JDK1.8的HashMap底层红黑树实现
Posted Code_BinBin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK1.8的HashMap底层红黑树实现相关的知识,希望对你有一定的参考价值。
今天看了小刘老师讲的红黑树,看完后茅塞顿开,受益匪浅,于是我打算写一篇博客记录一下今天所学,本文章大多来自小刘老师的笔记,以及部分自己的见解

什么是树
在学习红黑树之前,我们先来复习一下什么是树
**树(tree)**是一种抽象数据类型(ADT),用来模拟具有树状结构性质的数据集合。它是由n(n>0)个有限节点通过连接它们的边组成一个具有层次关系的集合。
把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
树有很多种,向上面的一个节点有多余两个的子节点的树,称为多路树,而每个节点最多只能有两个子节点的一种形式称为二叉树。
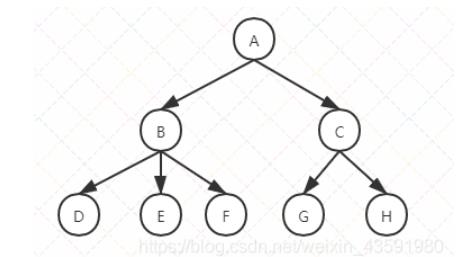
- 节点:上图的圆圈,比如A,B,C等都是表示节点。节点一般代表一些实体,在java面向对象编程中,节点一般代表对象。
- 边:连接节点的线称为边,边表示节点的关联关系。一般从一个节点到另一个节点的唯一方法就是沿着一条顺着有边的道路前进。在Java当中通常表示引用。
树结构常用术语
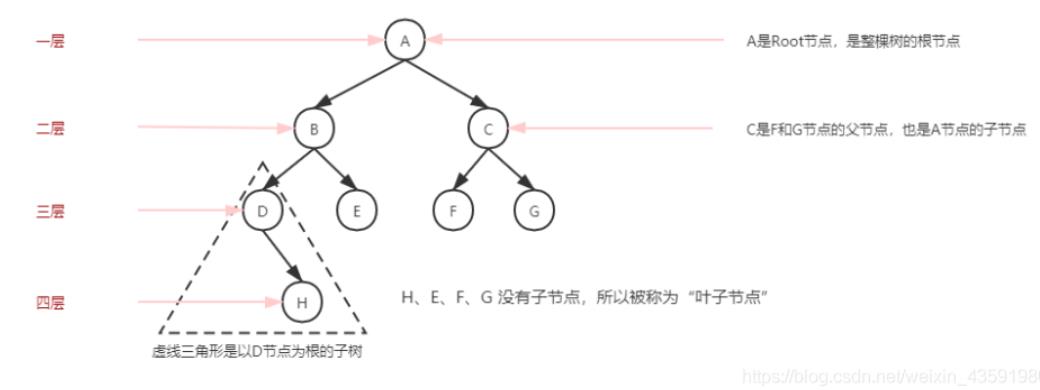
- 路径:顺着节点的边从一个节点走到另一个节点,所经过的节点的顺序排列就称为“路径”。
- 根:树顶端的节点称为根。一棵树只有一个根,如果要把一个节点和边的集合称为树,那么从根到其他任何一个节点都必须有且只有一条路径。A是根节点。
- 父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点
- 子节点:一个节点含有的子树的节点称为该节点的子节点;F、G是C节点的子节点。
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;F、G节点互为兄弟节点。
- 叶节点:没有子节点的节点称为叶节点,也叫叶子节点,比如上图的H、E、F、G都是叶子节点。
- 子树:每个节点都可以作为子树的根,它和它所有的子节点、子节点的子节点等都包含在子树中。
- 节点的层次:从根开始定义,根为第一层,根的子节点为第二层,以此类推。
- 深度:对于任意节点n,n的深度为从根到n的唯一路径长,根的深度为0;(从上往下看)
