安全左移理念,鹅厂 DevSecOps 如何实践?
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了安全左移理念,鹅厂 DevSecOps 如何实践?相关的知识,希望对你有一定的参考价值。

作者:yuyangzhou、dexyfruan,腾讯 TEG 应用运维安全工程师
引子
随着 DevOps 模式的落地,快字当头。研效提速也意味着出现安全漏洞的数量和概率随之上涨。过去安全风险的管控主要依赖于 DAST 类技术,即:采用黑盒测试技术,对待检查目标发起含检查用例的请求。DevOps 给这一模式带来了挑战,安全检查速度慢、周期长,容易给业务带来干扰,一定程度上有阻碍业务持续交付的风险。另据 Capers Jones 的研究结论:解决缺陷的成本,在研发流程中越靠后越高。
因此,安全机制的左移在开展 DevSecOps 建设时就变得更为重要了。 左是指软件开发生命周期的早期,也就是设计、编码阶段。发生安全漏洞研发的早期阶段存在哪些问题?我们认为可以总结为三类:
开发人员不了解安全编写代码的知识
开发人员有一定安全意识,但因为赶进度或疏忽遗漏编写安全机制,或是错误地实现安全校验逻辑
代码编写是否安全仅凭开发人员自觉,缺乏检查和卡点机制
调研业界理念与实践基础上,团队进行了安全左移建设的探索,主要包括三个机制:面向开发人员的代码安全指南、默认安全框架组件、嵌入基础设施的代码安全检查。作为前述项目的参与者,我们想与业界同行分享交流其中的一些思考与经验。
I. 代码安全指南
1.1 背景
首先是开发人员缺乏安全编写代码知识的问题。 在开展日常安全运营过程中,常常会遇到如下与之关联的挑战:
一个业务被发现问题,如何把这种“踩坑”的经验沉淀下来,分享给其他业务以及新加入公司的同事?
如何帮助开发人员建立起安全编码意识,实现代码写出来就没有漏洞?
当检出安全漏洞时,如何给予开发人员详细、可操作的改进指引?
安全编码意识和漏洞修复指引,两份材料是否合二为一?
综合上述背景,去年梳理了一份统一代码安全指南。从开发人员视角讲述安全注意事项,并配套了丰富的代码示例。覆盖常见的 8 门编程语言,包括:C#、C,C++、Go、javascript、Java、Objective-C、php、Python。

1.2 设计理念
代码安全指南的内容呈树状结构展开,共分 5 层,如下:
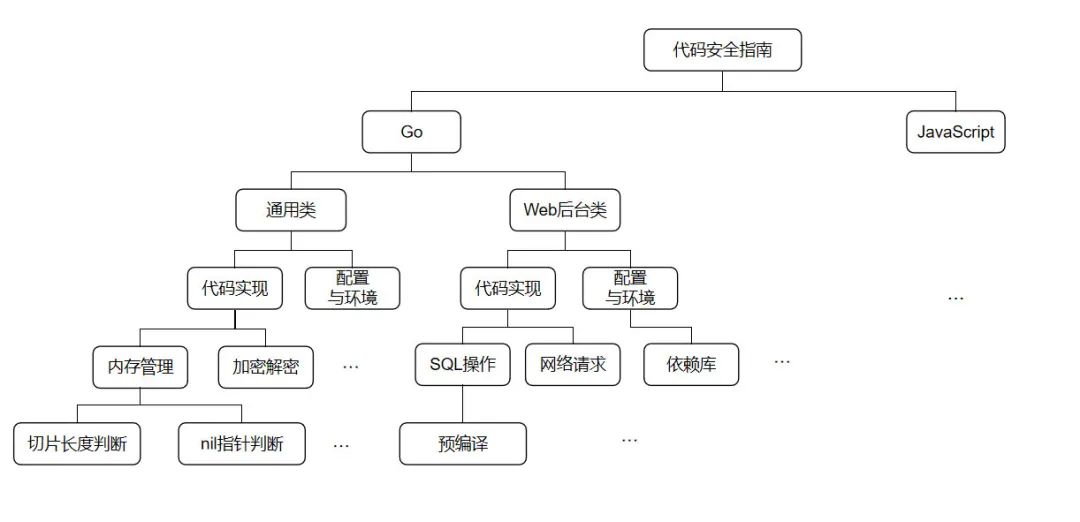
1.2.1 语言
每种语言面临安全的风险种类不同,需要分别开展详述。如:go 和 javascript 对比,go 就不存在原型链污染的问题。同时,由于公司内的代码风格规范亦分语言展开,安全规范采取相同的分语言方式能保持整体的连贯性。
1.2.2 端
这里的端是指不同的终端,如:Web、安卓客户端、ios 客户端、PC 客户端。实践过程中,将内容按端区分的原因有:
1、同一门编程语言,用在不同的终端应用开发,其面临的风险类型和数量有着天壤之别。例如:JavaScript 应用于前端页面开发时,面临的主要风险是 DOM XSS;但 JavaScript 亦可依托 Node.js 进行 Web 后端接口开发,如果编码不当,则存在命令注入、SQL 注入等风险。
2、大型互联网公司内,项目开发采取“流水线”化作业,分工往往精细明确,将不同端的场景作为主干目录,更便于开发人员检索、快速了解编码安全知识。
1.2.3 场景
通过复盘历史漏洞,安全风险可按成因粗略归为两类:
1、代码漏洞,是指代码编写时,因不安全的 API 使用和逻辑编写产生的安全风险。
2、运维漏洞,是指代码的运行环境、配置和依赖等系统运维相关的安全风险。如腾讯蓝军分享的《浅析软件供应链攻击之包抢注低成本钓鱼》一文,涉及的安全风险本质上是是:部分语言依赖包管理,当部分企业私有软件包仅在公司内部软件源注册时,攻击者就可以在外部公共软件源上抢注。如果公司内员工使用包管理软件拉取时,未配置公司镜像源时,就会拉取到攻击者抢注的恶意包。
1.2.4 功能
在对内、外部发现的漏洞进行复盘过程中,我们发现安全风险与业务场景高度相关,例如:

