小白爬虫(爬虫获取妹纸图片,附加完整代码)
Posted 韶光不负
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白爬虫(爬虫获取妹纸图片,附加完整代码)相关的知识,希望对你有一定的参考价值。
没有什么别的想法,就只是人我心情愉悦,哈哈哈哈,懂得都懂,小编就不继续说下起了,感觉车开远了,回归正题。下面开始上干货。
目录
千里之行,始于足下,我们先找到一个目标。(小编百度搜索了一个,地址:妹纸图片)
果然,就是让人心情愉悦,下面可以点击鼠标右键检查或者f12查看源代码,让我们看看这些小姐姐图片放在那里,点击绿色部分更快让我们找到我们需要都内容。
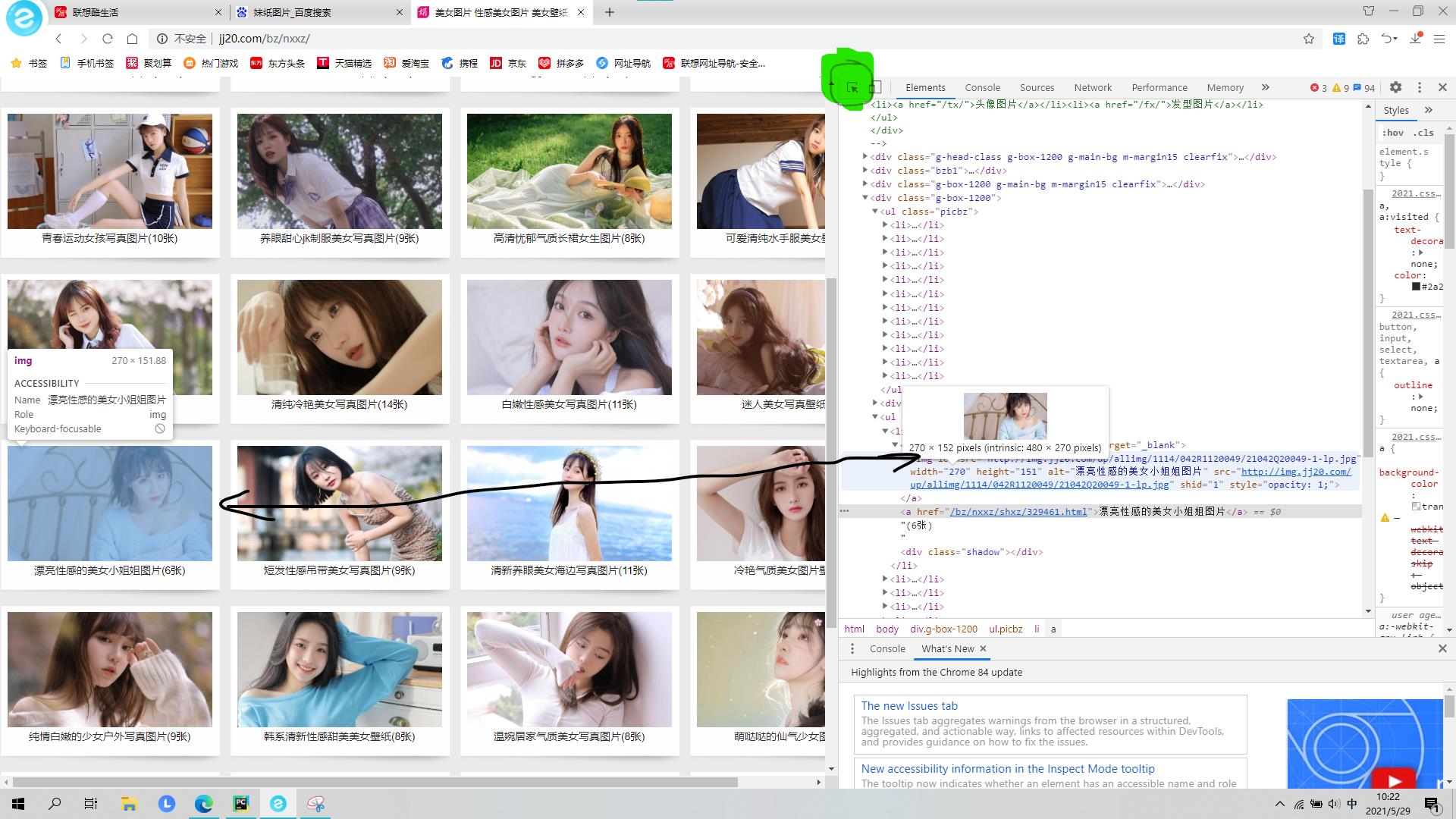
第二步,请求网址
下面就开始用代码加图片进行理解了。(如果爬取其他网址请求不到,说明有反爬机制,反爬机制解决办法)
import requests
# 导入请求库
# 请求网页
response=requests.get('http://www.jj20.com/bz/nxxz/')
print(response.text)内容如下(绿色部分,表示出现了乱码问题,下面修改一下编译方式,乱码解决办法)
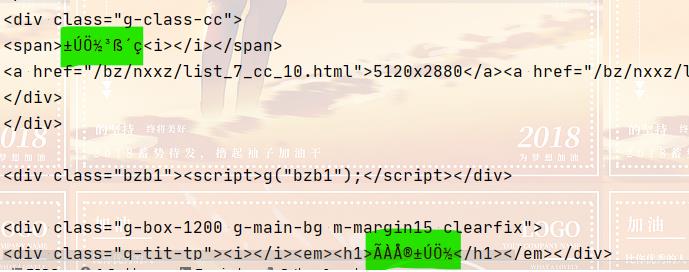
按方法可以看到网页的编码格式,(gbk)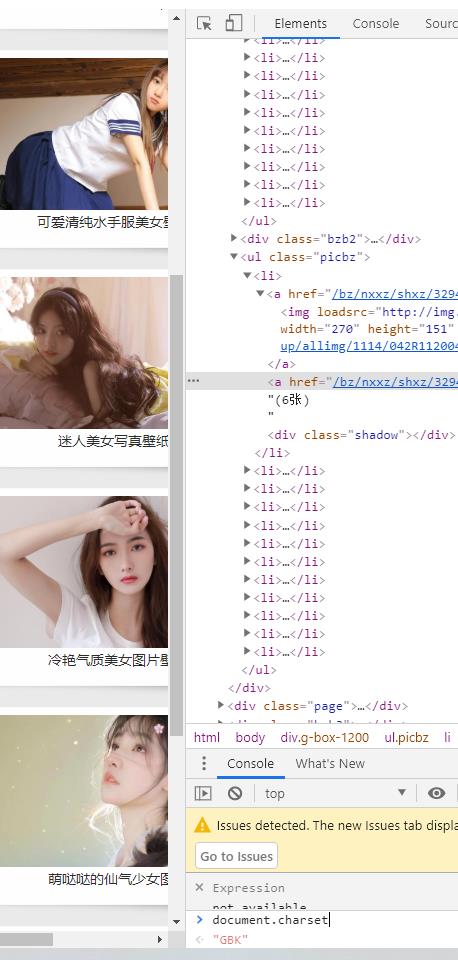
修改代码如下
import requests
# 导入请求库
# 请求网页
response=requests.get('http://www.jj20.com/bz/nxxz/')
#指定编译方式
html=response.text.encode('iso-8859-1').decode('gbk')
print(html)现象
第三步,解析网址
往往我们需要从网页中获取图片连接,然后进行爬取保存。
