常用中间件
Posted 07zhywjh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用中间件相关的知识,希望对你有一定的参考价值。
什么是中间件:
中间件是为应用提供通用服务和功能的软件。数据管理、应用服务、消息传递、身份验证和 API 管理通常都要通过中间件。
中间件的分类(我自己归类不一定准确):
1.接入层中间件
2. 缓存中间件
3 文件存储中间件
4 数据库中间件
5. 消息中间件
6.搜索中间件
7.引擎类中间件
8.调度类中间件
9.服务治理中间件
10.AMP中间件( Application Performance Management)
11.大数据中间件
一 接入层中间件
nginx :一个高性能的HTTP和反向代理web服务器,解决了c10k问题
openrestry: 通过lua脚本扩展nginx功能,可提供负载均衡、请求路由、安全认证、服务鉴权、流量控制与日志监控等服务
Kong:一款基于OpenResty(Nginx + Lua模块)编写的高可用、易扩展的,由 Mashape公司开源的API Gateway项目。Kong是基于NGINX和Apache Cassandra 或PostgreSQL构建的,能提供易于使用的RESTful API来操作和配置API管理系 统, 所以它可以水平扩展多个Kong服务器,通过前置的负载均衡配置把请求均 匀地分发 到各个Server,来应对大批量的网络请求
由于nginx基于c开发如果要扩展不熟悉c的开发成本比较高,而kong和openrestry 基于lua,lua比较简单基本一看就会
tengine: 由淘宝网发起的Web服务器项目。它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性
haproxy: HAProxy是支持虚拟主机的,可以工作在4、7层(支持多网段)
HAProxy负载均衡策略非常多8种
lvs: 抗负载能力强、是工作在网络4层之上仅作分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件里的性能最强的,对内存和cpu资源消耗比较低
keepalived: 高可用(ip漂移),生产中一台性能好,一台性能差以便恢复后能漂移回去
slb:
cdn:
h5:
二 缓存中间件
JVM级别
guava: FIFO:先进先出 ,LRU:最近最少使用算法,LFU:最近最少频 率使用
ehcache : 覆盖guava的所有功能,可以持久化可以集群
caffeine : Caffeine是基于Java8,对Guava缓存的重写版本
非JVM级别
redis: 主从模式,主备模式(哨兵),分片(一致性hash);AKF集群拆 分;缓存击穿,缓存穿透,缓存雪崩,布隆过滤器,分布式锁 ;8种数 据类型 bitmap处理日活月活;redis事务
memcached: 数据类型单一,能够无缝集成其它组件比如mysql,单节点性能极高,处理大 数据(大于10K)
es: 比如大量坐标计算 还不用做双写一致性
nginx: 把url当中key作为缓存服务器, 可以再url后面加一串随机数避免客户端缓存(秒杀种的 点亮按钮)
三 文件存储中间件
fastdfs
hdfs
oos
es
四 数据库中间件
mycat:不推荐使用
shardingsphere
ShardingSphere-JDBC :数据水平扩展
ShardingSphere-Proxy: 分布式事务
ShardingSphere-Sidecar(TODO):分布式治理
五 消息中间件
我们为什么用消息中间件?