由于代码安全指南的目标受众是开发人员看的。在撰写指南过程中,我们尝试将漏洞转化为功能场景,作为主干目录。由于与具体的业务场景关联,在开发时能更容易想起相关的注意事项,由此可降低认知、学习成本。
1.2.5 API/sink 点
对于开发人员来说, 各类 API 是程序代码的基础组成部分。对安全团队来说,API 也就是编写安全检查策略要收集整理的 sink 点。
1、为什么要在代码安全指引中,枚举 API/sink 点?
对开发人员来说,API 是实现业务逻辑时,高频接触对象。通常安全漏洞往往可归因为 API 的错误使用。对安全工程师来说,sink 点是编写安全策略、组件是非常重要的一部分,直接决定了 SAST 系统的扫描能力。
业界也不乏类似的探讨,如 Google 在 ICSE '21 的论文*《If It’s Not Secure, It Should Not Compile: Preventing DOM-Based XSS in Large-Scale Web Development with API Hardening》*中,阐释了 Google 加固前端组件,使其 Web 页面能天然“免疫”DOM XSS 漏洞的实践过程。
其中主要的思路是对.innerhtml 等容易被误用产生安全问题的 API 做了加固,封装为前端组件中新的函数对象。形成了 JavaScript 公共库https://github.com/google/closure-library,并设计了对应的编译时检查工具。自2018年在其内部逐步推广后,截止2020年Q2外部向Google报告全部漏洞类型中,DOM XSS 已由原先的 20%降低至 2%。
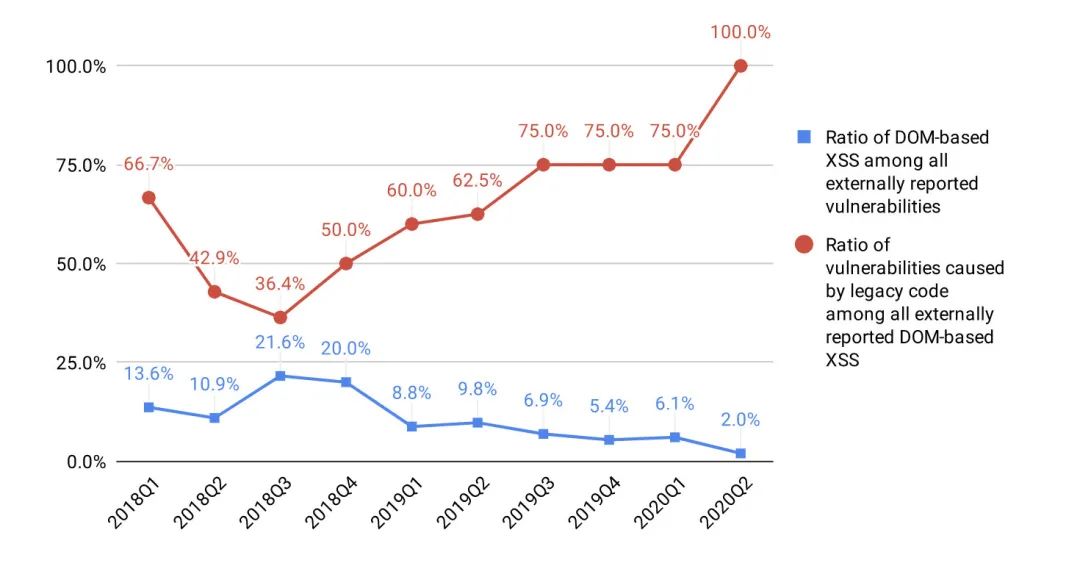
在上述实践过程中,最为重要的一步是:XSS sink 点的提取,也就是易被误用产生安全漏洞的 API。原文“We would like to mention that many other XSS counter-measures, such as data-flow analyses, also need to identify areasonably comprehensive set of XSS sinks to be effective. Therefore, enumerating the sinks are somewhat orthogonal to API hardening",指出 sink 点的提取是开展 API 加固极为重要的一步。
与上述实践类似,我们认为在代码安全指南中,清楚地列出容易被误用的 API,对日常开发和安全策略建设均有帮助。
2、如何确保所枚举 API 的完善性?
这也是上述论文中抛出的一大难点,原文提到:“It is unrealistic to cover all browser-specific XSS sinks because many browsers have undocumented behaviors. As our best effort, we work with the developers of some mainstream browsers to stay informed about new browser features that may have security implications.”。
文章指出,这是一项非常有挑战的任务。编写代码安全指引时,我们亦遇到了类似的挑战,采取的解决思路是:
1)整合各语言、组件、框架文档中的最佳安全实践。在编写安全指南初期,我们重点参考了 CWE、OWASP 等材料。
2) 结合内、外部已知的漏洞案例的复盘、抽象,做校对补充。
3)举一反三,推导鲜有提及的风险点。例如,使用 jQuery 的页面,会因为不安全地使用.html()方法产生 DOM XSS 漏洞。那是否还有其他函数有同样的风险呢?通过查阅 jQuery 的开发者手册https://api.jquery.com/html/发现,.html 函数接受的入参类型为 htmlString 和 function。
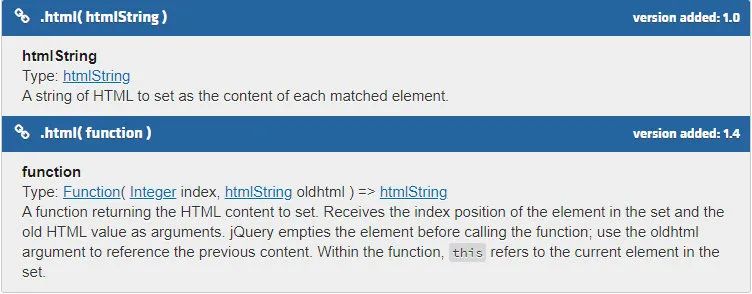
官方文档给出的示例如下:
$( "div.demo-container" )
.html( "<p>All new content. <em>You bet!</em></p>" );
因此可以得出产生漏洞的原因是:从用户可控来源获取切未经过滤的值,可定义为 htmlString 类型并经.html()写入页面,进而产生 XSS 漏洞。顺藤摸瓜可以整理出:.append()、.prepend()、.wrap()、.replaceWith()、.wrapAll()、.wrapInner()、.after()、.before()等 API 存在同样的因误用产生安全风险的可能性。最终,针对上述场景下的指引要求描述如下:

除列出所有风险 API,让开发人员在使用时,脑海里能对快速关联到指引要求外,在编写指引时,我们约定还采取了两种额外的表述注意点,来保证指引内容的可操作性:
a、限定产生安全风险的开发场景,更明确;
b、明确给出安全漏洞的规避方式,或是提供可选的“开箱即用”式安全方案。最终,效果如下:

1.3 效果与不足
通过上述的思路,撰写代码安全指南并配套在线学习课程和考试,我们试图解决开发人员不了解如何安全地开发的问题。当前,该方向仍存在两项挑战:
1、补充完善 sink 点的工作长尾且任务量大,需要随着内外部发现的漏洞、编程语言&框架的迭代不断迭代。为此我们决定将上述代码安全指南通过 Github 开源,希望和社区携手,一道维护完善。项目地址:https://github.com/Tencent/secguide
2、代码安全指南只是安全左移建设的第一步,还需解决的挑战有:
开发人员有一定安全意识,但因为赶进度或疏忽遗漏编写安全机制,或是错误地实现安全校验逻辑
代码编写是否安全全凭开发人员自觉,缺乏提示、检查和卡点机制
II. 静态代码安全检查
2.1 现有技术
“代码编写是否安全全凭开发人员自觉,缺乏提示、检查和卡点机制”的问题,解决方式是:静态代码安全检查解决。
要对代码安全规范扫描,我们首先需要考虑的就是将源码表示成一种方便检查的形式,然后选择合适的方式进行扫描。常规的源码表示方式以 AST(抽象语法树)和 IR(中间表达)为主:以 C++ 为例, clang 可以将 C/C++源码转换为 clang AST 和 LLVM IR。
一般而言,IR 是从 AST 经过层层转换而来,所以会比 AST 拥有更多信息。但相对的,每种语言一般会有自己不同的 IR,处理起来会相对比较困难。而 AST 的形式则简单直观,操作起来也比较容易。

源码

Clang AST

LLVM IR
根据选择的源码表示不同,有不同的方式做代码检查:
方式一、AST 匹配
第一种方式是在 AST 上做检查,既然源码被表示成了树的形式,我们就可以遍历 AST,使用一些 pattern 去检查代码规范中的问题。如:Go 语言代码安全指南中的 1.7.2 条目(CSRF 防护)
// good
import (
"net/http"
"github.com/gorilla/csrf"
"github.com/gorilla/mux"
)
func main() {
r := mux.NewRouter()
r.HandleFunc("/signup", ShowSignupForm)
r.HandleFunc("/signup/post", SubmitSignupForm)
//使用csrf_token验证
http.ListenAndServe(":8000",
csrf.Protect([]byte("32-byte-long-auth-key"))(r))
}
对于该样例,我们需要做两个检查:
检查 http.ListenAndServe 参数中是否存在 CSRF 防护相关配置
检查该配置的正确
具体实现上,我们可以遍历该文件的 AST,寻找到 http.ListenAndServe 调用所在的节点,遍历它的参数,观察是否存在 CSRF 防护相关的参数,再对参数的内容正确性做检查。
通过使用 AST 的方式我们能方便快捷的进行相关规范条目的验证。但对于一些条目,例如 C++的 1.2 条目:
// Good
std::string cmdline = "ls ";
cmdline += user_input;if(cmdline.find_first_not_of("1234567890.+-\\*/e ") == std::string::npos)
system(cmdline.c_str());
else
warning(...);
很显然这里如果要判断它违反规范需要满足两个条件:
cmdline 含有用户输入
没有对 cmdline 做相关检查
如果说第二个条件还能通过模式匹配的方式检查的话,第一个条件就很难通过模式匹配的方式检查了,所以我们需要另一种检查方式。
方式二、污点分析
污点分析是更为常用的检查安全漏洞的方法。通过标记外部输入点、基于程序数据流观察数据是否能到达危险函数(如:SQL 查询,命令执行等函数)来检查安全漏洞。
要实现污点分析,有三个核心的关键点:
source 点:表示外部输入,如 web 输入,文件输入等。
sink 点:表示危险的函数调用或者变量赋值,如 system 等函数
sanitizer:表示过滤点,经过过滤点的数据将被取消标记。
以下面这段代码为例,污点分析从 user_input 一路进行数据流追踪(一般因为 source 点的数量远远大于 sink 点的数量,会反过来从 sink 点开始回溯以提升效率),中间的检查就是 sanitizer,这时候会取消标记,因此该漏洞并不成立。

