haproxy高可用集群+pacemaker+fence (nginx源码编译)
Posted dezasseis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了haproxy高可用集群+pacemaker+fence (nginx源码编译)相关的知识,希望对你有一定的参考价值。
一、Pacemaker简介
Pacemaker是一个集群资源管理器。它利用集群基础构件(OpenAIS 、heartbeat或corosync)提供的消息和成员管理能力来探测并从节点或资源级别的故障中恢复,以实现群集服务(亦称资源)的最大可用性。
二、pacemaker结构以运作方式
01_pacemaker 内部结构
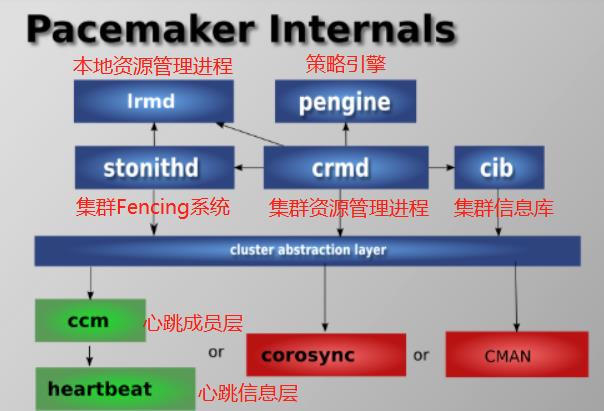
Pacemaker作为一个独立的集群资源管理器项目,其本身由多个内部组件构成,这些内部组件彼此之间相互通信协作并最终实现了集群的资源管理, Pacemaker项目由五个内部组件构成,各个组件之间的关系如上图所示。
02_组件说明:
- lrmd:本地资源管理守护进程。它提供了一个通用的接口支持的资源类型。直接调用资源代理(脚本)。
本地资源管理进程(Local Resource Manager deamon) - PEngine:政策引擎。根据当前状态和配置集群计算的下一个状态。产生一个过渡图,包含行动和依赖关系的列表。
策略引擎(PolicyEngine) - stonithd:心跳系统。
集群 Fencing进程( Shoot The Other Node In The Head deamon) - CRMD:集群资源管理守护进程。主要是消息代理的PEngine和LRM,还选举一个领导者(DC)统筹活动(包括启动/停止资源)的集群。
集群资源管理进程( Cluster Resource Manager deamon)运行有CRMd的Master节点服务器称为DC( Designated controller,控制器节点) - CIB:群集信息库。包含所有群集选项,节点,资源,他们彼此之间的关系和现状的定义。同步更新到所有群集节点。
