Zetta:HBase用户的新选择,当知乎遇上TiDB生态
Posted TiDB_PingCAP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zetta:HBase用户的新选择,当知乎遇上TiDB生态相关的知识,希望对你有一定的参考价值。
本篇文章整理自知乎在线基础架构负责人白瑜庆在 PingCAP Infra Meetup 上的演讲实录。本文讲述了知乎与 TiDB 的渊源,介绍了一款基于 TiDB 生态研发的开源产品 Zetta,能够在规避 HBase 性能问题同时,减小 TiDB 部署后分布式架构下的系统延迟。
背景概况
BigTable 数据模型
在开始介绍 Zetta 之前,我们先来看看 BigTable。BigTable 是一个稀疏的多维度的有序的表(Sparse multidimensional sorted map),它是谷歌开发的用来解决数据量庞大的场景下的数据索引问题的数据模型。谷歌爬虫的数据量非常大,BigTable 不仅能提供满足其业务场景的低延时存储服务,同时,在开发效率上,还提供了宽列能力,即数据结构化,对于开发十分友好。目前,BigTable 被应用于 Google Earth、Google Analytics、Personalized Search 等需要进行数据分析的场景。
知乎面临的挑战
当知乎发展到 2016、2017 年的时候,随着业务增长,遇到了很多和 Google 类似的问题。在数据规模持续增长的环境下,很多的场景其实呈现的是 NoSQL 的场景,它并不是一个非常严格的关系型的场景。
举个例子,知乎的 Redis 现在已经有了三万到四万左右个实例。如果对它们做微服务化改造,服务之间的调用会非常频繁。而对于某些在线服务,它要求低延迟,高吞吐,高并发。
比如首页已读的服务,需要在首页展示时过滤掉用户已读的数据。每次知乎展示的首页的数据是用户维度加上内容维度的一个非常大的数据集。这其中还包括 AI 用户画像服务,用户画像是一个非常稀疏的数据,它储存了用户对哪些内容感兴趣的一个非常稀疏的表。这些场景不断对我们的基础设施产生冲击。
