常规动态网页爬取
Posted xingweikun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常规动态网页爬取相关的知识,希望对你有一定的参考价值。
使用Selenium库爬取动态网页
需根据浏览器版本下载Chrome的补丁文件chromedriver
打开浏览对象并访问页面
from selenium import webdriver
driver=webdriver.Chrome('D:/chromedriver_win32/chromedriver.exe')# Chrome的补丁文件chromedrive下载目录
url='https://www.ptpress.com.cn/search/books'
driver.get(url)
data=driver.page_source
print(data)
页面等待
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver=webdriver.Chrome('D:/chromedriver_win32/chromedriver.exe')
url='https://www.ptpress.com.cn/search/books'
driver.get(url)
wait=WebDriverWait(driver,10)# 等待时间,如果在这个时间还没找到元素就会抛出异常
print(driver.find_element_by_id("searchVal"))
<selenium.webdriver.remote.webelement.WebElement (session="8181d8d581c649abba8af74d83941a8a", element="6f9142c5-b326-4933-92b4-05e9e8f93097")>
页面操作
填充表单
import time
driver=webdriver.Chrome('D:/chromedriver_win32/chromedriver.exe')
url='https://www.ptpress.com.cn/search/books'
driver.get(url)
driver.execute_script('window.open()')
#print(driver.window_handles)
# 在第一个选项卡放http://www.tipdm.org
# 在第一个选项卡放http://www.tipdm.com
driver.switch_to_window(driver.window_handles[1])
driver.get('http://www.tipdm.com')
time.sleep(1)
driver.switch_to_window(driver.window_handles[0])
driver.get('http://www.tipdm.org')

执行javascript
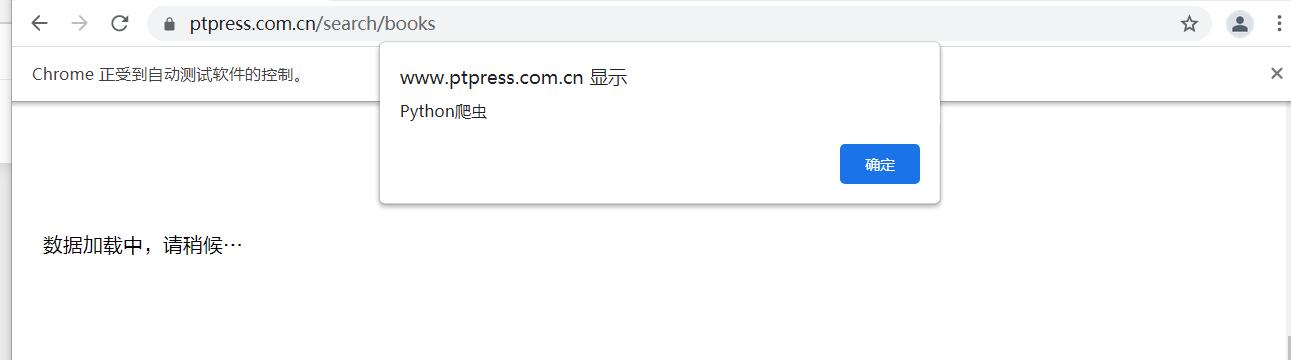
driver=webdriver.Chrome('D:/chromedriver_win32/chromedriver.exe')
url='https://www.ptpress.com.cn/search/books'
driver.get(url)
# 翻页到底部
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
driver.execute_script('alert("Python爬虫")')
元素选取
定位一个元素
driver=webdriver.Chrome('D:/chromedriver_win32/chromedriver.exe')
url='https://www.ptpress.com.cn/search/books'
driver.get(url)
input_first=driver.find_element_by_id("searchVal")
input_second=driver.find_element_by_css_selector("#searchVal")
input_third=driver.find_element_by_xpath('//*[@id="searchVal"]')
print(input_first)
print(input_second)
print(input_third)
<selenium.webdriver.remote.webelement.WebElement (session="143db49e478bb37f15f74791fccbffb3", element="726216cc-cf93-469f-95ba-24918c912096")>
<selenium.webdriver.remote.webelement.WebElement (session="143db49e478bb37f15f74791fccbffb3", element="726216cc-cf93-469f-95ba-24918c912096")>