- 高度:对于任意节点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为0;(从下往上看)
二叉搜索树
二叉树:树的每个节点最多只能有两个子节点。
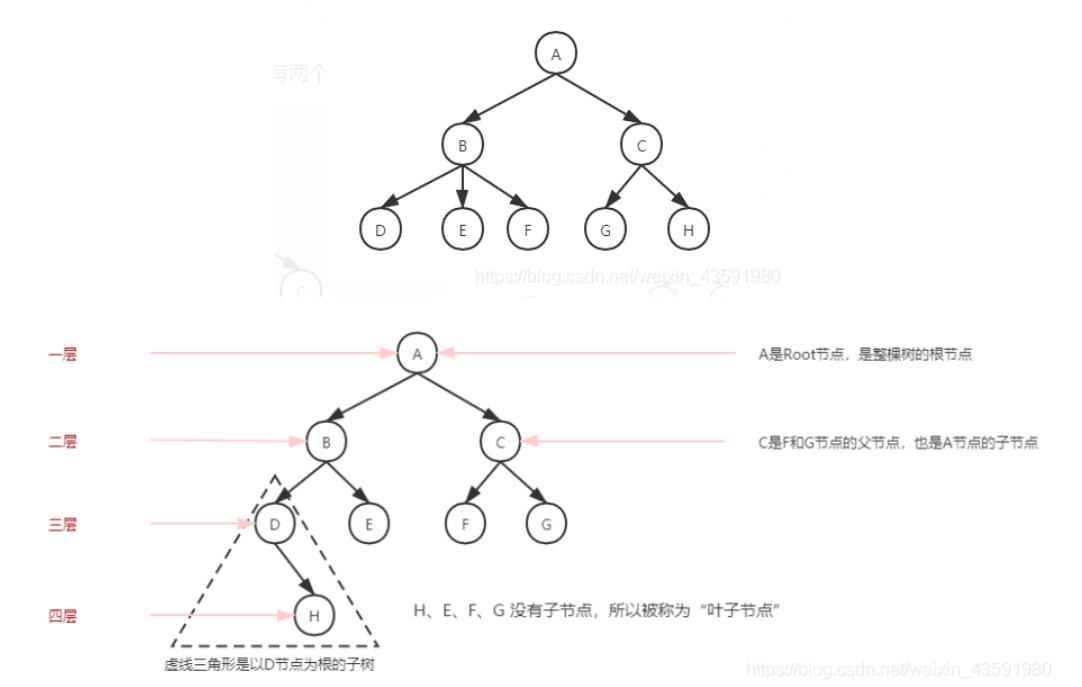
上图的第一幅图B节点有DEF三个子节点,就不是二叉树,称为多路树
而第二幅图每个节点最多只有两个节点,是二叉树,并且二叉树的子节点称为“左子节点”和“右子节点”
二叉搜索树:
如果我们给二叉树加一个额外的条件,就可以得到一种被称作二叉搜索树(binary search tree)的特殊二叉树。
二叉搜索树要求:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
它的左、右子树也分别为二叉排序树。
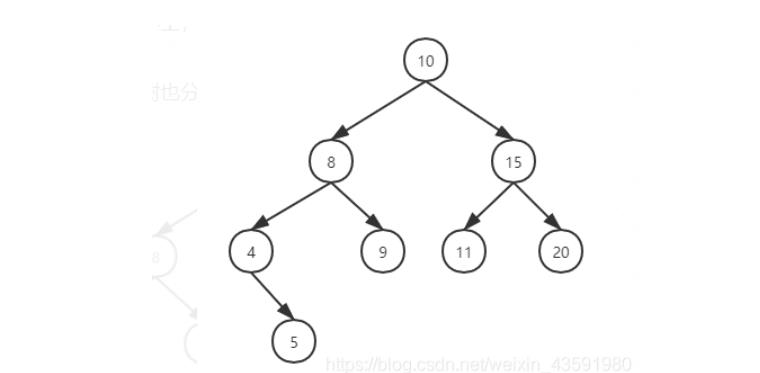
二叉搜索树-查找节点:
查找某个节点,我们必须从根节点开始查找。
- 查找值比当前节点值大,则搜索右子树;
- 查找值等于当前节点值,停止搜索(终止条件);
- 查找值小于当前节点值,则搜索左子树;
二叉搜索树-插入节点:
要插入节点,必须先找到插入的位置。与查找操作相似,由于二叉搜索树的特殊性,
待插入的节点也需要从根节点开始进行比较,小于根节点则与根节点左子树比较,
反之则与右子树比较,直到左子树为空或右子树为空,则插入到相应为空的位置。
二叉搜索树-遍历节点:
遍历树是根据一种特定的顺序访问树的每一个节点。比较常用的有前序遍历,中序遍历和后序遍历。而二叉搜索树最常用的是中序遍历。
- 中序遍历:左子树——>根节点——>右子树
- 前序遍历:根节点——>左子树——>右子树
- 后序遍历:左子树——>右子树——>根节点
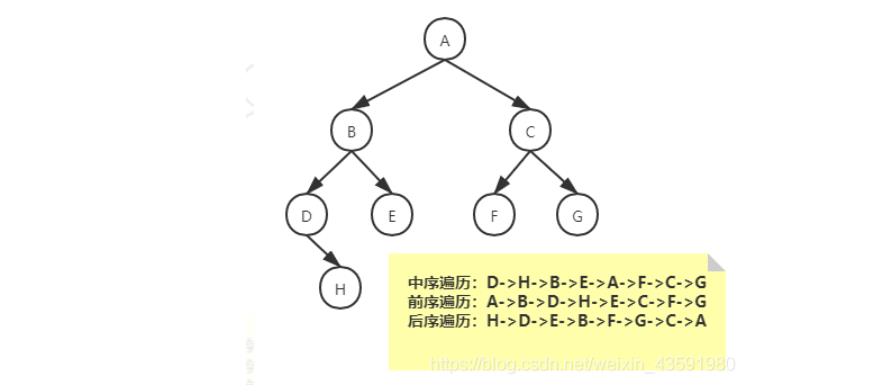
二叉搜索树-查找最大值和最小值
要找最小值,先找根的左节点,然后一直找这个左节点的左节点,直到找到没有左节点的节点,那么这个节点就是最小值。
同理要找最大值,一直找根节点的右节点,直到没有右节点,则就是最大值。
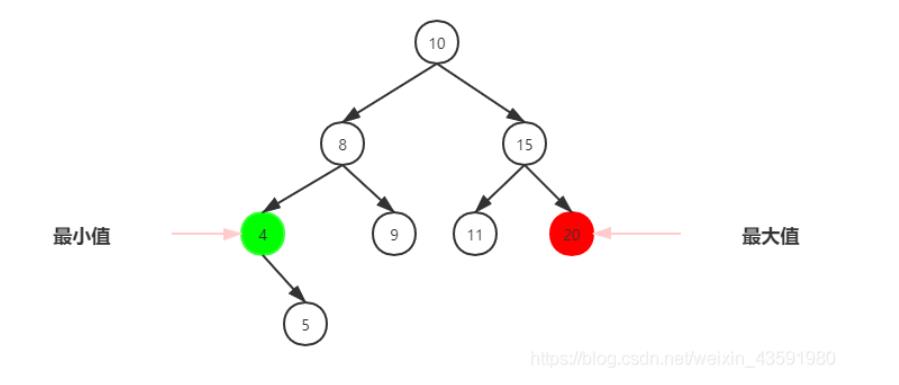
二叉搜索树-删除节点:
删除节点是二叉搜索树中最复杂的操作,删除的节点有三种情况,前两种比较简单,但是第三种却很复杂。
1、该节点是叶节点(没有子节点)
2、该节点有一个子节点
3、该节点有两个子节点
删除没有子节点的节点
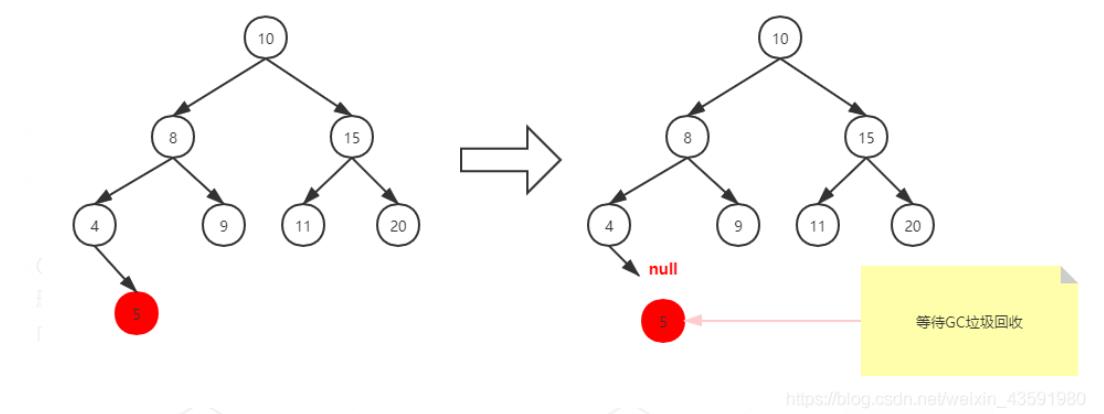
删除有一个子节点的节点
