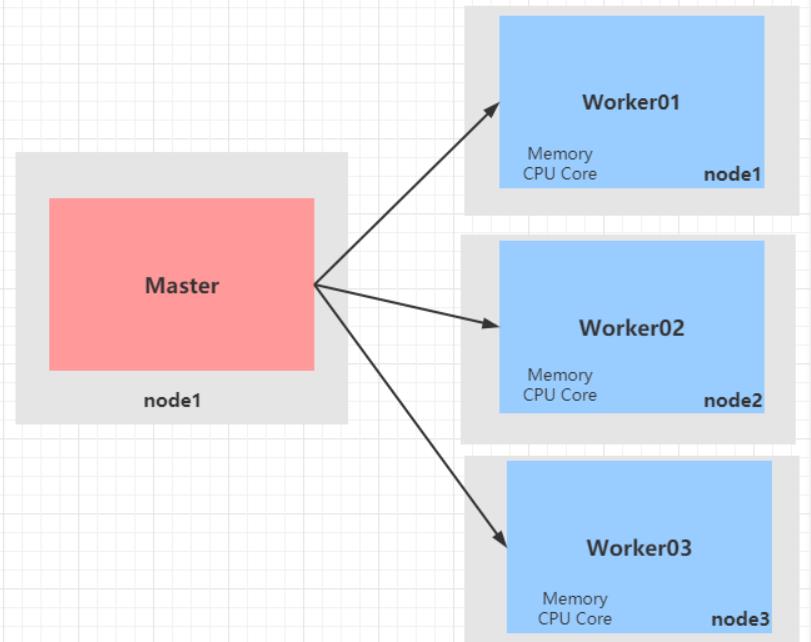
Standalone集群使用了分布式计算中的master-slave模型,master是集群中含有Master进程的节点,slave是集群中的Worker节点含有Executor进程。
-
Standalone集群主从架构:Master-Slave
-
主节点:老大,管理者,
Master -
从节点:小弟,干活的,
Workers -
Spark Standalone集群,类似Hadoop YARN,管理集群资源和调度资源: -
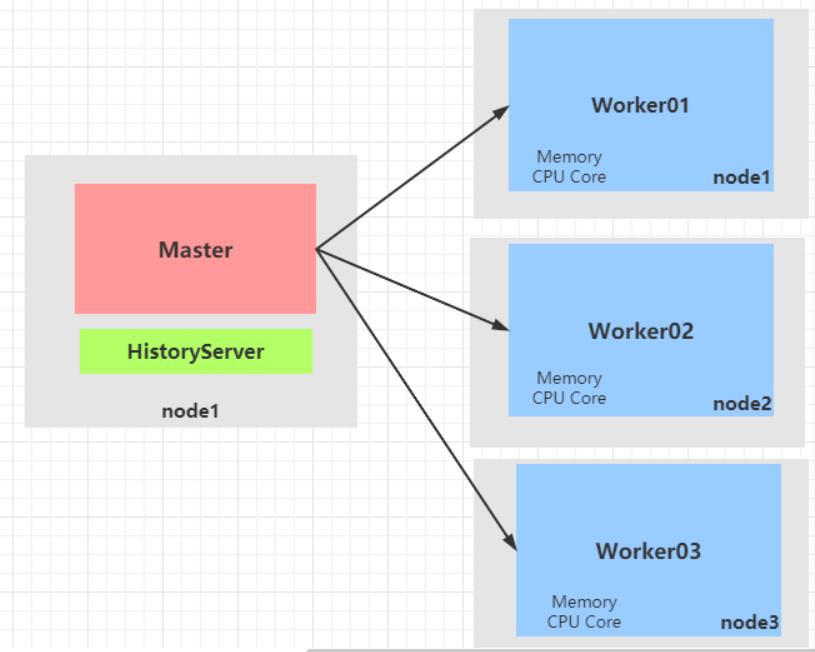
Master,管理整个集群资源,接收提交应用,分配资源给每个应用,运行Task任务
-
Worker,管理每个机器的资源,分配对应的资源来运行Task;每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数
-
HistoryServer,Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查
看应用运行相关信息。
配置和部署
当前使用三台虚拟机

服务启动和运行应用