集群信息基础( Cluster Information Base)。 - Heartbeat:心跳消息层,OpenAIS的一种替代。
- CCM:共识群集成员,心跳成员层。
组件之间运作模式:
- CIB主要负责集群最基本的信息配置与管理,Pacemaker中的 CIB主要使用XML的格式来显示集群的配置信息和集群所有资源的当前状态信息。CIB所管理的配置信息会自动在集群节点之间进行同步,
PE将会使用CIB所提供的集群信息来规划集群的最佳运行状态。并根据当前 CIB信息规划出集群应该如何控制和操作资源才能实现这个最佳状态,在PE做出决策之后,会紧接着发出资源操作指令,而PE发出的指令列表最终会被转交给集群最初选定的DC上(运行有CRMd的Master节点服务器称为DC,Designated controller,控制器节点)。 - 在集群启动之初, pacemaker便会选择某个节点上的 CRM进程实例来作为集群 Master CRMd,然后集群中的CRMd便会集中处理 PE根据集群 CIB信息所决策出的全部指令集。在这个过程中,如果作为 Master的 CRM进程出现故障或拥有Master CRM进程的节点出现故障,则集群会马上在其他节点上重新选择一个新的 Master CRM进程。
- 在 PE的决策指令处理过程中, DC会按照指令请求的先后顺序来处理PEngine发出的指令列表,简单来说,DC处理指令的过程就是把指令发送给本地节点上的 LRMd(当前节点上的 CRMd已经作为Master在集中控制整个集群,不会再并行处理集群指令)或者通过集群消息层将指令发送给其他节点上的 CRMd进程,然后这些节点上的CRMd再将指令转发给当前节点的 LRMd去处理。当集群节点运行完指令后,运行有CRMd进程的其他节点会把他们接收到的全部指令执行结果以及日志返回给 DC(即DC最终会收集全部资源在运行集群指令后的结果和状态),然后根据执行结果的实际情况与预期的对比,从而决定当前节点是应该等待之前发起的操作执行完成再进行下一步的操作,还是直接取消当前执行的操作并要求PEngine根据实际执行结果再重新规划集群的理想状态并发出操作指令。
