联邦学习--论文汇总
Posted 为了明天而奋斗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习--论文汇总相关的知识,希望对你有一定的参考价值。
回归老本行,Non-iid !!!
【1】SEPARATE BUT TOGETHER: UNSUPERVISED FEDERATED LEARNING FOR SPEECH ENHANCEMENT FROM NON-IID DATA, arXiv:2105.04727v1.
【2】Node Selection Toward Faster Convergence for Federated Learning on Non-IID Data
有些不友好:关于语音的缺乏理论知识,看的不太懂;第二个翻译器有问题,待后续完善吧。
分离但在一起:基于non-iid数据中增强语音的无监督联邦学习
FedEnhance: 一种无监督的联邦学习,用于跨多个客户端non-iid分布式数据的语音增强和分离。迁移学习促进收敛和学习性能。
现状
从高保真的混合声音分离出单独的声源,收集干净的源波形在不同的领域执行监督训练可能是繁琐的,甚至不可能。
联邦学习用于训练音频模型,关键字定位、自动语音识别和声音事件监测。
本地客户端数据集包含嘈杂的混合物,并且在不同的客户端之间可能有很大的差异。能够学习语音增强的分离模型,而不依赖于几个常见的假设,
a)需要监督数据
b)假设数据在客户端之间的IID分布。
每个客户端都可以访问有限数量的噪声混合语音和孤立的噪声记录。
所有的客户都使用MixIT进行无监督的本地培训,从一个嘈杂的语音录音和一个嘈杂的录音合成一个混合物。