削峰填谷:
应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮。有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大大提到系统的稳定性和用户体验。
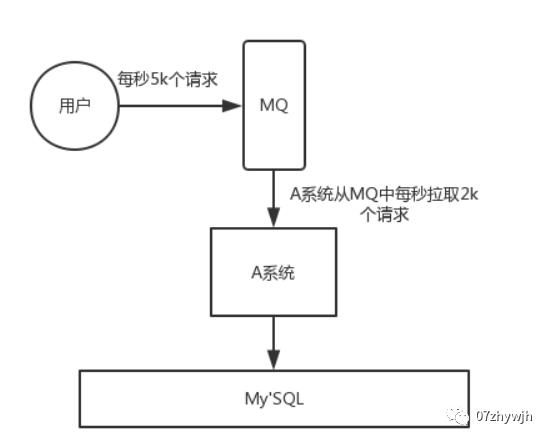
一般情况,为了保证系统的稳定性,如果系统负载超过阈值,就会阻止用户请求,这会影响用户体验,而如果使用消息队列将请求缓存起来,等待系统处理完毕后通知用户下单完毕,这样总不能下单体验要好。
处于经济考量目的:
业务系统正常时段的QPS如果是1000,流量最高峰是10000,为了应对流量高峰配置高性能的服务器显然不划算,这时可以使用消息队列对峰值流量削峰
应用解耦:
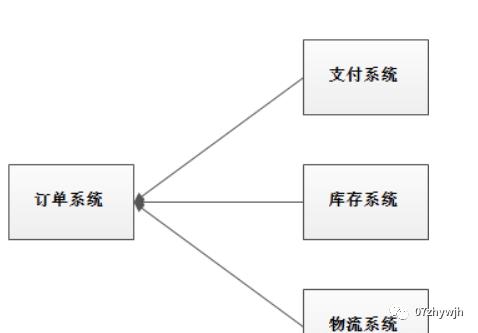
系统的耦合性越高,容错性就越低。以电商应用为例,用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障或者因为升级等原因暂时不可用,都会造成下单操作异常,影响用户使用体验。
使用消息队列解耦合,系统的耦合性就会提高了。比如物流系统发生故障,需要几分钟才能来修复,在这段时间内,物流系统要处理的数据被缓存到消息队列中,用户的下单操作正常完成。当物流系统回复后,补充处理存在消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故障。
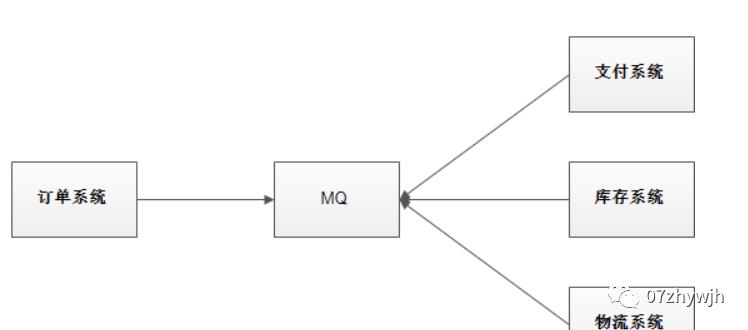
数据分发:
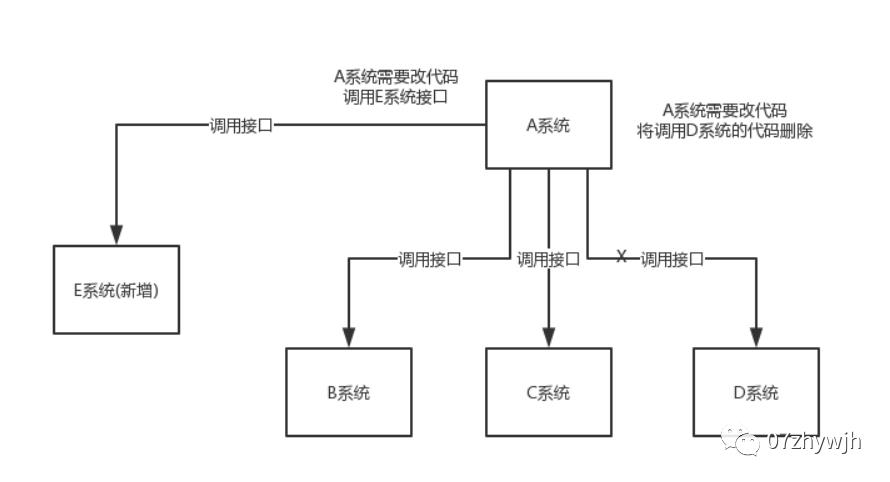
通过消息队列可以让数据在多个系统更加之间进行流通。数据的产生方不需要关心谁来使用数据,只需要将数据发送到消息队列,数据使用方直接在消息队列中直接获取数据即可
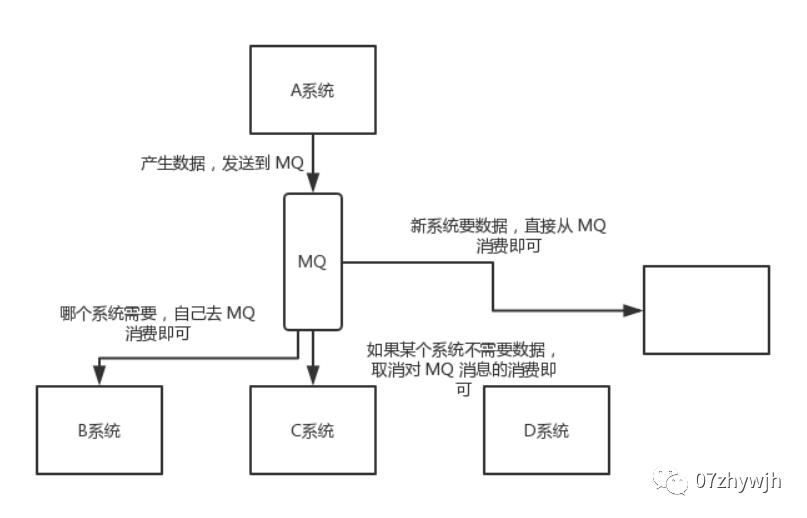
kafaka:
顺序读写
kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能
顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写
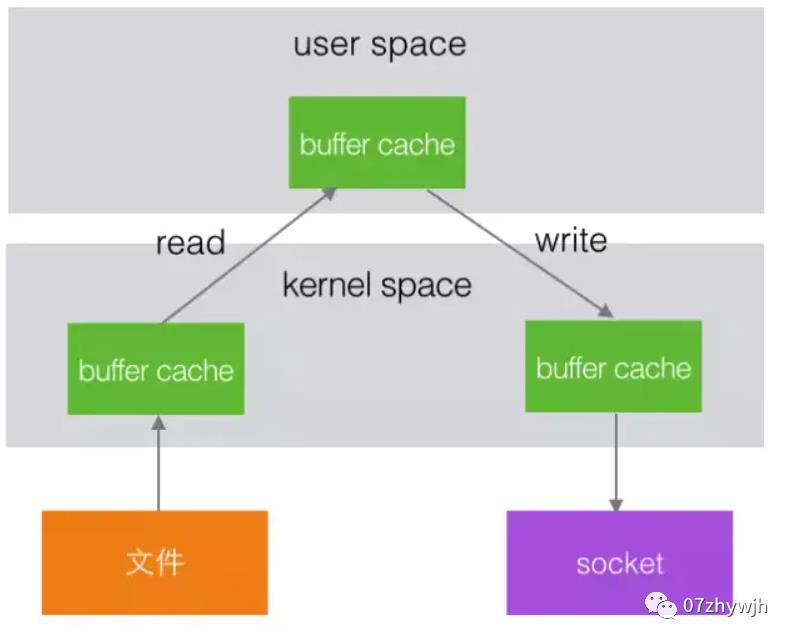
零拷贝
平时从服务器读取静态文件时,服务器先将文件从复制到内核空间,再复制到用户空间,最后再复制到内核空间并通过网卡发送出去,而零拷贝则是直接从内核到内核再到网卡,省去了用户空间的复制。
分区
kafka中的topic中的内容可以被分为多分partition存在,每个partition又分为多个段segment,所以每次操作都是针对一小部分做操作,很轻便,并且增加并行操作的能力