- 在某些情况下,集群可能会要求节点关闭电源以保证共享数据和资源恢复的完整性,为此,Pacemaker引人了节点隔离机制,而隔离机制主要通过STONITH进程实现。 STONITH是一种强制性的隔离措施, STONINH功能通常是依靠控制远程电源开关以关闭或开启节点来实现。在Pacemaker中, STONITH设备被当成资源模块并被配置到集群信息 CIB中,从而使其故障情况能够被轻易地监控到。同时,STONITH进程( STONITHd)能够很好地理解 STONITH设备的拓扑情况,因此,当集群管理器要隔离某个节点时,只需STONITHd的客户端简单地发出 Fencing某个节点的请求, STONITHd就会自动完成全部剩下的工作,即配置成为集群资源的STONITH设备最终便会响应这个请求,并对节点做出Fenceing操作,而在实际使用中,根据不同厂商的服务器类型以及节点是物理机还是虚拟机,用户需要选择不同的 STONITH设备。
三、安装与配置
01_实验准备
实验环境:
- 防火墙关闭
- selinux为Disabled
两台服务器之间做免密):
server1:172.25.2.1
server4:172.25.2.4
02_安装
- 软件仓库配置
vim /etc/yum.repos.d/westos.repo
[dvd]
name=rhel7.6 BaseOS
baseurl=http://172.25.2.250/rhel7.6/
gpgcheck=0
[HighAvailability]
name=rhel7.6
baseurl=http://172.25.2.250/rhel7.6/addons/HighAvailability
gpgcheck=0