服务器-客户端通信
服务器拥有一个全局模型权重 θ g ( r ) \\theta^{(r)}_g θg(r), 分散在每一轮r中,假设服务器与客户共享相同的分离网络架构 f ( . ; θ g ( r ) ) f( . ; \\theta^{(r)}_g) f(.;θg(r)),每个分离模型输出M个源, s = f ( x ; θ ) ∈ R M ∗ T s=f(x;\\theta)\\in R^{M*T} s=f(x;θ)∈RM∗T,更新步骤中,客户端在数据集上独立训练更新 θ c ( r ) \\theta^{(r)}_c θc(r),。
客户端训练
第c个客户端只能访问数据集
D
c
D_c
Dc, 包括两部分
D
c
=
(
D
c
m
,
D
c
n
)
D_c = (D^m_c,D^n_c)
Dc=(Dcm,Dcn),分别是混合语音和噪声,以及只有噪音,每个客户端生成人工混合的混合集合(Moms),包括噪声的语音
x
∼
D
c
m
x \\sim D^m_c
x∼Dcm和纯噪声
n
∼
D
c
n
n \\sim D^n_c
n∼Dcn,分两种不同的情况,每个客户的私人数据
D
c
m
D^m_c
Dcm,假定客户端访问纯噪声
D
c
n
D^n_c
Dcn.
有监督的数据:
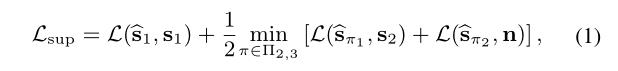
该方法可以在单个节点上进行IID训练,并通过在其他数据集上进行预训练,以及将节点与监督数据结合,进一步提高IID训练的性能。
Node Selection Toward Faster Convergence for Federated Learning on Non-IID Data(面向非iid数据的联邦学习的快速收敛节点选择)
下一代计算网络正在经历从传统云计算到移动边缘计算(MEC)系统的范式转变,算力和内存能力的提升,MSE系统构建了边缘点云网络架构,
支持资源受限节点,满足低延迟通信或高吞吐量。
背景
传感器、移动设备和联网车辆等边缘节点不断生成前所未有的数据量,再加上前沿的机器学习(ML) /深度学习(DL)技术,MEC系统能够进行智能推理(如道路拥堵预测[4])和感知控制(如:无人机(UA Vs群控导航[5])。从隐私、安全、监管或必要性的角度来看,为模型培训收集数据是不现实的。联邦学习在边缘服务器[6],[7]解耦数据采集和模型训练。在边缘服务器的编排下优化全局模型,这允许多个边缘节点协作以增强数据,同时将训练数据保存在本地。
现存的困难
1.(节点代表性有限)跨参与节点的数据样本可能不是独立且相同分布的(non-i.i.d.)。由于每次迭代的参与节点都是随机选择的,节点上的数据分布不能代表全局的数据分布。
2.(有偏更新)数据集会导致模型的有偏更新,导致模型收敛性停滞,模型精度大幅降低,从而对资源受限的边缘节点[10],[11]调用额外的通信轮。
3.(通信时间)虽然发送的数据量相对较小(即一般模型参数比原始训练数据的大小更小),但由于网络的不确定性、带宽限制和落群效应等原因
4.数据异构,通过对局部数据样本的特征学习来更新模型,这些样本是特定于用户的,显示出不同的模式,从而对资源受限的边缘节点[10],[11]调用额外的通信轮。
现存的工作
1.针对降低无线链路上的通信成本:重要梯度(通过发送更大的梯度来减少通信,减少模型迁移的大小)、模型量化和模型聚合。
2.利用多址信道的波形叠加特性,在无线链路上同时实现了模型传输和聚合。
3.自适应调优局部训练,模型聚合的加权设计和节点选择策略。
4.Li等人[9]的算法FedProx使用一个正则化术语来平衡全局-局部目标的优化差异和允许参与节点执行可变数量的局部更新,从而克服non-iid。
5.与贡献相关的加权设计,即FedAdp,以提高非iid节点存在时FL的收敛速度。
6.避免同步聚合协议中的长尾等待时间,选用节点自己参与局部训练,看作为无偏节点选择。
7.基于节点的资源条件有意识的选择节点
8、 Amiria等人[20]设计了一种单独或联合考虑2-范数度量的本地更新显著性和信道条件的节点调度算法。
9. 局部更新的显著性是通过梯度发散来评估的。
10. 作者提出了有偏的客户端选择策略,即优先选择具有较高局部损失的节点。虽然贡献相关的损失度量导致更快的收敛,但有偏选择不能保证全局模型更新与全节点参与期望相同。选择偏斜会造成潜在的误差,而局部损耗测量会导致额外的通信和计算代价。
注:上述节点选择设计均未分析数据异构对节点选择的影响。
创新点:
- 不需要对所有参与节点进行全局模型聚合,但排除一些不利的局部更新可以使全局模型在模型精度方面得到更好的结果。
- 检查局部梯度和全局梯度之间的关系,识别并排除不利的局部更新,找出每一轮全局中参与节点局部更新的最优子集,利用局部梯度和全局梯度的内积作为指标
- 利用最优聚合的结果,概率节点选择框架(FedPNS),可以分析数据的异构性,并据此调整每个节点在后续全局轮中被选中的概率。
- 概率节点选择是在服务器端进行的,这不会带来额外的通信成本。
- 最优组合,识别排除潜在的对抗性局部更新,扩大每一轮全局损失的预期减少。
- 在保证全局更新无偏性的前提下,FedPNS倾向于选择提高模型收敛性的节点。
联邦模型、部分参与、Non-iid。
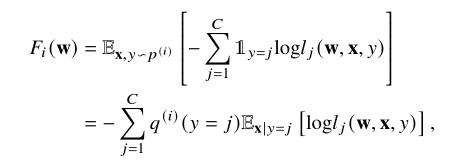
F
i
(
w
)
F_i(w)
Fi(w)是局部经验风险(交叉熵)
以局部更新和全局更新之间的内积为准则,隐式地描述了节点上数据分布和种群分布之间的差异,首先识别出更新对全局有不利影响的节点,通过排除潜在的对抗性局部更新并降低这些节点被选中的概率,可以确保对全局损失减少贡献较大的节点享有较高的被选中概率。
选择规则:
三个假设:
-
利普西斯条件+光滑
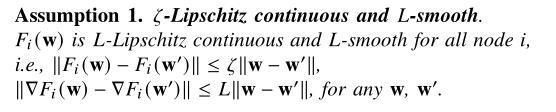
-
B-本地,如果相似,B趋向于1
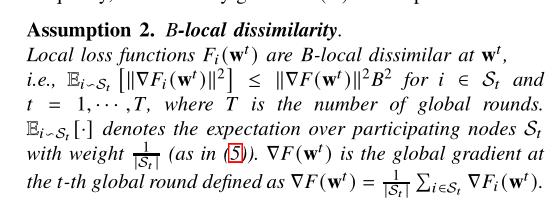
-
梯度有界

聚合梯度信息:
1.全局与局部的内积小于0,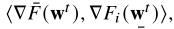
2.检查项
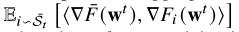
- 优化聚合,直到找不到任何不利的本地更新或剩余本地更新的数量低于阈值为止

FedPNS
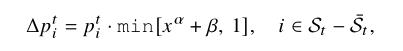

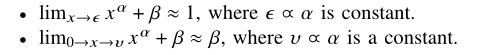
α
\\alpha
α控制实现概率
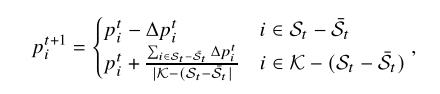
以上是关于联邦学习--论文汇总的主要内容,如果未能解决你的问题,请参考以下文章