搜索引擎怎么搜不到信息了?互联网正在孤岛化吗?|图文
Posted 柴知道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索引擎怎么搜不到信息了?互联网正在孤岛化吗?|图文相关的知识,希望对你有一定的参考价值。

搜索引擎里的信息为何越来越少?互联网为什么变成了一座座信息孤岛?
视频版
↓↓ 看完这个视频就知道了 ↓↓
↑↑ 信我,真的超级好看 ↑↑
图文版
我们需要先简单地了解一下,搜索引擎是怎么搜信息的。
搜索引擎中最基础的工具,叫做「爬虫」。
「爬虫」搜信息跟你用浏览器上网差不多,都是先向服务器发送请求,获得返回的页面,然后从中筛选出有价值的内容。

比如这就是一个简单的爬虫。这行代码相当于把网址链接输入浏览器,获得豆瓣电影排行榜的文本内容:
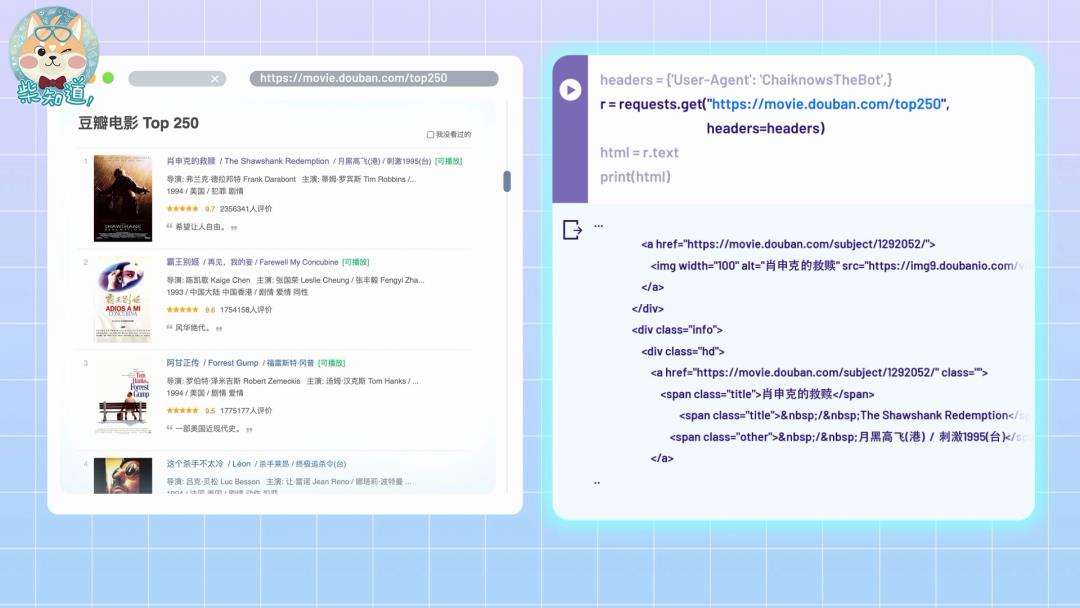
再使用一些解析工具,就能找到你要的信息:

不过这只适用于简单的静态网页。而像柴司的B站主页属于动态网页,此时就需要借助浏览器的渲染工具才能获取到有用的信息。
比如这行代码,就能让爬虫借助 Chrome 框架来渲染爬取的网页,顺利获取动态渲染的内容。