# 请求网页
response=requests.get('http://www.jj20.com/bz/nxxz/')
#指定编译方式
html=response.text.encode('iso-8859-1').decode('gbk')
#解析网址
url=re.findall('<img src="(.*?)" width=".*?" height=".*?" alt=".*?">',html)
print(url)效果
第四步,保存图片
下面就是进行图片保存,一般都以二进制形式保存。
import requests
# 导入请求库
import re
#导入正则表达(筛选需要内容)
import time
# 请求网页
response=requests.get('http://www.jj20.com/bz/nxxz/')
#指定编译方式
html=response.text.encode('iso-8859-1').decode('gbk')
#解析网址
url=re.findall('<img src="(.*?)" width=".*?" height=".*?" alt=".*?">',html)
#保存图片
for ul in url:
#增加延时
time.sleep(1)
#设置图片名称,以/为分隔符获取最后部分
name=ul.split('/')[-1]
new_response=requests.get(ul)
with open(name,mode='wb') as f:
f.write(new_response.content)
print('下载完成')
现象

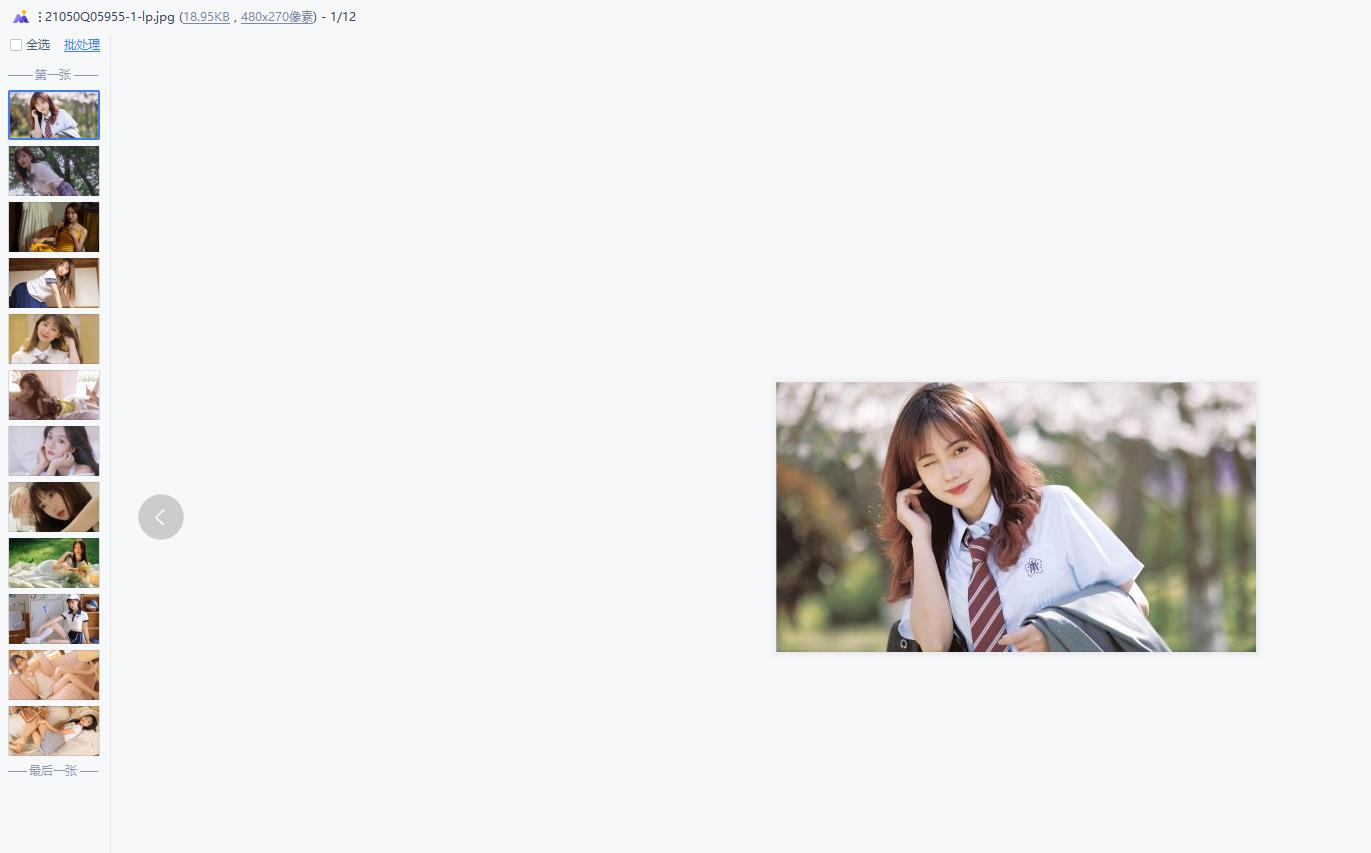
代码优化(完整代码)
import requests
# 导入请求库
import re
#导入正则表达(筛选需要内容)
import time
import os
#导入操作系统模块
