消息队列应用场景&ActiveMQ消息发送失败的处理方案,先收藏!
Posted java构架师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了消息队列应用场景&ActiveMQ消息发送失败的处理方案,先收藏!相关的知识,希望对你有一定的参考价值。
今天我们来介绍一下ActiveMQ消息队列消息发送失败的处理方案。
在介绍今天的内容之前,首先我们来探讨一下为什么要用MQ。 企业中系统为什么要用消息队列那?其实要从消息中间件的常见使用场景来讲,然后结合自身系统对应的使用场景,说明系统中引入消息中间件解决了什么问题。
使用消息队列MQ,大致解决三类问题:
(1)系统解耦
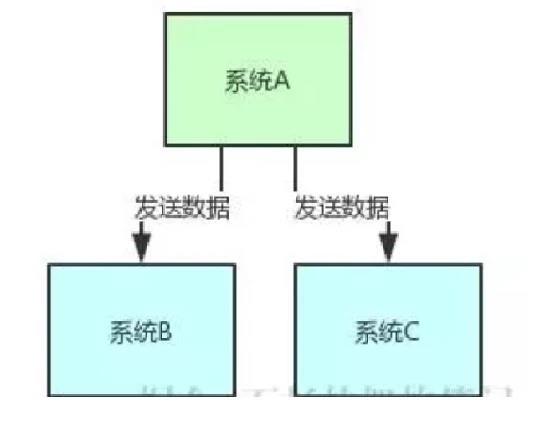
假设你有个系统 A,这个系统 A 会产出一个核心数据,现在下游有系统 B 和系统 C 需要这个数据。那简单,系统 A 就是直接调用系统 B 和系统 C 的接口发送数据给他们就好了。
整个过程,如下图所示:
但是现在要是来了系统 D、系统 E、系统 F、系统 G,等等,十来个其他系统慢慢的都需要这份核心数据呢?如下图所示:
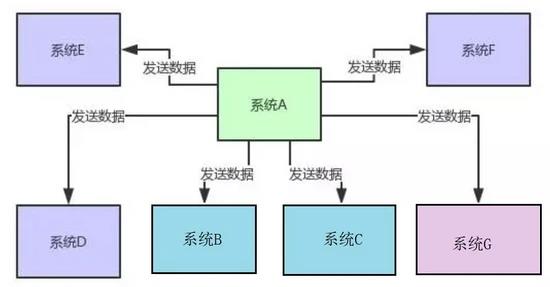
一个大规模系统,往往会拆分为几十个甚至上百个子系统,每个子系统又对应 N 多个服务,这些系统与系统之间有着错综复杂的关系网络。此时如果你要是采取上面那种模式来设计系统架构,那么绝对你负责系统 A 的同学要被烦死了。
两个问题:
要修改系统之间的调用关系,A系统就需要修改代码!
某个下游系统突然宕机了,系统 A 的调用代码就会抛异常!
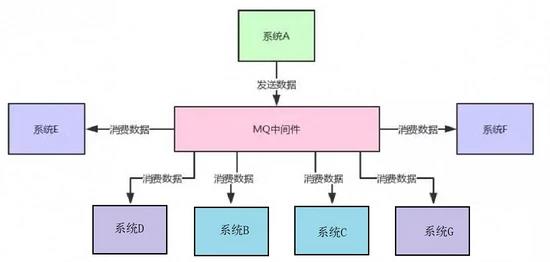
所有,某些场景下,这种架构师绝对不合适的,系统耦合度太严重。因此在上述系统架构中,就可以采用 MQ 中间件来实现系统解耦。系统 A 就把自己的一份核心数据发到 MQ 里,下游哪个系统感兴趣自己去消费即可,不需要了就取消数据的消费,如下图所示:
(2)异步调用
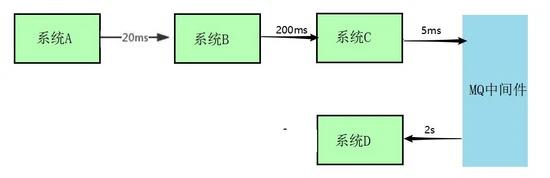
假设你有一个系统调用链路,是系统 A 调用系统 B,一般耗时 20ms;系统 B 调用系统 C,一般耗时 200ms;系统 C 调用系统 D,一般耗时 2s,如下图所示:

现在最大的问题就是:用户一个请求过来巨慢无比,因为走完一个链路,需要耗费 20ms + 200ms + 2000ms(2s) = 2220ms,也就是 2 秒多的时间。但是实际上,链路中的系统 A 调用系统 B,系统 B 调用系统 C,这两个步骤起来也就 220ms。就因为引入了系统 C 调用系统 D 这个步骤,导致最终链路执行时间是 2 秒多,直接将链路调用性能降低了 10 倍,这就是导致链路执行过慢的罪魁祸首。
那此时我们可以思考一下,是不是可以 将系统 D 从链路中抽离出去做成异步调用 呢?其实很多的业务场景是可以允许异步调用的。 所以, 最终的解决方案就是可以考虑把系统 C 对系统 D 的调用抽离出去做成异步化的 ,不要放在链路中同步依次调用。这样,实现思路就是系统 A→系统 B→系统 C,直接就耗费 220ms 后直接成功了。然后系统 C 就是发送个消息到 MQ 中间件里,由系统 D 消费到消息之后慢慢的异步来执行这个耗时 2s 的业务处理。通过这种方式直接将核心链路的执行性能提升了 10 倍。