只要几分钟的时间,你就能写出这些简单的爬虫。
每年三月,虚拟世界都会出现“三月爬虫”的壮观景象——因为临近毕业的学生都在临时抱佛脚,爬取数据写论文~

一些技巧足够娴熟,又没把技术用对地方的朋友,还能给自己甚至整个公司都赢得包吃包住的待遇。
当然,搜索引擎的工程架构高度复杂,我们刚才所说的只是这个架构中的一个部分而已。
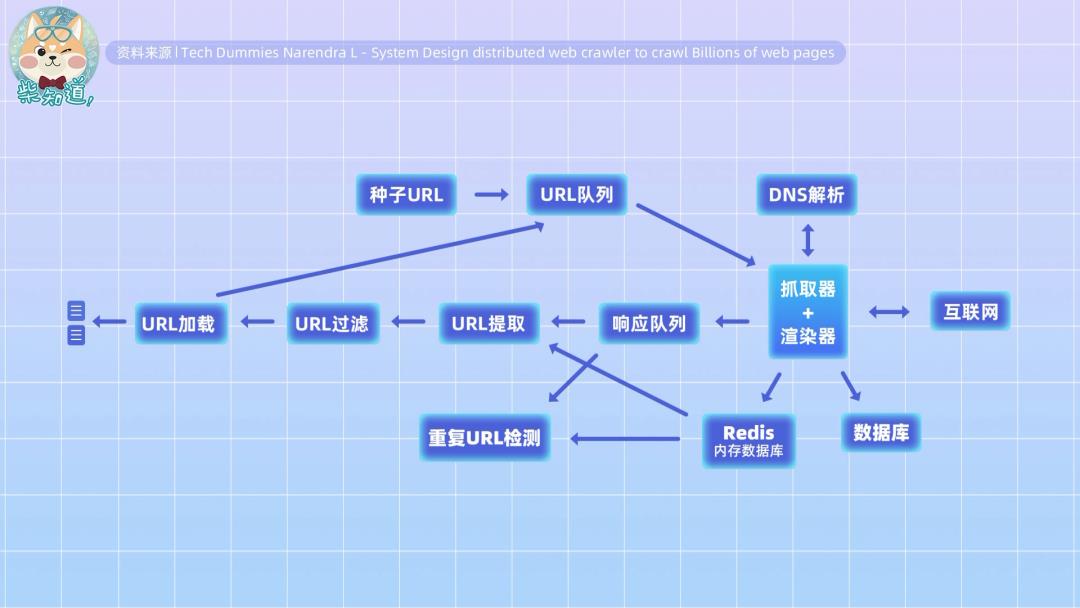
但至少从理论上来说,只要时间与资源足够,网上的绝大部分内容都能被搜索引擎的爬虫爬取到。
那为什么搜索引擎还是搜不到这些内容呢?
因为有人限制了爬虫。
并不是所有的信息都愿意被爬虫搜集,所以爬虫与网站之间有一套行业默认的协议:robots协议。
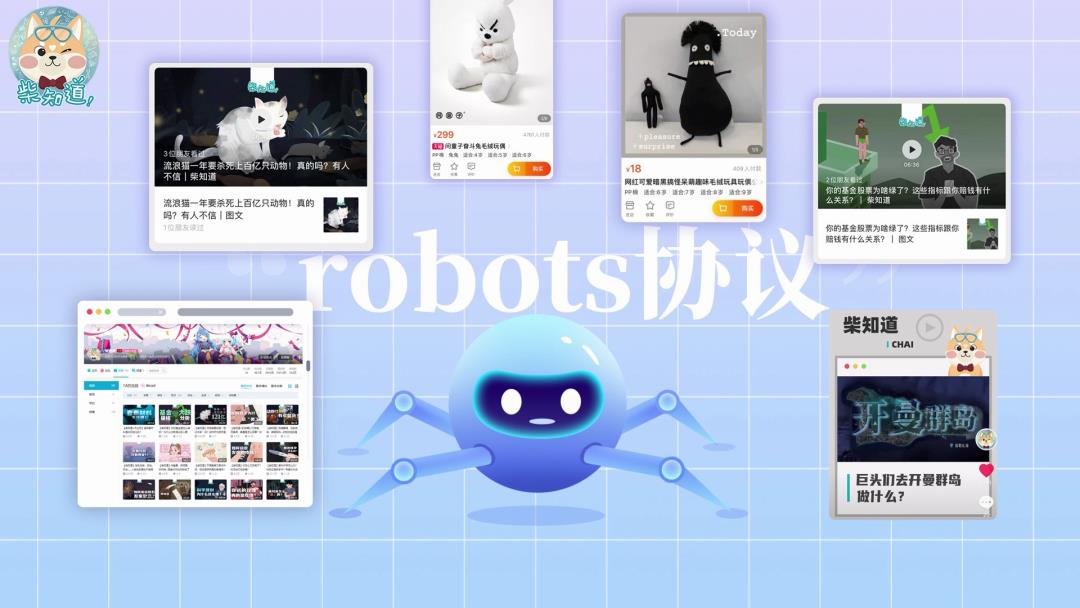
你可以在许多网站的根目录里看到这样的robots协议,它会告诉爬虫哪些内容可以爬取,哪些不能。