- 安装pacemake、pcs、psmisc、policycoreutils-python
yum install -y pacemaker pcs psmisc policycoreutils-python
ssh server4 yum install -y pacemaker pcs psmisc policycoreutils-python - 设置开机自启
systemctl enable --now pcsd.service
ssh server4 systemctl enable --now pcsd.service - 设置密码
echo westos | passwd --stdin hacluster
ssh server4 'echo westos | passwd --stdin hacluster
03_配置
- 配置群集节点认证
pcs cluster auth server1 server4

- 创建一个二节点的群集
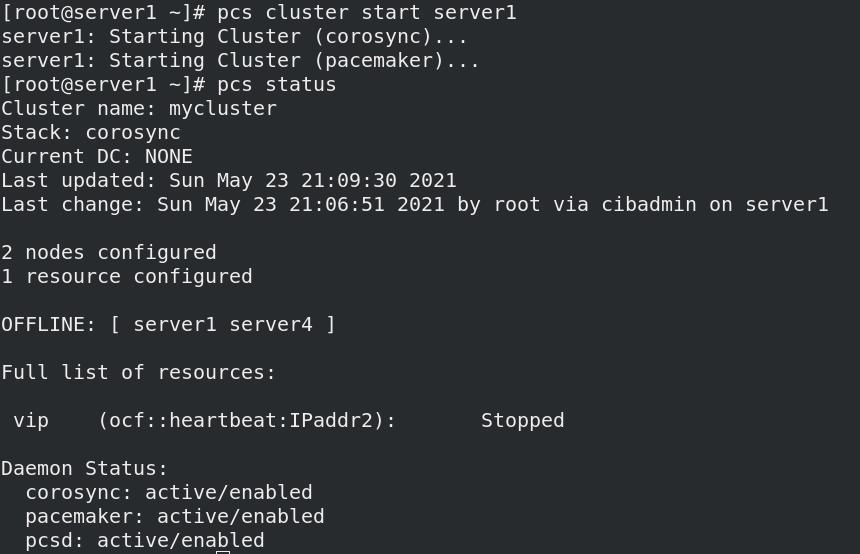
pcs cluster setup --name mycluster server1 server4 - 启动群集
pcs cluster start --all
pcs cluster enable --all - 禁用STONITH组件功能
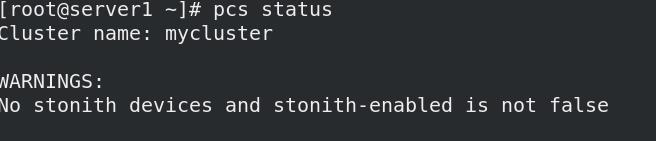
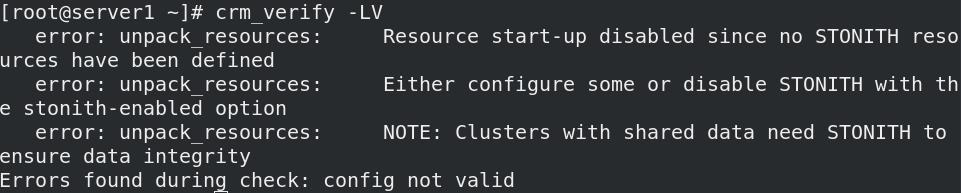
pcs property set stonith-enabled=false
若是不禁,pcs status 查看状态时会有警告,crm_verify -LV 验证群集配置信息会有错误

- 创建VIP
pcs resource create vip ocf:heartbeat:IPaddr2 ip=192.168.17.100 op monitor interval=30s
参数都可以通过pcs resource create --help查看
