TiDB 5.0 跨中心部署能力初探 | Joint Consensus 助力 TiDB 5.0 无畏调度
Posted TiDB_PingCAP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TiDB 5.0 跨中心部署能力初探 | Joint Consensus 助力 TiDB 5.0 无畏调度相关的知识,希望对你有一定的参考价值。
TiDB 5.0 已于上周正式发布,在这个大版本更新中提升 TiDB 集群的跨中心部署能力是一个重要的着力点,在共识算法这一层,最激动人心莫过于 Joint Consensus 支持了。这个特性帮助 TiDB 5.0 在跨 AZ 的调度中完全容忍少数派数目的 AZ 不可用。本文会先谈成员变更在 TiDB 历史,然后介绍新特性的设计,最后说下我们在实现过程中遇到的问题和解决方案。
成员变更
TiKV 作为 TiDB 的存储层,负责数据的管理和读写操作。TiKV 将数据划分为大小大致相同的分片,每个分片会有多个副本,分别储存在不同的 AZ (Available Zone) 中,并使用 Raft 算法来保证强一致的读写。当需要做均衡调度时,TiDB 的元数据管理组件 PD 会挑选出需要做调整的分片,并下发命令给 TiKV 完成副本的搬迁。由于 Raft 算法本身有关于在线成员变更的设计,所以搬迁副本很自然地就通过成员变更算法完成了。
TiKV 所使用的 Raft 算法最开始 port 自 Etcd 的 Raft。 Etcd 并未实现完整的 Joint Consensus 算法,它实现的是一个特殊的单步变更(和 Diego Ongaro 在其博士论文里提到的单步变更类似,但是不完全一样)。因此做副本搬迁的时候,整个流程需要分多步完成。
比如,当 PD 决定需要将某副本从 TiKV 2 移到 TiKV 3 时,它会先通过 AddNode 的命令,在 TiKV 3 添加一个新的副本。然后再通过 RemoveNode 命令,将 TiKV 2 上的副本删掉,从而完成变更。理论上也可以先 RemoveNode,再 AddNode 来实现变更,但是这样的操作顺序会导致产生 2 副本的中间状态,而 2 副本无法容忍任意节点宕机,比较危险。
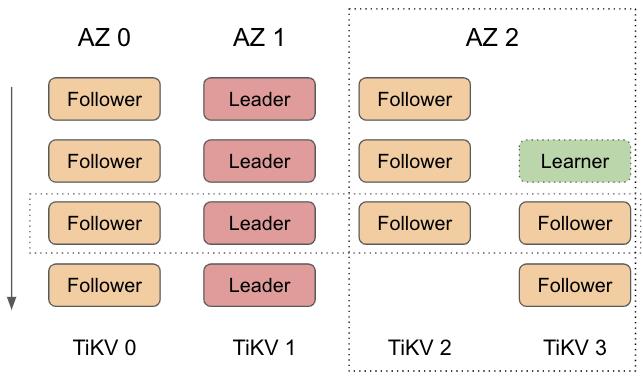
先加后减的步骤虽然只会产生 4 副本的状态,能容忍单节点宕机,但是还不是 100% 可用的。当需要考虑跨 AZ 的场景时,PD 有可能需要将副本搬迁到同一个 AZ 的另一个 TiKV 上。上图中,如果 AZ 2 在 Raft group 4 副本状态时不可用了,就只剩下 AZ 0 和 AZ 1 的 2 副本,无法形成 quorum,导致整个 Raft group 不可用。在 5.0 以前的实现里,我们引入了 learner 角色,并在进入 4 voter 之前,先通过 AddLearner 命令将要添加的副本作为 learner 角色添加到 Raft group 里。 等追上足够的数据,再进行先加后减的操作。这样的步骤可以极大减少 4 副本存在的时间窗口(顺利的话是毫秒级),但是依然不是 100% 可用的。
Joint Consensus
其实 Raft 论文里早已提供了 100% 可用的成员变更算法:Joint Consensus。我们用 C(a, b, c) 表示一个分别拥有 a、b、c 三个副本的 Raft group。当要从 C(a, b, c) 变更成 C(a, b, d),引入一个中间状态 joint C(a, b, c) & C(a, b, d)。当 group 处于 joint 状态时,日志只有在两个成员列表里都复制到 quorum 才能算 commit。要进行变更时,先从 C(a, b, c) 变更成 C(a, b, c) & C(a, b, d)。每个节点收到这个命令时,立刻将本地成员变更成 joint 状态。当这个命令被 commit 以后,再提交一个新的命令退出 joint 状态,从 C(a, b, c) & C(a, b, d) 变成 C(a, b, d)。关于这个算法的正确性证明已经超出了本文的范畴,感兴趣的可以参阅 Raft 论文。
