深度学习项目三ResNet50多分类任务十二生肖分类
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习项目三ResNet50多分类任务十二生肖分类相关的知识,希望对你有一定的参考价值。
相关文章:
【深度学习项目一】全连接神经网络实现mnist数字识别
【深度学习项目二】卷积神经网络LeNet实现minst数字识别
【深度学习项目三】ResNet50多分类任务【十二生肖分类】
『深度学习项目四』基于ResNet101人脸特征点检测
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/1930877
1. 卷积神经网络简介
1.1 AlexNet

贡献:
- 引入ReLU作为激活函数
- Dropout层
- Max Pooling
- GPU加速
- 数据增强(截取、水平翻转)
1.2 VGG

1.3 GoogleNet

全连接层对输入输出大小有限制,用池化层代替没有约束。
1.4 ResNet
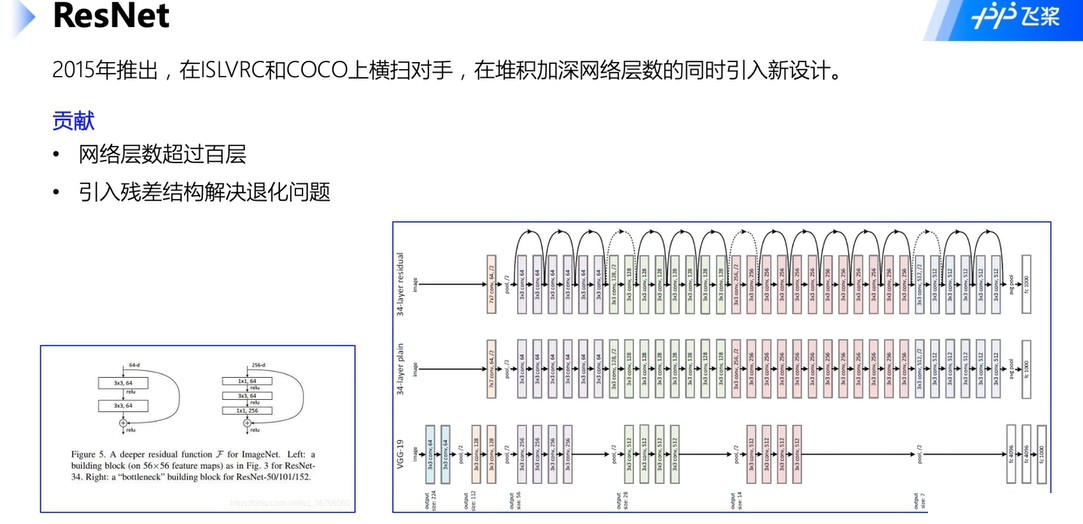
- 残差结构解决梯度消失问题,多个路径前向传播。
- 层数改变如图左下角,主要是为了减少计算开销,既减少参数。
2. 数据集介绍
按照12生肖在网上”下载的12种动物照片
训练样本量| 7,096张
验证样本量| 639张
测试样本量| 656张
加载使用方式|自定义数据集
2.1 数据标注
数据集分为train、valid、test三个文件夹,每个文件夹内包含12个分类文件夹,每个分类文件夹内是具体的样本图片。
.
├── test|train|valid
│ ├── dog
│ ├── dragon
│ ├── goat
│ ├── horse
│ ├── monkey
│ ├── ox
│ ├── pig
│ ├── rabbit
│ ├── ratt
│ ├── rooster
│ ├── snake
│ └── tiger
我们对这些样本进行一个标注处理,最终生成train.txt/valid.txt/test.txt三个数据标注文件。
```python
config.py
__all__ = ['CONFIG', 'get']
CONFIG = {
'model_save_dir': "./output/zodiac",
'num_classes': 12,
'total_images': 7096,
'epochs': 20,
'batch_size': 32,
'image_shape': [3, 224, 224],
'LEARNING_RATE': {
'params': {
'lr': 0.00375
}
},
'OPTIMIZER': {
'params': {
'momentum': 0.9
},
'regularizer': {
'function': 'L2',
'factor': 0.000001
}
},
'LABEL_MAP': [
"ratt",
"ox",
"tiger",
"rabbit",
"dragon",
"snake",
"horse",
"goat",
"monkey",
"rooster",
"dog",
"pig",
]
}
def get(full_path):
for id, name in enumerate(full_path.split('.')):
if id == 0:
config = CONFIG
config = config[name]
return config
import io
import os
from PIL import Image
from config import get
# 数据集根目录
DATA_ROOT = 'signs'
# 标签List
LABEL_MAP = get('LABEL_MAP')
# 标注生成函数
def generate_annotation(mode):
# 建立标注文件
with open('{}/{}.txt'.format(DATA_ROOT, mode), 'w') as f:
# 对应每个用途的数据文件夹,train/valid/test
train_dir = '{}/{}'.format(DATA_ROOT, mode)
# 遍历文件夹,获取里面的分类文件夹
for path in os.listdir(train_dir):
# 标签对应的数字索引,实际标注的时候直接使用数字索引
label_index = LABEL_MAP.index(path)
# 图像样本所在的路径
image_path = '{}/{}'.format(train_dir, path)
# 遍历所有图像
for image in os.listdir(image_path):
# 图像完整路径和名称
image_file = '{}/{}'.format(image_path, image)
try:
# 验证图片格式是否ok
with open(image_file, 'rb') as f_img:
image = Image.open(io.BytesIO(f_img.read()))
image.load()
if image.mode == 'RGB':
f.write('{}\\t{}\\n'.format(image_file, label_index))
except:
continue
generate_annotation('train') # 生成训练集标注文件
generate_annotation('valid') # 生成验证集标注文件
generate_annotation('test') # 生成测试集标注文件
2.2 数据集定义
接下来我们使用标注好的文件进行数据集类的定义,方便后续模型训练使用。
2.2.1 导入相关库
import paddle
import numpy as np
from config import get
HWC和CHW区别
- C代表:输入通道数
- H/W分别代表图片的高、宽
NCHW
- N代表样本数
to_tensor
paddle.vision.transforms.to_tensor(pic, data_format=‘CHW’)[源代码]
将 PIL.Image 或 numpy.ndarray 转换成 paddle.Tensor。
- 形状为 (H x W x C)的输入数据 PIL.Image 或 numpy.ndarray 转换为 (C x H x W)。 如果想保持形状不变,可以将参数 data_format 设置为 ‘HWC’。
- 同时,如果输入的 PIL.Image 的 mode 是 (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1) 其中一种,或者输入的 numpy.ndarray 数据类型是 ‘uint8’,那个会将输入数据从(0-255)的范围缩放到 (0-1)的范围。其他的情况,则保持输入不变。
2.2.2 导入数据集的定义实现
我们数据集的代码实现是在dataset.py中。
import paddle
import paddle.vision.transforms as T
import numpy as np
from config import get
from PIL import Image
__all__ = ['ZodiacDataset']
# 定义图像的大小
image_shape = get('image_shape') #'image_shape': [3, 224, 224],
