分布式存储引擎大厂实战——带你读源码搞懂为什么Redis用单线程还这么快
Posted 神技圈子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式存储引擎大厂实战——带你读源码搞懂为什么Redis用单线程还这么快相关的知识,希望对你有一定的参考价值。
分布式存储引擎大厂实战——带你读源码搞懂为什么Redis用单线程还这么快
前言
通常来说Redis是单线程,主要是指redis的网络IO和读写键值对是由一个线程完成的。这也是redis对外提供键值存储服务的主要流程。但是其它功能,比如持久化,集群数据同步等,其实是由额外的线程执行的。
所以,redis并不是完全意义上的单线程,只是一般把它成为单线程高性能的典型代表。那么,很多小伙伴会提问,为什么用单线程?为什么单线程能这么快。
Redis为什么用单线程
首先我们要得了解下多线程的开销问题。平时写程序很多人都觉得使用多线程,可以增加系统吞吐率,或者增加系统扩展性。的确对于一个多线程的系统来说,在合理的资源分配情况下,确实可以增加系统中处理请求操作的资源实体,进而提升系统能够同时处理的请求数,即吞吐率。但是,如果没有良好的系统设计经验,实际得到的结果,其实会刚开始增加线程数时,系统吞吐率会增加。但是,再进一步增加线程时,系统吞吐率就增加迟缓了,甚至会出现下降的情况。
为什么会出现这种情况呢?关键的性能瓶颈就是系统中多线程同时对临界资源的访问。比如当有多个线程要修改一个共享的数据,为了保证资源的正确性,就需要类似互斥锁这样额外的机制才能保证,这个额外的机制是需要额外开销的。比如,redis有个数据类型List,它提供出队(LPOP)和入队(LPUSH)操作。假设redis采用多线程设计。现在假设有两个线程T1和T2线程T1对一个List执行LPUSH操作,线程T2对该List执行LPOP操作,并对队列长度减1。为了保证队列长度的正确性,需要让这两个线程的LPUSH和LPOP串行执行,否则,我们可能就会得到错误的长度结果。 这就是多线程编程经常会遇到的共享资源并发访问控制问题。
而且多线程开发中,并发控制一直是多线程开发的难点问题。如果没有设计经验,只是简单地采用一个粗粒度的互斥锁,就会出现不理想的结果那就是即使增加了线程,大部分线程也在等待获取访问临界资源的互斥锁,造成并行变串行,系统吞吐率并没有随着线程的增加而增加。
单线程Redis为什么这么快
通常单线程的处理能力要比多线程差很多,但是Redis却能用单线程模型达到每秒种十万级别的处理能力。为什么呢?
一方面,Redis的大部分操作都在内存上完成,再加上它采用了高效的数据结构(比如哈希表、跳表)。
另一方面,Redis采用了多路复用机制,能在网络IO操作中能并发处理大量的客户端请求,从而实现高吞吐率。那么Redis为什么要非阻塞呢?
