HDFS数据的读写过程(重点)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS数据的读写过程(重点)相关的知识,希望对你有一定的参考价值。
参考技术A (1)客户端通过FileSystem.open()打开文件,相应地,在HDFS文件系统中DistributedFileSystem具体实现了FileSystem。因此,调用了open()方法后,DistributedFileSystem会创建输入流FSDataInputStream,对于HDFS而言,具体的输入流就是DFSInputStream.(2)DFSInputStream的构造函数中,输入流通过ClientProtocal.getBloackLocations()远程调用NameNode,获得文件开始部分数据块的保存位置。对于该数据块。名称节点返回保存该数据块的锁哟数据节点的地址,同时根据距离客户端的远近对数据节点进行排序,然后DistributedFileSystem会利用DFSInputStream来实例化FSDataInputStream返回给客户端,同时返回了数据块的数据节点的地址。
(3)获得输入流FSDataInputStream后,客户端调用read()函数开始读取数据。输入流根据前面的排序结果,选择距离客户端最近的数据节点建立连接,然后读取数据。
(4)读取完毕后,关闭流,如果还有下一个数据块,就与下一个DN建立连接,读取数据块。
(1)客户端发起创建文件请求
(2)DistributedFileSystem通过RPC远程调用名称节点,在文件系统的命名空间中创建一个新的文件。名称节点会执行一些检查,比如这个文件是否存在,客户端是否有权限等。通过检查,名称节点会狗仔一个新文件,并且添加文件信息。然后返回给客户端一个输出流,客户端通过这个输出流,用它来写入数据。
(3)获得输出流FSDataOutputStream以后,客户端调用输出流的write方法想HDFS中对应的文件写入数据
客户端向输出流FSDataOutputStream中写入的数据会首先被分成一个个的分包,这些分包被放入DFSOutputStream对象的内部队列。每个包64K,包中有数据块,块是512字节,这些包被放入DFSOutputStream对象的内部队列,FSDataOutputStream向名称节点申请保存文件和副本数据块的若干数据节点。这些数据节点形成一个数据流管道,队列中的分包最后被打包成数据包,发往数据流管道第一个节点,第一个节点又复制到第二、三个节点,采用流水线复制策略(在写入磁盘时候 是每次4k往磁盘写)
(5)为保证所有数据节点的数据准备DataNode返回确认包 Client收到应答,将对应分宝从内部队列移除。开始下一个分包。
HDFS的读写流程面试的重点
挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
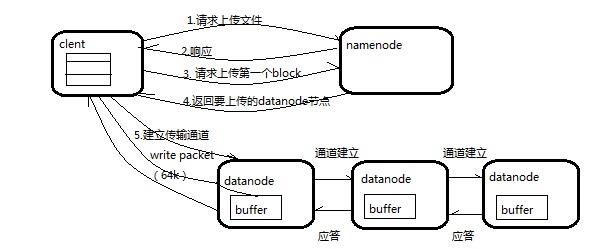
客户端通过DistributedFileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
NameNode返回是否可以上传。
客户端请求第一个 Block上传到哪几个DataNode服务器上,NameNode返回3个DataNode节点。
客户端通过FSDataOutputStream模块请求NameNode返回的三个DataNode中的就近的一个节点(dn1)上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。dn1、dn2、dn3逐级应答客户端。
客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。重复执行上述步骤,知道文件上传完毕。

Fsimage文件:是HDFS文件系统元数据的一个永久的检查点,它里面的内容主要包括HDFS文件系统的所有目录和文件inode的序列化信息。
Edits文件:这个文件主要存放的是HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作第一步会记录到Edits文件中。
seen_txid文件是用来保存最后一个edits_数字的文件。
当NameNode启动的时候会将Fsimage文件加载到内存中,同时也会加载Edits文件里面的更新操作,保证内存中的元数据信息是最新的,同步的,我们可以把这一步理解成NameNode启动的时候会把Fsimage和Edits文件合并。
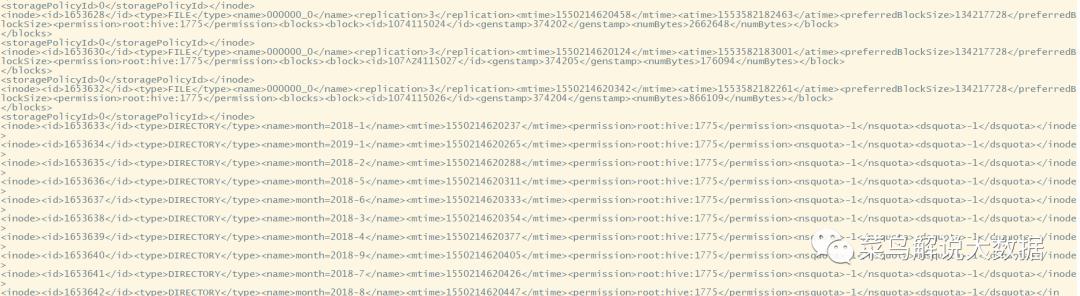
查看Fsimage文件,执行命令:hdfs oiv -p XML -i fsimage_0000000000134673403,下图是Fsimage文件的部分内容,也可以使用命令:hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
以上是关于HDFS数据的读写过程(重点)的主要内容,如果未能解决你的问题,请参考以下文章