大数据基本操作课程笔记
Posted shi_zi_183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据基本操作课程笔记相关的知识,希望对你有一定的参考价值。
课程目标
1、安装hadoop
2、尝试单机模式,伪分布模式,分布模式
课前环境
master、slave1、slave2三台虚拟机,可以相互ping通,可以免密登录,安装了jdk1.8.0,zookeeper,同步时钟。
安装hadoop
这里使用的hadoop-3.3.0.tar.gz

是二进制包,不需要编译,解压即可。
解压hadoop
tar -zxvf hadoop-3.3.0.tar.gz -C /usr/local

重命名hadoop根目录
mv /usr/local/hadoop-3.3.0/ /usr/local/hadoop

添加环境变量
这里因为我们只希望hadoop用户启动hadoop所以我们这里对环境变量的设置在
/home/hadoop/.bashrc进行。
这个脚本文件仅会在对应用户启动时被系统调用,这样就实现了用户个性化设置。
vi ~/.bashrc

这里将hadoop的bin和sbin目录写入了环境变量。
我们之前安装jdk的时候在profile中定义过了JAVA_HOME,这里需要重新定义,因为profile定义的变量虽然所有用户都可以使用,但是之后启动hadoop脚本时,会提示无法取到,我们需要在.bashrc中重新声明。
或者修改
/usr/local/hadoop/etc/hadoop/hadoop-env.sh
将其中的JAVA_HOME写成绝对路径。
使环境变量立即生效
source .bashrc
检查hadoop
hadoop version
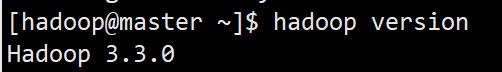
配置单机模式
单机模式直接使用hadoop不须修改配置文件。
注意在这之前一定要先切换hadoop用户。
su hadoop
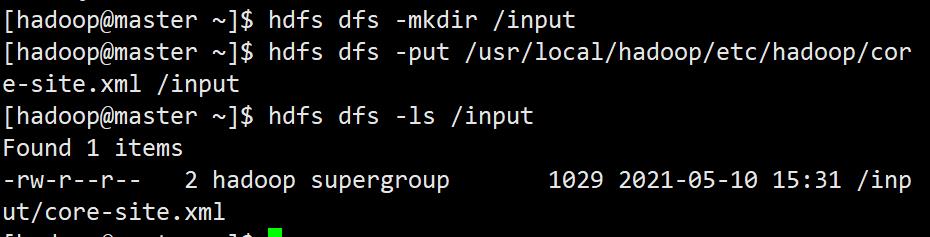
新建输入目录
mkdir /usr/local/hadoop/input
放入测试文件
这里使用hadoop配置文件做测试文件(是什么都无所谓,有内容就行)
cp /usr/local/hadoop/etc/hadoop/*.xml /usr/local/hadoop/input/
执行样例程序中的单词计数
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /usr/local/hadoop/input/ /usr/local/hadoop/output
其中 /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar是使用的jar包
wordcount 是程序名称
/usr/local/hadoop/input/ 是我们放入统计文件的输入目录
/usr/local/hadoop/output 是结果文件的输出目录(这个目录不能新建不然会报错)。
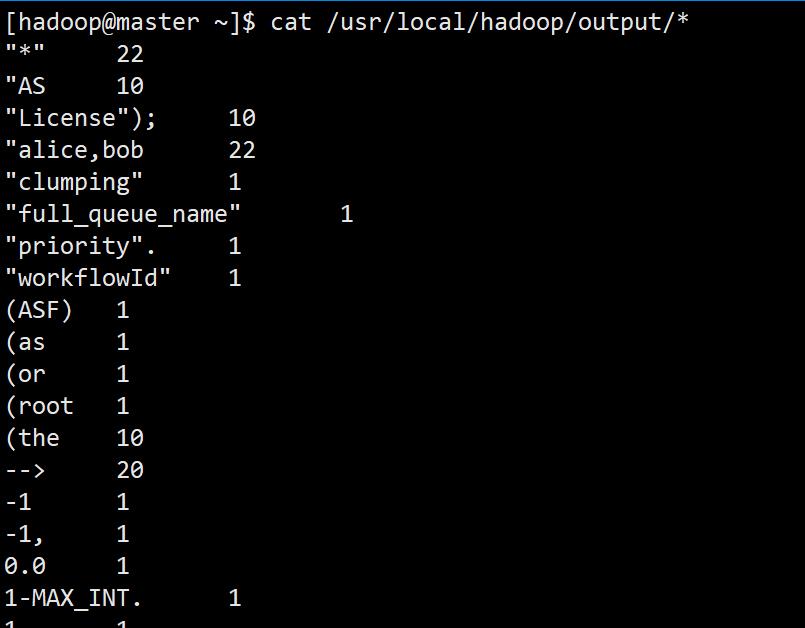
查看结果
ll /usr/local/hadoop/output/
cat /usr/local/hadoop/output/*