批量发送
kafka允许进行批量发送消息,producter发送消息的时候,可以将消息缓存在本地,等到了固定条件发送到kafka 如 一段时间发送一次,息条数到固定条数后
数据压缩
Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩。压缩的好处就是减少传输的数据量,减轻对网络传输的压力。Producer压缩之后,在Consumer需进行解压,虽然增加了CPU的工作,但在对大数据处理上,瓶颈在网络上而不是CPU,所以这个成本很值得
Kafka的设计目标是高吞吐量,它比其它消息系统快的原因体现在以下几方面:
1、Kafka操作的是序列文件I / O(序列文件的特征是按顺序写,按顺序读),为保证顺序,Kafka强制点对点的按顺序传递消息,这意味着,一个consumer在消息流(或分区)中只有一个位置。
2、Kafka不保存消息的状态,即消息是否被“消费”。一般的消息系统需要保存消息的状态,并且还需要以随机访问的形式更新消息的状态。而Kafka 的做法是保存Consumer在Topic分区中的位置offset,在offset之前的消息是已被“消费”的,在offset之后则为未“消费”的,并且offset是可以任意移动的,这样就消除了大部分的随机IO。
3、Kafka支持点对点的批量消息传递。
4、Kafka的消息存储在OS pagecache(页缓存,page cache的大小为一页,通常为4K,在Linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问)
rabbitmq
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现
MQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
可靠性(Reliability)
RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。灵活的路由(Flexible Routing)
在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。消息集群(Clustering)
多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。高可用(Highly Available Queues)
队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。多种协议(Multi-protocol)
RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。多语言客户端(Many Clients)
RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。管理界面(Management UI)
RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。跟踪机制(Tracing)
如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。插件机制(Plugin System)
RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
Exchange 分发消息时根据类型的不同分发策略有区别,目前共四种类型:direct、fanout、topic、headers
队列中的消息在以下三种情况下会变成死信 (1)消息被拒绝(basic.reject 或者 basic.nack),并且requeue=false; (2)消息的过期时间到期了;(3)队列长度限制超过了。通过配置死信队列的转发规则达到延迟消息
Rocketmq相比于Rabbitmq、kafka具有主要优势特性有:
支持事务型消息(消息发送和DB操作保持两方的最终一致性,rabbitmq和kafka不支持)
支持结合rocketmq的多个系统之间数据最终一致性(多方事务,二方事务是前提)
支持18个级别的延迟消息(rabbitmq和kafka不支持)
支持指定次数和时间间隔的失败消息重发(kafka不支持,rabbitmq需要手动确认)
支持consumer端tag过滤,减少不必要的网络传输(rabbitmq和kafka不支持)
支持重复消费(rabbitmq不支持,kafka支持)
选择:成熟团队(kafka),不是(rabbitmq),rocketmq(非得用事物消息)
六 搜索中间件 (es)
正排索引 :
倒排索引
压缩
字典树
优化
七 引擎类中间件
规则引擎
Drools
URule
流程引擎
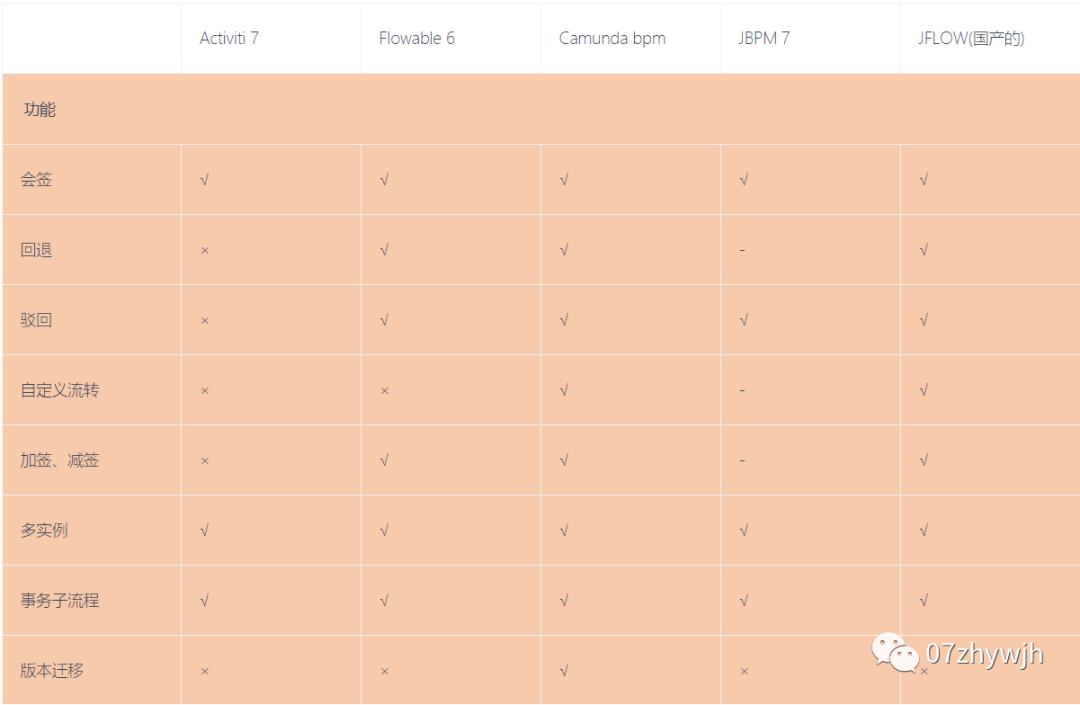
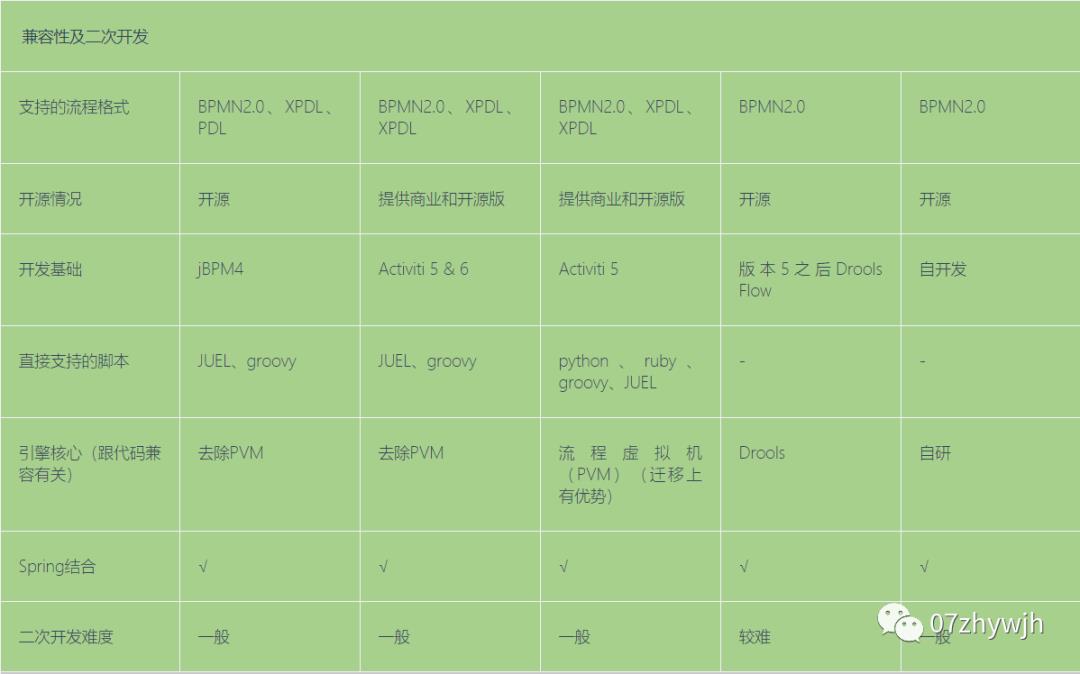
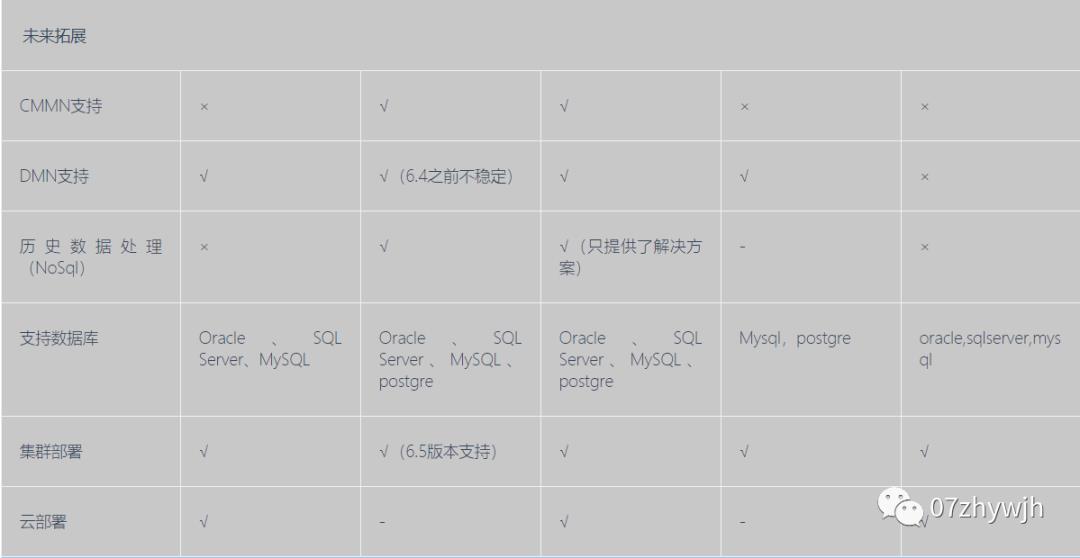
如果做大做强了从来源版升级到商业版
OLAP (On-Line Analytical Processing)
Spark SQL,Presto ,Kylin,Impal, Clickhouse
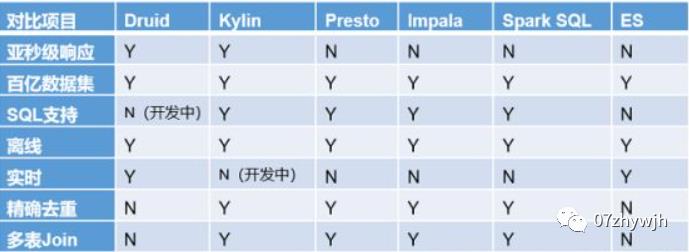
1.Druid:是一个实时处理时序数据的OLAP数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。
2.Kylin:核心是Cube,Cube是一种预计算技术,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。