引入 HBase
在那个时期知乎最终选择了 HBase。HBase 是一个优秀的 BigTable 的开源实现,它有很成熟的生态。但是同时它也有一些小问题,如不支持跨行事务、二级索引不完善等。
尽管可以利用第三方的组件来解决(比如 Phoenix ),但同时也会产生新的问题:系统组件非常多,维护起来很复杂。知乎在使用过程中也遇到了一些问题。
-
第一,HBase 的使用成本非常的高。要让 HBase 变得好用,需要投入非常专业的工程师团队来调试,这些工程师不仅需要具备相关的知识,还要对 HBase 特别了解。
-
第二,业务接入 HBase 的成本很高。很多时候我们是使用 mysql 或者 NoSQL 进行开发,所以迁移到 HBase 我们需要付出比较大的工作量。
-
第三,HBase 的调优难度很高。举个例子,HBase 的 Cache 和 HDFS 的一些参数调优,需要非常细致地针对业务场景进行调整,难度高。
总结起来,HBase 并不是知乎在当前业务场景下的最优解。事实上,即使知乎团队在非常努力的调优、优化的情况下,HBase 的响应时间仍然一直在剧烈波动。而知乎团队不仅希望响应时间尽可能低,还希望它能够稳定,这一点 HBase 满足不了。
自建 RBase
基于上述情况,在 2017 年前后,知乎利用 K8s、Kafka、Redis、MySQL 等成熟组件研发出了 RBase。RBase 上层是 HBase,底层存储是 MySQL。MySQL 部署在 K8s 上,中间接入 Kafka,然后利用 Cache Through 的方式最大化降低延迟。

但是 RBase 也存在一些问题。在中等数据规模的场景下,MySQL 每次进行 Sharding 以进行集群扩充都非常麻烦。并且由于数据库里的数据是无序的,所以无法比较顺利的进行数据分析。在这种情况下知乎依然开发出了首页已读过滤和反作弊设备指纹功能,并且不断进行迭代。
到 2019 年,知乎的数据量进一步增长,到最后 MySQL 的 Sharding 已经成为这个系统压力最大的地方。所以,RBase 进一步升级,引入了 TiDB 来替换 MySQL。