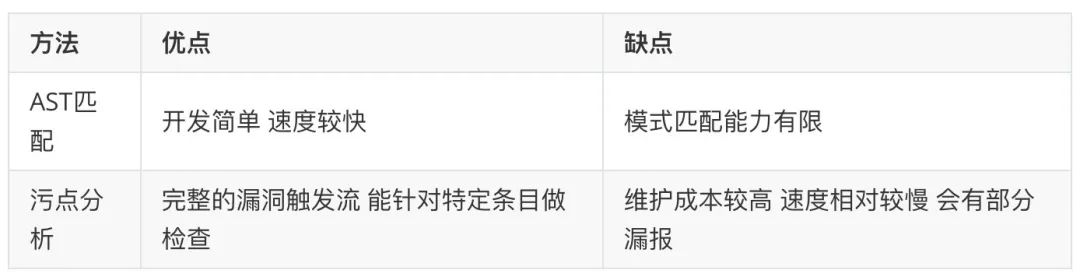
使用污点分析,由于是通过数据流追踪的方式得到漏洞,我们能得到程序相对精确的漏洞触发流程,便于研发二次检查。同时因为依赖手动配置 source 点、sink 点和 sanitizer,会有部分漏报。而且研发往往会采用不同的过滤方式,不同的写法,导致 sanitizer 并不能很好的确定下来。在大型项目中,组件往往分布于不同仓库,加上许多自定义的通信框架,完整的程序数据流会很难得到。
综上我们可以总结出两种不同的扫描方式各自的优缺点:
2.2 工具调研
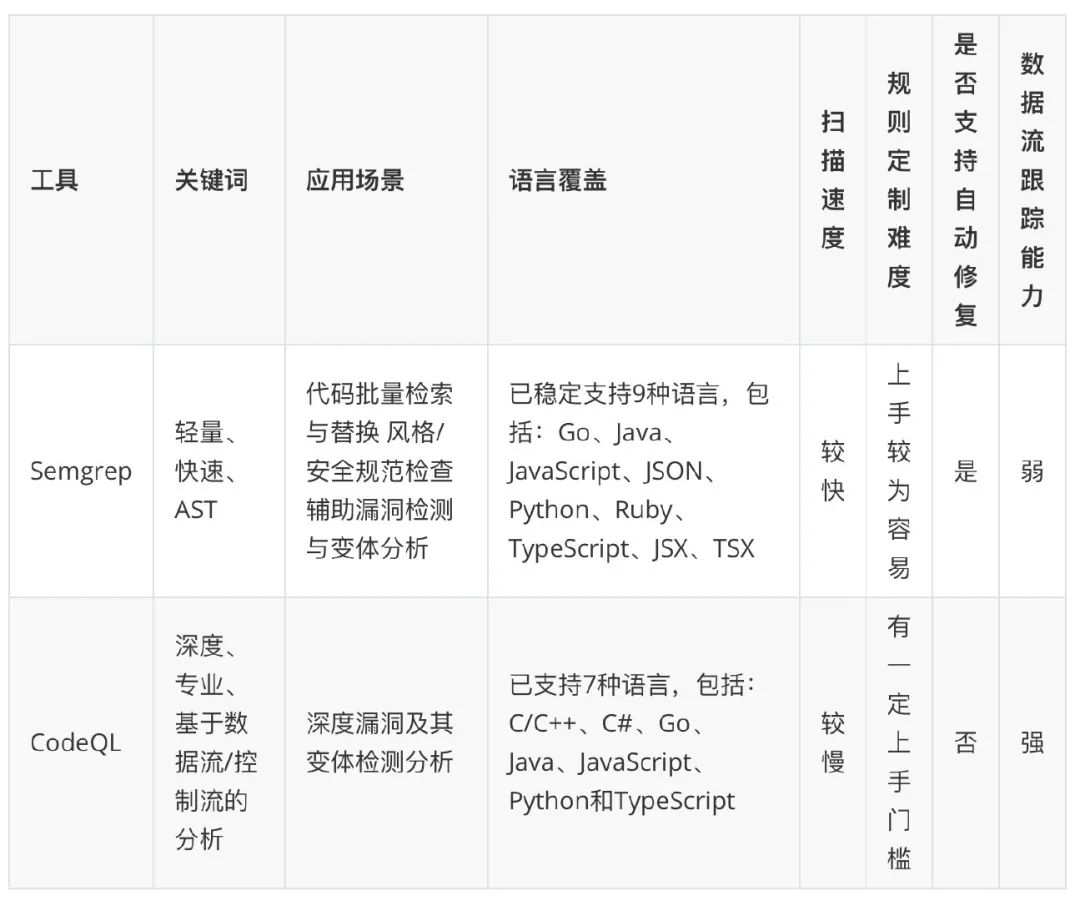
在初步了解了扫描方式后,就要对社区工具做调研。针对单一语言的工具写起来就太多了(各种语言的 lint),这里主要提两个工具:Semgrep 和 CodeQL。一是这两个工具支持语言都不止一个,二是在各自技术领域它们都比较有代表性。
2.2.1 Semgrep
Semgrep 是一款基于 Facebook 开源 SAST 工具 pfff 中的 sgrep 组件开发的开源 SAST 工具,目前由安全公司 r2c 统一开发维护,提供强于 grep 工具的代码匹配检索能力。
其核心技术原理可以用下面这张图概述:
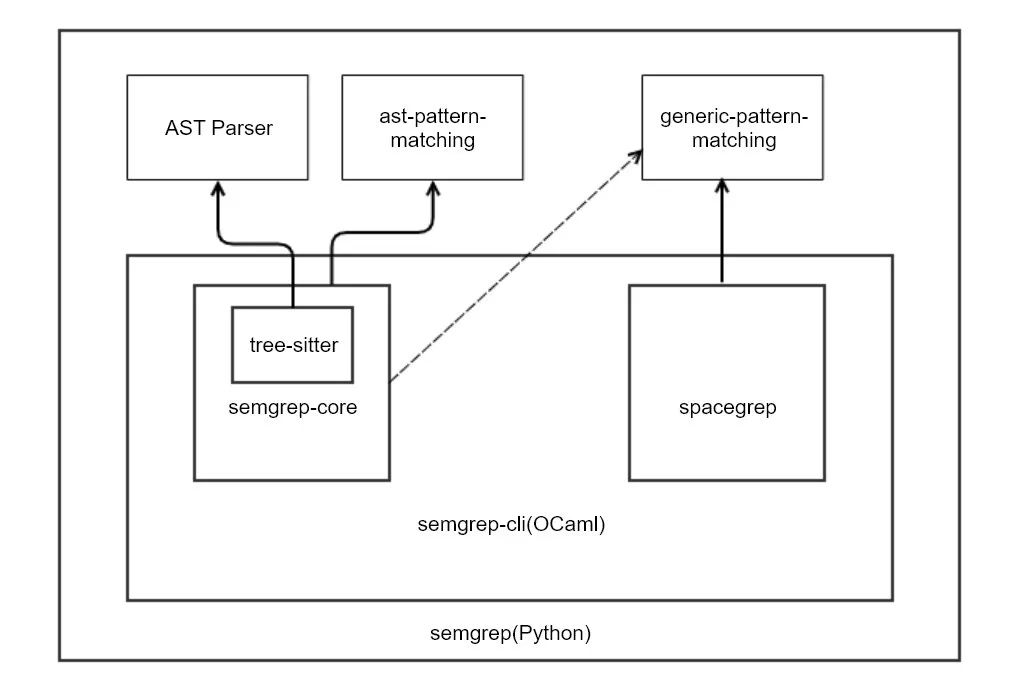
Semgrep 支持两种类型的代码模式匹配。一种是基于 AST 的匹配,使用 tree-sitter parse 各种语言的源码,并将它们转换成 generic AST(Semgrep 内的一种通用 AST 格式),然后再使用规则匹配。举个例子,如果要检索代码中使用 strcpy 的代码行,可以编写如下 ripgrep 命令:
rg --quiet --stats strcpy -tc
但类似如下的代码也会被匹配到,实际上它仅为注释,并没有真正调用 strcpy:
45:// string.h is not guaranteed to provide strcpy on C++ Builder.
而运行如下 semgrep 命令,即可基于 AST 搜索,实现更精准的匹配。其中 ... 是 semgrep 提供的代码模式匹配语法 —— 省略号运算符(Ellipsis operator),用于代表若干参数、语句或字符:
semgrep -e "strcpy(...)" --lang=c .
另一种模式是 generic pattern matching,使用一个通用文本 parser(spacegrep),通过分词和特殊字符的识别来做代码模式匹配。相比基于 AST 的匹配,该模式能力较弱,但拓宽了工具对各类编程语言的覆盖能力。例如对 YAML、ERB、Jinja 等语言,就可以使用该模式进行检查。假设有一个配置文件如下,想要检索其中不正确的“allowed_origins”配置:
resource "aws_s#_bucket" "b"{ bucket = "s3-website-test-open.hashicorp.com"
acl = "private"
cors_rule {
allowed_headers = ["\\*"]
allowed_methods = ["PUT", "POST"]
allowed_origins = ["\\*"] \\# \\<--- Matches here
expose_headers = ["ETag"]
max\\_age_seconds = 3000
}
}
尽管还不支持解析该文件格式的 AST,可以基于 spacegrep 提供的能力,编写如下规则对代码库进行检索:
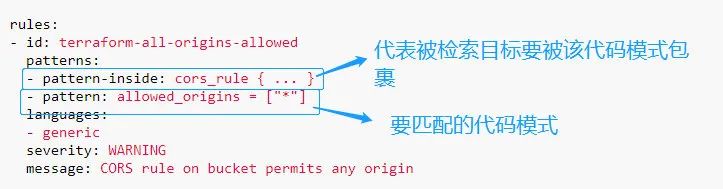
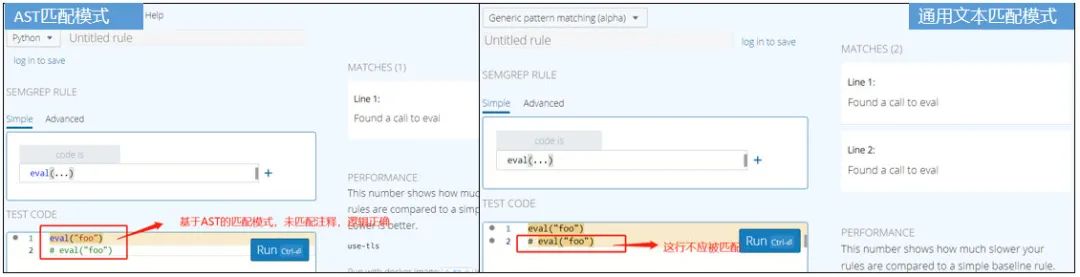
但该种匹配模式下,有时无法区分出是真实的 API 调用,还是代码注释。两种模式对同一代码片段匹配效果,比对如下:
综上,Semgrep 的特点如下:
安装便捷。通过包管理工具安装 cli,即装即用。
规则上手、编写简单。采用 yaml 配置文件编写扫描规则,语法简单但表现能力相较于传统 grep 类工具更强大。
引擎本身和规则集均开源,且支持的规则集丰富,已经开源包含总计有 1000+条规则。
扫描速度快。直接基于 AST/文本匹配,工具效率会相对较高。经测试,扫描速度可达到 2~10w 行代码/秒。
支持代码自动修复替换。通过 AutoFix 语法可自动修复存在安全风险的代码。
易于集成,官方已给出了一系列和 CI 集成的配置,涉及 14 款 CI 平台,如 Jenkins、Gitlab、Circle CI 等。
2.2.2 CodeQL
CodeQL 是 Semmle 公司推出的一款静态代码分析工具(以前叫 Semmle QL),后被 Github 收购,并成立了 Security Lab 支持 Github 的开源代码安全检查能力。
相对于 Semgrep,CodeQL 走的是深度分析的技术路线,核心技术原理是分析源码并将其转换成代码快照,然后通过它自己的 QL 查询语言做代码查询来达到扫描的目的。
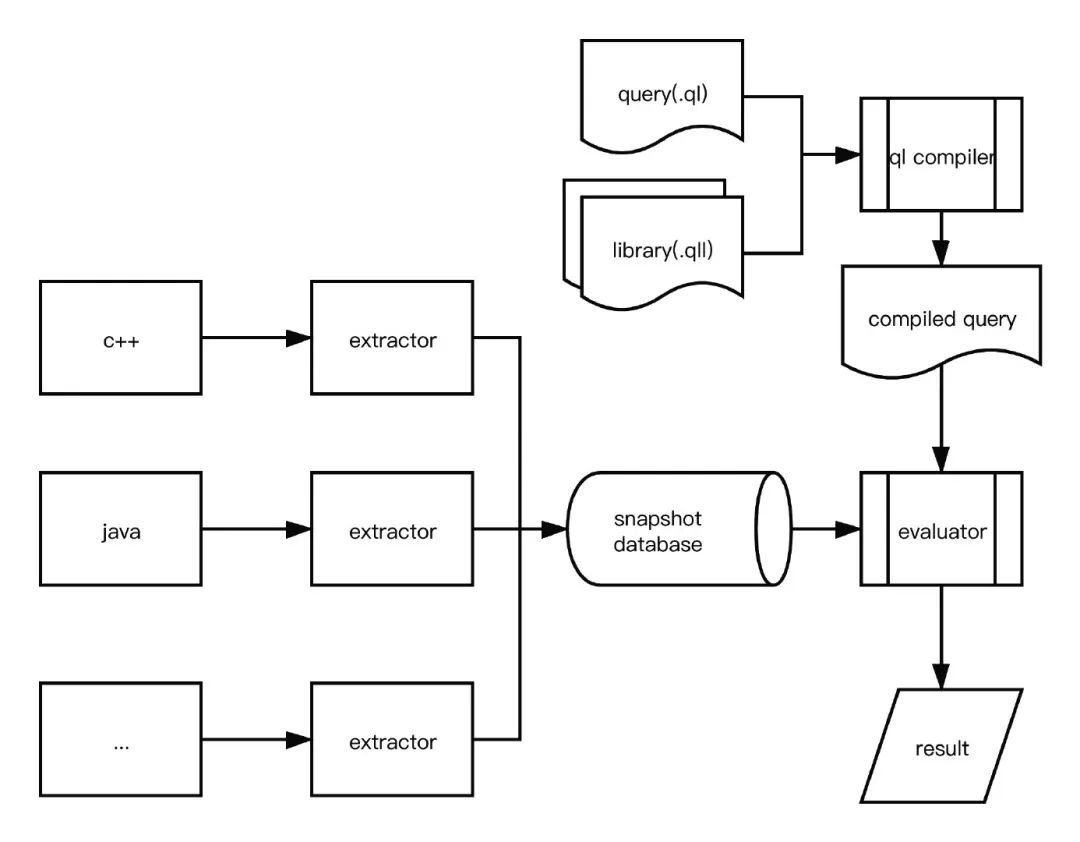
如上图,先提取不同语言的源代码文件到代码快照,然后将查询规则(.ql 文件)编译成 CodeQL 内部的查询形式,再对代码快照进行查询。