3.Presto:它没有使用Mapreduce,大部分场景下比HIVE块一个数量级,其中的关键是所有的处理都在内存中完成。
4.Impala:基于内存计算,速度快,支持的数据源没有Presto多。
5.SparkSQL:是spark用来处理结构化的一个模块,它提供一个抽象的数据集DataFrame,并且是作为分布式SQL查询引擎的应用。它还可以实现Hive on Spark,hive里的数据用sparksql查询。
6.框架选型:(1)从超大数据的查询效率来看:
Druid>Kylin>Presto>SparkSQL
(2)从支持的数据源种类来讲:
Presto>SparkSQL>Kylin>Druid
clickhouse
https://www.processon.com/view/link/609ce4491e085353cf93bb44
批处理会将源业务系统中的数据通过数据抽取工具(例如Sqoop)将数据抽取到HDFS中,这个过程可以使用MapReduce、Spark、Flink技术对数据进行ETL清洗处理,也可以直接将数据抽取到Hive数仓中,一般可以将结构化的数据直接抽取到Hive数据仓库中,然后使用HiveSQL或者SparkSQL进行业务指标分析,如果涉及到的分析业务非常复杂,可以使用Hive的自定义函数或者Spark、Flink进行复杂分析,这就是我们通常说的数据指标分析。分析之后的结果可以保存到Hive、HBase、MySQL、Redis等,供后续查询使用。一般在数仓构建中,如果指标存入Hive中,我们可以使用Sqoop工具将结果导入到关系型数据库中供后续查询。HBase中更擅长存储原子性非聚合查询数据,如果有大量结果数据后期不需要聚合查询,也可以通过业务分析处理考虑存入HBase中。对于一些查询需求结果反馈非常快的场景可以考虑将结果存入Redis中。
对于大多数企业构建数仓之后,会将结果存入到Hive中的DM层中。DM层数据存入的是与业务强相关的报表数据,DM层数据是由数仓中DWS层主题宽表聚合统计得到,这种报表层设计适合查询固定的场景。对于一些查询需求多变场景,我们也可以使用impala来直接将主题宽表数据基于内存进行交互式查询,对web或者数据分析做到交互式返回结果,使用impala对内存开销非常大。还有另外一种方式是使用Kylin进行预计算,将结果提前计算好存入DM层数据是由数仓中DWS层主题宽表聚合统计得到,这种报表层设计适合查询固定的场景。对于一些查询需求多变场景,我们也可以使用impala来直接将主题宽表数据基于内存进行交互式查询,对web或者数据分析做到交互式返回结果,使用impala对内存开销非常大。还有另外一种方式是使用Kylin进行预计算,将结果提前计算好存入Hbase中,以供后续交互式查询结果,Kylin是使用空间获取时间的一种方式,预先将各种维度组合对应的度量计算出来存入HBase,用户写SQL交互式查询的是HBase中预计算好的结果数据。最后将数据分析结果可以直接对web以接口服务提供使用或者公司内部使用可视化工具展示使用。
