5.11 Seq2seq +Attention可视化
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5.11 Seq2seq +Attention可视化相关的知识,希望对你有一定的参考价值。
1.Seq2Seq
Sequence-to-sequence 模型(以下简称 Seq2Seq)是一种深度学习模型,其论文《Sequence to Sequence Learning with Neural Networks》由谷歌的同学于 2014 年发表于 NIPS 会议,目前已有超过 9400 次的引用。Seq2Seq 的应用广泛,常应用于机器翻译,语音识别,自动问答等领域。谷歌翻译也在 2016 开始使用这个模型。接下来介绍的 Seq2Seq 是没加 Attention 的传统 Seq2Seq,而我们现在经常说的 Seq2Seq 是加了 Attention 的模型。
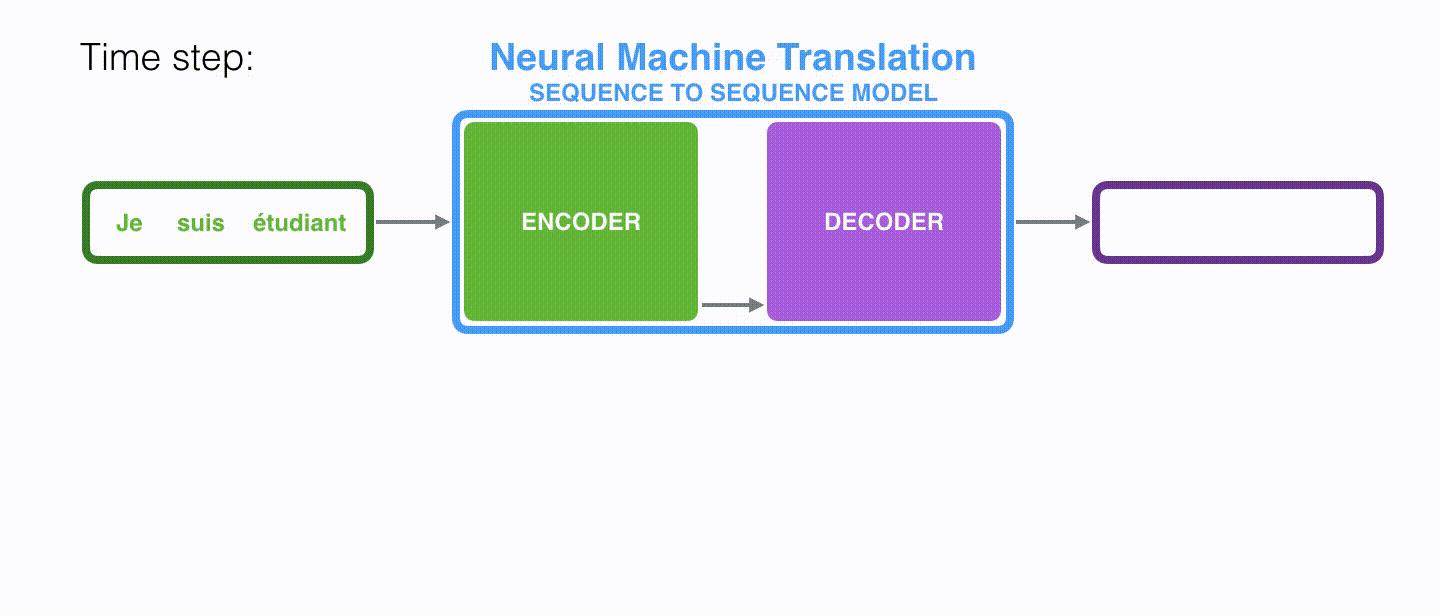
Seq2Seq 可以理解为输入一个序列,然后经过一个黑盒后可以得到另一个序列:

如果将 Seq2Seq 应用于机器翻译领域的话,就是输入一种语言,然后得到另一个语言:

这个黑盒中,是 Encoder-Decoder 框架。输入一个序列 ( x 1 , x 2 , . . . , x T x_1,x_2,...,x_T x1,x2,...,xT) ,然后编码器进行编码得到一个上下文信息 c \\mathbf{c} c(一个向量),然后通过解码器进行逐一解码,最后得到另一个序列 ( y 1 , y 2 , . . . , y T ′ y_1,y_2,...,y_{T^{\\prime}} y1,y2,...,yT′) 。
这边我们需要注意几点:
- 输入/输出序列:输入输出序列都是 Embedding 向量;
- 上下文信息:上下文信息 c \\mathbf{c} c 是一个向量,其维度与编码器的数量有关,通常大小为 256、512、1024 等。
- 逐一解码:解码器需要根据上下文 c \\mathbf{c} c 和先前生成了历史信息 来生成此刻的 。
这里的编码器和解码器根据不同的模型和应用都是可以自由变换和组合的,常见的有 CNN/RNN/LSTM/GRU 等。而 Seq2Seq 使用的是 RNN 模型。
在机器翻译的情况下,上下文是一个向量(基本上是一组数字)。