<selenium.webdriver.remote.webelement.WebElement (session="143db49e478bb37f15f74791fccbffb3", element="726216cc-cf93-469f-95ba-24918c912096")>
此外,还可以通过By类来获取网页元素
from selenium.webdriver.common.by import By
driver=webdriver.Chrome('D:/chromedriver_win32/chromedriver.exe')
url='https://www.ptpress.com.cn/search/books'
driver.get(url)
input_first=driver.find_element(By.ID,"searchVal")
print(input_first)
<selenium.webdriver.remote.webelement.WebElement (session="485bf28500c1cbf5f4e6341baf3f6a20", element="275a8a3d-08bd-4de9-a0b9-6d24c5d38537")>
定位多个元素
driver=webdriver.Chrome('D:/chromedriver_win32/chromedriver.exe')
url='https://www.ptpress.com.cn/search/books'
driver.get(url)
lis=driver.find_element_by_css_selector('#nav')
print(lis)
<selenium.webdriver.remote.webelement.WebElement (session="990d7412f2982c53040b045aad28cb5f", element="70fa1b17-1fd3-489f-a268-e52fda75b040")>
此外,还可以通过By类来获取网页元素
driver=webdriver.Chrome('D:/chromedriver_win32/chromedriver.exe')
url='https://www.ptpress.com.cn/search/books'
driver.get(url)
lis=driver.find_element(By.CSS_SELECTOR,'#nav')
print(lis)
<selenium.webdriver.remote.webelement.WebElement (session="0a411b2b9333f56fe7b3eb888961f643", element="5077e561-0e14-420b-94e6-587ad2be3e7f")>
预期条件
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import re
import time
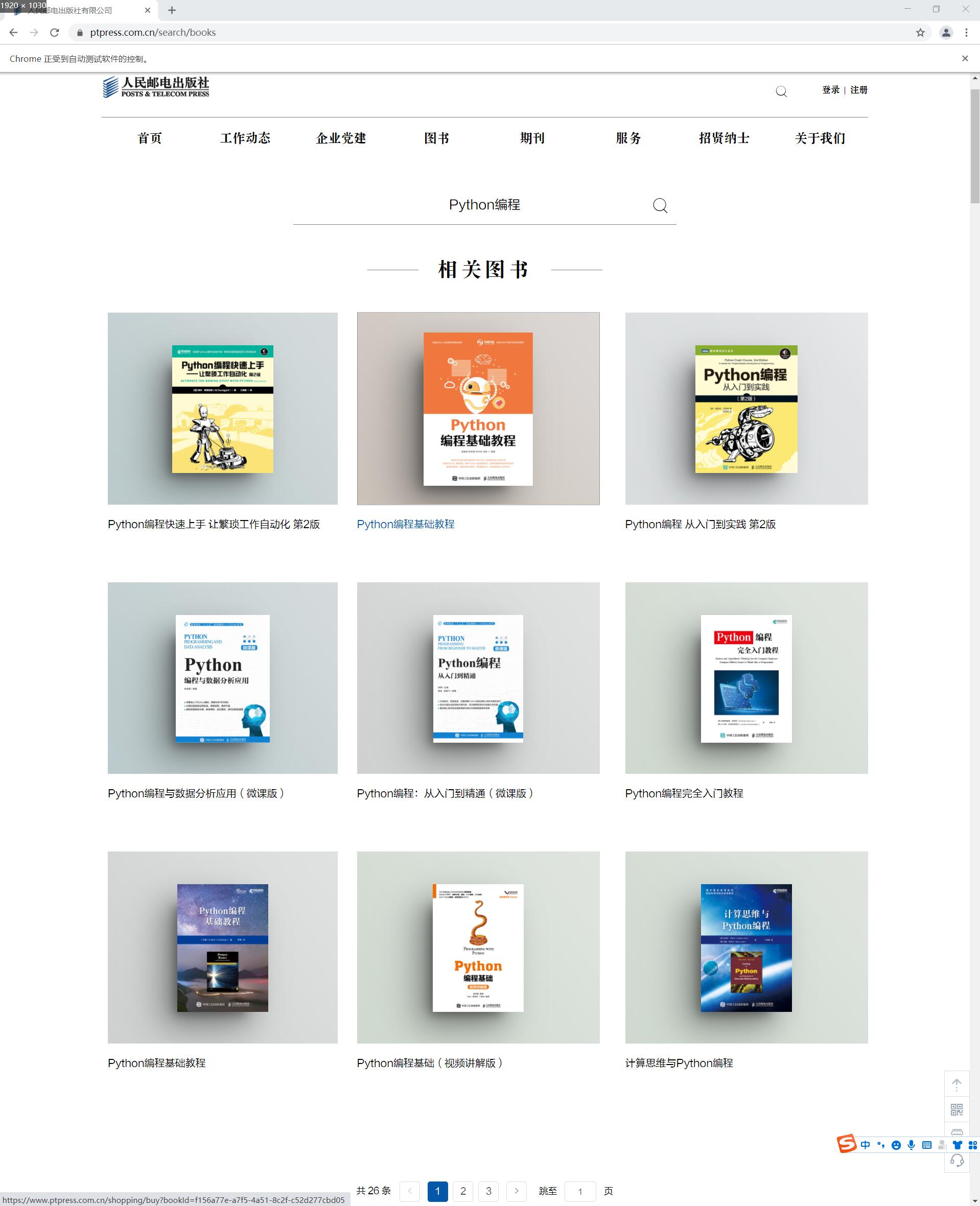
driver = webdriver.Chrome('D:/chromedriver_win32/chromedriver.exe')
url = 'https://www.ptpress.com.cn/search/books'
wait = WebDriverWait(driver, 10)
# 模拟搜索"Python编程"
# 打开网页
driver.get(url)
# 等待搜索按钮加载完成
search_btn = driver.find_element_by_id("searchVal")
# 在搜索框填写Python编程
search_btn.send_keys('Python编程')
# 等待确认按钮加载完成
confirm_btn = wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#app>div:nth-child(1)>div>div>div>button>i'))
)
# 点击确认按钮
confirm_btn.click()
# 等待5秒
time.sleep(5)
html = driver.page_source
# 使用BeautifulSoup找到书籍信息的模块
soup = BeautifulSoup(html, 'lxml')
a = soup.select('.rows')
# 使用正则表达式解析书籍图片信息
ls1 = '<img src="(.*?)"/></div>'
pattern = re.compile(ls1, re.S)
res_img = re.findall(pattern, str(a))
# 使用正则表达式解析书籍文字信息
ls2 = '<img src=".*?"/></div>.*?<p>(.*?)</p></a>'
pattern1 = re.compile(ls2, re.S)
res_test = re.findall(pattern1, str(a))
print(res_test, res_img)

以上是关于常规动态网页爬取的主要内容,如果未能解决你的问题,请参考以下文章