以上无论批处理过程还是流处理过程,使用到的技术几乎离不开Hadoop生态圈。
什么是ClickHouse
ClickHouse是一个开源的,用于联机分析(OLAP)的列式数据库管理系统(DBMS-database manager system), 它是面向列的,并允许使用SQL查询,实时生成分析报告。ClickHouse最初是一款名为Yandex.Metrica的产品,主要用于WEB流量分析。ClickHouse的全称是ClickStream,Data WareHouse,简称ClickHouse。
ClickHouse不是一个单一的数据库,它允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器。ClickHouse同时支持列式存储和数据压缩,这是对于一款高性能数据库来说是必不可少的特性。一个非常流行的观点认为,如果你想让查询变得更快,最简单且有效的方法是减少数据扫描范围和数据传输时的大小,而列式存储和数据压缩就可以帮助我们实现上述两点,列式存储和数据压缩通常是伴生的,因为一般来说列式存储是数据压缩的前提。
ClickHouse是一个数据库管理系统,而不仅是一个数据库,作为数据库管理系统具备完备的管理功能:
u DDL(Data Definition Language-数据定义语言):可以动态地创建、修改或删除数据库、表和视图,而无须重启服务。
u DML(Data Manipulation Language):可以动态查询、插入、修改或删除数据。
u 分布式管理:提供集群模式,能够自动管理多个数据库节点。
u 权限控制:可以按照用户粒度设置数据库或者表的操作权限,保障数据的安全性。
u 数据备份与恢复:提供了数据备份导出与导入恢复机制,满足生产环境的要求。
列式存储
目前大数据存储有两种方案可以选择,行式存储(Row-Based)和列式存储(Column-Based)。
l 行式存储在数据写入和修改上具有优势。
行存储的写入是一次完成的,如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,可以保证数据的完整性。列式存储需要把一行记录拆分成单列保存,写入次数明显比行存储多(因为磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际消耗更大。
数据修改实际上也是一次写入过程,不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。
所以,行式存储在数据写入和修改上具有很大优势。
l 列式存储在数据读取和解析、分析数据上具有优势。
