3天掌握Spark-- RDD函数
Posted 一只楠喃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3天掌握Spark-- RDD函数相关的知识,希望对你有一定的参考价值。
Spark之RDD函数
RDD 函数分类
RDD 的操作主要可以分为
Transformation和Action两种。
Transformation转换,将1个RDD转换为另一个RDDAction触发,当1个RDD调用函数以后,触发一个Job执行(调用Action函数以后,返回值不是RDD)


RDD中2种类型操作函数:Transformation(lazy)和Action(eager)函数
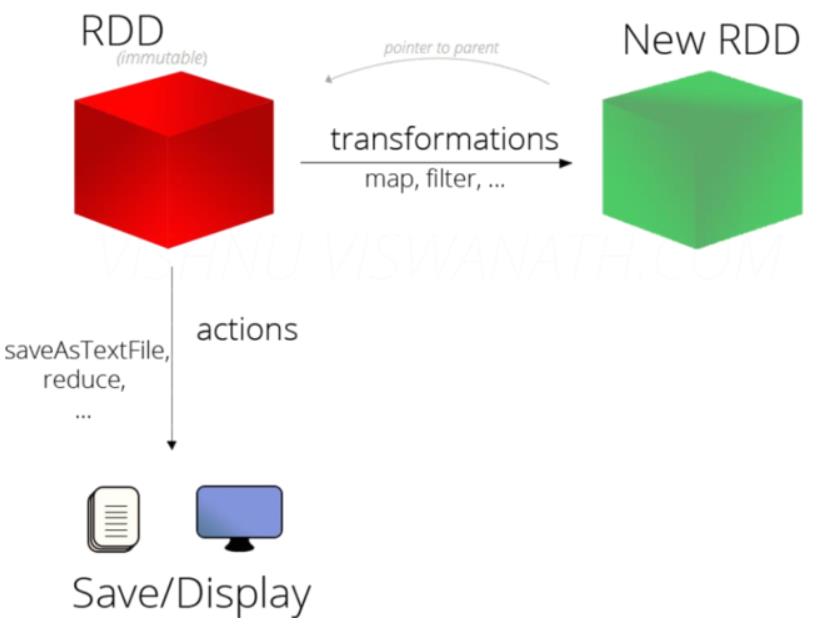
Transformation转换函数