04_测试
- 节点server1开启,自动添加VIP
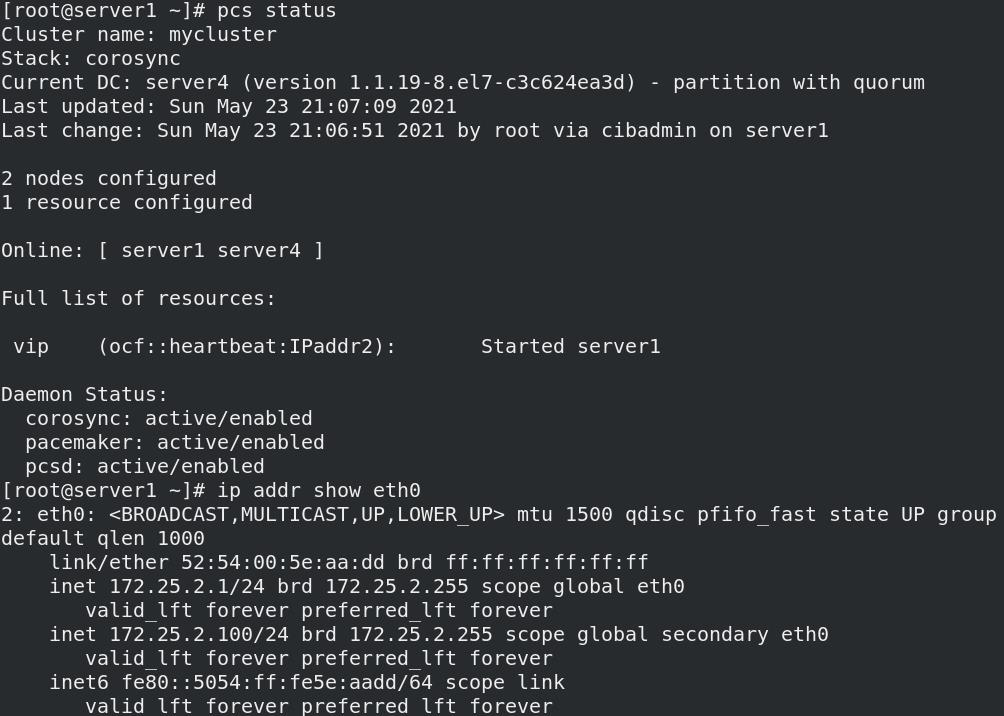
- 停止节点server1服务时,另一个节点server4自动接管,并自动添加VIP
pcs cluster stop server1
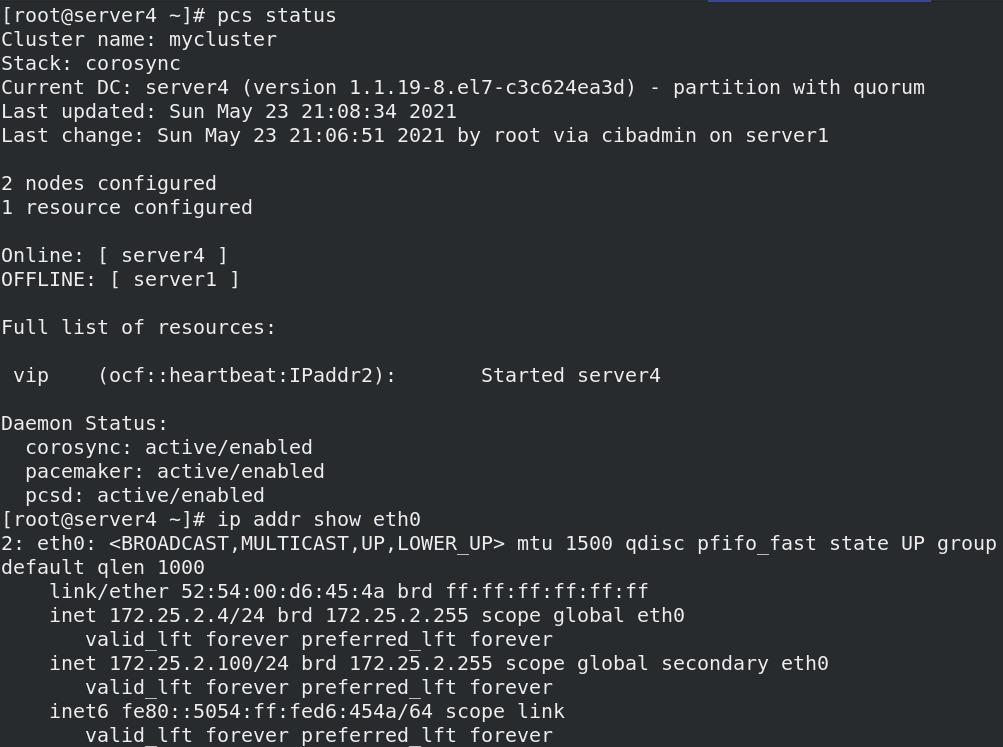
- 重新开启server1服务,资源不会发生切换,依旧在server4上管理,server1不会接管
四、pacemaker与haproxy
01_配置
- 两个服务器节点server1 server4均安装haproxy,且关闭haproxy服务,配置也相同
yum install -y haproxy
systemctl disable --now haproxy.service
scp haproxy.cfg root@172.25.2.4:/etc/haproxy/ - 创建资源
pcs resource create haproxy systemd:haproxy op monitor interval=30s
可能两个资源不被同一节点管理
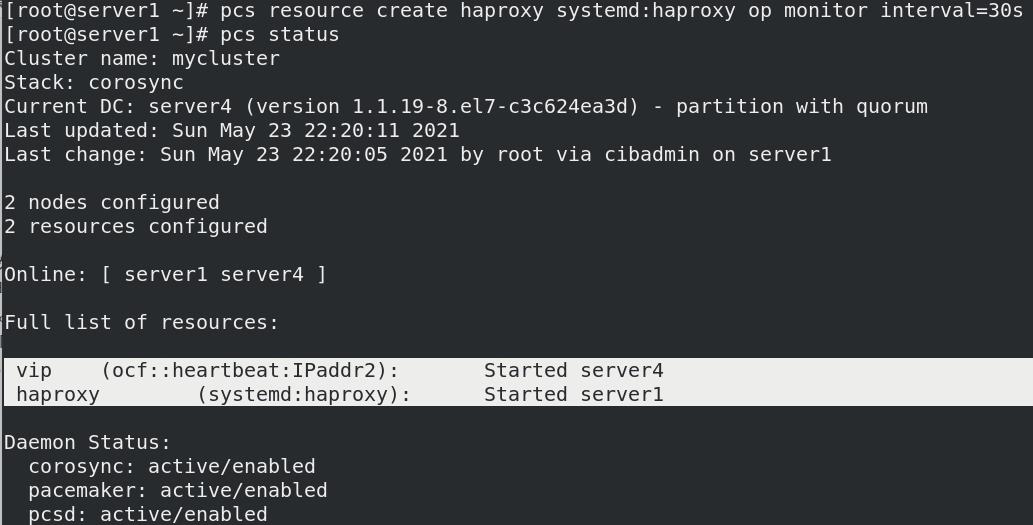
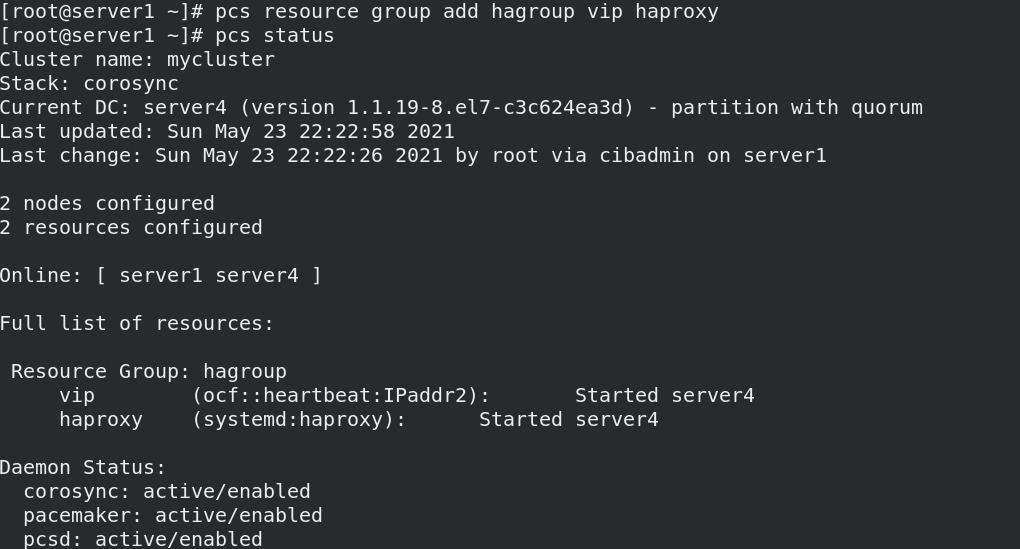
- 创建组(使两个资源被同一节点管理)
pcs resource group add hagroup vip haproxy
02_测试1:关闭节点的pcs服务
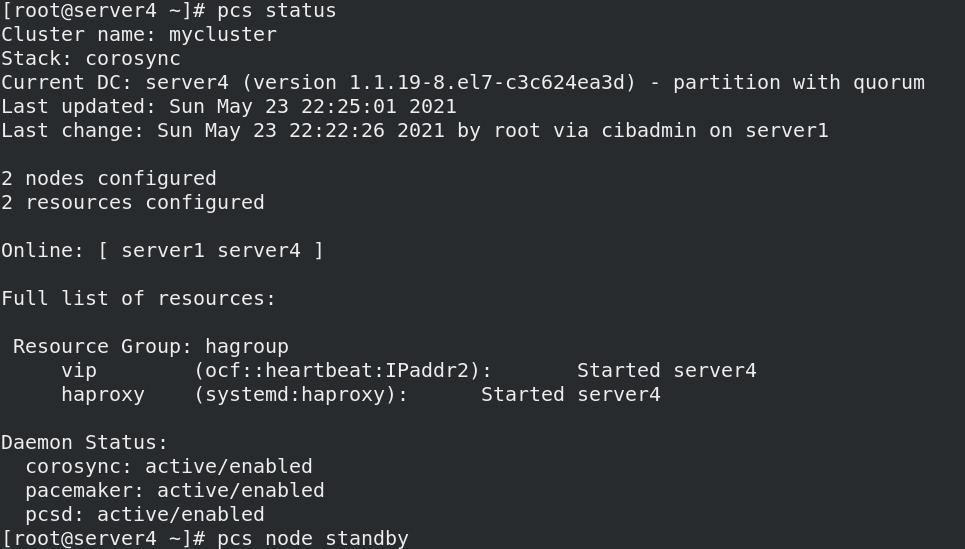
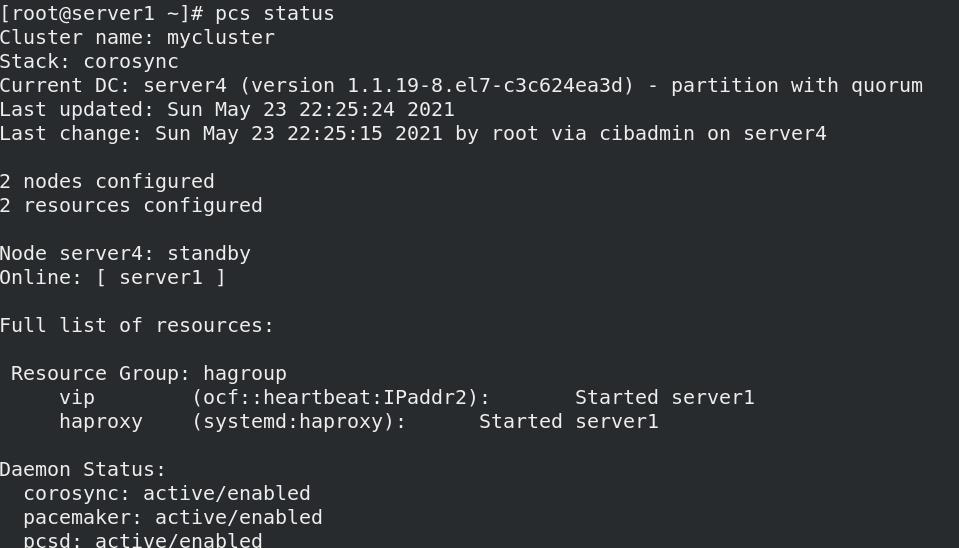
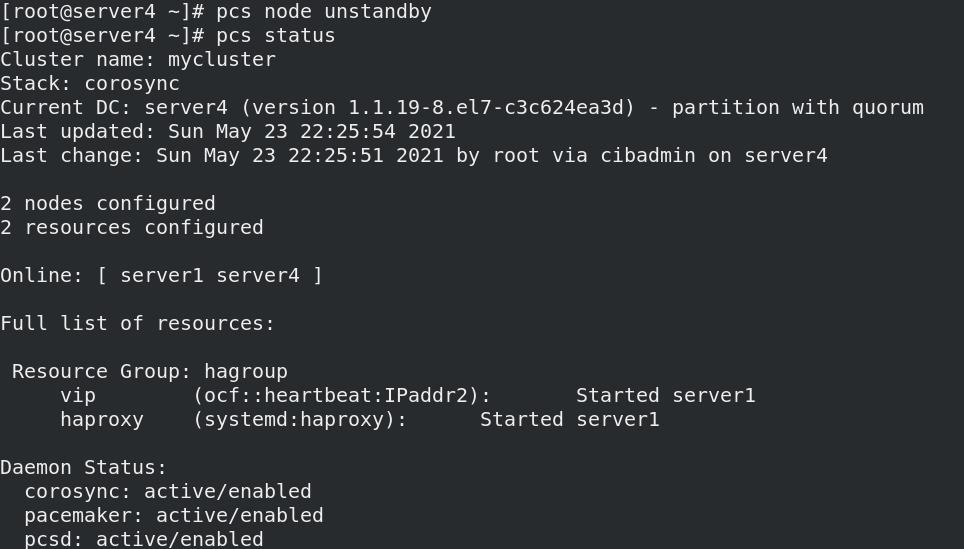
- 关闭节点server4,自动被空闲节点server1接管,server4重新开启服务后,不会回切,依旧server1接管
pcs node standby