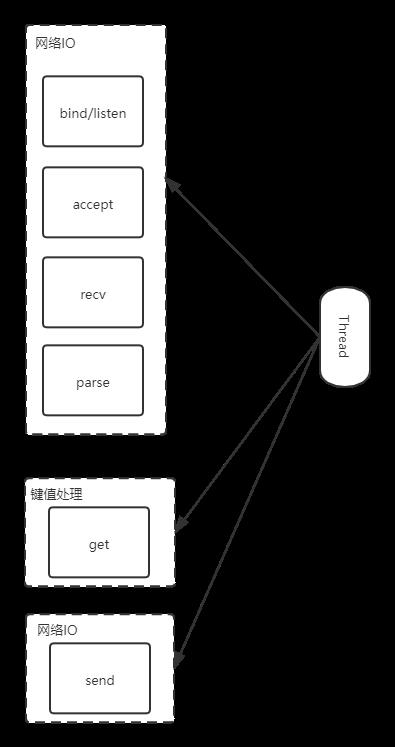
如上图所示,Redis为了处理一个get请求流程如下,需要监听客户端请求(bind/listen),然后和客户端建立连接(accept)。从socket中读取请求(recv),解析客户端发送请求后,根据请求类型读取键值数据(get),最后将结果返回给客户端(send)。其中accept()和recv()默认是阻塞操作。当Redis监听一个客户端有连接请求,但是一直未能成功建立连接时就会阻塞在accept()函数,这样容易导致其它客户端无法和Redis建立连接。同样,当Redis通过recv()从一个客户端读取数据时,如果数据一直没有到达,Redis也会阻塞在recv()。所以,这都会造成Redis整个线程阻塞,无法处理其它客户端请求,效率极低。因此,需要将socket设置为非阻塞。
套接字的非阻塞模式
套接字缺省是阻塞的。这一点意味着当发出一个不能立即完成的套接字调用时,其进程将被投入睡眠,等待相应操作的完成。对套接字的非阻塞模式设置。一般主要调用fcntl函数。这个函数主要用于改变打开文件的性质。
下面就来看下设置非阻塞模式的示例代码:
int flag
flags = fcntl(fd, F_GETFL, 0);
if(flags < 0)
{
...
}
flags |= O_NONBLOCK;
if(fcntl(fd, F_SETFL, flags) < 0)
{
...
return -1;
}
在Redis的anet.c文件中也是的非阻塞代码也是类似逻辑。用anetSetBlock函数处理,函数定义如下:
int anetSetBlock(char *err, int fd, int non_block) {
int flags;
/* Set the socket blocking (if non_block is zero) or non-blocking.
* Note that fcntl(2) for F_GETFL and F_SETFL can't be
* interrupted by a signal. */
if ((flags = fcntl(fd, F_GETFL)) == -1) {
anetSetError(err, "fcntl(F_GETFL): %s", strerror(errno));
return ANET_ERR;
}
/* Check if this flag has been set or unset, if so,
* then there is no need to call fcntl to set/unset it again. */
if (!!(flags & O_NONBLOCK) == !!non_block)
return ANET_OK;
if (non_block)
flags |= O_NONBLOCK;
else
flags &= ~O_NONBLOCK;
if (fcntl(fd, F_SETFL, flags) == -1) {
anetSetError(err, "fcntl(F_SETFL,O_NONBLOCK): %s", strerror(errno));
return ANET_ERR;
}
return ANET_OK;
}
监听套接字设置为非阻塞模式,Redis调动accept()函数但一直未有连接请求到达时,Redis线程可以返回处理其它操作,而不用一直等待。类似的,也可以针对已连接套接字设置非阻塞模式,Redis调用recv()后,如果已连接套接字上一直没有数据到达,Redis线程同样可以返回处理其它操作。但是我们也需要有机制继续监听该已连接套接字,并在有数据到达时通知Redis。这样才能保证Redis线程,即不会像基本IO模型中一直阻塞点等待,也不会导致Redis无法处理实际到达的连接请求。
基于EPOLL机制实现
Linux中的IO多路复用是指一个执行体可以同时处理多个IO流,就是经常听到的select/EPOLL机制。该机制可以允许内核中同时允许多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求。一旦有请求到达就会交给Redis线程处理。
Redis网络框架基于EPOLL机制,此时,Redis线程不会阻塞在某个特定的监听或已连接套接字上,也就不会阻塞在某一个特定的客户端请求处理上。所以,Redis可以同时处理多个客户端的连接请求。如下图
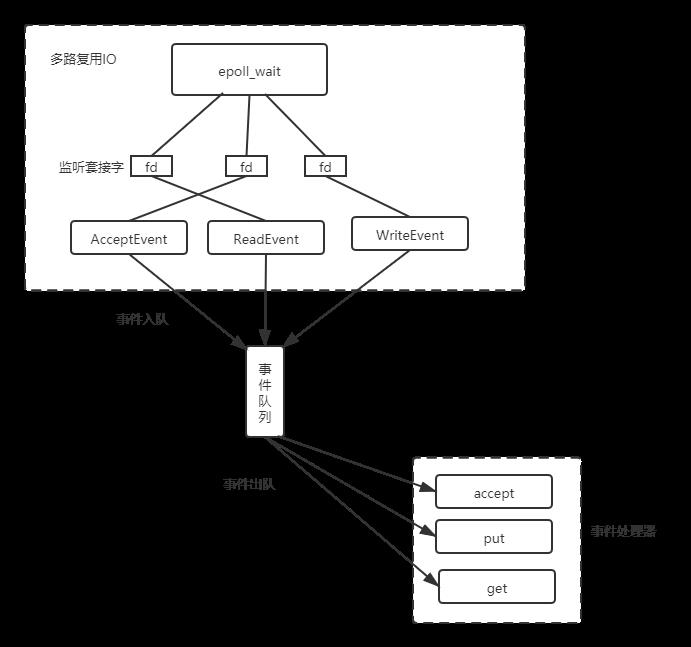