整体来说 RBase 还是这套架构,但是 MySQL Sharding 的问题彻底解决了,同时这个系统还保证了不错的性能,能够承载更多的服务。但是这又带来一个新的问题:分布式数据库不可避免的会增加系统的延迟。
为了更好的解决上述问题,最后,Zetta 诞生了。
Zetta 的诞生
数据库的三种典型场景:Transactional / Serving / Analytical
在数据库里有三种场景,其中有两种是大家比较熟悉的,事务和分析。事务场景包括金融交易等复杂业务逻辑、强关系模型的场景。分析场景包括像 Adhoc、ETL、报表等场景。但是还有一种场景:Serving 的场景,它用于在线的服务,不存在强关系。

用户画像服务就是 Serving 的一种场景,它可能带有稀疏的宽列,还有实时计算等。而 Zetta 正是在知乎 Serving 场景需求不断增长的背景下诞生的。
Zetta 架构解析
技术发展的最终目标都要服务于价值,成本驱动技术进步。
事务的数据价值很高,大数据的数据价值密度相对较低,而 Serving 是基于中间的一个场景。Zetta 就是在这个价值密度条件下降低查询成本和使用成本的一个成本折中的产品。
知乎的 Zetta 希望成为 TiDB 生态伙伴,因为 TiDB 的生态,不仅是开放的,而且是成熟的。同时,Zetta 也希望可以在 TiDB 的生态里面成为 Serving 场景下的伙伴。
在此之前,我们也有一些权衡,如下图,黑色部分是我们已经做了,橙色是我们正要做的,蓝色是我们现在计划去做的。

Zetta 可以选择一致性的级别,支持在强一致读和弱一致读的选择,当然这是根据业务场景来决定的。Zetta 还支持非事务,比如说它可以为了更极端的性能而放弃对事务的要求。另外,Zetta 在未来将会支持缓存读取,这将带来性能的进一步提升。
在访问模式中,Zetta 支持宽列的模式。宽列就是一个特别宽的表,这个列是可以不断动态增加的,并且还可以选择高表模式或者宽表模式,这两种模式在物理上是不太一样的,但是在 Zetta 中可以设置。另外 Zetta 还使用了聚簇索引以提升性能,此外还有 Hash 打散。