pcs node unstandby
03_测试2:关闭haproxy服务
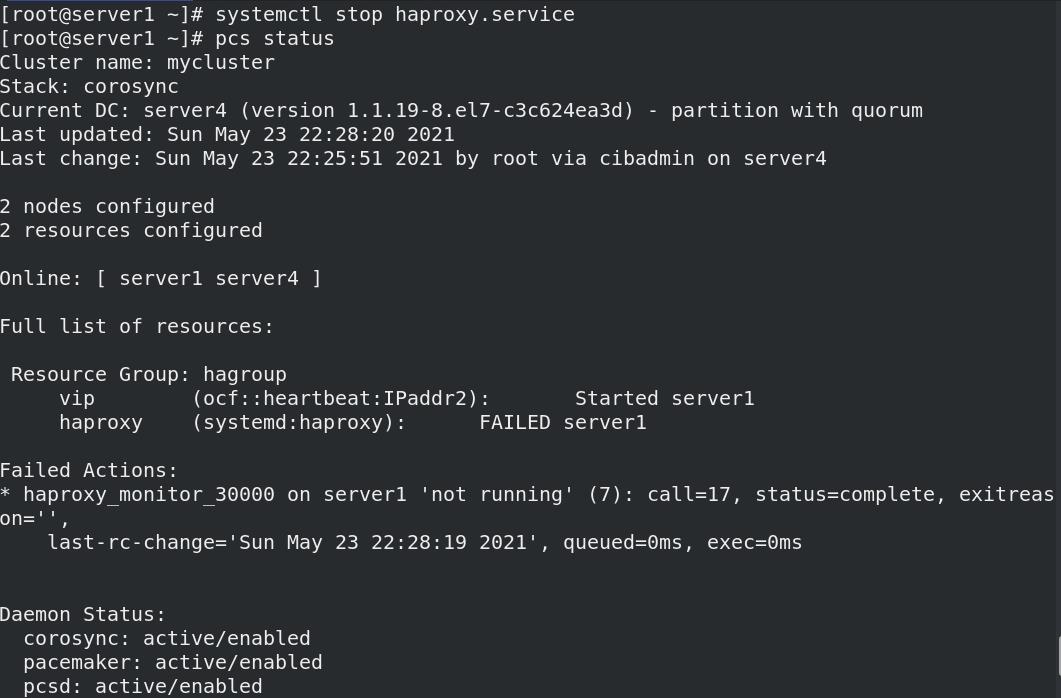
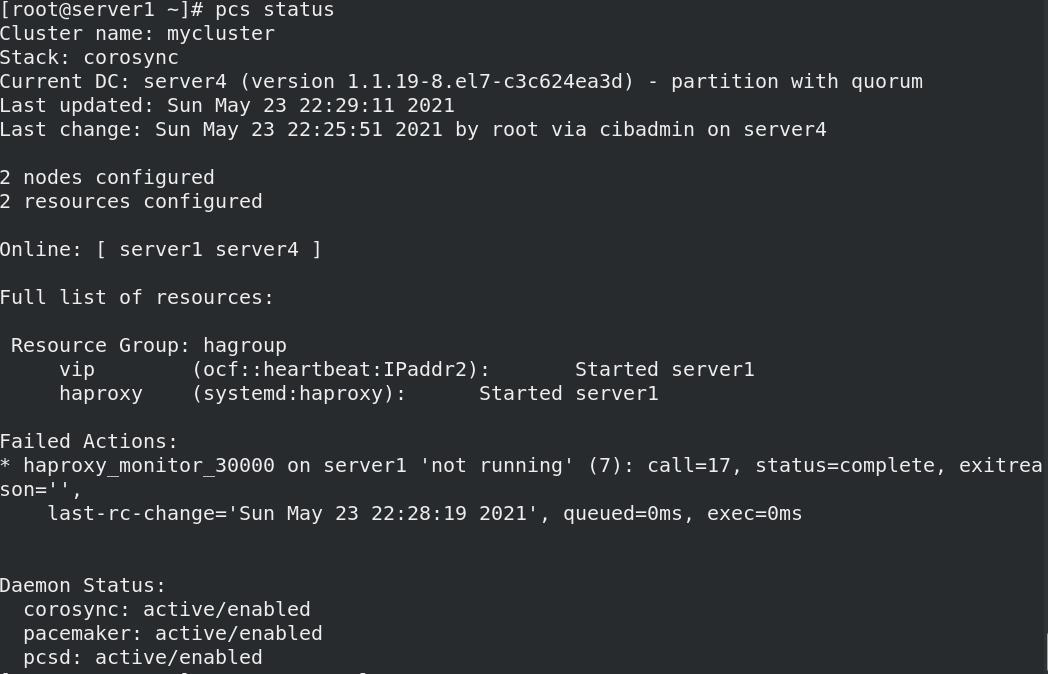
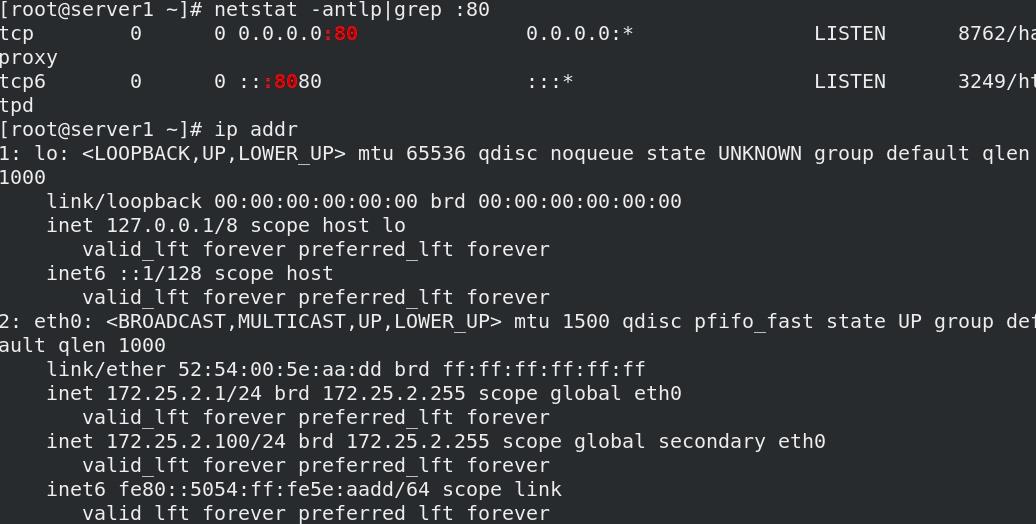
当节点关闭haproxy服务后,系统检测到haproxy关闭后又会自动开启,显示状态时会有日志显示haproxy关闭过。
systemctl stop haproxy.service
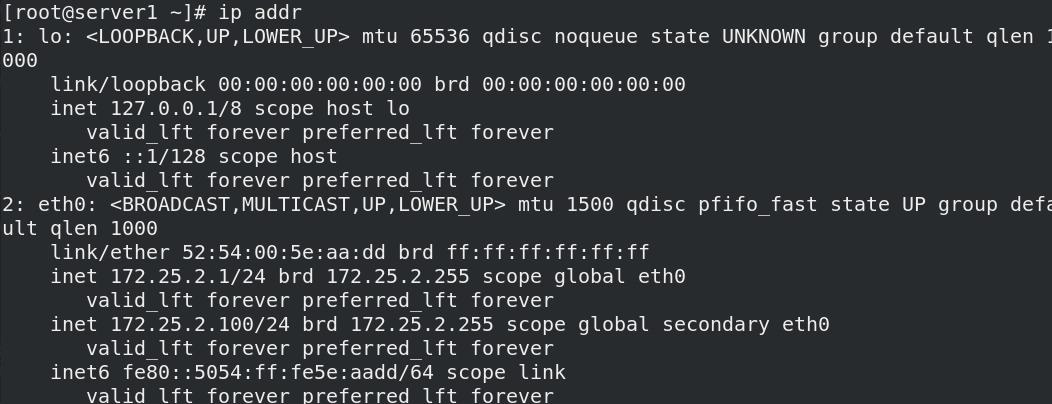
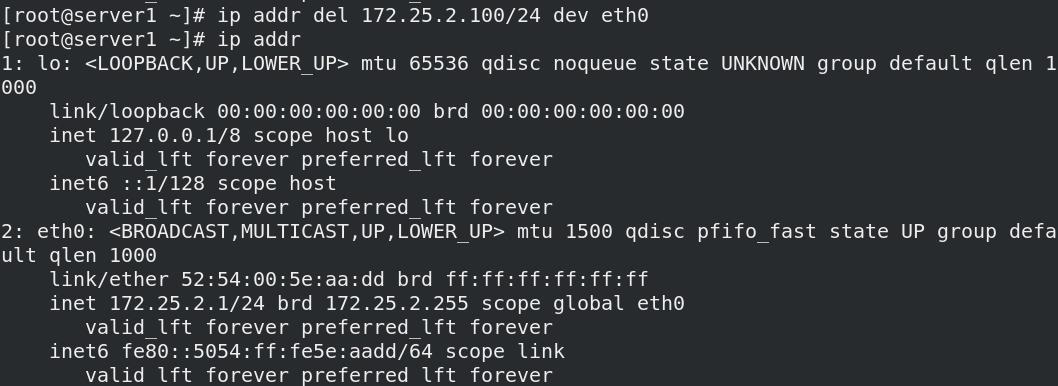
04_测试3:删除vip
- vip被删除后,检测到vip被删除,会自动添加
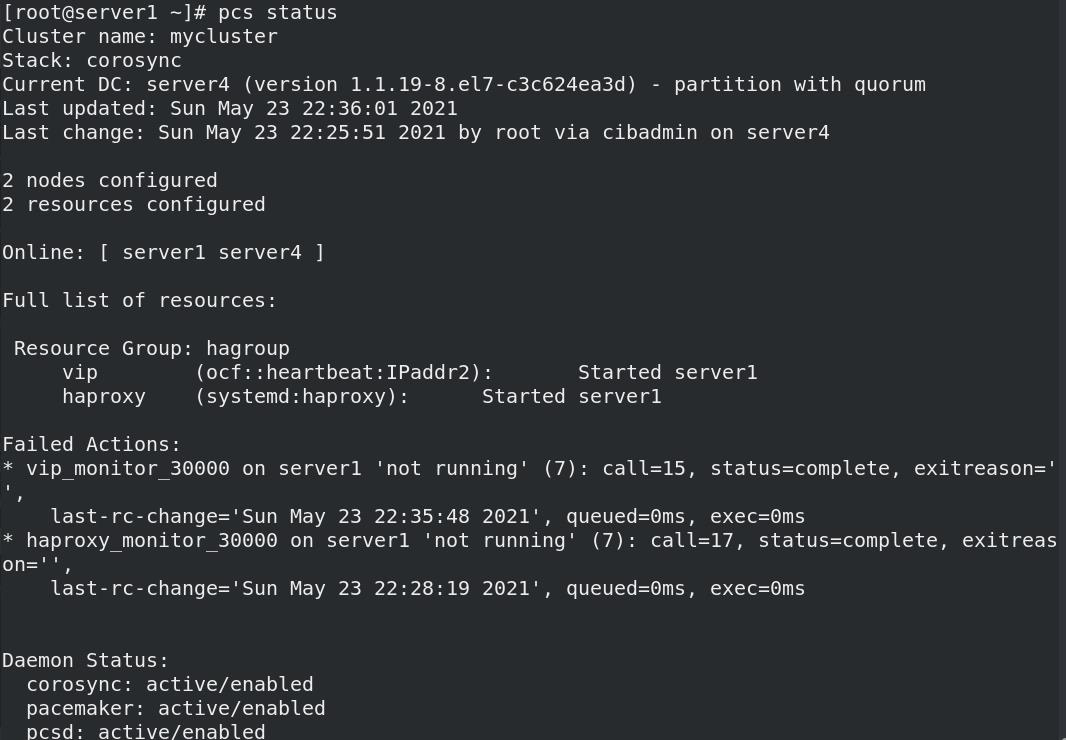
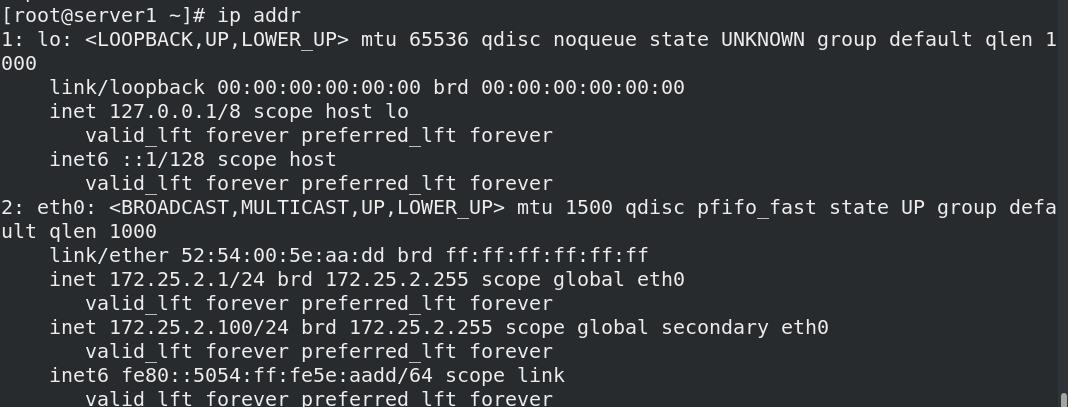
05_测试4:禁掉硬件设备
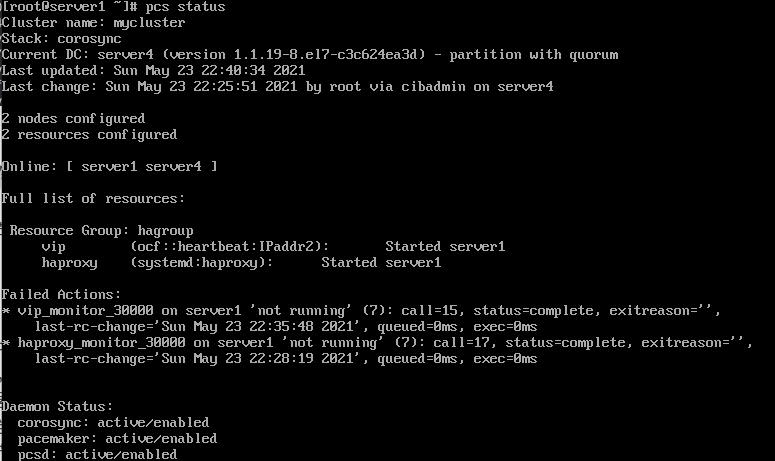
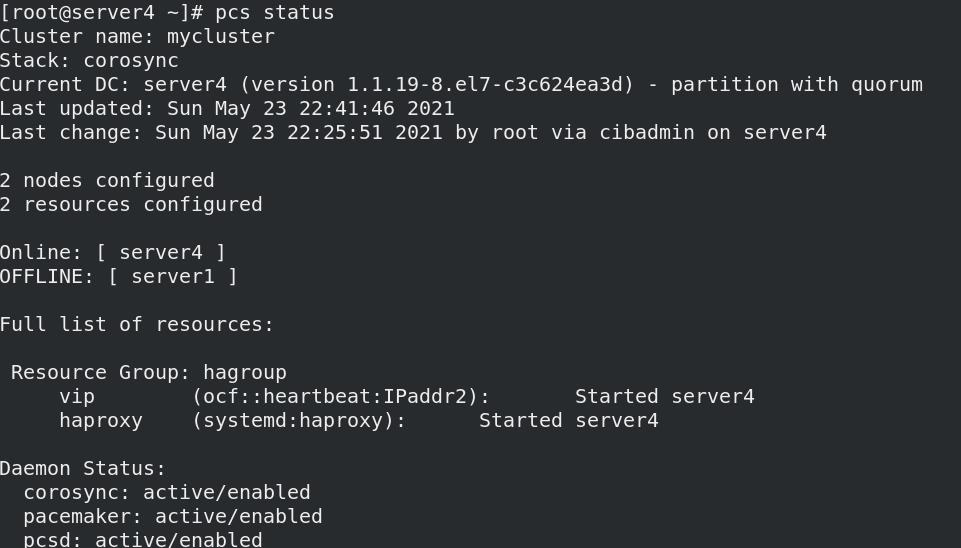
- 资源被自动接管到空闲节点server4,但是server1仍旧以为是自己接管,等到server1重启后才显示正常
ip link set down eth0
五、Fence
作用:在haproxy高可用集集群中,当主备服务器共享存储,备用服务器向主服务器通过心跳发送数据包检测主服务器状态,当主服务器接受大量客户请求导致CPU负载达到100%,资源耗尽,无法及时回复备服务器发送的数据包(延迟回复),造成主服务器假死状态,备用服务器抢夺资源,接管集群。当主服务器结束假死状态,两个服务器抢夺接管集群,造成集群资源被多个节点占有,两个节点同时向资源写数据,破坏了资源的安全性和一致性从而导致脑裂的发生。Fence会自动的把服务器A给kill掉,以阻止“脑裂”的发生.
