爬虫进阶 - XPath应用
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫进阶 - XPath应用相关的知识,希望对你有一定的参考价值。
XPath学习
XPath 简介
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻XML 文档的,但同样适用于 html 文档的搜索。所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。
…
XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有想要定位的节点都可以用 XPath来选择。
…
官方文档:https://www.w3.org/TR/xpath/。
XPath安装
pip install lxml
XPath语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是沿着路径(path)或者步(steps)来选取的。下面列举了一些常用的路径表达式进行节点的选取,如表所示:
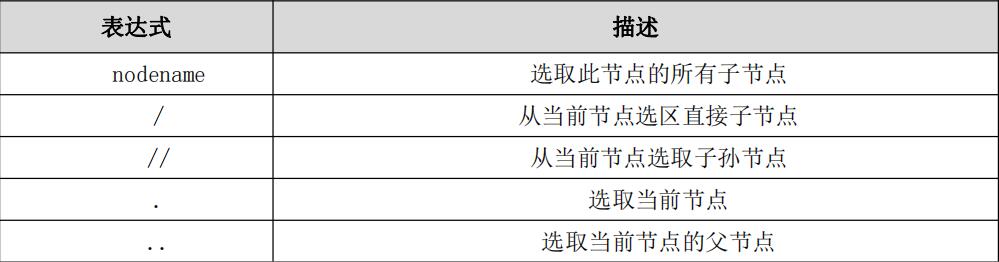
XPath 的常用匹配规则如下所示:
//title[@lang='eng']
上述 XPath 匹配规则代表的是选择所有名称为title,同时属性 lang 的值为 eng 的节点,后面会通过 Python 的 lxml 库,利用 XPath 进行 HTML 的解析。
上面路径都是选取了所有符合条件的节点,是否能选取某个特定的节点或者包含某一个指定值得节点,这就需要用到谓语。谓语被嵌在方括号中,用来查找某个特定的节点或者包含某个指定的值的节点。
- 谓语示例:
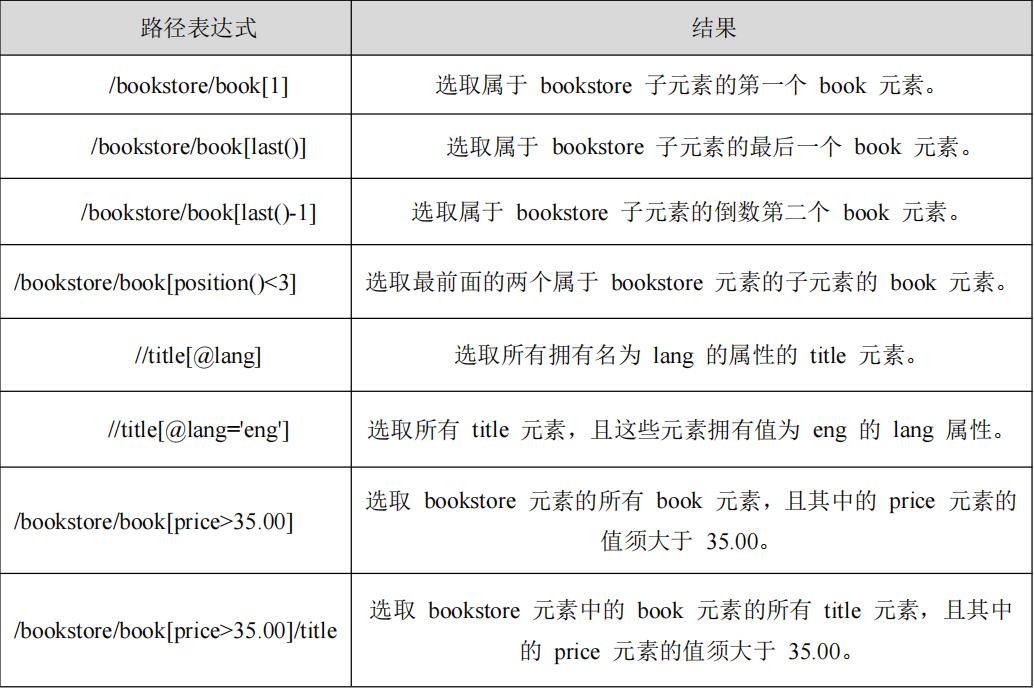
- 选取未知节点

- 通配符选取示例

通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
- 选取若干路径示例
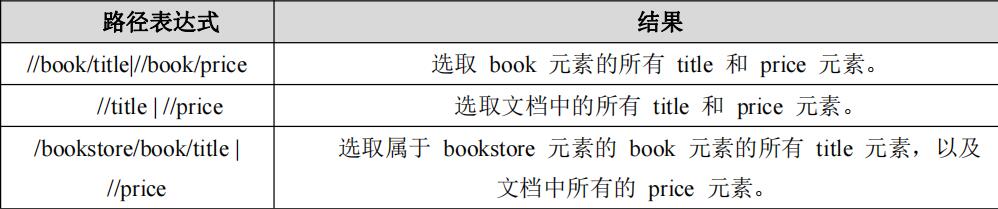
XPath 使用
首先给出 XPath_test.html,实例分析就按照这个文档来进行,文档内容如下:
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li>
</ul>
</div> </body></html>
用以 // 开头的 XPath 规则来选取所有符合要求的节点
from lxml import etree
# 第一个参数,解析的HTML文件, etree.HTMLParser解析器
html = etree.parse('./xpath_test.html', etree.HTMLParser())
# 获取所有节点
result = html.xpath('//*')
print(result)
结果如下
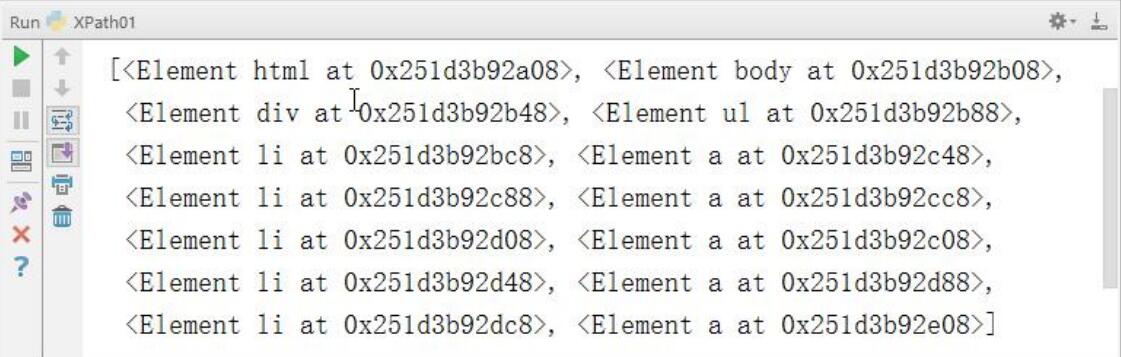