🌟 其他能力
Zetta 还提供了二级索引的能力,同时 Zetta 也不需要多版本,因为多版本有的时候对于开发的同学来说并不重要,所以 Zetta 开发团队在实际场景中把多版本的概念弱化了。同时Zetta 支持多种协议,它不仅本身是可以用 HBase Thrift Server 的方式,也支持 MySQL 和 HBase 原生的方式。

除此之外,Zetta 还与 Flink 打通,使 Zetta 可以作为大数据 Connector。接下来知乎团队还会继续开发数据 TTL。在大数据场景下,数据的 TTL 是非常实际的需求,因为数据非常的多,所以无用的数据需要定期进行清理。
另外,Zetta 还支持全文检索,并且支持 Redis 协议的接入。
🌟 架构概览
下面是 Zetta 的架构图。第一个核心是 TableStore 的 server,它的底层存储是 TiKV,但是知乎团队重新设计了数据的结构,包括表映射 KV 的方法等等。
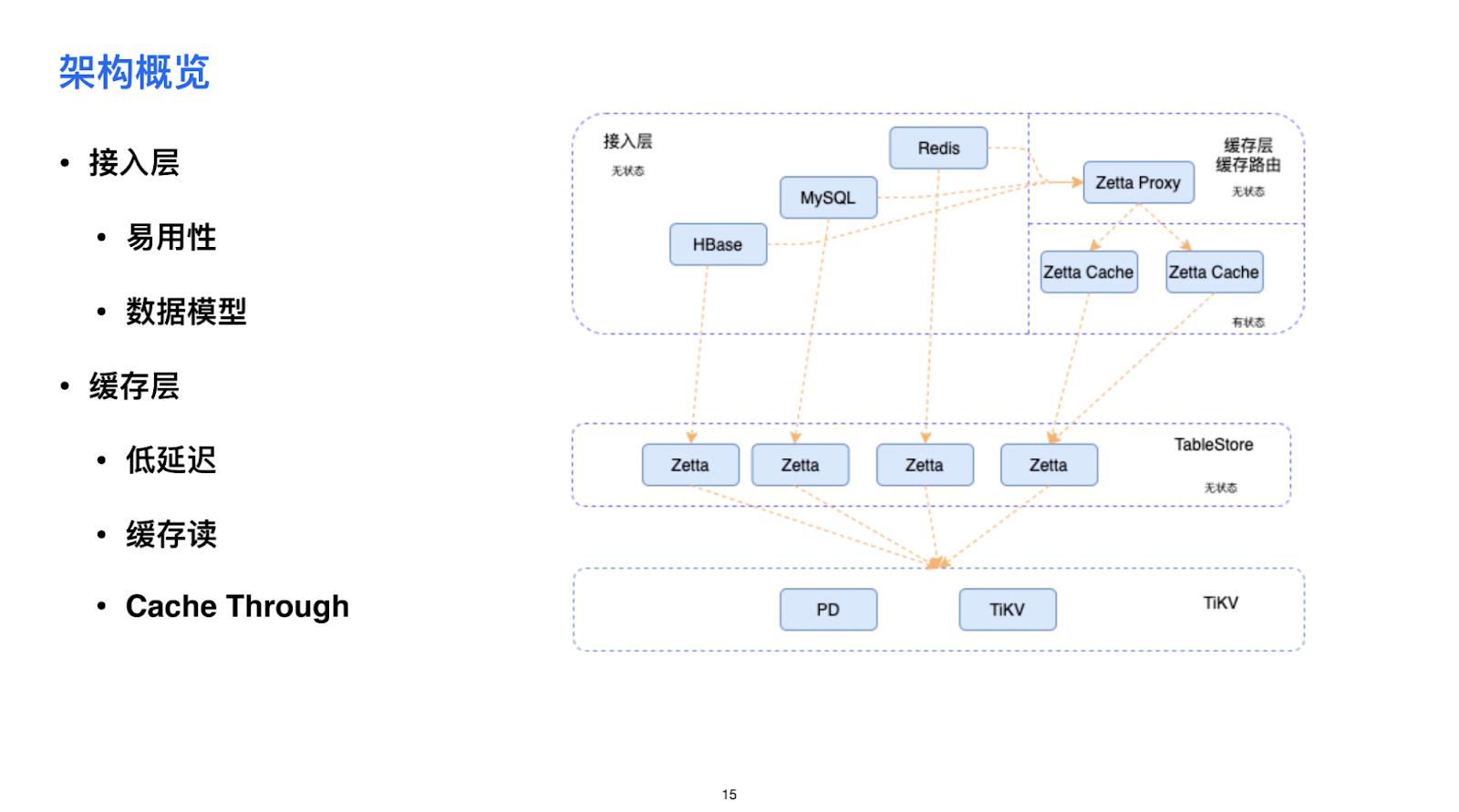
重点说一下接入层,接入层本身是没有状态的,为了提升易用性,Zetta 和上层接入层是通过 grpc 进行通信的。但是对于用户来说,暴露 grpc 接口也不好,上层的数据对用户来说不够友好。易用性是通过 MySQL 或者 HBase 的方式将数据映射到 Zetta 上面去,同时也支持数据模型。
为了做到低延迟,Zetta 实现了一个缓存层,用户写的时候通过 Cache Server 去做缓存,相当于直接写到 Zetta,然后再更新到 KV。数据的读和写都发生在 Proxy 层和 cache 层,但是它们会根据请求做缓存和路由。Zetta 提供了一个完整的解决方案,供开发人员去决定使用哪种方式接入。
Zetta 在知乎的应用
⽣产环境应⽤的收益
Zetta 的投入使用后,给服务的使用方和提供方都带来了非常大的收益。
使用方得到了非常大的性能提升。不仅服务的延迟下降了,响应的时间稳定了,并且实现了降低服务成本和物理成本的目标。