Action触发函数,触发一个Job执行

RDD 中常见函数概述
RDD中包含很多函数,主要可以分为两类:Transformation转换函数和Action函数。
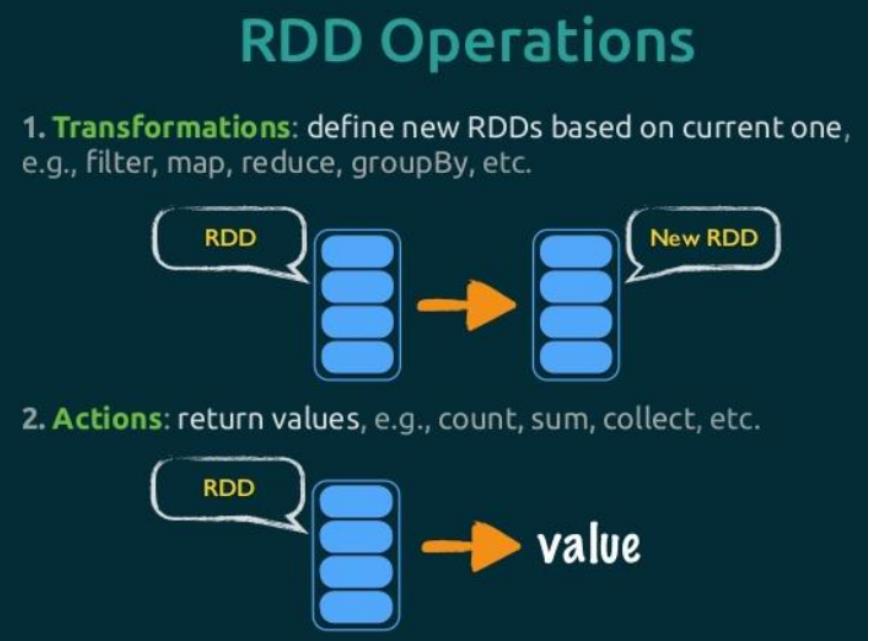
主要常见使用函数如下,每个函数通过演示范例讲解。
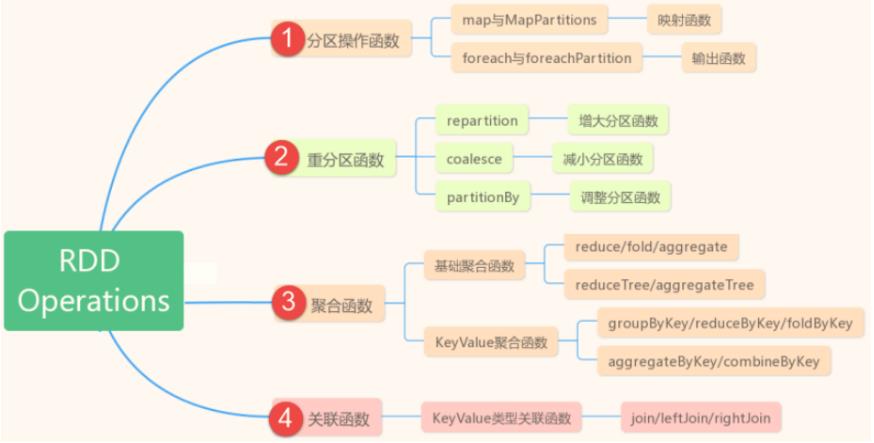
1、分区操作函数
对RDD中每个分区数据进行操作
2、重分区函数
调整RDD中分区数目,要么变大,要么变小
3、聚合函数
对RDD中数据进行聚合统计,比如使用reduce、redueBykey等
4、关联函数
对2个RDD进行JOIN操作,类似SQL中JOIN,分为:等值JOIN、左外连接和右外连接、全外连接fullOuterJoin
RDD 函数之基本函数使用
RDD中map、filter、flatMap及foreach等函数为最基本函数,都是对RDD中`每个元素进行操作,将元素传递到函数中进行转换`。

