关于中文分词的一些入门算法
Posted 林庚 coding基地
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于中文分词的一些入门算法相关的知识,希望对你有一定的参考价值。
预计阅读时间:11分钟
-本号开启了第一个专栏 #从0开始NLP#
在这个专栏中,将会把我学习进程中所学到的一点点NLP知识慢慢补充进来,也相当于学习博客了,但是我会尽量写得足够详细能让一些不是这个方向但却对这个方向感兴趣的读者,可以通过阅读该专栏内的文章收获到一些有用的知识~
正文
分词概念
直入主题,首先来看一眼百度百科对于分词的定义,十分的清晰。分词那就是把一句话所有的词识别出来,再分开。
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多。
百度百科
举个简单例子
我们给定两个句子,一个中文一个英文
“北京的天气真好啊”以及"The weather in Beijing is very nice"
按照百度百科的说法,我们可以不考虑词组,将英文句子首先分成
The weather in Beijing is very nice
而对于中文,按照我们母语使用者的习惯,也可以很轻易的分出来
北京 的 天气 真好 啊
知道了分词的基本原理,那我们现在需要思考的就是为什么要分词呢?
在自然语言处理中有一个词性标注的任务
词性标注任务的内容很简单
同样给出一句话
“我被我亲爱的老爸打了一顿”
我们可以很容易得出在这句话中,打是动词,亲爱的是形容词。而为了完成这个任务,首先要做的就是分词。
对于我们来说,凭借着经验,对一个中文的句子分词是十分简单,但是想要让计算机尽可能准确地实现这个任务是十分困难的。
废话不多说,直接开始论述如何让计算机“学会”如何中文分词!
准备
在开始我们的分词任务之前,我们需要准备两个东西。
一个是中文词典,一般来说类似于下面这种格式来保存我们的词典
| 词语 |
索引 |
| 北京 |
0 |
| 的 |
1 |
| 天 |
2 |
| 气 | 3 |
| 天气 |
4 |
| 真 | 5 |
| 好 | 6 |
| 真好 |
7 |
| 真好啊 |
8 |
| ... |
... |
之所以需要让每一个词和一个索引数字对应,简单来说是为了方便之后每一个词能够转变成数字在计算机中表示,这里不做赘述。
然后我们还需要一个句子的集合,可以是一本书,一篇小说,一首诗,只要包含是包含若干个句子的文本就可以了。我们需要通过这一段文本,算出每一个词在文本中出现的概率。
简单举例让你知道算概率的方法。