而对于服务的提供方来说,不再需要去考虑其他的组件,只需要维护好 Zetta 和 TiKV 集群,极大降低了维护的成本,同时所需资源成本也大幅降低。除此之外,因为 TiKV 社区非常活跃,开发人员在遇到问题时可以第一时间进行反馈,并且社区会进行修复,一直持续地改进 TiKV。这样 Zetta 便与 TiDB 生态产生了良性的互动,持续地进行基础设施的迭代,互相受益。
具体的情况可以通过一些图表和数据来展示。
⽣产环境应⽤
🌟 已读服务 & 已推服务


在生产环境的应用中,知乎的已读服务,在使用 Zetta 后,延迟从 100ms 下降到 90ms,存储容量也大幅度降低了。已推服务在使用 Zetta 后,也是实现了响应时间和存储量的大幅下降。
🌟 搜索高亮数据
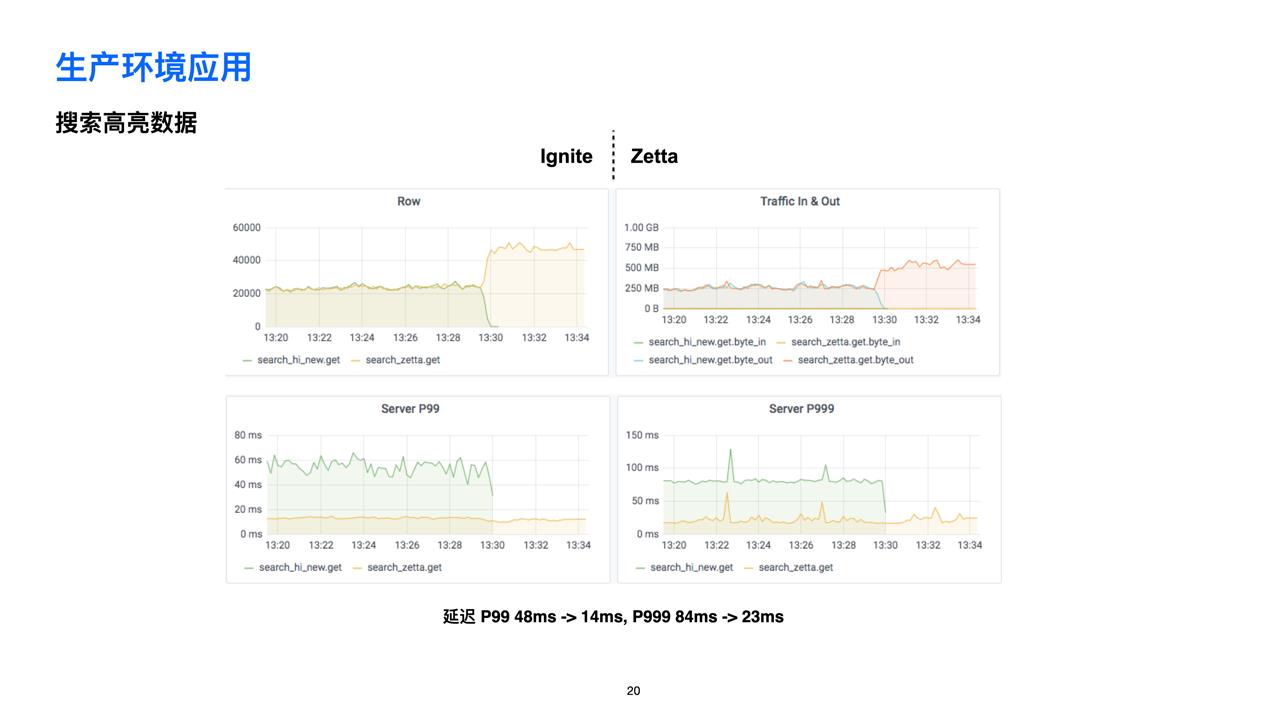
知乎搜索框的搜索高亮数据的服务,它本来是使用一个名叫 Ignite 的分布式数据库,在使用 Zetta 代替后,延迟的时间大幅降低。同时,除了性能的提升外,运维的难度降低了,再也不需要有专门的运维人员去管理 Ignite 数据库了。
🌟 图片元数据服务
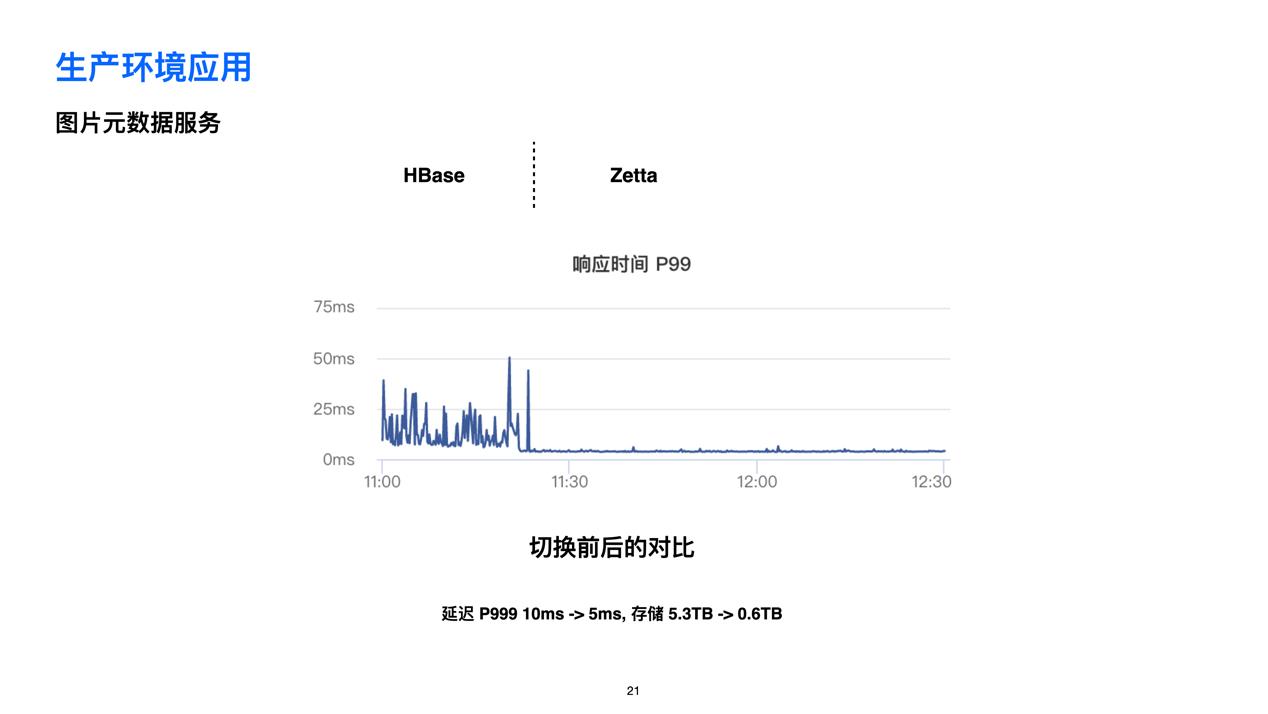
还有一个是 Zetta 在图片元数据服务中的应用。这个图片的意思是,通过实现HBase 到 Zetta 的切换,实现了延迟和存储的大幅降低。其实代码上并没有改变,只是直接把 Thrift server 的地址从 HBase Thrift server 改为 Zetta Thrift server。
可能大家会有疑问,为什么在切换到 Zetta 后服务的延迟和存储需求会降那么多?
-
第一个原因,我们调整 HBase 参数的能力比较有限,知乎 HBase 底层的存储没有压缩。
-
第二个原因,HBase 有很多版本。如果在线上开 Compression,资源消耗是非常可怕的,且其影响是不可控的,所以知乎很少开 Compression。只有在业务低峰的时候,才敢去尝试开一次。
当然,我们被问到最多的问题是说知乎 HBase 的 Compression 需要多长时间。这个其实也不确定,一般是在半夜一点到第二天早晨七点之间可以完成。