编写词频统计WordCount程序,使用基本函数
/**
* 演示RDD中基本函数使用
*/
object _01SparkBasicTest {
def main(args: Array[String]): Unit = {
// 创建SparkContext实例对象,传递SparkConf对象,设置应用配置信息
val sc: SparkContext = {
// a. 创建SparkConf对象
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// b. 传递sparkConf对象,构建SparkContext实例
SparkContext.getOrCreate(sparkConf)
}
// step1. 读取数据
val inputRDD: RDD[String] = sc.textFile("datas/wordcount/input.data", minPartitions = 2)
// step2. 处理数据
val resultRDD: RDD[(String, Int)] = inputRDD
// 过滤数据
.filter(line => null != line && line.trim.length > 0)
// 分割单词
.flatMap(line => line.trim.split("\\\\s+"))
// 转换为二元组
.map(word => word -> 1)
// 按照单词分组,对组内数据进行聚合求和
.reduceByKey((tmp, item) => tmp + item) // TODO: 隐式转换,将RDD对象抓好为PairRDDFunctions对象,调用方法
// step3. 输出数据
resultRDD.foreach(item => println(item))
// 应用结束,关闭资源
sc.stop()
}
}
RDD 函数之分区操作函数
每个RDD由多分区组成的,实际开发建议对每个分区数据的进行操作,map函数使用mapPartitions代替、foreach函数使用foreachPartition代替。
[前面编写WordCount词频统计代码中,使用map函数和forearch函数,针对RDD中每个元素操作,并不是针对每个分区数据操作的,如果针对分区操作:mapPartitions和foreachPartition]
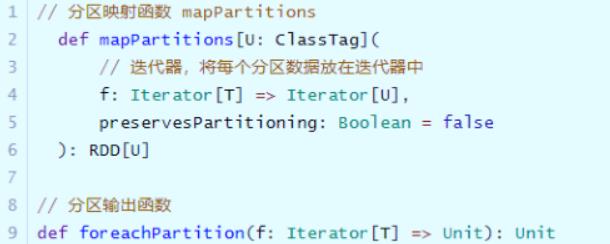
针对分区数据进行操作时,函数的参数类型:迭代器Iterator,封装分区中所有数据
针对词频统计WordCount代码进行修改,针对分区数据操作,范例代码如下:
/**
* 分区操作函数:mapPartitions和foreachPartition
*/
object _02SparkIterTest {
def main(args: Array[String]): Unit = {
// 创建SparkContext实例对象,传递SparkConf对象,设置应用配置信息
val sc: SparkContext = {
// a. 创建SparkConf对象
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// b. 传递sparkConf对象,构建SparkContext实例
SparkContext.getOrCreate(sparkConf)
}
// step1. 读取数据
val inputRDD: RDD[String] = sc.textFile("datas/wordcount.data", minPartitions = 2)
// step2. 处理数据
val resultRDD: RDD[(String, Int)] = inputRDD
// 过滤数据
.filter(line => line.trim.length != 0 )
// 对每行数据进行单词分割
.flatMap(line => line.trim.split("\\\\s+"))
// 转换为二元组
//.map(word => word -> 1)
/*
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false
): RDD[U]
*/
.mapPartitions(iter => iter.map(word => (word, 1)))
// 分组聚合
.reduceByKey((tmp, item) => tmp + item)
// step3. 输出数据
//resultRDD.foreach(item => println(item))
/*
def foreachPartition(f: Iterator[T] => Unit): Unit
*/
resultRDD.foreachPartition(iter => iter.foreach(item => println(item)))
// 应用结束,关闭资源
sc.stop()
}
}
分区操作的好处

RDD 函数之重分区函数
如何对RDD中分区数目进行调整(增加分区或减少分区),在RDD函数中主要有如下三个函数。
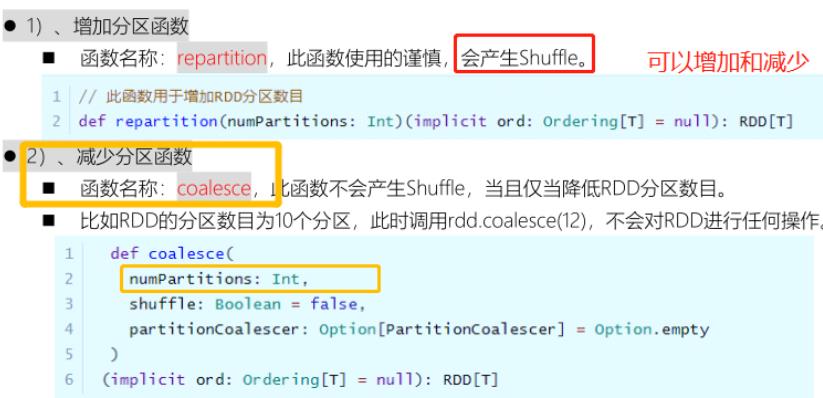
上述2个函数最为关键:
- 增加RDD分区数目:repartition
- 减少RDD分区数目:coalesce,不产生Shuffle
/**
* 分区操作函数:mapPartitions和foreachPartition
*/
object _02SparkPartitionTest {
def main(args: Array[String]): Unit = {
// 创建SparkContext实例对象,传递SparkConf对象,设置应用配置信息
val sc: SparkContext = {
// a. 创建SparkConf对象
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// b. 传递sparkConf对象,构建SparkContext实例
SparkContext.getOrCreate(sparkConf)
}
// step1. 读取数据
val inputRDD: RDD[String] = sc.textFile("datas/wordcount.data", minPartitions = 2)
println(s"raw rdd partitions = ${inputRDD.getNumPartitions}")
// TODO: 增加RDD分区数目
val etlRDD: RDD[String] = inputRDD.repartition(3)
println(s"etl rdd partitions = ${etlRDD.getNumPartitions}")
// step2. 处理数据
val resultRDD: RDD[(String, Int)] = inputRDD
// 过滤数据
.filter(line => line.trim.length != 0 )
// 对每行数据进行单词分割
.flatMap(line => line.trim.split("\\\\s+"))
// 转换为二元组
//.map(word => word -> 1)
/*
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false
): RDD[U]
*/
.mapPartitions(iter => iter.map(word => (word, 1)))
// 分组聚合
.reduceByKey((tmp, item) => tmp + item)
// step3. 输出数据
//resultRDD.foreach(item => println(item))
/*
def foreachPartition(f: Iterator[T] => Unit): Unit
*/
// TODO: 降低结果RDD分区数目
val outputRDD: RDD[(String, Int)] = resultRDD.coalesce(1)
println(s"output rdd partitions = ${outputRDD.getNumPartitions}")
outputRDD.foreachPartition(iter => iter.foreach(item => println(item)))
// 应用结束,关闭资源
sc.stop()
}
}
调整分区的场景