删除有一个子节点的节点,我们只需要将其父节点原本指向该节点的引用,改为指向该节点的子节点即可。
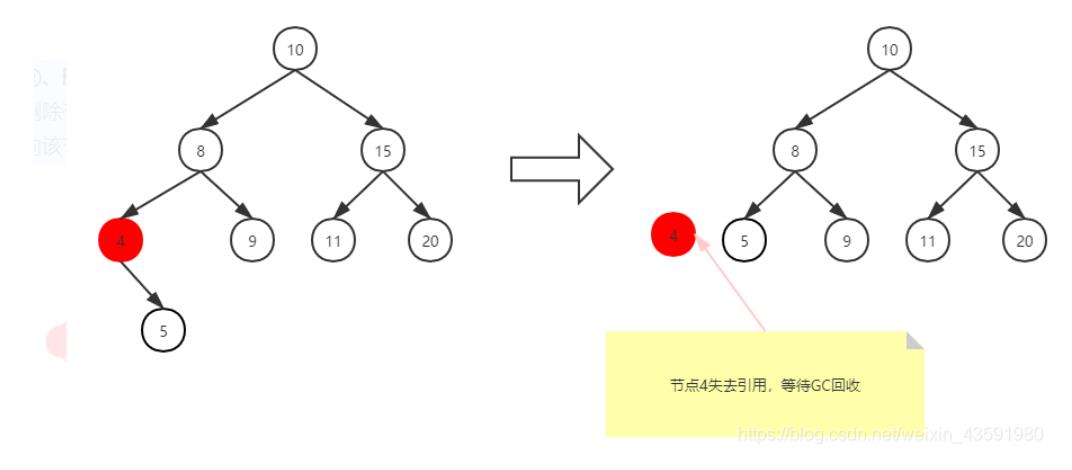
删除有两个子节点的节点
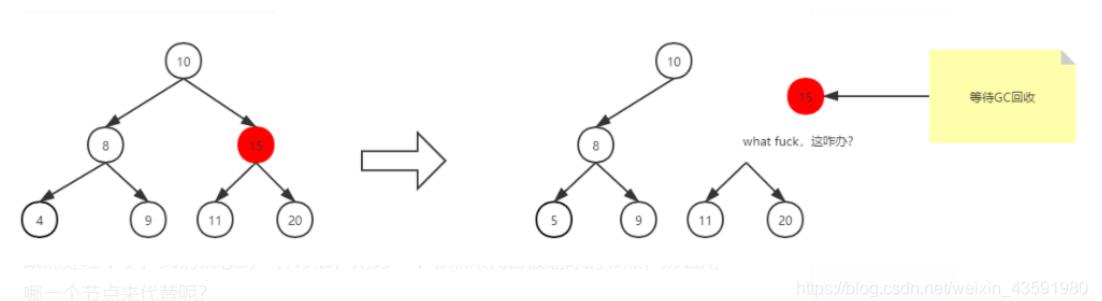
当删除的节点存在两个子节点,那么删除之后,两个子节点的位置我们就没办法处理了。
既然处理不了,我们就想到一种办法,用另一个节点来代替被删除的节点,那么用哪一个节点来代替呢?
我们知道二叉搜索树中的节点是按照关键字来进行排列的,某个节点的关键字次高节点是它的中序遍历后继节点。
用后继节点来代替删除的节点,显然该二叉搜索树还是有序的。
那么如何找到删除节点的中序后继节点呢?
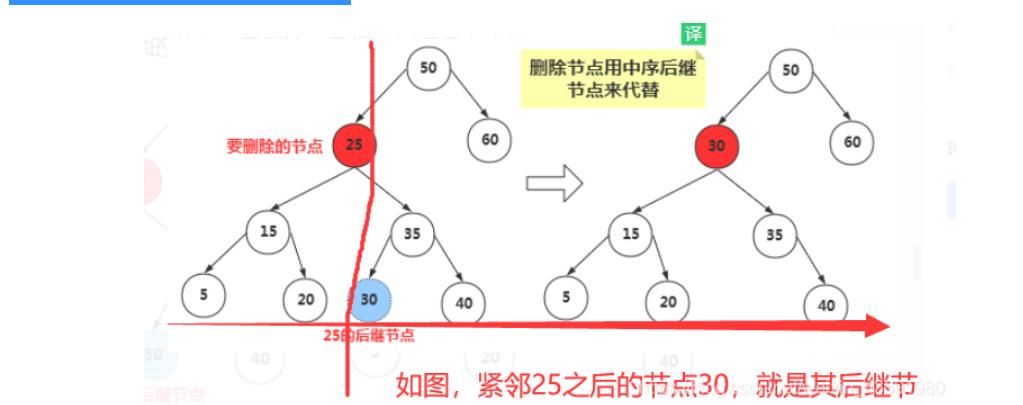
其实我们稍微分析,这实际上就是要找比删除节点关键值大的节点集合中,最小的那一个节点,只有这样代替删除节点后才能满足二叉搜索树的特性。
后继节点也就是:比删除节点大的最小节点。
二叉搜索树-时间复杂度分析:
回顾经典-二分查找算法,数组{1,2,3,4,5,6,7,8,9…100000}
暴力算法:
for(int i=0;i<a.length;i++){
if(a[i]==t)
.....
}
在这里,如果我们运气好,那么查找几下就可以出来,如果运气不好,那肯需要查几千下,几万下才可以出答案,那么我们有什么办法解决呢?我们可以使用二分法
二分查找算法
@Test
public void test03() {
int[] arr = new int[]{1,2,3,4,5,6,7,8,9,10};
System.out.println(binarySearch(arr,3));
}
/*
* 二分查找
*/
public static int binarySearch(int[] arr, int data) {
int low = 0;
int height = arr.length - 1;
while (low <= height) {
int mid = low + (height - low) / 2;
if (arr[mid] < data) {
low = mid + 1;
} else if (arr[mid] == data) {
return mid;
} else {
height = mid - 1;
}
}
return -1;
}
但是,我们知道,二分查找的话,数据源必须是有序数组,性能非常不错,每次迭代查询可以排除掉一半的结果。
二分查找算法最大的缺陷是什么?