目录下有_SUCCESS证明运行成功。
配置伪分布式
伪分布就是由master同时充当namenode和datanode。
修改主配置文件
vi /usr/local/hadoop/etc/hadoop/core-site.xml
hadoop配置文件是xml格式的,修改参数时要按照xml格式。
配置项写在configuration标签里,这个标签不开缺省不然会报错。
一个配置项一个property标签。
property一般包含三种标签:
name:表示配置项名称
value:表示配置项值
description:表示对配置项的描述
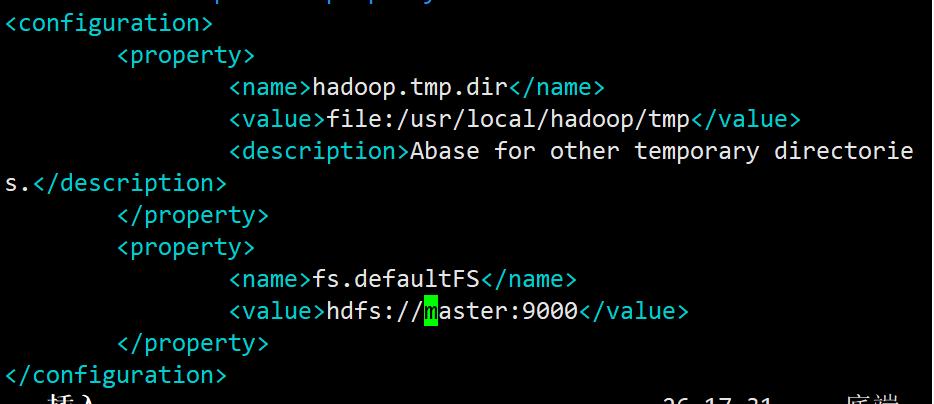
hadoop.tmp.dir是hadoop存放临时文件的目录,默认是在/tmp
为了防止意外关机导致tmp情况,建议放在持久化目录下。
fs.defaultFS是设置hdfs的默认根目录地址,并指定datanode向namenode发送心跳的地址。
这里应该是master或master的ip地址+开启端口
配置hdfs配置文件
vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml

dfs.replication是数据块的备份份数,默认3块,备份越多,冗余越高,安全性越好。
dfs.namenode.name.dir是保存FsImage镜像的目录,作用是存放hadoop的名称节点namenode里的metadata;dfs.datanode.data.dir是存放HDFS文件系统数据文件的目录,作用是存放hadoop的数据节点datanode里的多个数据块。
dfs.http.address 是hadoop http服务器的地址与监听端口。
格式化名称节点
hadoop namenode -format