RDD 函数之RDD 中聚合函数
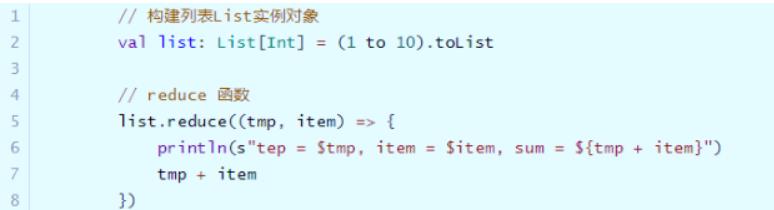
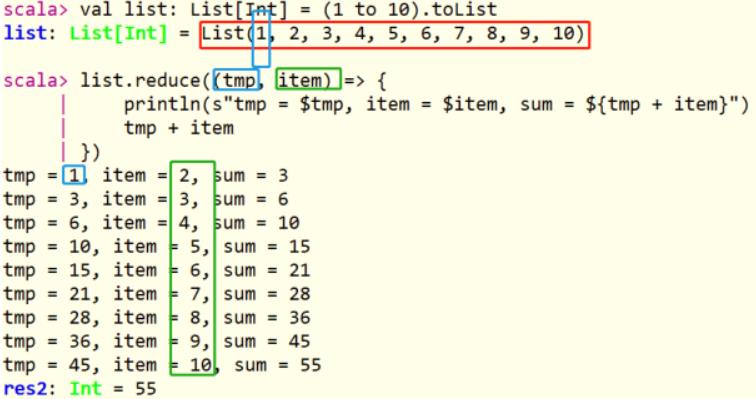
查看列表List中聚合函数reduce和fold源码如下:

通过代码,看看列表List中聚合函数使用:
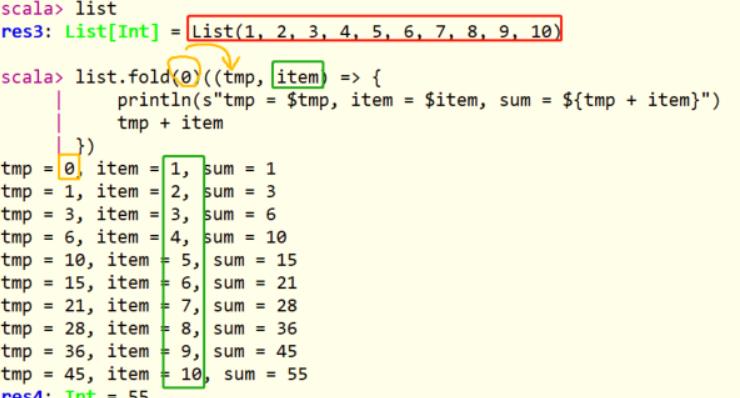
fold聚合函数,比reduce聚合函数,多提供一个可以初始化聚合中间临时变量的值参数:
聚合操作时,往往聚合过程中需要中间临时变量(到底时几个变量,具体业务而定),如下案例