原理:当意外原因导致主机异常或者宕机时,备用设备调用Fence设备将主机重启或将其从网络中隔离,当Fence操作成功后,返回信息给备机,备机接受到Fence的信息后,开始接管服务和资源。通过Fence将异常主机占据的节点信息释放,保证资源和服务始终运行在一个结点上。
01_检测主机安装与配置
Fence主机:172.25.2.250
- 安装fence-virtd、fence-virtd-libvirt、fence-virtd-multicast,网络监听器、电源管理器、内核层面控制虚拟机
yum install -y fence-virtd
yum install -y fence-virtd-libvirt
yum install -y fence-virtd-multicast - 编写fence信息
fence_virtd -c
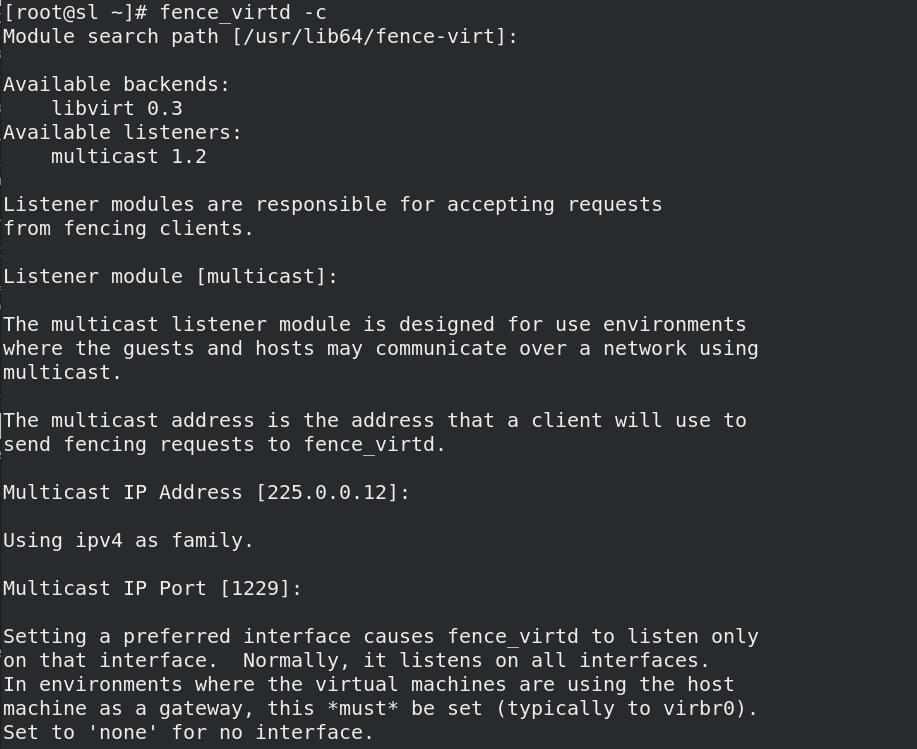
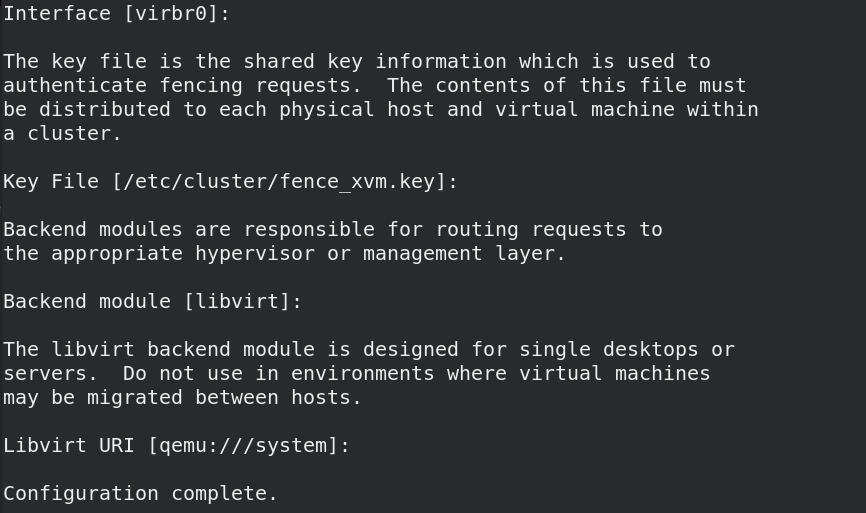
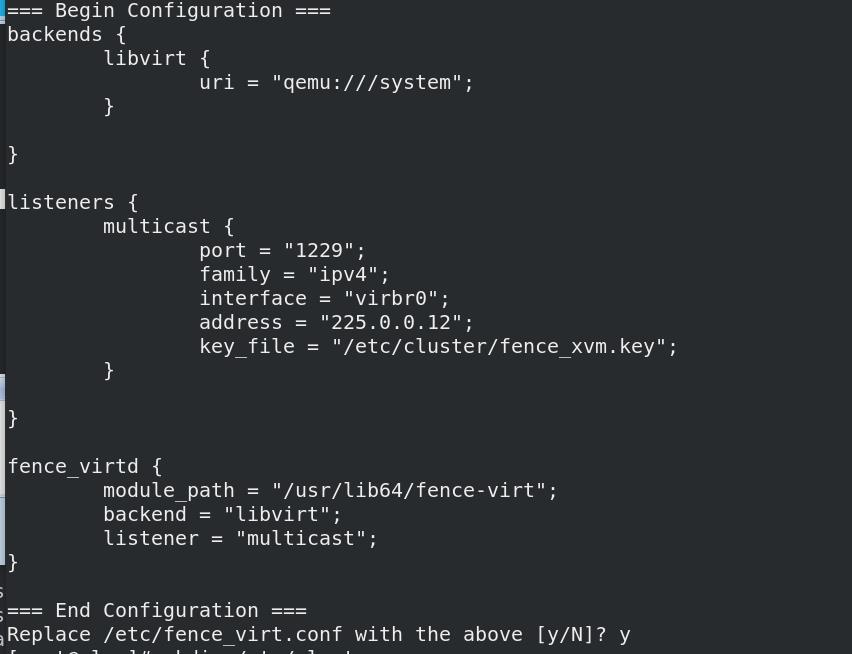
- 创建目录/etc/cluster,切到其目录下,生成key文件
mkdir /etc/cluster
cd /etc/cluster
dd if=/dev/urandom of=fence_xvm.key bs=128 count=1:生成key文件 - 重启fence_virtd服务,可以查看到1229端口

systemctl restart fence_virtd
- 传输key文件到被监测节点(在所有节点提前创建/etc/cluster目录)
scp fence_xvm.key root@172.25.2.1:/etc/cluster/
scp fence_xvm.key root@172.25.2.4:/etc/cluster/
02_集群服务器配置
- 所有集群服务器安装fence-virt
yum install fence-virt.x86_64 -y
ssh server4 yum install fence-virt.x86_64 -y - 查看fence代理
stonith_admin -I

- 添加fence
- pcs stonith create vmfence fence_xvm pcmk_host_map="server1:vm1;server4:vm4" op monitor interval=60s
选项在pcs stonith describe fence_xvm都可以查看到
#pcmk_host_map的值以键值对书写,如下:
#hostname:虚拟机名称
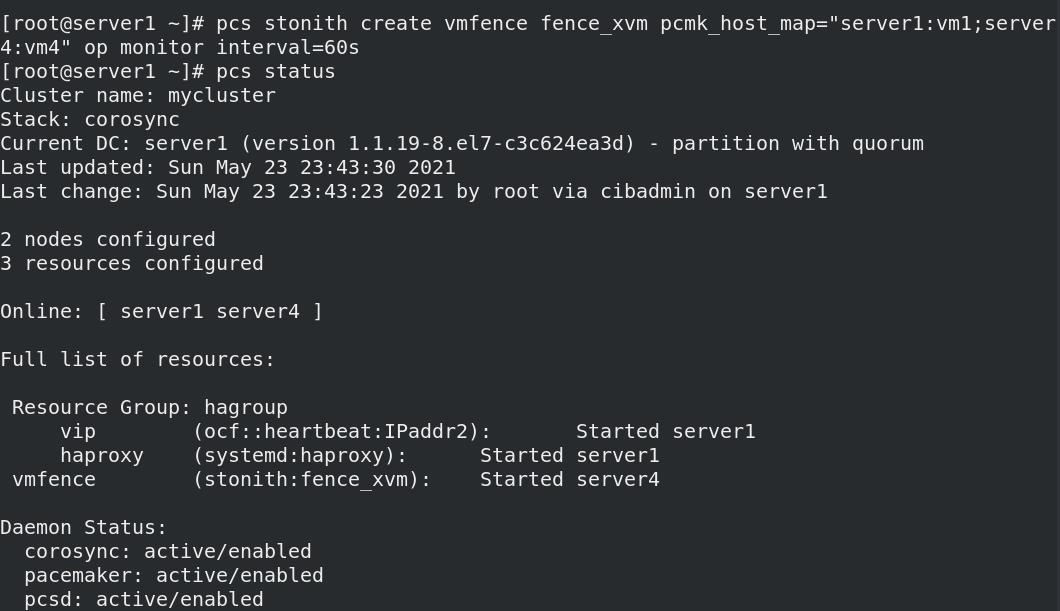
- 开启STONITH组件功能
pcs property set stonith-enabled=true - 验证群集配置信息无错误
crm_verify -LV
03_测试1:损坏内核