数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
列式存储中的每一列数据类型是相同的,不存在二义性问题,例如,某列类型为整型int,那么它的数据集合一定是整型数据,这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。
所以,列式存储在数据读取和解析数据做数据分析上更具优势。
综上所述,行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略,数量大可能会影响到数据的处理效率。列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域比较重要。一般来说一个OLAP类型的查询可能需要访问几百万或者几十亿行的数据,但是OLAP分析时只是获取少数的列,对于这种场景列式数据库只需要读取对应的列即可,行式数据库需要读取所有的数据列,因此这种场景更适合列式数据库,可以大大提高OLAP数据分析的效率。ClickHouse就是一款使用列式存储的数据库,数据按列进行组织,属于同一列的数据会被保存在一起,列与列之间也会由不同的文件分别保存,在对OLAP场景分析时,效率很高。
数据压缩
为了使数据在传输上更小,处理起来更快,可以对数据进行压缩,ClickHouse默认使用LZ4算法压缩,数据总体
压缩比可达8:1。
ClickHouse采用列式存储,列式存储相对于行式存储另一个优势就是对数据压缩的友好性。例如:有两个字符串“ABCDE”,“BCD”,现在对它们进行压缩:
压缩前:ABCDE_BCD 压缩后:ABCDE_(5,3) |
通过以上案例可以看到,压缩的本质是按照一定步长对数据进行匹配扫描,当发现重复部分的时候就进行编码转换。例如:(5,3)代表从下划线往前数5个字节,会匹配上3个字节长度的重复项,即:“BCD”。当然,真实的压缩算法比以上举例更复杂,但压缩的本质就是如此,数据中重复性项越多,则压缩率越高,压缩率越高,则数据体量越小,而数据体量越小,则数据在网络中的传输越快,对网络带宽和磁盘IO的压力也就越小。
列式存储中同一个列的数据由于它们拥有相同的数据类型和现实语义,可能具备重复项的可能性更高,更利于数据的压缩。所以ClickHouse在数据压缩上比例很大。
报表引擎
搜索引擎
八 调度类中间件
xxljob
Azkaban
Airflow
Oozie
elastic-job
九 大数据中间件
hadoop
cdh
ambari
spark
flink
hive
hbase-phoenix
kylin
es
十 AMP中间件
侵入式
zipkin
大众cat
非侵入式
pinpoint :韩国人开发
skywalking
以上是关于常用中间件的主要内容,如果未能解决你的问题,请参考以下文章