(3)流量消峰 假设你有一个系统,平时正常的时候每秒可能就几百个请求,系统部署在 8 核 16G 的机器的上,正常处理都是 ok 的,每秒几百请求是可以轻松抗住的。但是如果在高峰期一下子来了每秒钟几千请求,瞬时出现了流量高峰,此时你可以搞 10 台机器,抗住每秒几千请求的瞬时高峰。但是如果瞬时高峰每天就那么半个小时,半小时过后直接就降低为了每秒就几百请求,如果你线上部署了很多台机器,那么每台机器就处理每秒几十个请求就可以了,造成了资源的浪费。
此时我们就可以用 MQ 中间件来进行流量削峰。所有机器前面部署一层 MQ,平时每秒几百请求大家都可以轻松接收消息。 一旦到了瞬时高峰期,一下涌入每秒几千的请求,就可以积压在 MQ 里面,然后那一台机器慢慢的处理和消费。等高峰期过了,再消费一段时间,MQ 里积压的数据就消费完毕了。
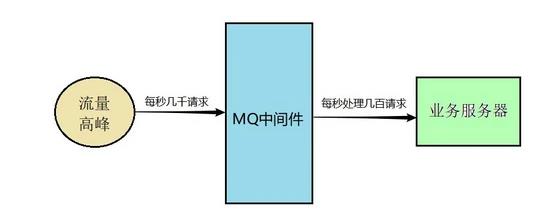
这个就是很典型的一个 MQ 的用法, 用有限的机器资源承载高并发请求 。如果业务场景允许异步削峰,高峰期积压一些请求在 MQ 里,然后高峰期过了,后台系统在一定时间内消费完毕不再积压的话,那就很适合用这种技术方案。
接下来,我们探讨一下ActiveMQ消息队列消息发送失败的处理方案这个问题与其讨论MQ消息队列消息发送失败的解决方案,等同于探讨中间件如何保证消息的一致性的问题?怎么保证两个服务器的通信同步更新成功,网络不好,造成的数据丢失问题。
解决方案:首先主动方(消息发送方)有个预处理的动作,就是发送消息的同时插入一条数据到数据库的表中, 这条 数据的关键字段:状态的值为 待确认. (可以单独抽离出来一个服务器安装数据库,任何主动方都是通过数据源连接这个数据库,给数据源一个IP地址就可以连接这个数据库)
然后执行生产者的业务代码时: ——–>如果失败: 就回滚,捕捉异常,把预处理的这条数据给删除了,数据库就没有数据了,消费方就不会有消息执行。双方数据一致。 ——–>如果成功: 修改数据的状态,把 待确认 改为 待发送 ,再把信息发给MQ,
第一种情况: 在MQ发送信息到消费方有可能导致数据丢失 , 消费方无法接收信息,那么之前插入数据库中那条数据还是处于待发送状态 ,如果数据丢失,消费方无法接收信息, 生产者有个定时任务,会不断去数据库找状态为待发送的那条记录, 如果找到待发送这条数据就再次把信息发到MQ,因为不会无限次数发送,因此如果发送6次均为失败就会转人工客服 ,比如发送短信通知客服,客服去排查哪条消息再告诉运维,在排查消费端为什么接收不到,这样就可以保证数据的最终一致性。
第二种情况: 正常情况下消费方如果能接收数据 , 处理完消费方就会链接到数据库把待发送那条信息删除,删除成功就说明主动方跟消费方都执行成功。 直接删除,不做逻辑删除,原因:数据量会越来越多。导致服务器的查询速度变慢。
方案总结: 缺点:少实时性。只能确保消息的最终一致性。
以上是关于消息队列应用场景&ActiveMQ消息发送失败的处理方案,先收藏!的主要内容,如果未能解决你的问题,请参考以下文章