上述示例中 * 代表匹配所有节点,返回的结果是一个列表,每个元素都是一个 Element 类型,后跟节点名称。
也可以指定匹配的节点名称,示例如下。
指定匹配的节点名称
from lxml import etree
# 第一个参数,解析的HTML文件, etree.HTMLParser解析器
html = etree.parse('./xpath_test.html', etree.HTMLParser())
# 获取所有节点
print("获取ul节点")
result = html.xpath('//ul')
print(result)
print(html.xpath('//li'))
通过 / 或 // 即可查找元素的子节点或子孙节点。选择 li 节点的所有直接 a 子节点。
选择 li 节点的所有直接 a 子节点
from lxml import etree
html = etree.parse('./XPath_test.html', etree.HTMLParser())
result = html.xpath('//li/a') print(result)
用@符号进行属性过滤
print('根据属性选择')
# @ 是属性选择, 单引号中用双引号
print(html.xpath('//li[@class="item-inactive"]'))
print('获取节点下子节点')
print(html.xpath('//li[@class="item-inactive"]/a'))
调用 text()方法获取文本
print('获取节点文本')
# text() 获取节点文本
print(html.xpath('//li[@class="item-inactive"]/a/text()'))
@符号跟属性名直接获取节点的属性值
print('获取节点的属性值')
# @href:获取属性值, li 下 a标签 的 href属性值
print(html.xpath('//li[@class="item-inactive"]/a/@href'))
多属性匹配
from lxml import etree
print('多属性匹配')
text = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
<li class="li" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
print(html.xpath('//li[@class="li li-first" and @name="item"]'))
# 包含 contains(@class, "li")
print(html.xpath('//li[contains(@class, "li") and @name="item"]'))
摘自尚学堂PDF
感谢!
技术开源,知识共享,分享快乐!
加油!
以上是关于爬虫进阶 - XPath应用的主要内容,如果未能解决你的问题,请参考以下文章