假设我们输入一段文本有100个字,在这100个字中假设有5个“我”字,那么“我”的概率就是5/100=0.05
所以为了每个词的概率更加可靠,我们倾向于这个文本越大越好。
我们得到一个词典,以及词典中每个词出现的概率。假设我们设每个词的概率如下(为了使整体概率和为1,我们编造了一些数据)
word_prob = {"北京":0.03,"的":0.08,"天":0.005,"气":0.005,
"天气":0.06,"真":0.04,"好":0.05,"真好":0.04,
"啊":0.01,"真好啊":0.02, "今":0.01,"今天":0.07,
"课程":0.06,"内容":0.06,"有":0.05,"很":0.03,
"很有":0.04,"意思":0.06,"有意思":0.005,"课":0.01,
"程":0.005,"经常":0.08,"意见":0.08,"意":0.01,
"见":0.005,"有意见":0.02,"分歧":0.04,"分":0.02,
"歧":0.005}现在我们给定一个句子“北京的天气真好啊”,我们的任务是给这个句子分词。
那么可以绘制一个有9个节点的有向图,每一个连接都按句子顺序对应着一个字,如图
又由我们的词典可以知道,存在一些词,如北京,天气,的,真,真好啊。
那么我们继续改进有向图,增加可以表示这些词的连接,并将已有连接出现在词典中的连接用标记出来,如图(由于代码绘图显示不够直观,所以这里使用了涂鸦)

接着我们按照我们得到的词出现的概率接着补全我们的有向图(之后我们的算法介绍也都围绕这张图)如图
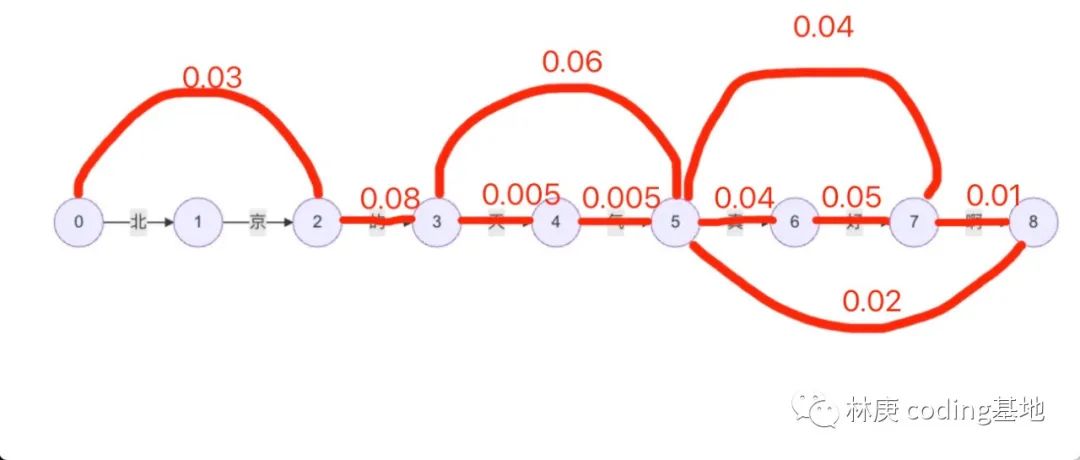
分词算法
得到我们这个表示整个句子的有向图之后就可以开始我们的算法介绍了
最大匹配算法
还是以上文的有向图为例,最大匹配算法的原理真的很简单。我们设置一个窗口,扫过我们的有向图,直到扫完最后一个字。这么说可能有点抽象,我们设置这个窗口的大小为5个字的长度(设置多少都没关系,因为按照经验,长度大于5的词语并不常见,所以设置成5),直接看图说话吧。
我们首先将窗口的左端靠近第一个字,在这个框中内容是“北京的天气”,并不是词典中的词语,此时我们将窗口的大小减少一个字。
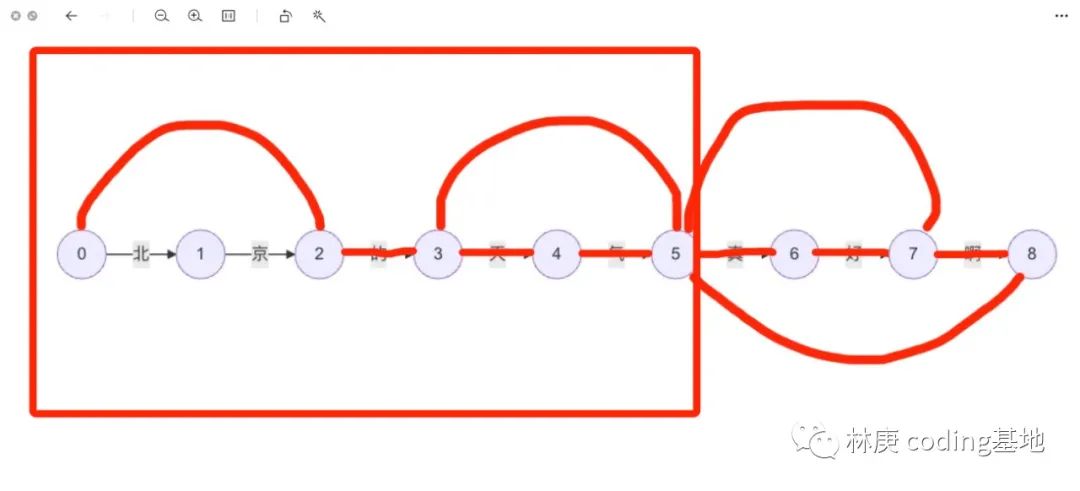
窗口的大小变成4,依旧不是词典中的词语,反复操作,直到窗的大小等于2,这时候就得到了第一个词“北京”,这也是我们分词操作的第一个结果
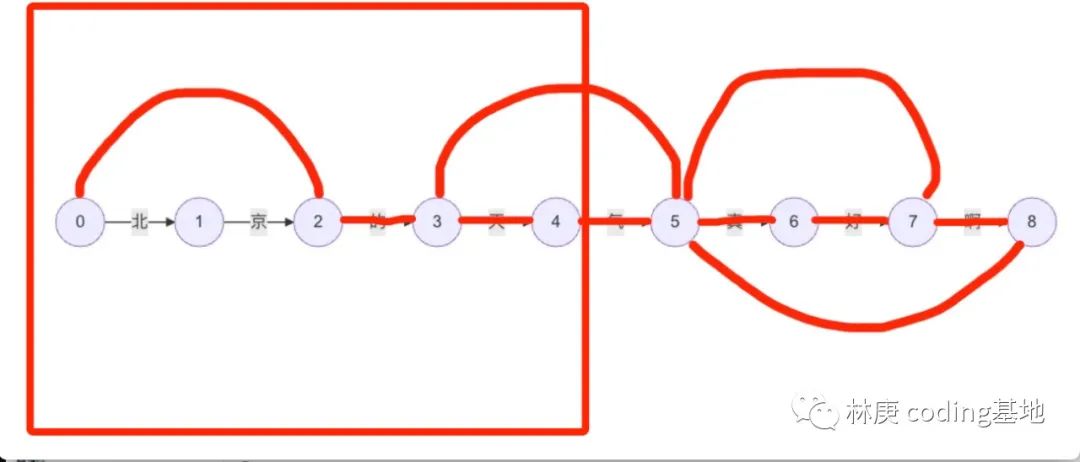
之后窗口移动到“京”右端,窗口大小重新变成5,反复之前的操作。