def picture(urls):
# 请求网页
response=requests.get(urls)
#指定编译方式
html=response.text.encode('iso-8859-1').decode('gbk')
#解析网址
url=re.findall('<img src="(.*?)" width=".*?" height=".*?" alt=".*?">',html)
# 判断是否存在文件夹,不存在就创建
return url
if __name__ == '__main__':
if not os.path.exists('pictur'):
os.mkdir('pictur')
# 保存图
page = 1
while page <= 2:
urls = f'http://www.jj20.com/bz/nxxz/list_7_{page}.html'
for ul in picture(urls):
print(ul)
time.sleep(1)
name = ul.split('/')[-1]
new_response = requests.get(ul)
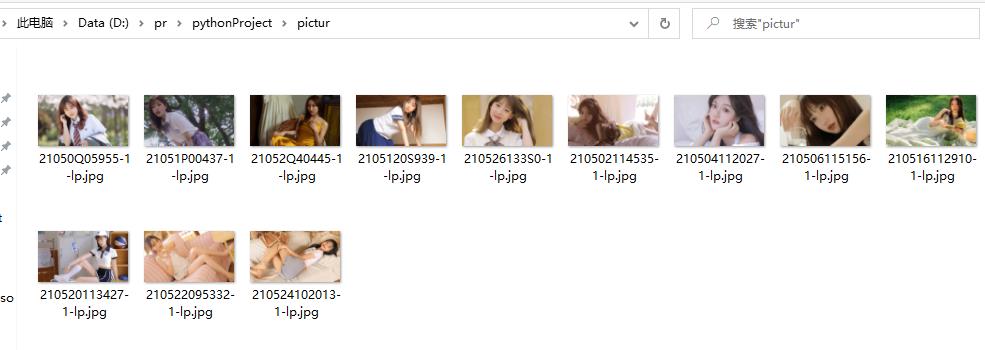
with open(file=r'D:\\pr\\pythonProject\\pictur\\{}'.format(name), mode='ab') as f:
f.write(new_response.content)
print('下载完成')
page+=1
现象
以上是关于小白爬虫(爬虫获取妹纸图片,附加完整代码)的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫-20行代码爬取王者荣耀所有英雄图片,小白也轻轻松松
python爬虫-20行代码爬取王者荣耀所有英雄图片,小白也轻轻松松
凌晨一点肝文1920×1080高清必应壁纸爬取,只为爬虫小白们入门!!!