为了在请求到达时能通知到Redis线程,EPOLL提供了事件的回调机制。即针对不同事件调用相应的处理函数。下面我们就来介绍下它是如何实现的
事件分类
Redis服务器是一个事件驱动程序,服务器需要处理以下两类事件
- 文件事件(file event):Redis服务器通过套接字与客户端进行连接,而文件事件就是服务器对套接字的抽象。服务器与客户端的通信会产生相应的文件,而服务器则通过监听并处理这些事件完成一系列操作。
- 时间事件(time event):Redis服务器中的一些操作(比如serverCron函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
Redis用如下结构体来记录一个文件事件:
/* File event structure */
typedef struct aeFileEvent {
int mask; /* one of AE_(READABLE|WRITABLE|BARRIER) */
aeFileProc *rfileProc;
aeFileProc *wfileProc;
void *clientData;
} aeFileEvent;
结构中通过mask来描述发生了什么事件:
- AE_READABLE:文件描述符可读
- AE_WRITABLE:文件描述符可写
- AE_BARRIER:文件描述符阻塞
那么,回调机制怎么工作的呢?其实rfileProc和wfileProc分别就是读事件和写事件发生时的回调函数。它们对应的函数如下
typedef void aeFileProc(struct aeEventLoop *eventLoop, int fd, void *clientData, int mask);
事件循环
Redis用如下结构体来记录系统中注册的事件及其状态:
/* State of an event based program */
typedef struct aeEventLoop {
int maxfd; /* 当前注册的fd最大数 */
int setsize; /* 能注册的fd最大数 */
long long timeEventNextId;
time_t lastTime; /* Used to detect system clock skew */
aeFileEvent *events; /* 数组,已经注册的事件 */
aeFiredEvent *fired; /* 数组,已经触发的事件 */
aeTimeEvent *timeEventHead;
int stop;
void *apidata; /* 用于存放和epollfd相关的数据 */
aeBeforeSleepProc *beforesleep; /*在epoll_wait阻塞之前调用的函数*/
aeBeforeSleepProc *aftersleep;/*在epoll_wait阻塞之后调用的函数*/
} aeEventLoop;
这一结构体中,最主要的就是文件事件指针events和时间事件头指针timeEventHead。文件事件指针events指向一个固定大小(可配置)数组,通过文件描述符作为下标,对应的元素是该fd关注的事件,fired的下标仅仅是索引index,该index位置上的元素是记录了触发的fd以及对应的事件类型。fired中的元素struct aeFiredEvent结构如下
typedef struct aeFiredEvent{
int fd; //有事件触发的文件描述符
int mask; //这个fd触发具体的事件类型
}aeFiredEvent
epoll相关函数
epoll系列函数被封装后都是aeApi_为前缀
- aeApiCreate:基于epoll_create函数封装。
- aeApiAddEvent:基于epoll_ctl函数封装,向epllfd事件空间中注册感兴趣的事件。
- aeApiDelEvent:基于epoll_ctl函数封装,从epllfd事件空间中删除感兴趣的事件
- aeApiPoll事件:基于epoll_wait函数封装,阻塞等待事件发生
aeApiAddEvent函数
这个函数主要用来关联事件到EPOLL,所以会调用epoll的ctl方法定义如下:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* If the fd was already monitored for some event, we need a MOD
* operation. Otherwise we need an ADD operation.