在Master节点node1上启动,进入$SPARK_HOME,必须配置主节点到所有从节点的`SSH无密钥`登录,集群各个机器`时间同步`。
- 主节点Master启动命令
[root@node1 ~]# /export/server/spark/sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /export/server/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-node1.itcast.cn.out
[root@node1 ~]#
[root@node1 ~]# jps
15076 DataNode
15497 Master
15545 Jps
14973 NameNode
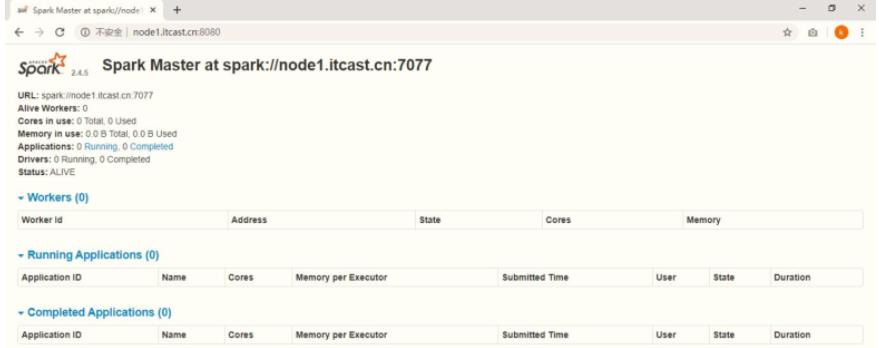
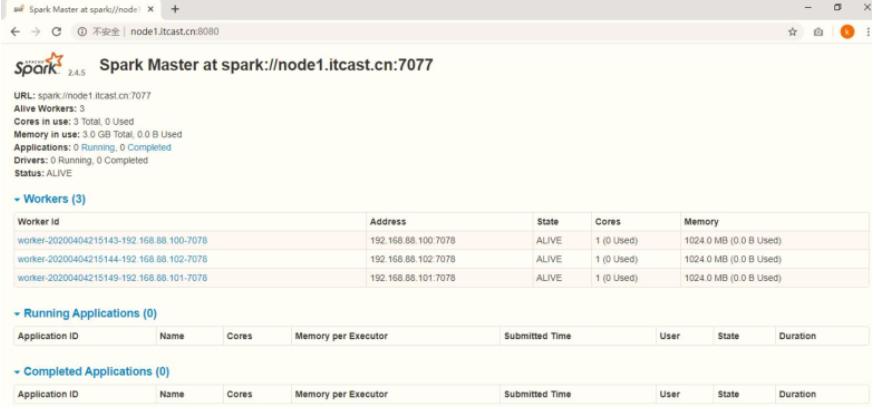
WEB UI页面地址:http://node1:8080
- 从节点Workers启动命令
/export/server/spark/sbin/start-slaves.sh
- 历史服务器HistoryServer
/export/server/spark/sbin/start-history-server.sh