强制依赖 有序数组,性能才能不错。
数组有什么缺陷?
没有办法快速插入,也没有办法扩容
那怎么才能拥有二分查找的高性能又能拥有链表一样的灵活性?
二叉搜索树!!
二分查找算法时间复杂度推算过程
| 查询次数 | 时间复杂度 |
|---|---|
| 1 | N/2 |
| 2 | N/(2^2) |
| 3 | N/(2^3) |
| 4 | N/(2^4) |
| k | N/(2^K) |
从上表可以看出N/(2K)肯定是大于等于1,也就是N/(2K)>=1,我们计算时间复杂度是按照最坏的情况进行计算,
也就是是查到剩余最后一个数才查到我们想要的数据,也就是
N/(2^K)=1 => 2^K = N => K = log2 (N) => 二分查找算法时间复杂度:O(log2(N)) => O(logN)
普通二叉搜索树致命缺陷:
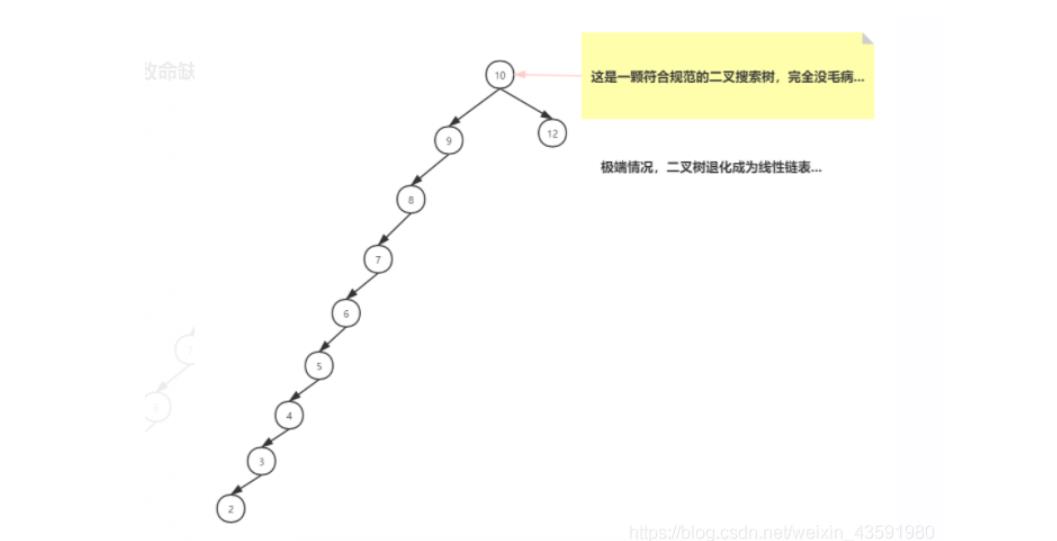
这颗二叉树查询效率咋样呢?
O(N)
怎么解决 二叉搜索树 退化成线性链表的问题?
如果插入元素时,树可以自动调整两边平衡,会保持不错的查找性能。
AVL树简介:
AVL树有什么特点?
- 具有二叉查找树的全部特性。
- 每个节点的左子树和右子树的高度差至多等于1。
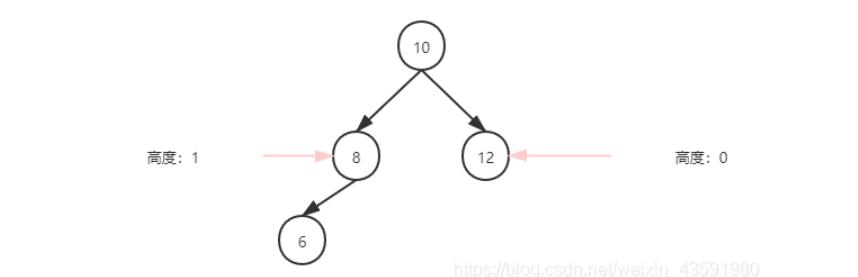
平衡树基于这种特点就可以保证不会出现大量节点偏向于一边的情况了!(插入或者删除时,会发生左旋、右旋操作,使这棵树再次左右保持一定的平衡)
如何构建AVL树?(再讲就跑题了…不是本期教程的内容,感兴趣的同学自行百度吧)
为什么有了平衡树还需要红黑树?
虽然平衡树解决了二叉查找树退化为近似链表的缺点,能够把查找时间控制在 O(logn),不过却不是最佳的,
因为平衡树要求每个节点的左子树和右子树的高度差至多等于1,这个要求实在是太严了,导致每次进行插入/删除节点的时候,
几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。
显然,如果在那种插入、删除很频繁的场景中,平衡树需要频繁着进行调整,这会使平衡树的性能大打折扣,为了解决这个问题,于是有了红黑树!!!

红黑树的性质:
- 性质1:每个节点要么是黑色,要么是红色。
- 性质2:根节点是黑色。
- 性质3:每个叶子节点(NIL)是黑色。
- 性质4:每个红色节点的两个子节点一定都是黑色。不能有两个红色节点相连。
- 性质5:任意一节点到每个叶子节点的路径都包含数量相同的黑结点。俗称:黑高!