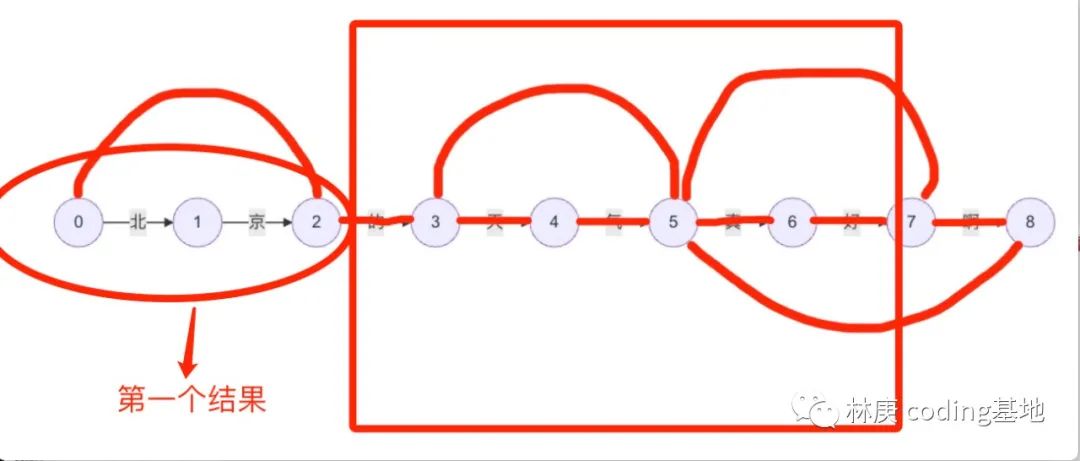
反复这个操作,最后就可以得出结果
北京 / 的 / 天气 / 真好啊
而窗口放在最左端的方法又称为正向最大匹配,你也可以将窗口从右端开始,这样就是逆向最大匹配,你也可以进行从左到右、从右到左两次匹配,这样就是双向最大匹配。具体过程都类似于前向最大匹配
这里贴出正向最大匹配算法的代码 :)
MAX_LENGTH=5#LOCAL_DICT是一个词语列表,根据你的需求来自己更改吧~
LOCAL_DICT=["我们","经常","有","有意见","意见","分歧"]
def forward_segment(str1):
result=[]
i=0
while i<len(str1):
for j in range(MAX_LENGTH):
str_frame=str1[i:i+MAX_LENGTH-j]
if str_frame in LOCAL_DICT:
result.append(str_frame)
i+=len(str_frame)
break
if j==MAX_LENGTH-1:
result.append(str_frame)
i+=1
return result
在这个算法中,并没有用到概率,所以得出的结果是相对不准确的,因为这个算法很容易就能想到,长度越大的词就越优先被识别出来。接下来将介绍一个更加准确的方法。
通过概率求解的思路
回到上文那个包含概率的有向图
我们可以用节点的下标来定义到达每一个字的概率,如设P6=句子到达“真”的概率,P8=句子到达“啊”的概率。我们的任务就是到“啊”的最大概率,也就是P8可能的最大值。
那么由上图可以看出P8有两种情况,一种是等于P7+0.01,一种是P5+0.02。
而我们要求出的是最大的那一个概率,那么就可以知道P8=MAX(P4+0.01,P5+0.02)。以此类推,可以用相同的方法表示P5,P4,为了表示P5,P4你又需要用相同方法表示P3,P4....
可想而知,一直这样下去你需要穷举出所有可能的计算路径,这样你可能要计算很多次相同的数据(就好像上面加粗文字中提到需要计算两次P4),所耗费的计算量变得十分巨大!所以将要提出的算法,正好是用来解决这个问题的。
维特比算法
维特比算法实质上就是一个动态规划,核心思想是将可能会重复计算的结果都保存在一个受到维护的数组中(在python中就是列表了)。就拿上面加粗字为例。
依旧上包含概率的有向图
我们要计算p8
那么就得分别计算P5+0.02和P7+0.01,因为我们要计算P8的最大值,所以P5和P7应该越大越好