WEB UI页面地址:http://node1:18080
将上述运行在Local Mode的圆周率PI程序,运行在Standalone集群上,修改【
--master】地址为Standalone集群地址:spark://node1.itcast.cn:7077,具体命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \\
--master spark://node1.itcast.cn:7077 \\
--class org.apache.spark.examples.SparkPi \\
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \\
10
查看Master主节点WEB UI界面:
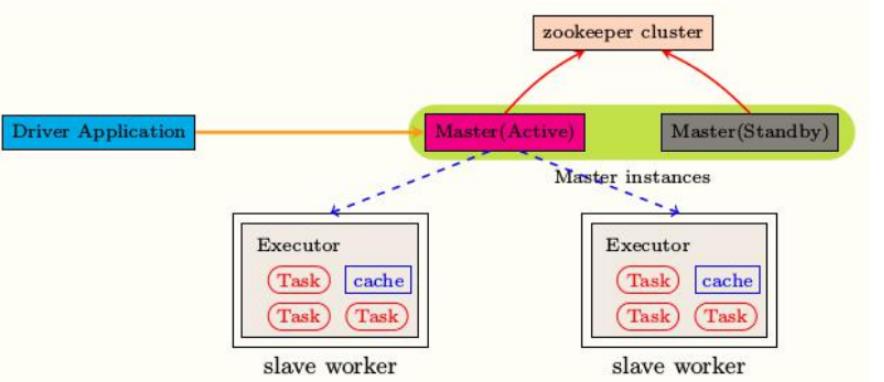
Spark 应用架构组成
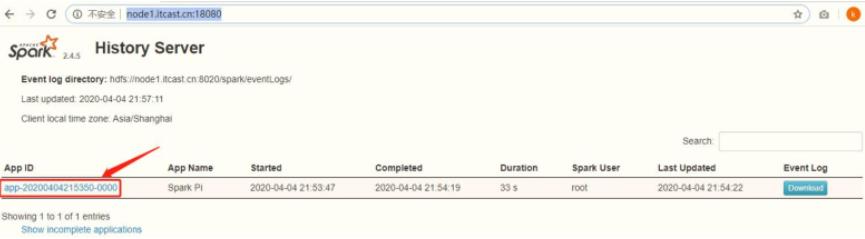
登录到Spark HistoryServer历史服务器WEB UI界面,点击刚刚运行圆周率PI程序:
切换到【Executors】Tab页面:
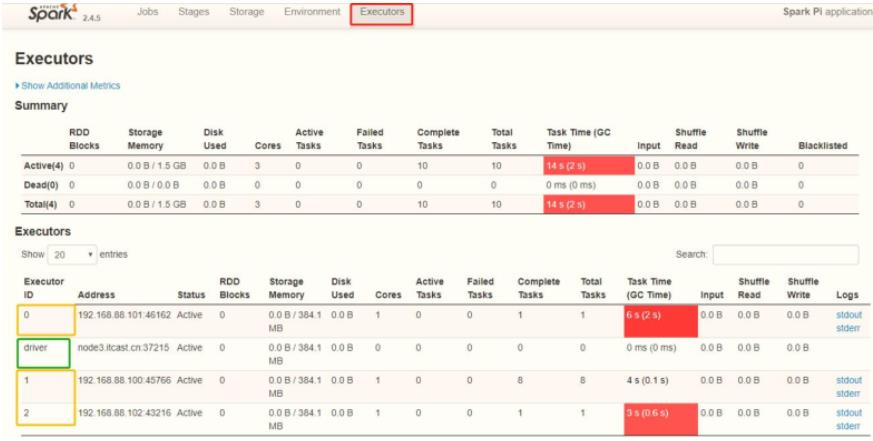