红黑树实例图:
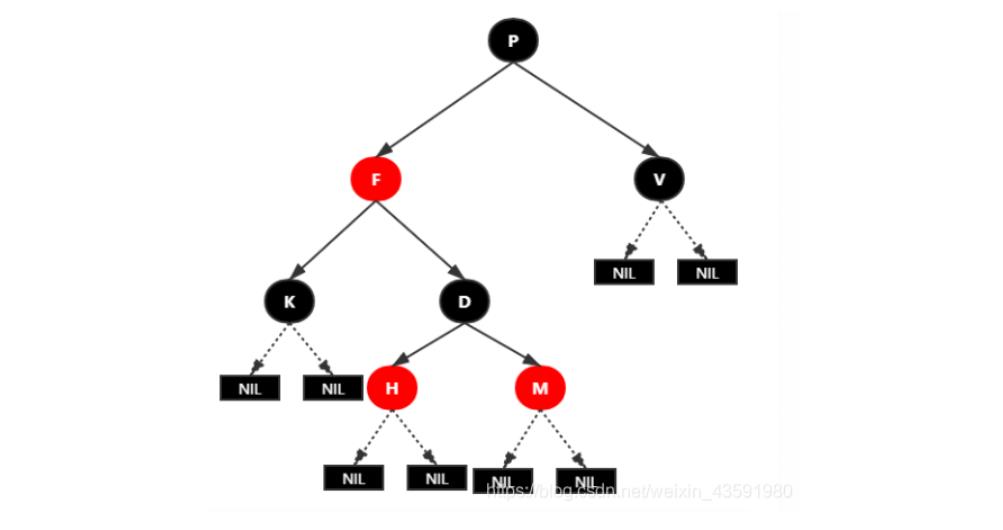
红黑树并不是一个完美平衡二叉查找树,从图上可以看到,根结点P的左子树显然比右子树高,
但左子树和右子树的黑结点的层数是相等的,也就是说,任意一个结点到到每个叶子结点的路径都包含数量相同的黑结点(性质5)。
所以我们叫红黑树这种平衡为黑色完美平衡。
红黑树的性质讲完了,只要这棵树满足以上性质,这棵树就是趋近与平衡状态的,
不要问为什么,这就是一个定理,类似于能量守恒,物质守恒。
前面讲到红黑树能自平衡,它靠的是什么?三种操作:左旋、右旋和变色。
1.变色:结点的颜色由红变黑或由黑变红。
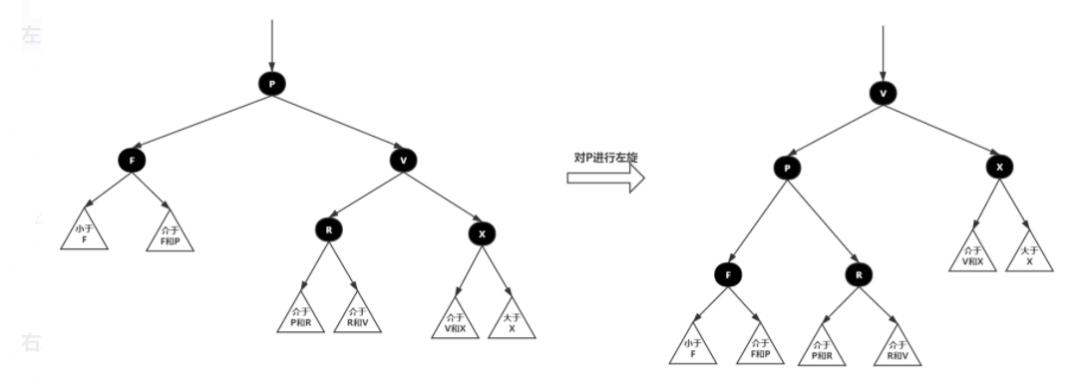
2.左旋:以某个结点作为支点(旋转结点),其右子结点变为旋转结点的父结点,右子结点的左子结点变为旋转结点的右子结点,左子结点保持不变。
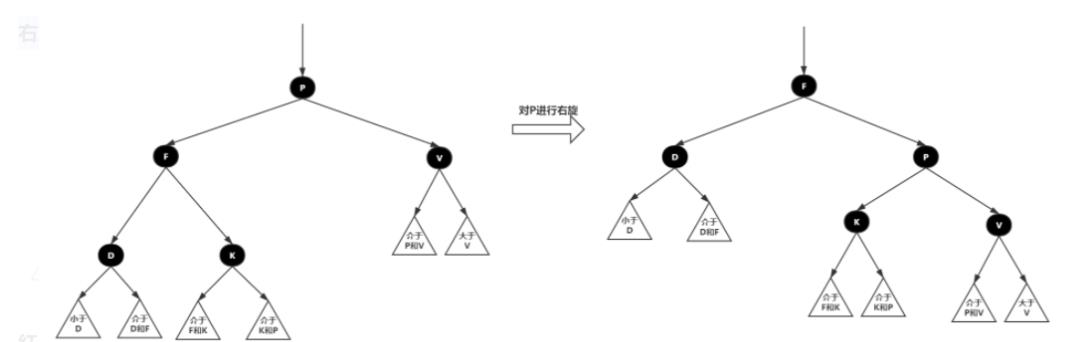
3.右旋:以某个结点作为支点(旋转结点),其左子结点变为旋转结点的父结点,左子结点的右子结点变为旋转结点的左子结点,右子结点保持不变
左旋图示:
右旋图示:
红黑树查找:
红黑树插入:
插入操作包括两部分工作:
1.查找插入的位置
2.插入后自平衡