IMAGE_SIZE = (image_shape[1], image_shape[2])
class ZodiacDataset(paddle.io.Dataset):
"""
十二生肖数据集类的定义
"""
def __init__(self, mode='train'):
"""
初始化函数
"""
assert mode in ['train', 'test', 'valid'], 'mode is one of train, test, valid.' #判断参数合法性
self.data = []
"""
根据不同模式选择不同的数据标注文件
"""
with open('signs/{}.txt'.format(mode)) as f:
for line in f.readlines():
info = line.strip().split('\\t')
if len(info) > 0:
self.data.append([info[0].strip(), info[1].strip()])#进行切分形成数组,每个数组包含图像的地址和label
if mode == 'train':
self.transforms = T.Compose([
T.RandomResizedCrop(IMAGE_SIZE), # 随机裁剪大小,裁剪地方不同等于间接增加了数据样本 300*300-224*224
T.RandomHorizontalFlip(0.5), # 随机水平翻转,概率0.5,也是等于得到一个新的图像
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
else: #评估模式:没必要进行水平翻转增加样本量了,主要是想看看效果
self.transforms = T.Compose([
T.Resize(256), # 图像大小修改
T.RandomCrop(IMAGE_SIZE), # 随机裁剪,
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
def __getitem__(self, index):
"""
根据索引获取单个样本
"""
image_file, label = self.data[index]
image = Image.open(image_file)
#转成RGB模式,三通道的
if image.mode != 'RGB':
image = image.convert('RGB')
image = self.transforms(image)#得到预处理后的结果
return image, np.array(label, dtype='int64')#对label做个数据转换,int类型转成numpy
def __len__(self):
"""
获取样本总数
"""
return len(self.data)
from dataset import ZodiacDataset
2.3.3 实例化数据集类
根据所使用的数据集需求实例化数据集类,并查看总样本量。
train_dataset = ZodiacDataset(mode='train')
valid_dataset = ZodiacDataset(mode='valid')
print('训练数据集:{}张;验证数据集:{}张'.format(len(train_dataset), len(valid_dataset)))
3.模型选择和开发
3.1 网络构建
本次我们使用ResNet50网络来完成我们的案例实践。
1)ResNet系列网络

2)ResNet50结构

3)残差区块

4)ResNet其他版本


network = paddle.vision.models.resnet50(num_classes=get('num_classes'), pretrained=True)
#pretrained=True使用别人已经训练好的预训练模型进行训练网络
model = paddle.Model(network)
model.summary((-1, ) + tuple(get('image_shape')))
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 64, 112, 112] 9,408
BatchNorm2D-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 256
ReLU-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 0
MaxPool2D-1 [[1, 64, 112, 112]] [1, 64, 56, 56] 0
Conv2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 4,096
BatchNorm2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-5 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-5 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
Conv2D-2 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
BottleneckBlock-1 [[1, 64, 56, 56]] [1, 256, 56, 56] 0
Conv2D-6 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384
BatchNorm2D-6 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-3 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-7 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-7 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-8 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-8 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
BottleneckBlock-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-9 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384
BatchNorm2D-9 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-4 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-10 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-10 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-11 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-11 [[1, 256, 56, 56]] [1,