注意这里格式化一定要使用hadoop用户,不然创建的新文件不是hadoop用户,会导致无法启动。
启动hadoop
start-dfs.sh

成功启动
验证hadoop

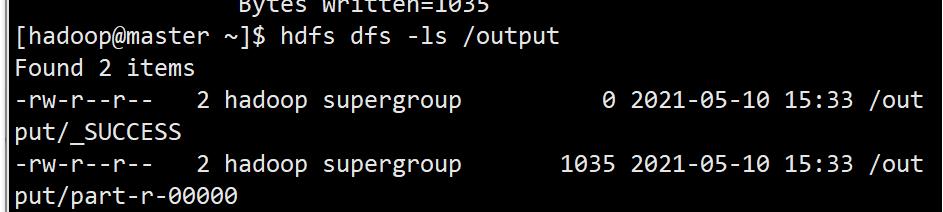
成功
配置分布式
修改主配置文件
vi /usr/local/hadoop/etc/hadoop/core-site.xml
与伪分布一样
修改hdfs配置文件
增加一个备用namenode——httpd服务器
vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml

修改mapred配置文件
vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
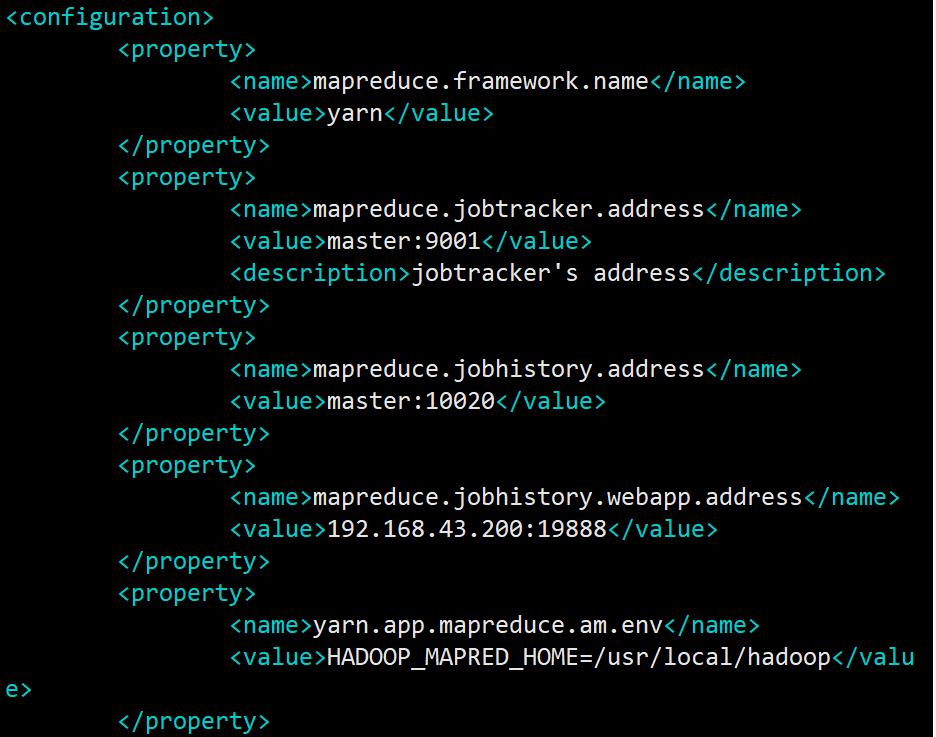
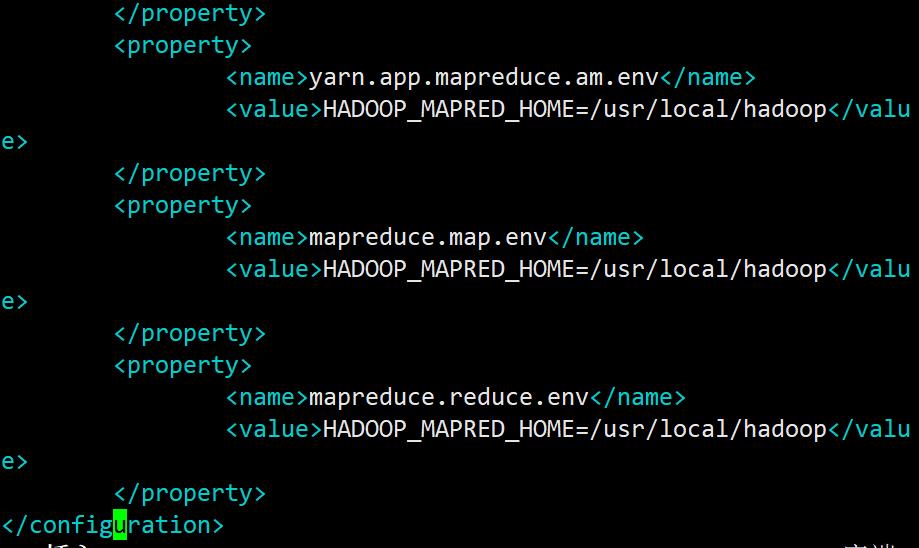
mapreduce.jobtracker.address 值改为master+端口号,标明jobtracker的地址与端口
mapreduce.jobhistory.address 值改为master+端口号,表名jobhistory的地址与端口
mapreduce.jobhistory.webapp.address 值改为master_ip+端口号,表名web界面的地址
修改workers