其规则形式如上(一部分),编写起来会比较复杂。CodeQL 的优势是支持完整的污点分析和过程间分析,相对不可避免的,分析时间会大大上升。
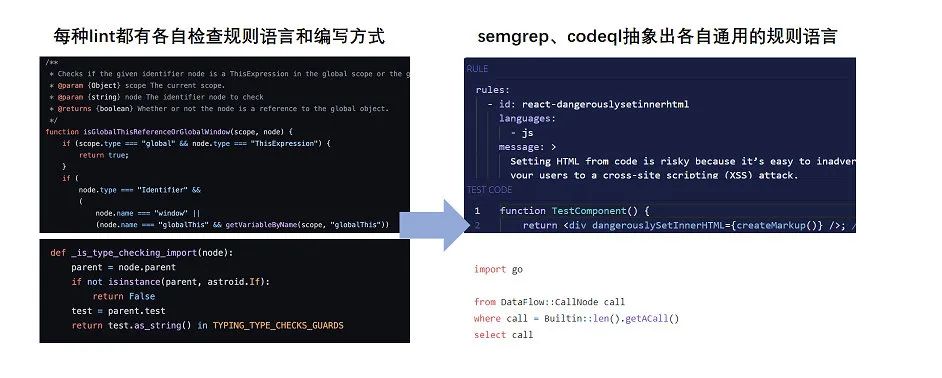
值得一提的是:两款工具都对策略规则写法做了统一,能较好地解决跨编程语言检查的需求。 设想一下:如果用每种语言的 lint 编写检查规则,不同 lint 间的规则语法不一致,将会带来比较高的维护门槛。
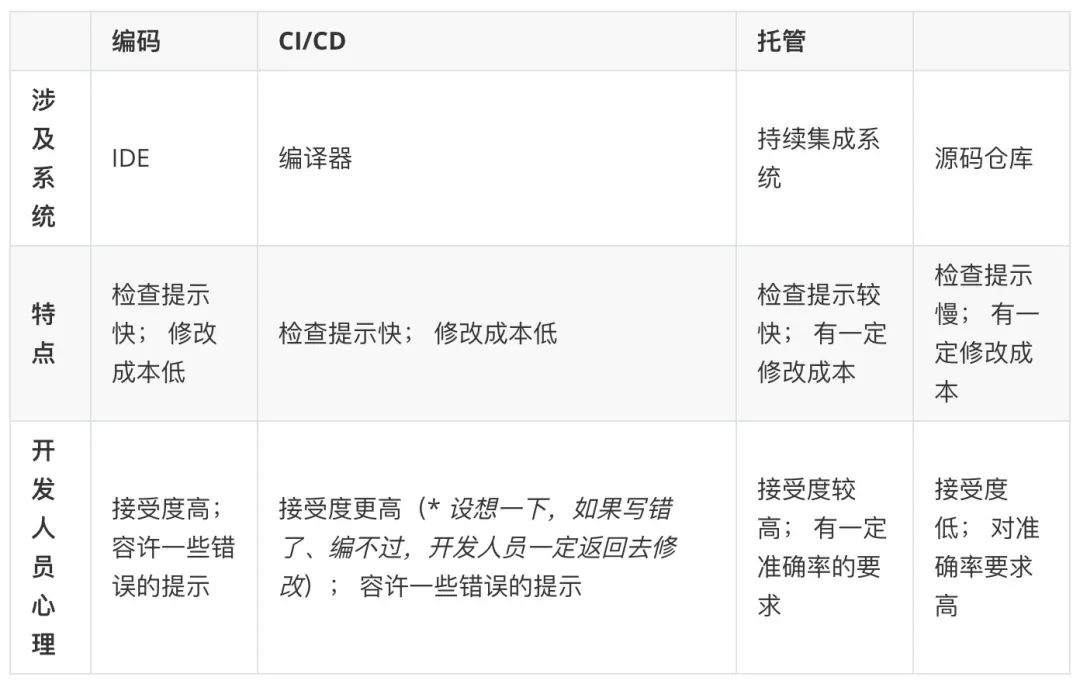
2.2.3 比对及选型
通常,编写代码涉及三个环节 -- 编码、代码托管、CI/CD,开发人员在各阶段对检查工具和结果的期望和要求是不同的。可以简单概括并比对如下:
两款代码检查工具可简单比对总结如下:
2.3 结论与实践
在编写代码的不同阶段,开发人员对检查工具和结果的预期和要求各不相同。在不同编码阶段采取的静态代码安全检查方案可概括如下:
1、本地编写阶段
在本阶段,对工具有一定要求:速度快,容错性要高。而且往往这个点代码还未写完,工具的检查错误可以快速得到修复。这时候 AST 模式匹配就会是一个很好的检查方式。在编码阶段,可以使用 semgrep 等类似 lint、grep 工具,封装为 IDE 插件。
实践过程中,还可以尝试引入一些更激进的策略,如:提示并要求修改不安全的 SQL 查询拼接逻辑。开发人员可根据提示快速判断,如果风险确实存在,即借助自动修复功能修改代码,进而在代码构建前收敛安全风险。
2、构建部署阶段
这个阶段代码已签入代码仓库,类似 semgrep 或 CodeQL 的方案可封装为流水线原子,提供给开发人员使用,并配套提供安全卡点(质量红线)机制。如果检查出安全漏洞,应给出详细的漏洞触发路径,并提示风险关联的代码安全指南条目来引导修复。
3、日常检查阶段,代码仓库检查
该阶段一般为纯旁路的检查,时效性可以适当放宽,可进行一系列复杂的分析。但需要注意的是,由于代码仓库是纯静态代码,如果工具对编译有要求(如 Clang,CodeQL 的部分语言),在该阶段检查应注意编译环境的适配。
值得一提的是,代码安全规范/指南也在编写策略的过程中扮演非常重要的角色。如果公司内有一份比较清晰、完善的规范,能详细地列出各类容易出错的 API,编写检查规则会容易许多。
III. 默认安全的框架组件
3.1 背景
当有了一份代码安全指南和配套的静态检查机制后,开发人员仍需要自行在项目中引入或实现安全校验逻辑。这时候就会遇到“开发人员有一定安全意识,但因为赶进度或疏忽遗漏编写安全机制,或是错误地实现安全校验逻辑”的问题。
深挖背后的原因及“痛点”,我们认为可以归纳为如下三点:
全凭安全意识不靠谱。 即便是安全工程师也会犯错,需要将安全指南的要求转化为开箱即用式的安全组件。
重检查,轻具可操作性、便捷的解决方案。 检查工具聚焦于发现问题,但开发人员在解决问题的时候,如果没可操作的解决方案,修复工作往往难以推动。
研发效率与质量。 不同业务重复在写安全校验逻辑,不仅浪费人力,还容易出错。
通过分析业界相关理论与实践,借助公司建设统一后台框架的契机,我们开展了开展默认安全的框架组件建设。
3.2 分析与解决
3.2.1 业界理论与实践
1、嵌入框架的安全组件。 Google 在《Building Secure and Reliable Systems: Best Practices for Designing, Implementing, and Maintaining Systems》一书的第 12 章中分享了其内部在代码编写阶段开展的安全左移建设实践。可概括为:
“越早越好”。应该在软件设计初期就考量安全、稳定性问题。否则,越往后代价越高,过程会很痛苦。(笔者注:本质上就是安全左移)
“安全意识教育很重要,但不是银弹,即便是安全工程师也会犯错”。依赖安全意识教育,效果不佳。这是因为,业务开发阶段,关注点往往是功能的实现,要兼顾安全和稳定性设计方面的权衡,会很难。因此,应侧重关注安全机制、工具的建设。
Google 团队认为,安全能力嵌入框架大有裨益,如下:
规范化与一致性,复用最佳实践。某些功能容易出问题,通过框架封装,能减少由业务各自实现产生的风险
提升研效。业务逻辑与通用功能抽离,专注业务逻辑开发,无需关注其他细节。不仅能减少代码审阅的精力,也能缩短修复问题的时间。
降低修复成本及时间。虽然框架不能保证预防、解决所有安全问题,但出现问题时,只需要在“一个点”集中解决
2、Security by Design。 USNIX15'的议题《Preventing Security Bugs through Software Design》中抛出了与众不同却巧妙的观点:写出漏洞不一定是开发者的问题,而可能是 API 设计得容易出错。以 SQL 注入为例,尽管大部分语言、组件和框架都提供了参数绑定(参数化查询)的功能,安全规范也有不断强调。但开发人员仍非常容易写出带 SQL 注入问题的代码。
为解决前述问题,提出了一种名为 trustedsqlstring 的机制,从接口设计层拒绝拼接 SQL 查询语句传入。以 Go 语言例,各类参数需要标注静态类型的机制。通过修改 SQL 查询组件导出操作函数的入参类型,可以从 API 设计机制上禁用查询拼接,仅允许通过占位符动态拼接参数值进入查询语句。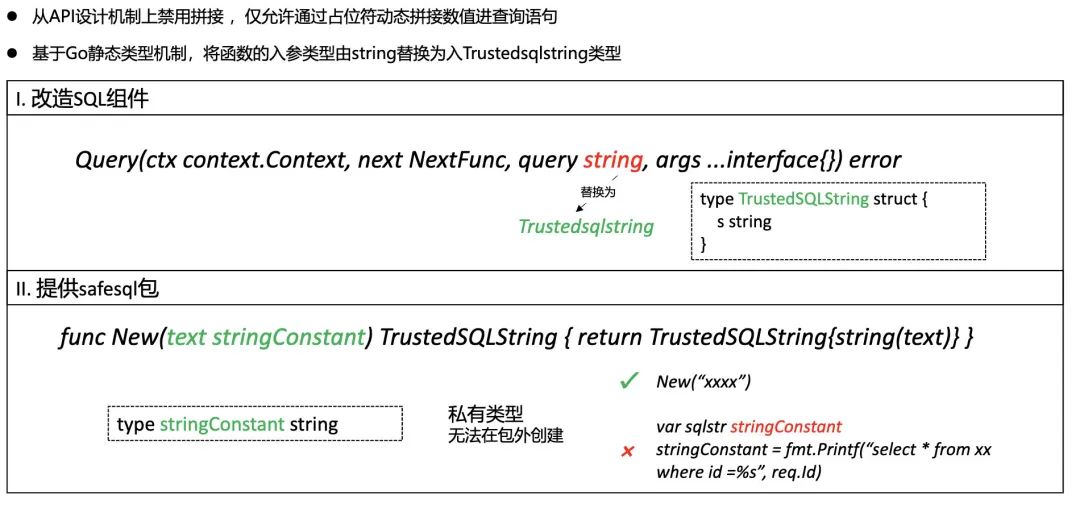
虽然 Google 仅分享了针对 XSS 和 SQL 注入做组件加固的方案,并不足以覆盖所有应用漏洞。但核心思路仍具有借鉴价值,可归纳为:基于白名单模式,对现有组件做安全加固,使安全机制在默认情况下能生效。
3.2.2 安全组件方案分析
通过整理汇总,可以把现有的安全过滤方案分为三类:校验、过滤和组件。
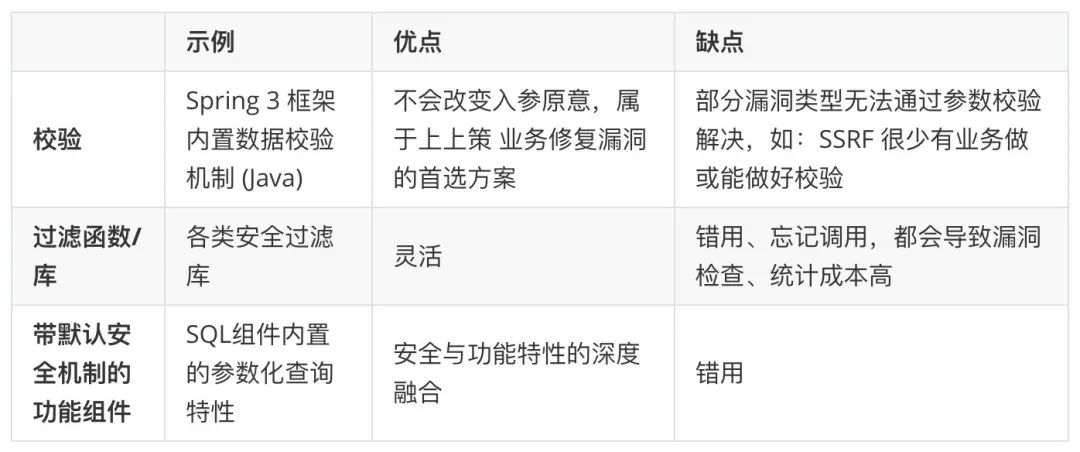
从上述对比来看,组合采用校验,和带默认安全机制的功能组件(融入 Security by Design 设计思路)两个方案是最优解。
3.2.3 落地案例
数据校验是几乎每份安全规范类文档会囊括的要点,但实际在业务研发过程中,落地情况并不理想。 一方面,引入数据校验有一定成本和门槛,导致该逻辑往往会被省略;另一方面,即便是编写了数据校验逻辑,其准确性和安全性也鲜有检查。结果是:我们在内部安全工单系统中,能看到许多开发人员在漏洞处理结论时备注“未做数据校验,已经通过添加相关逻辑解决”。据内部复盘数据统计,这类可通过数据校验规避的漏洞约占历史 Web 漏洞安全工单数量的 70%~ 80%。
为此,我们为公司级 RPC 框架引入了一套 Validation 组件和检查、卡点机制,并取得了不错的效果。 公司级 RPC 框架使用 Protocol Buffer 作为 IDL,根据设计理念,Protocol Buffer 原本就带有一定数据校验类似的特性。但经分析,其不足以支撑业务和安全的需求,例如:校验入参是否为空?传入的是否是字母数字组合,这些需求是 PB 原生的能力无法支持的。因此,需要引入第三方数据校验组件补充这部分能力,当前主要有两类方案:
方案 1、在代码中引入 validator,并编写校验规则
方案 2、在 IDL 文件中编写校验规则并自动生成代码的 protoc 插件
通过分析对比,最终选择了方案 2 —— 开发人员在定义 proto 文件时即在拓展字段中定义好校验规则,过程如下:

同时,通过对历史漏洞的复盘分析,我们发现许多漏洞是 string 类型的字段未限制字符集产生的。如:id 参数功能上仅允许数字传入,但未做校验,允许传入`)('"等字符,带入经拼接产生的 SQL 查询语句,最终产生了 SQL 注入漏洞。于是,我们在内部代码安全指南中添加了明确的要求:请求(Req)消息体中的 String 类型字段必须限定格式/字符范围+长度。
另一方面,我们还与基础设施开发团队合作,将上述组件嵌入了 proto 管理平台默认提供的文件模版中。开发人员几乎可以无额外成本,快速上手使用这套机制:

此外,我们还设计了静态安全检查和卡点机制,并引入上述平台,来保证数据校验逻辑的准确性和安全性。开发人员在保存 proto 文件时,能立即获得提示并及时修正存在的安全隐患。

综上,数据校验本身是一项业务需求,通过降低开发门槛、给出安全要求并配套自动化检查和卡点机制,在框架层提供组件让每个业务模块都能做好数据校验。基于前述思路建设的组件还有不少,包括:DB 组件、网络资源请求组件等。这些组件不是自成一体的安全过滤函数库,而是与某项特定功能需求结合的特定组件。
3.3 效果与小结
结合对业界现有理念与实践的分析,我们基于代码安全指南在公司级框架上建设了一系列“默认安全”的组件,并设计了一系列检查工具嵌入在统一的研发基础设施中。
理想情况下,组件是和代码安全指南高度对应的。举个例子,开发人员在 Go 项目编写资源请求功能时,无需在每个项目中自行实现 SSRF 防御逻辑,只需引入组件即可快速实现业务功能,又确保安全。

由此带来的收益是:
更高的业务接受度,安全机制内置在功能组件中,使用几乎无感知,且会被当作一种最佳业务实践口口相传,逐步获得高覆盖度;
代码安全检查更准确方便;
研发效能的提升,开发人员无需自行、重复实现安全校验/检查代码。
当然,上述工作也给安全和基础组件研发团队提出了挑战:既要对应用安全风险有全面且深入的了解,在开发安全组件时,还要兼顾功能灵活性(业务需求)和安全性(安全需求)。
IV. 总结
综上,借助代码安全指南、默认安全框架组件、嵌入基础设施的静态代码安全检查三项机制联动,我们试图在软件研发生命周期的最初阶段收敛漏洞。

在上述框架下,研发和安全人员日常开展工作的模式为:
研发人员
阅读学习代码安全指南、安全组件文档
业务基于统一框架、组件设计功能,聚焦于业务逻辑
使用自助安全检查工具,在 DevOps 各环节检查漏洞,漏洞修复指引会链接回代码安全规范,形成闭环。
安全人员
有新的漏洞进来 -> 分析提炼漏洞模式(变体分析)-> 沉淀至代码安全规范
基于代码安全规范编写检查规则(浅层和深层)
推出对应的安全组件
在安全左移探索过程中仍有许多机制尚待优化,我们希望通过逐步开源上述解决方案,与业界一道丰富安全左移的理论和实践。
上述探索过程中,获得了基础设施研发团队(框架、持续集成平台)、业务侧研发安全团队的支持,在此献上诚挚的谢意。
参考资料
Kern, Christoph. "Preventing security bugs through software design." (2015).
Wang, Pei, Julian Bangert, and Christoph Kern. "If It’s Not Secure, It Should Not Compile: Preventing DOM-Based XSS in Large-Scale Web Development with API Hardening." 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 2021.
Adkins, Heather, et al. Building Secure and Reliable Systems: Best Practices for Designing, Implementing, and Maintaining Systems. O'Reilly Media, 2020.
轻量级开源 SAST 工具 semgrep 分析
腾讯研发安全团队
腾讯公司内部与自研业务贴合最紧密的一线安全工程团队之一。团队负责软件生命周期各阶段的安全机制建设,包括:制定安全规范/标准/流程、实施内部安全培训、设计安全编码方案、构建安全漏洞检测(SAST/DAST/IAST)与 Web 应用防护(WAF)系统等。在持续为 QQ、微信、云、游戏等重点业务提供服务外,也将积累十余年的安全经验向外部输出。通过为腾讯云的漏洞扫描、WAF 等产品提供底层技术支撑,助力产业互联网客户安全能力升级。
以上是关于安全左移理念,鹅厂 DevSecOps 如何实践?的主要内容,如果未能解决你的问题,请参考以下文章