比如这是B站个人主页的robots协议,它规定如果是这些白名单里的爬虫,就可以爬你主页的内容。

另一大内容源今日头条也差不多:它的 robots 协议只允许自己家的爬虫获取信息,其他爬虫统统禁止。

不过,robots 协议其实只是一个“君子协定”,因为它并不是强制要求,而且没有从技术上阻挡爬虫的能力。

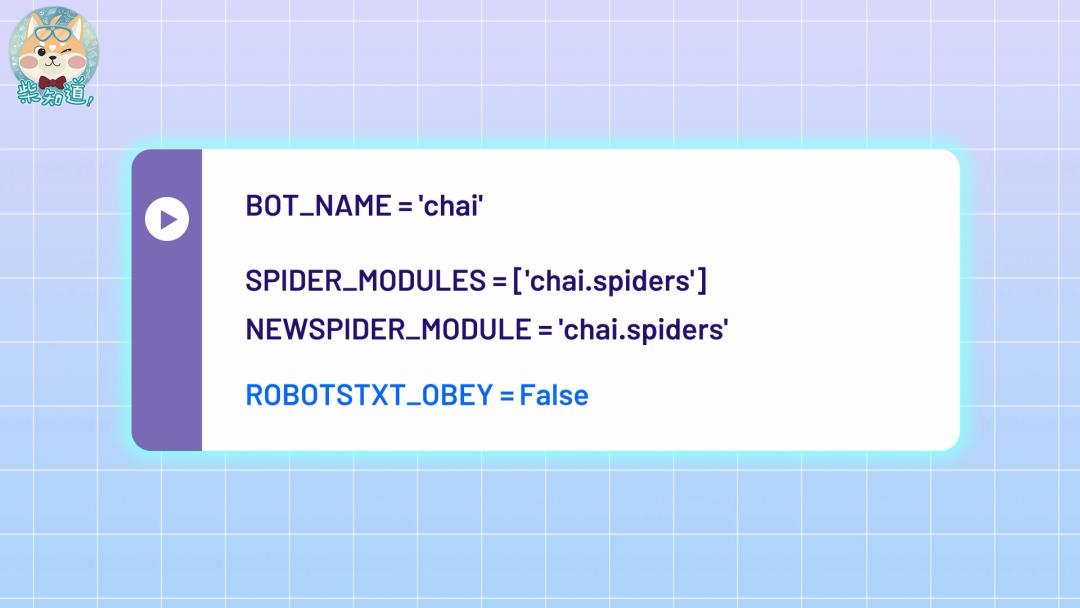
比如你自己在使用一些爬虫框架的时候,只需要把这个参数调整成 False,你的爬虫就会忽视掉 robots 协议,爬取信息。
那为什么搜索引擎公司不这么干呢?
因为法律不允许。

robots 协议虽然不是法律条文,但作为被广泛接受的行业规则,在法庭上也受到了认可。
比如 360 就曾无视 robots 协议抓取百度的内容。而法院在判决中认为, robots 协议是业内公认应该被遵守的商业道德,所以判决 360 赔偿百度 70 万元。

当然,两家公司当时的缠斗也并没有因此结束。

有时候,即便搜索引擎遵守了 robots 协议,也仍然可能因为爬虫内容使用不当而遭到起诉。
比如百度和大众点评的案件中,法院认为百度虽然遵守了大众点评的 robots 协议,但是却将爬取的内容用于充实百度地图和百度知道的内容,其行为具有明显的“搭便车”、“不劳而获”的特点,属于不正当竞争,最终被判赔偿 300 余万元。

所以,只要 robots 协议不让搜索引擎爬取信息,那么哪怕搜索引擎想爬,有能力爬,那也不敢爬。
不过,还要再问一个问题:
为什么越来越多的公司,都不让搜索引擎搜自己平台上的信息呢?
其实在过去,网站们大多希望被搜索引擎收录,获取流量。
比如早年间,你是可以通过百度直接搜索淘宝商品的。在当时,搜索引擎和其他公司之间是相互合作的关系。