注意:插入节点,必须为红色,理由很简单,红色在父节点(如果存在)为黑色节点时,红黑树的黑色平衡没被破坏,不需要做自平衡操作。
但如果插入结点是黑色,那么插入位置所在的子树黑色结点总是多1,必须做自平衡。
在开始每个情景的讲解前,我们还是先来约定下:
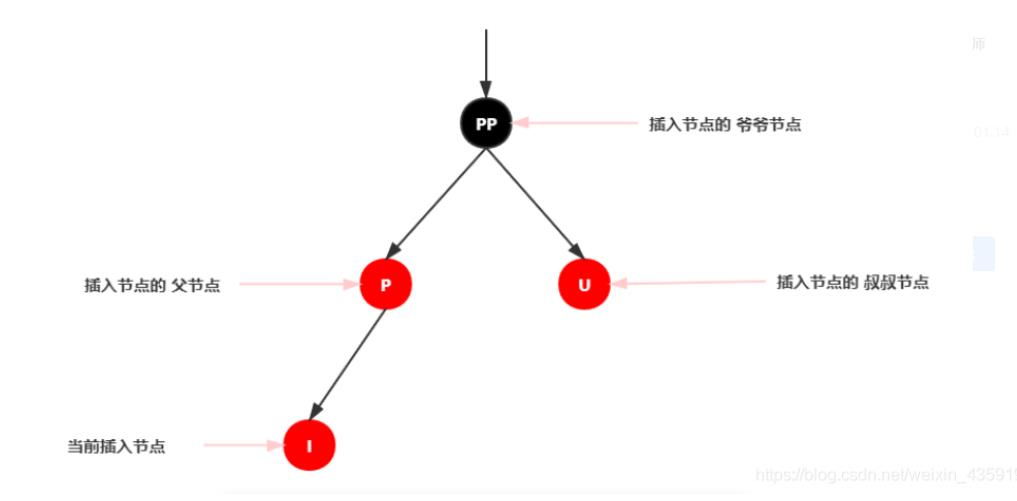
红黑树插入节点情景分析
情景1:红黑树为空树
最简单的一种情景,直接把插入结点作为根结点就行
注意:根据红黑树性质2:根节点是黑色。还需要把插入结点设为黑色。
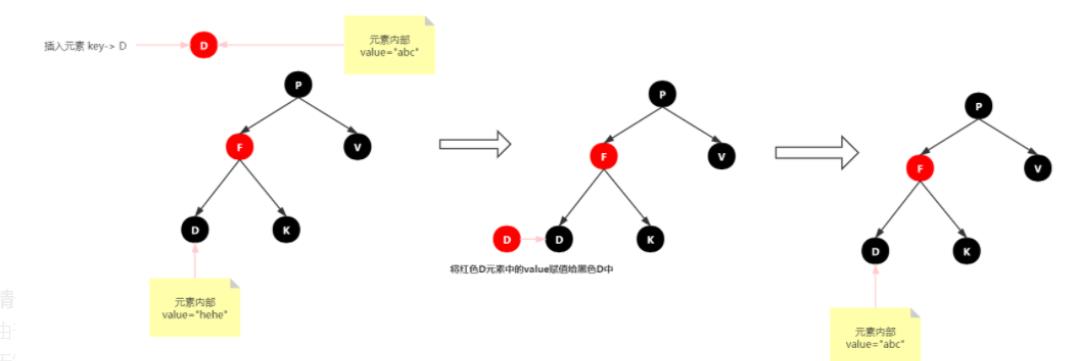
情景2:插入结点的Key已存在
处理:更新当前节点的值,为插入节点的值
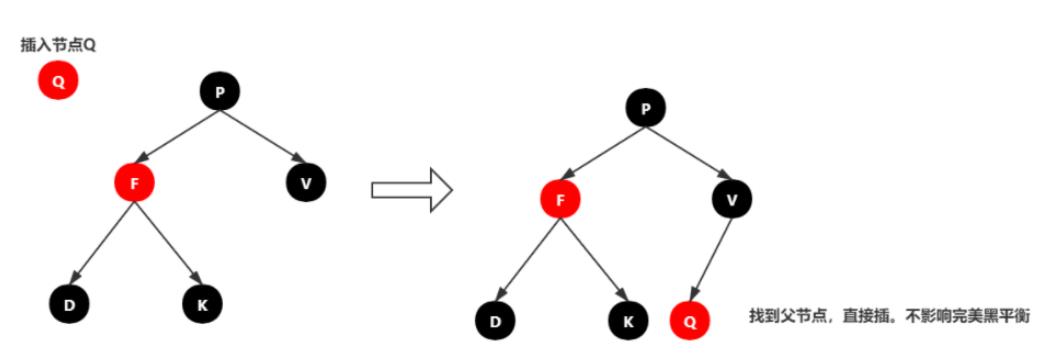
情景3:插入结点的父结点为黑结点
由于插入的结点是红色的,当插入结点的黑色时,并不会影响红黑树的平衡,直接插入即可,无需做自平衡。
情景4:插入节点的父节点为红色
再次回想下红黑树的性质2:根结点是黑色。如果插入节点的父结点为红结点,那么该父结点不可能为根结点,所以插入结点总是存在祖父结点。
这一点很关键,因为后续的旋转操作肯定需要祖父结点的参与。
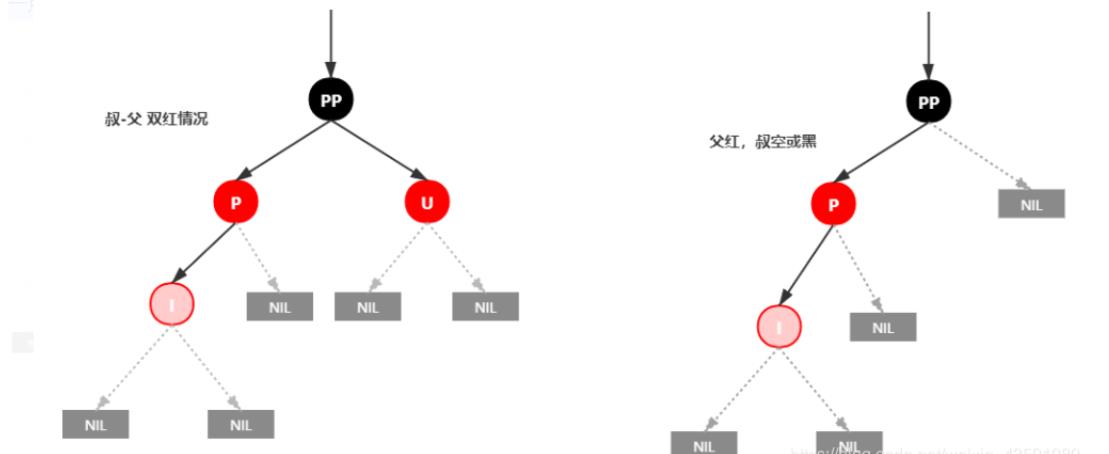