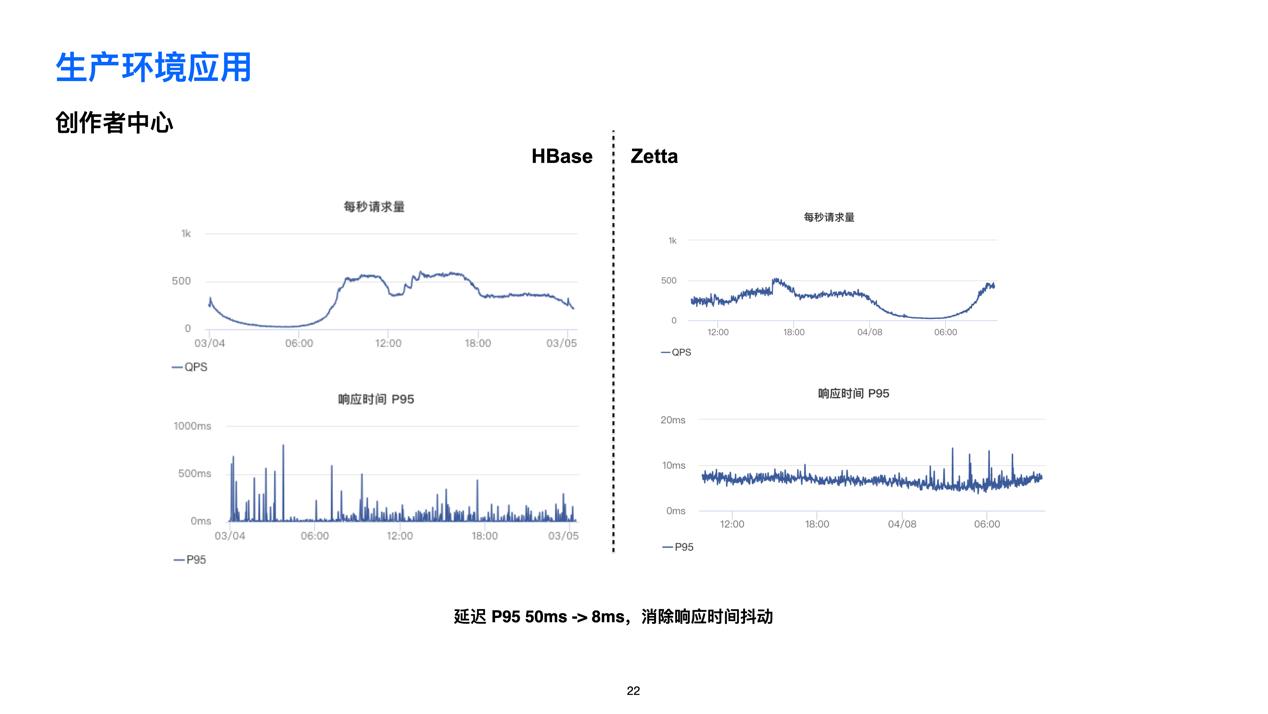
🌟 创作者中心
另外,创造者中心服务也应用了 Zetta。创作者中心是一个展示创作者数据的服务。原来创作者中心的核心数据全部都在 HBase 上,现在通过迁移,数据从原来HBase 里面 NoSQL 表,实现了从 HBase client切到 MySQL client 的改变。
现在,查询的代码可以写的非常清楚,每次查询就是一个 SQL。而在 HBase 里面,这个表非常复杂。所以这样带来两个好处,首先是性能上有所提升,其次也代码更加清晰明了。切换后,服务的延迟降低了,同时也消除了延迟的抖动。
生产环境规划接入服务

下一步,知乎计划把 Zetta 推广到知乎的其他服务上。服务等级分为从高到低的S、A、B 三层。S 可能涉及到的 HBase 集群数可能有4,接入方式有 ThriftServer 或者原生的方式,数据量可能有 120TB。预计当这个服务切换为 Zetta 的时候,存储容量将会有比较大的下降。
Zetta的未来
未来,知乎会对 Zetta 做进一步的提升。
-
第一个是让 Zetta 本身的性能提升,另外是功能上的提升。
-
第二个是知乎会拓展更多的应用,推广 Zetta 在知乎的场景,同时能够形成一些最佳实践。
-
第三个是要去拓展场景。我们现在可能专注于在线上做一些事情,后面会慢慢去找到适合大数据的场景的使用案例作为最佳实践。
-
最后,Zetta 希望在未来可以与 TiDB 进行整合,希望 Zetta 能够成为 TiDB 的生态伙伴。
Zetta 在 GitHub 的项目地址是:https://github.com/zhihu/zetta ,现在最新的代码是在知乎内部的仓库,大家如果对这个项目感兴趣、想交流的,也可以在项目里面联系我们,或者有场景想要接入 Zetta,我们也很乐意帮助大家。
以上是关于Zetta:HBase用户的新选择,当知乎遇上TiDB生态的主要内容,如果未能解决你的问题,请参考以下文章
惊现对抗RTX 3080 Ti的新“利器”,AMD YES!