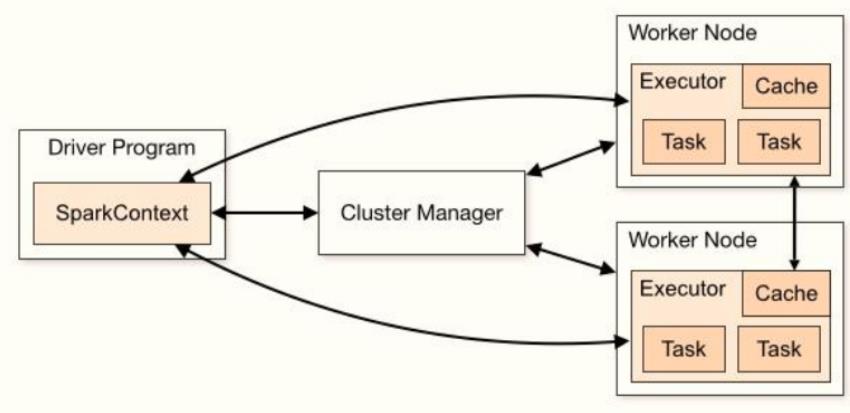
从图中可以看到Spark Application运行到集群上时,由两部分组成:Driver Program和Executors
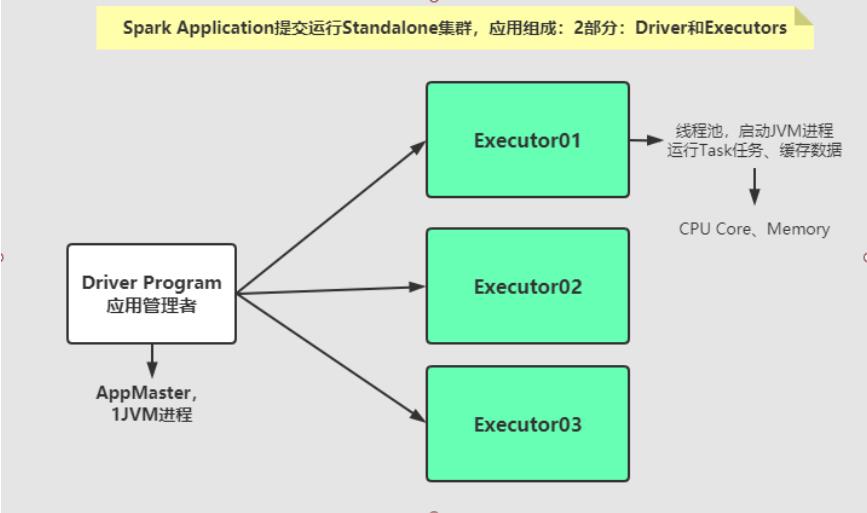
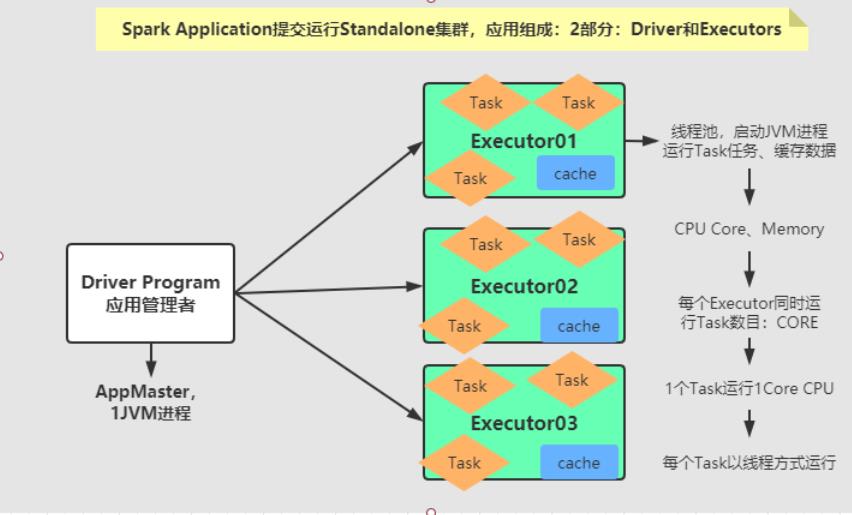
每个Executor相当于线程池,每个线程运行Task任务,需要1Core CPU。
- 一、
Driver Program- 相当于AppMaster,整个应用管理者,负责应用中所有Job的调度执行;
- 运行JVM Process,运行程序的MAIN函数,必须创建SparkContext上下文对象;
- 一个SparkApplication仅有一个;
- 第二、
Executors- 相当于一个线程池,运行JVM Process,其中有很多线程,每个线程运行一个Task任务,
一个Task运行需要1 Core CPU,所有可以认为Executor中线程数就等于CPU Core核数; - 一个Spark Application可以有多个,可以设置个数和资源信息;
-
- 相当于一个线程池,运行JVM Process,其中有很多线程,每个线程运行一个Task任务,