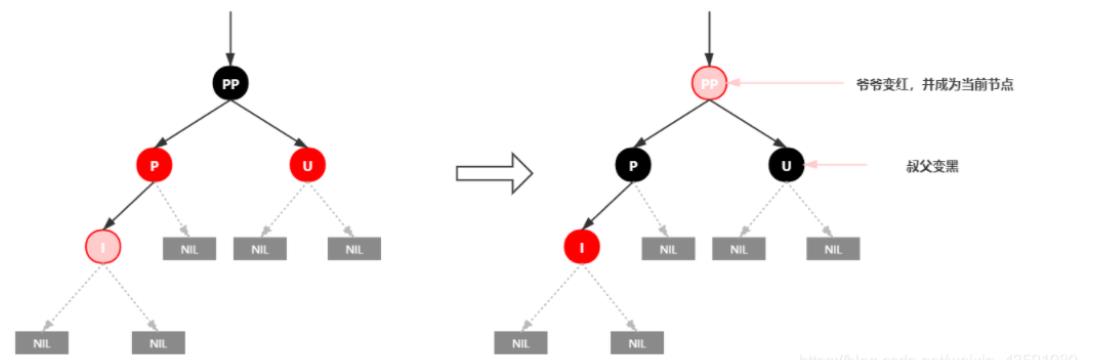
插入情景4.1:叔叔结点存在并且为红结点
依据红黑树性质4可知,红色节点不能相连 ==> 祖父结点肯定为黑结点;
因为不可以同时存在两个相连的红结点。那么此时该插入子树的红黑层数的情况是:黑红红。显然最简单的处理方式是把其改为:红黑红
处理:
1.将P和U节点改为黑色
2.将PP改为红色
3.将PP设置为当前节点,进行后续处理
插入情景4.2:叔叔结点不存在或为黑结点,并且插入结点的父亲结点是祖父结点的左子结点
注意:单纯从插入前来看,叔叔节点非红即空(NIL节点),否则的话破坏了红黑树性质5,此路径会比其它路径多一个黑色节点。
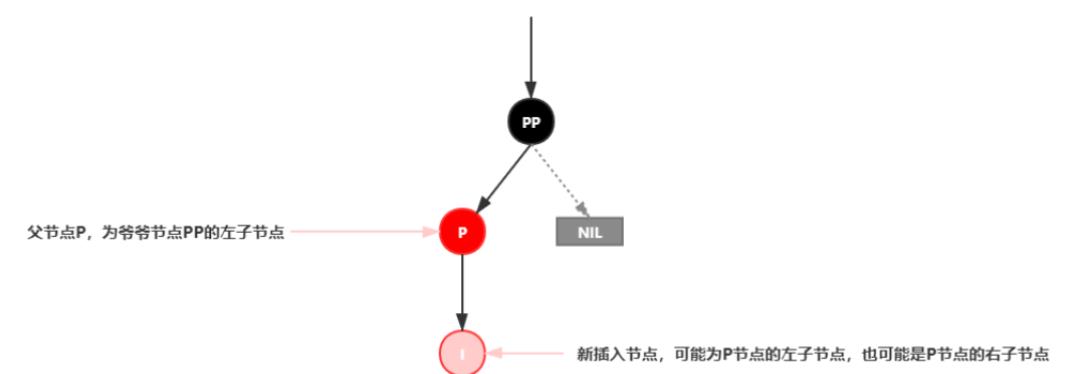
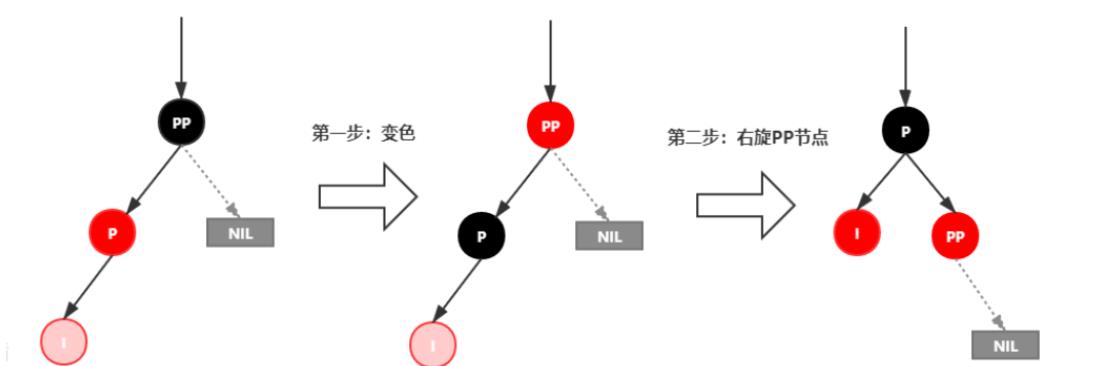
插入情景4.2.1:新插入节点,为其父节点的左子节点(LL红色情况)
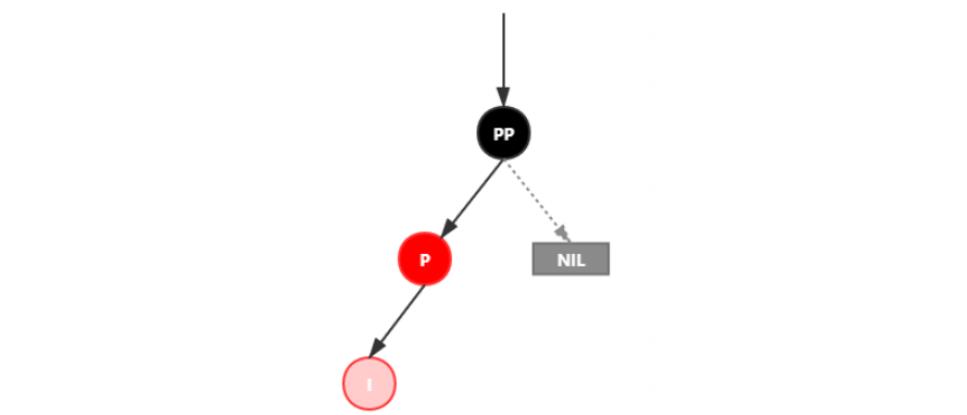
处理:
1.变颜色:将P设置为黑色,将PP设置为红色
2.对PP节点进行右旋
插入情景4.2.2:新插入节点,为其父节点的右子节点(LR红色情况)
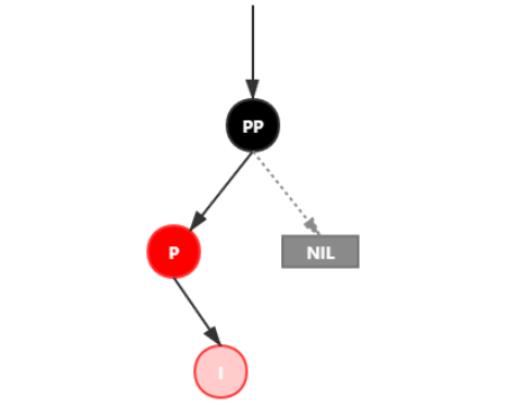
处理:
1.对P进行左旋