在RDD中提供类似列表List中聚合函数reduce和fold,查看如下:

RDD 函数之PairRDDFunctions 聚合函数
在Spark中有一个object对象
PairRDDFunctions,主要针对RDD的数据类型是Key/Value对的数据提供函数,方便数据分析处理。比如使用过的函数:reduceByKey、groupByKey等。
*ByKey函数:将相同Key的Value进行聚合操作的,省去先分组再聚合。
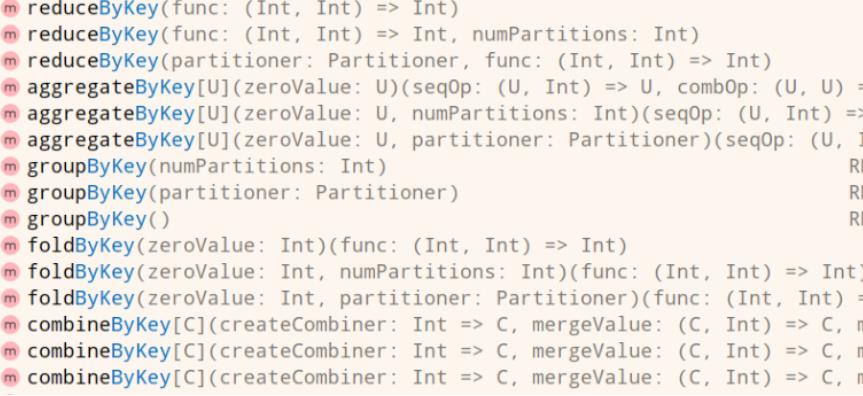
第一类:分组函数groupByKey

第二类:分组聚合函数reduceByKey和foldByKey

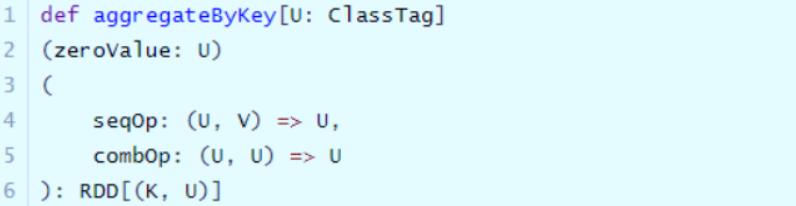
第三类:分组聚合函数aggregateByKey
RDD 函数之关联JOIN函数
当两个RDD的数据类型为二元组Key/Value对时,可以依据Key进行关联Join。

RDD中关联JOIN函数都在PairRDDFunctions中
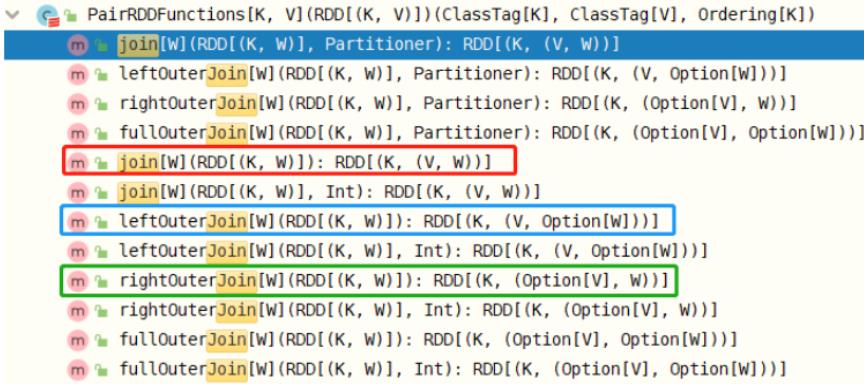
具体看一下join(等值连接)函数说明:

以上是关于3天掌握Spark-- RDD函数的主要内容,如果未能解决你的问题,请参考以下文章