Spark 应用WEB UI 监控
Spark 提供了多个监控界面,当运行Spark任务后可以直接在网页对各种信息进行监控查看。
/export/server/spark/bin/spark-shell --master spark://node1:7077
在spark-shell中执行词频统计WordCount程序代码,运行如下:
val inputRDD = sc.textFile("/datas/wordcount.data")
val wordcountsRDD = inputRDD.flatMap(line => line.split("\\\\s+")).map(word => (word, 1)).reduceByKey((tmp, item) => tmp +item)
wordcountsRDD.take(5)
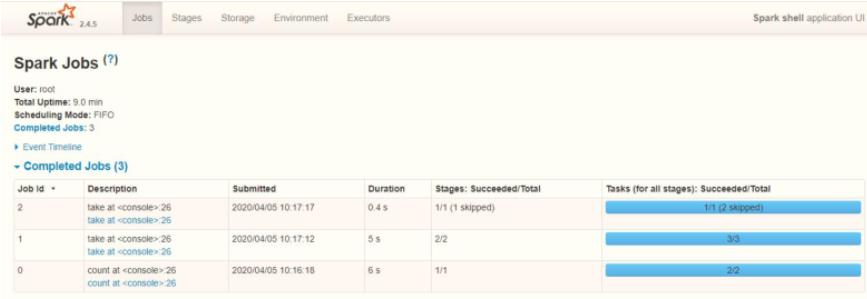
可以发现在一个Spark Application中,包含多个Job,每个Job有多个Stage组成,每个Job执行按照DAG图进行的。
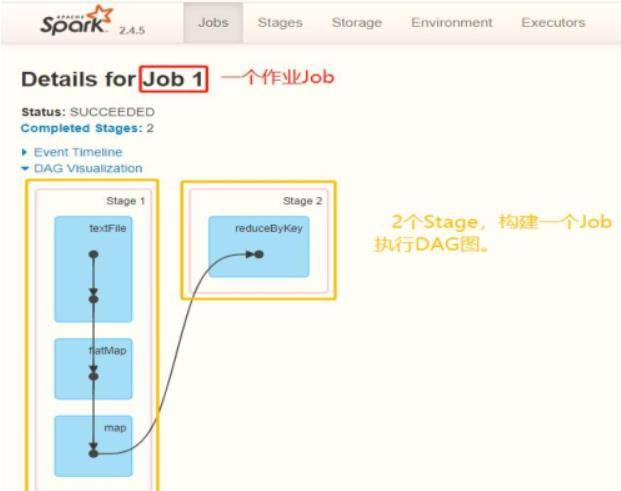