vi /usr/local/hadoop/etc/hadoop/workers
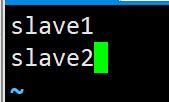
写入工作节点的主机名。
修改yarn配置文件
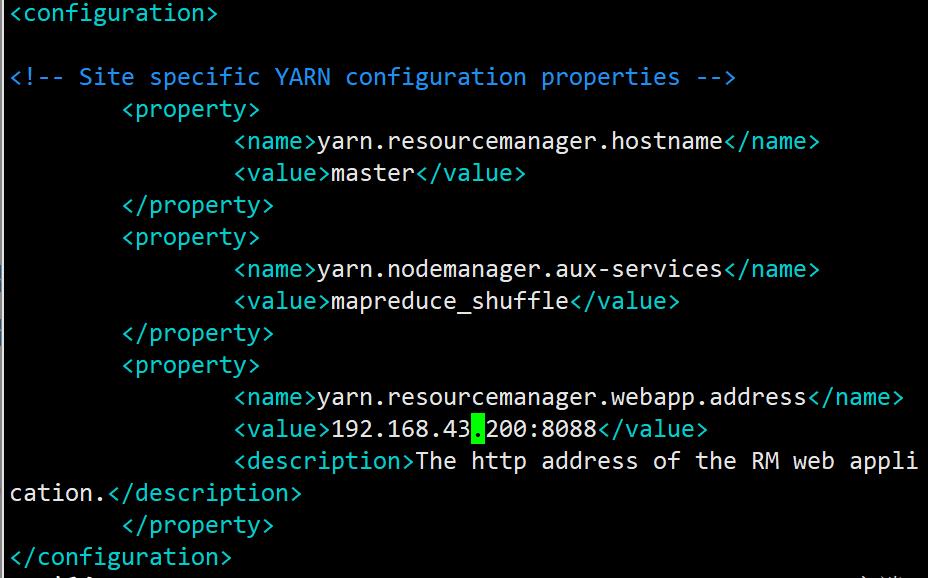
yarn.resourcemanager.hostname 改为master
yarn.resourcemanager.webapp.address 改为master_ip+端口号
删除master下的log,tmp
这个log,tmp是伪分布下生成的,我们需要删除从新生成
注意:打包复制之前一定要先删除原先的文件。
打包配置好的hadoop
tar -zcvf hadoop.tar.gz hadoop/
子节点获取hadoop并解压
scp hadoop@master:/usr/local/hadoop.tar.gz ./hadoop.tar.gz
tar -zxvf hadoop.tar.gz -C /usr/local/
初始化master的namenode
master输入
hadoop namenode -format

启动分布式
master输入
start-all.sh

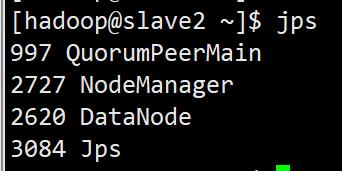
检查是否启动
master

slave1、slave2

以上是关于大数据基本操作课程笔记的主要内容,如果未能解决你的问题,请参考以下文章