2.将P设置为当前节点,得到LL红色情况
3.按照LL红色情况处理(1.变颜色 2.右旋PP)
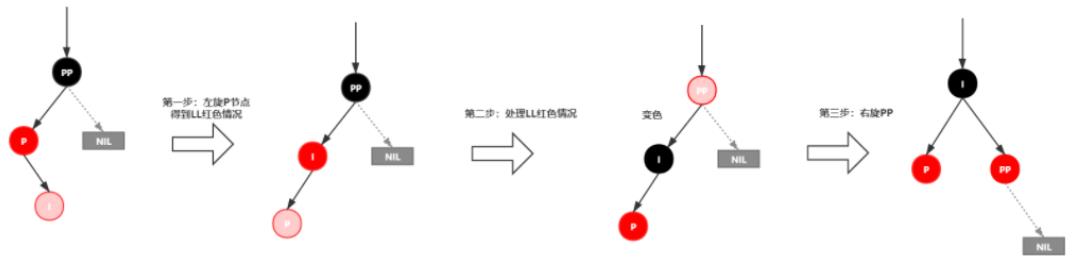
插入情景4.3叔叔结点不存在或为黑结点,并且插入结点的父亲结点是祖父结点的右子结点
该情景对应情景4.2,只是方向反转,直接看图。

插入情景4.3.1:新插入节点,为其父节点的右子节点(RR红色情况)
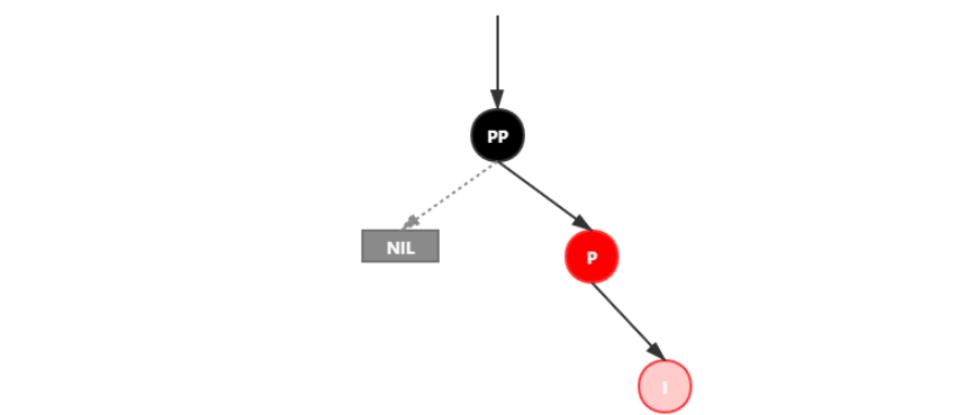
处理:
1.变颜色:将P设置为黑色,将PP设置为红色
2.对PP节点进行左旋
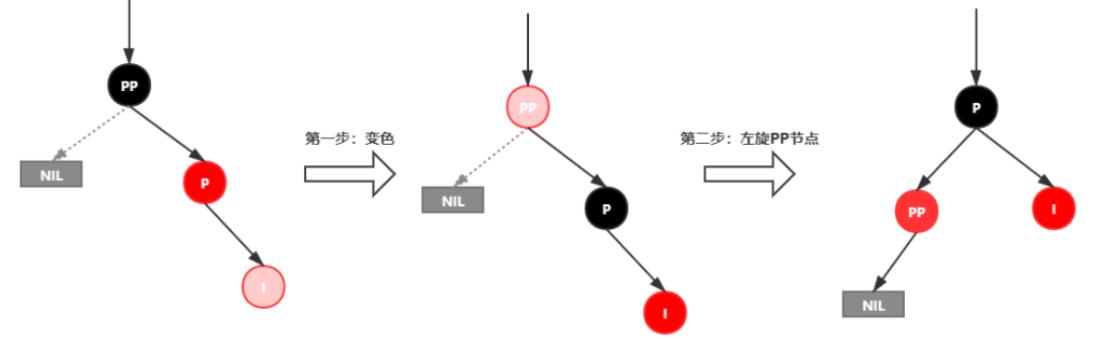
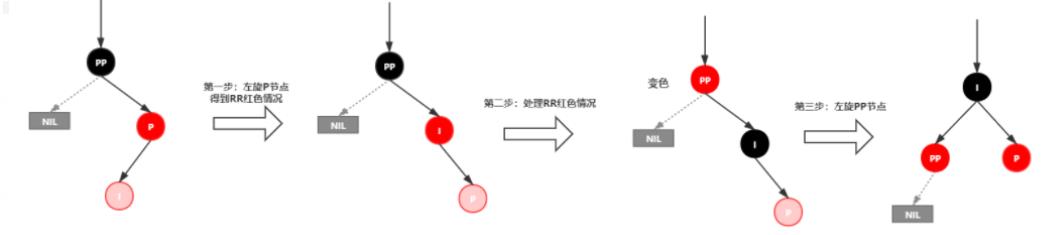
插入情景4.3.2:新插入节点,为其父节点的左子节点(RL红色情况)
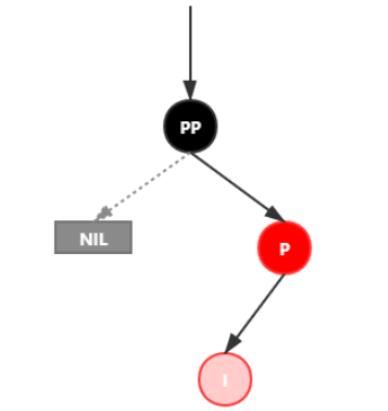
处理:
1.对P进行右旋
2.将P设置为当前节点,得到RR红色情况
3.按照RR红色情况处理(1.变颜色 2.左旋PP)
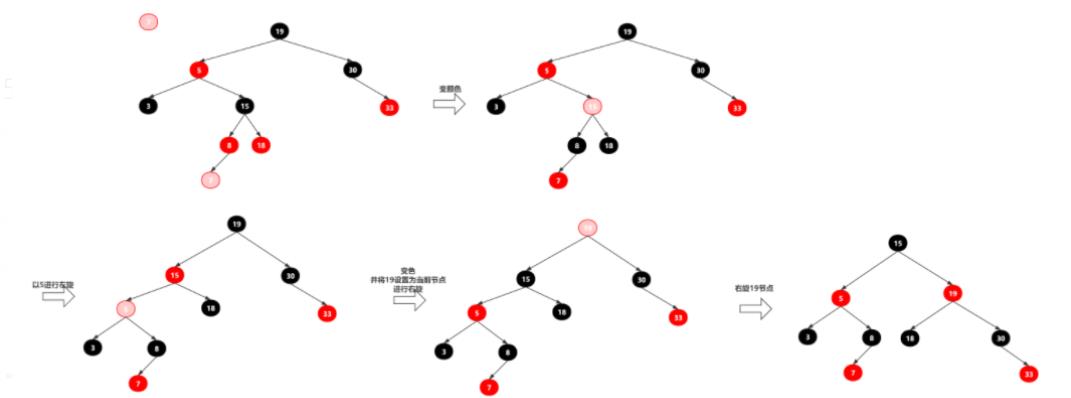
红黑树案例分析
以上是关于JDK1.8的HashMap底层红黑树实现的主要内容,如果未能解决你的问题,请参考以下文章