其中每个Stage中包含多个Task任务,每个Task以线程Thread方式执行,需要1Core CPU。
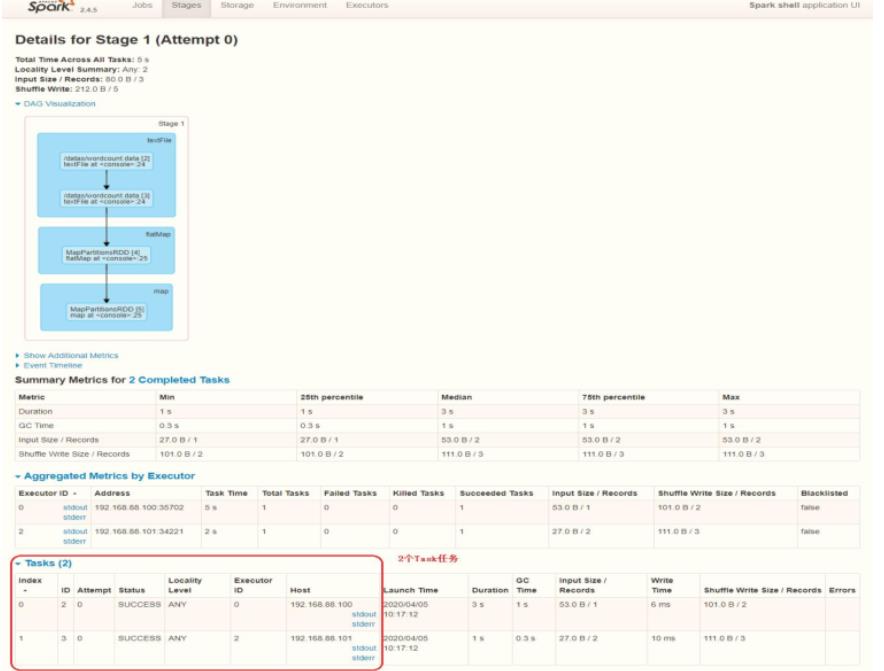
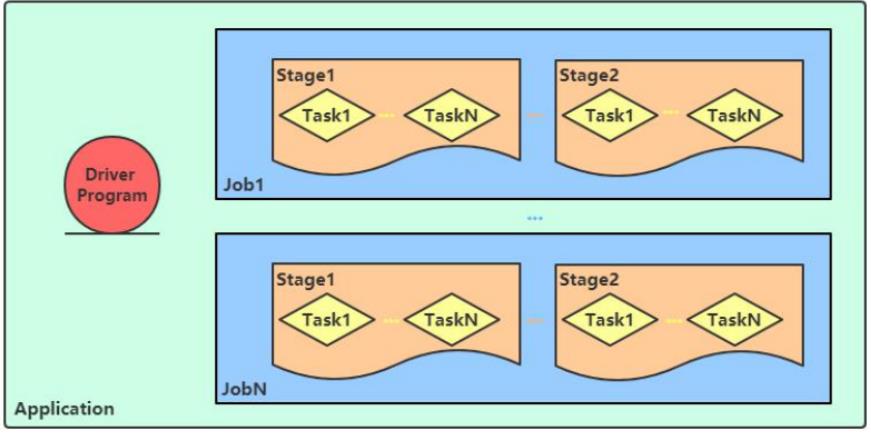
Spark Application程序运行时三个核心概念:Job、Stage、Task,说明如下

Job和Stage及Task之间关系:
Standalone HA
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF:single Point of Failover)的问题。
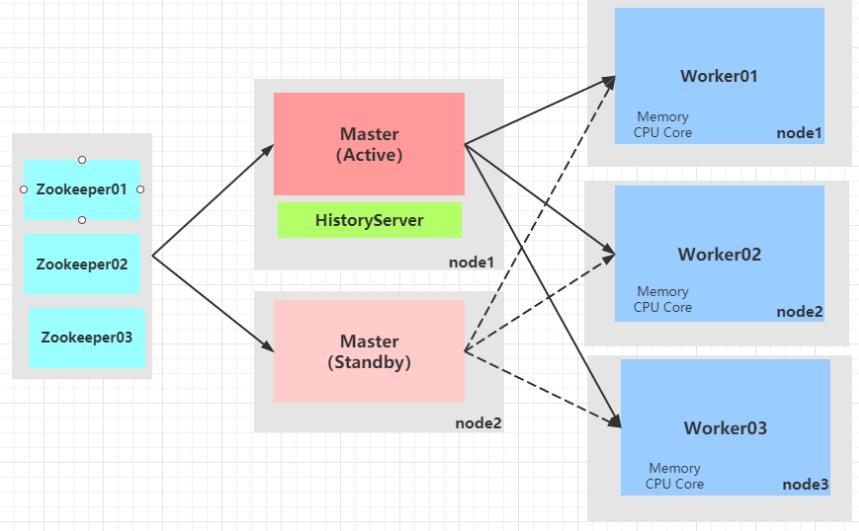
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。
使用Zookeeper集群:选举leader、监控leader
基于Zookeeper实现HA:http://spark.apache.org/docs/2.4.5/spark-standalone.html#high-availability
点个赞嘛!

以上是关于3天掌握Spark--Standalone集群的主要内容,如果未能解决你的问题,请参考以下文章