观察图像可以得出P7有可以等于P5+0.04也可以等于P6+0.05,所以我们如果按照之前粗体字的分析方法,就得计算P5。而运用维特比算法的时候,我们将P5保存起来,也就是说,在下一次计算P5的时候可以直接通过查询保存的值,来直接得到P5,而不是进行重复计算计算!那么在P8的一种可能性P7+0.01计算完之后,我们计算P8的另一种可能性P5+0.02就不再需要计算了,可以直接查表来得到...
以上就是最基本的思路,所以说思路很简单,但是代码实现比较困难,一般都需要大量训练来熟悉如何编写动态规划的代码。
这里直接贴出我自己实现的维特比算法的分词代码
NOT_A_NUM=1000000000000
def word_segment_viterbi(input_str):
graph = []
for i in range(len(input_str)):
initial=[]
for j in range(len(input_str)):
initial.append(NOT_A_NUM)
graph.append(initial)
for i in range(len(input_str)):
for j in range(i,len(input_str)):
if input_str[i:j] in dic_words:
if input_str[i:j] in word_prob.keys():
graph[i][j]=-math.log(word_prob[input_str[i:j]])
else:
graph[i][j]=-math.log(0.00001)
dp = [NOT_A_NUM]*len(input_str)
path = [-1]*len(input_str)
dp[0] = 0
for i in range(1,len(input_str)):
for j in range(i):
if dp[j]+graph[j][i] < dp[i]:
dp[i] = graph[j][i]
path[i] = j
best_segments=[]
i=len(input_str)-1
while i>0:
best_segments.append(input_str[path[i]:i+1])
i=path[i]-1
best_segments.reverse()
return best_segments对于维特比算法,除了分词还有更进阶的应用,在未来学习到了也会一点一点补充进来~
感谢阅读
以上是关于关于中文分词的一些入门算法的主要内容,如果未能解决你的问题,请参考以下文章