- 在节点server1测试:损坏内核,server1自动关机,再开启,实现监测功能!
echo c > /proc/sysrq-trigger
04_测试2:禁掉硬件设备
- 禁掉server4硬件设备,发现server4自动关机,再开启,实现监测功能!
ip link set down eth0
六、lvs与nginx
-
关闭pcs
pcs cluster stop --all
pcs cluster disable --all -
安装源码nginx
tar zxf nginx-1.18.0.tar.gz
cd nginx-1.18.0
yum install -y gcc pcre-devel openssl-devel:安装gcc、pcre-devel、openssl-devel -
关闭gcc的debug
vim auto/cc/gcc
#CFLAGS="$CFLAGS -g"
#注释此行(127行)可以使安装后的二进制文件更小
-
源码编译nginx
./configure --prefix=/usr/local/nginx --with-http_ssl_module:configure脚本,指定安装路径等参数
make && make install -
配置环境变量并启动服务
vim .bash_profile:编写变量
PATH=$PATH:$HOME/bin:/usr/local/nginx/sbin
source .bash_profile:重新读取文件,使变量生效
nginx:启动服务

- 配置文件
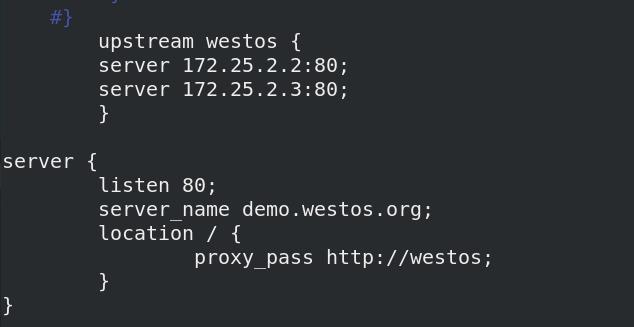
vim /usr/local/nginx/conf/nginx.conf
upstream westos {
server 172.25.2.2:80;
server 172.25.2.3:80;
}
server {
listen 80;
server_name demo.westos.org;
location / {
proxy_pass http://westos;
}
}
- 检查语法错误
nginx -t - 重新读取配置文件
nginx -s reload


- 测试
172.25.2.250
修改解析:
vim /etc/hosts
172.25.2.1 server1 demo.westos.org
访问测试:
for i in {1..5};do curl demo.westos.org;done
以上是关于haproxy高可用集群+pacemaker+fence (nginx源码编译)的主要内容,如果未能解决你的问题,请参考以下文章
Kubernetes(k8s)之k8s高可用负载均衡集群(haproxy+pacemaker实现负载均衡+高可用)
Linux的企业-高可用集群Haproxy+corosync+pacemaker+fence
HAproxy+keepalived/pacemaker实现高可用,负载均衡技术