但随着利益关系的转变,这种关系不复存在。淘宝在 2007 年屏蔽了百度,就是认为百度并没有给淘宝带来直接的交易量。

而在移动互联网时代,这种利益关系变得更为脆弱:各家公司都希望把你的时间和数据留在自己的应用里,而不是送给搜索引擎。

例如,如果你能在常用的搜索引擎里面搜淘宝商品,那淘宝就很难获取你的行为数据;而在淘宝上搜索,淘宝就能根据数据给你推荐个性化的商品……和个性化的广告。

反过来说,为了增加你停留在搜索页面的时间,谷歌等搜索引擎能让你在不跳转页面的情况下显示问题答案,这对于我们来说是方便了,但对于很多网站来说却很不划算。
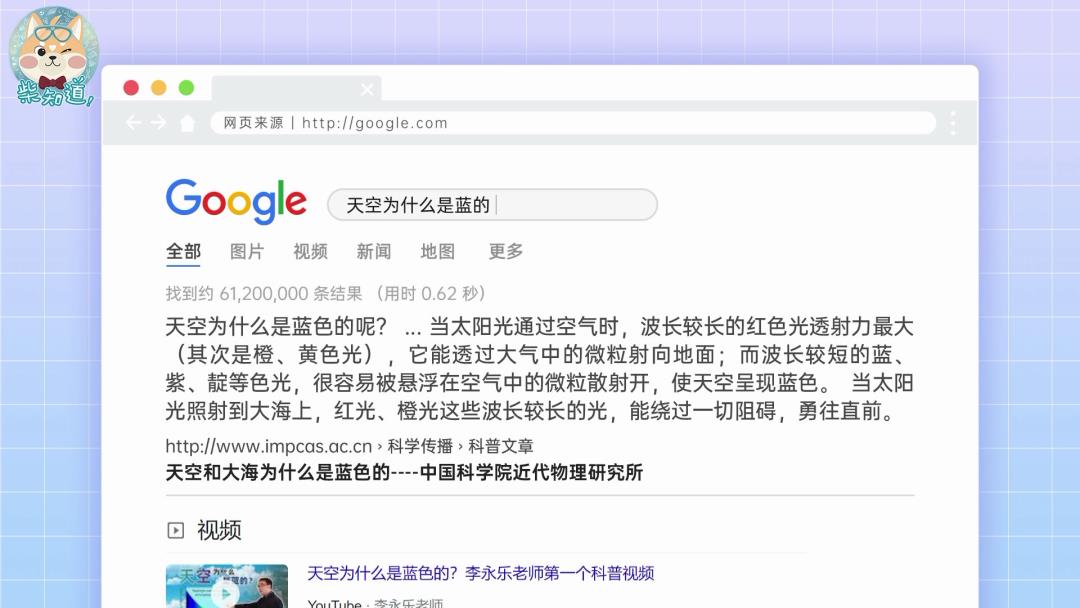
为了解决这些问题,一些搜索引擎选择自建内容体系,再把搜索结果导向自己的内容池,解决信息割裂的问题,同时把流量留在自己手里——但效果似乎也不太好。
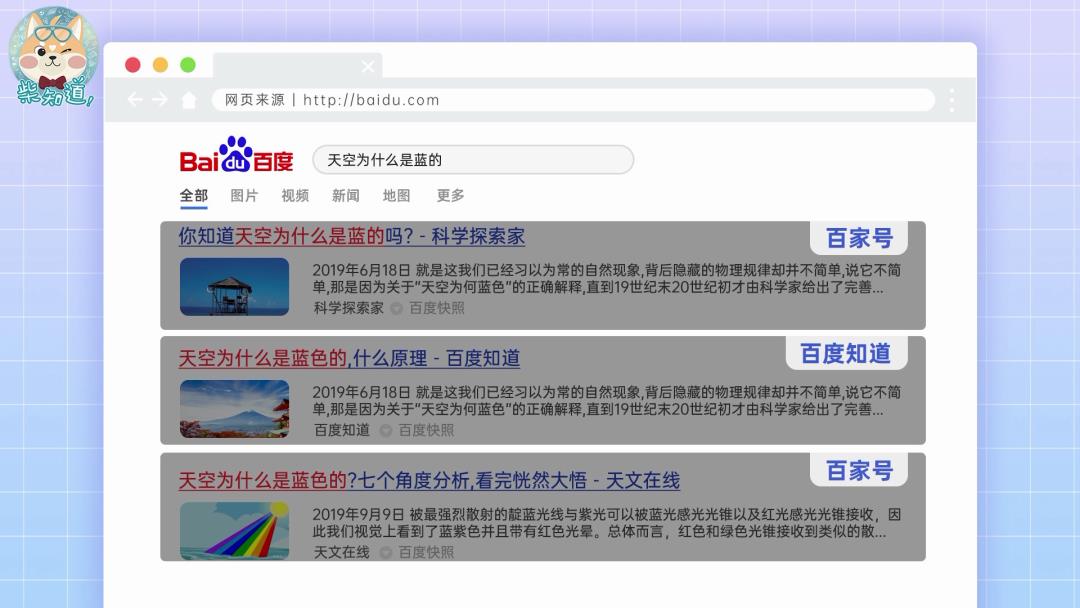
总之,最初的搜索引擎和其他公司间是相互合作的关系。但随着商业模式的转变,大家利益不再一致。曾经互联互通的互联网信息,就被圈在了一个个信息孤岛上。

我们希望互联网的未来,不会如此。
以上是关于搜索引擎怎么搜不到信息了?互联网正在孤岛化吗?|图文的主要内容,如果未能解决你的问题,请参考以下文章