*
* 如果 fd 没有关联任何事件,那么这是一个 ADD 操作。
* 如果已经关联了某个/某些事件,那么这是一个 MOD 操作。
*/
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}
当Redis服务创建一个客户端请求的时候会调用,会注册一个读事件。
当Redis需要给客户端写数据的时候会调用prepareClientToWrite。这个方法主要是注册对应fd的写事件。
如果注册失败,Redis就不会将数据写入缓冲。
如果对应套件字可写,那么Redis的事件循环就会将缓冲区新数据写入socket。
事件注册函数aeCreateFileEvent
这个是文件事件的注册过程,函数实现如下
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData)
{
if (fd >= eventLoop->setsize) {
errno = ERANGE;
return AE_ERR;
}
aeFileEvent *fe = &eventLoop->events[fd];
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;
fe->mask |= mask;
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
fe->clientData = clientData;
if (fd > eventLoop->maxfd)
eventLoop->maxfd = fd;
return AE_OK;
}
这个函数首先根据文件描述符获得文件事件对象,接着在操作系统中添加自己关心的文件描述符(利用上面提到的addApiAddEvent函数),最后将回调函数记录到文件事件对象中。因此,一个线程就可以同时监听多个文件事件,这就是IO多路复用了。
aeMain函数
Redis事件处理器的主循环
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
//开始处理事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS|
AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP);
}
}
这个方法最终会调用epoll_wait()获取对应事件并执行。
这些事件会放进一个事件队列,Redis单线程会对该事件队列不断进行处理。比如当有读请求到达时,读请求对应读事件。Redis对这个事件注册get回调函数。当内核监听到有读请求到达时,就会触发读事件,这个时候就会回调Redis相应的get函数。
向客户端返回数据
Redis完成请求后,Redis并非处理完一个请求后就注册一个写文件事件,然后事件回调函数中往客户端写回结果。检测到文件事件发生后,Redis对这些文件事件进行处理,即调用rReadProc或writeProc回调函数。处理完成后,对于需要向客户端写回的数据,先缓存到内存中。
typedef struct client {
...
list *reply; /* List of reply objects to send to the client. */
...
int bufpos;
char buf[PROTO_REPLY_CHUNK_BYTES];
} client;
发送给客户端的数据会存放到两个地方:
- reply指针存放待发送的对象;
- buf中存放待返回的数据,bufpos指示数据中的最后一个字节所在位置。
注意:只要能存放在buf中,就尽量存入buf字节数组中,如果buf存不下了,才存放在reply对象数组中。
写回客户端发生在进入下一次等待文件事件之前,会调用以下函数处理写回逻辑
int writeToClient(int fd, client *c, int handler_installed) {
while(clientHasPendingReplies(c)) {
if (c->bufpos > 0) {
nwritten = write(fd,c->buf+c->sentlen,c->bufpos-c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
totwritten += nwritten;
if ((int)c->sentlen == c->bufpos) {
c->bufpos = 0;
c->sentlen = 0;
}
} else {
o = listNodeValue(listFirst(c->reply));
objlen = o->used;
if (objlen == 0) {
c->reply_bytes -= o->size;
listDelNode(c->reply,listFirst(c->reply));
continue;
}
nwritten = write(fd, o->buf + c->sentlen, objlen - c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
totwritten += nwritten;
}
}
}
以上是关于分布式存储引擎大厂实战——带你读源码搞懂为什么Redis用单线程还这么快的主要内容,如果未能解决你的问题,请参考以下文章
分布式存储引擎大厂实战——Redis主从数据库如何实现数据一致性