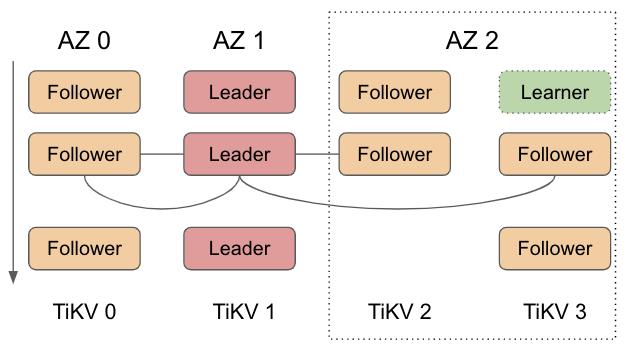
由于 quorum 是基于两个 3 副本的成员列表来计算的,中间 joint 状态和上文提到的多次单步变更一样,可以容忍任意单节点宕机。和多次单步操作相比,joint 还能实现 100% 可用。例如图中 4 副本状态,AZ 2 不可用会导致 2 个节点不可用,但是对于两个 3 副本成员列表来说都只是单节点不可用,所以 joint 状态下还是可以保持可用。
落地
上文我们提到,Etcd 的 Raft 算法实现和 Diego Ongaro 在论文里提到单步变更的不一样。其实 Etcd 算法实现在博士论文之前就开始做了,主要区别在于成员变更日志只有被 commit 以后才会被真正执行。而论文里的做法是收到就立刻执行。我们从 3.0 便开始调研 joint consensus 的可行性。我们最开始的做法是与论文完全保持一致,但是带来的兼容性问题和调整实在太多了。与此同时,CockroachDB 也开始给 Etcd 添加了早期的 Joint Consensus 支持。我们最终决定拥抱社区,和 Etcd 保持一致,一起进行优化和测试。
Etcd 的 Joint Consensus 实现并不完全和论文一致,而是继续延续了上面提到的做法,commit 才执行。这样的好处是成员变更日志和普通日志处理逻辑没有区别,可以使用统一的流程。由于 commit 以后的日志不会被复写,所以也不需要像收到即执行那样做特殊的变更回退,实现起来更简单。但是由于 commit 信息只有 leader 才有,所以特殊场景下由于信息同步不及时会出现可用性的 bug。感兴趣的同学可以去 Etcd 项目查看我们提交的相关 issue12。这里只举一个其中简单的例子。假设某个 joint 状态 C(a, b, c) & C(a, b, d),a 是 leader。如果退出 joint 的命令被复制到 a、b、c 以后,a 可以认为命令已经被 commit,并将 commit index 同步给 c 以后就 crash 了。所以 c 会执行 commit log,认为 joint 已经退出,从而把自己删除;b、d 并不知道 joint 退出命令已经被 commit,当发起选举时会依然会寻求两个 quorum 的投票。但是 a 已经 crash、c 已经自毁了,所以 b、d 无法从 (a, b, c) 中获得 quorum 投票,从而不可用。
这些问题最终导致和原始论文比,commit 才执行的 Joint Consensus 实现添加了两个限制:
1. Voter 被移除之前需要先降级成 Learner。
2. 选举时加入同步 commit index 机制。
再来看上文举的例子,由于 voter 不会被直接删除,所以 c 不会把自己删除,而是成为一个 learner。当 b 向 c 寻求投票时,会获知最新的 commit index,得知 joint 状态已经退出,从而只会尝试从 C(a, b, d) 中寻找 quorum,最终成功选举。
总结
在 5.0 我们添加了 Joint Consensus 支持,实现了跨 AZ 调度过程中能完全容忍少数派数目的 AZ 不可用。Raft 算法本身比较清晰简单,但是落地在工程上会有不同的调整和取舍。如果你对于解决分布式系统中类似的问题非常感兴趣,欢迎参与我们的项目 TiKV、raft-rs,或简历发送至 jay@pingcap.com 直接加入我们。
以上是关于TiDB 5.0 跨中心部署能力初探 | Joint Consensus 助力 TiDB 5.0 无畏调度的主要内容,如果未能解决你的问题,请参考以下文章
实践案例 | 用Kube-OVN实现跨K8s的统一网络平面部署TiDB
SUSE 发布 NeuVector 5.0,从数据中心云端到边缘全面拓展云原生安全能力