上下文是浮点数的向量。
您可以在设置模型时设置上下文向量的大小。它基本上是编码器RNN中隐藏单元的数量。这些可视化显示了大小为4的向量,但在实际应用程序中,上下文向量的大小可能是256、512或1024。
RNN在每个时间步长有两个输入:一个输入(在编码器的情况下,输入句子中的一个字)和一个隐藏状态。但是,这个词需要用一个向量表示。要将一个单词转换成一个向量,我们需要使用一种叫做“词嵌入”方法。这些方法将单词转换为向量空间,从而捕捉到单词的许多含义/语义信息。
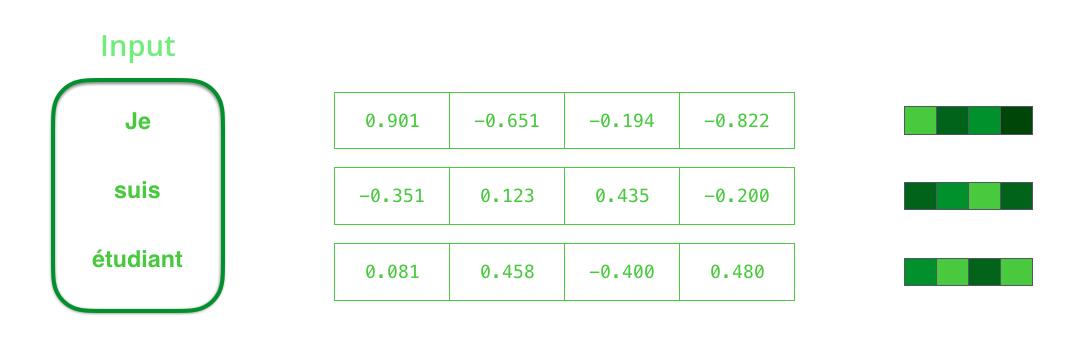
在处理之前,我们需要把输入的单词转换成向量。该转换是使用一个字嵌入算法完成的。我们可以使用预先训练过的嵌入,也可以在数据集上训练我们自己的嵌入。尺寸为200或300的嵌入向量是典型的,为了简单起见,我们展示了一个大小为4的向量。
现在我们已经介绍了我们的主要向量/张量,让我们回顾一下RNN的机制,并建立一种可视化语言来描述这些模型:
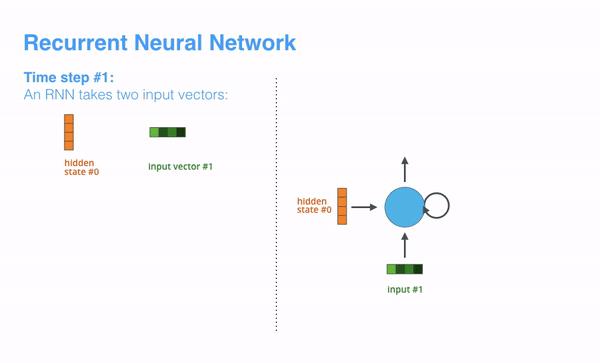
下一个RNN步骤采用第二个输入向量和隐藏状态#1来创建该时间步骤的输出。
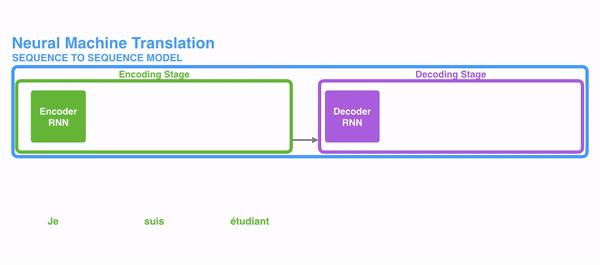
在下面的可视化中,编码器或解码器的每个脉冲都是RNN处理其输入并生成该时间步长的输出。由于编码器和解码器都是RNNs,每一次RNNs都会做一些处理,它会根据它的输入和之前看到的输入更新它的隐藏状态。
让我们看看编码器的隐藏状态。请注意,最后一个隐藏状态实际上是我们传递给解码器的上下文。
解码器还维护从一个时间步骤传递到下一个时间步骤的隐藏状态。我们只是没有在这个图形中可视化它,因为我们现在关注的是模型的主要部分。
现在让我们看看另一种可视化序列到序列模型的方法。这个动画将使它更容易理解描述这些模型的静态图形。这被称为“展开”视图,这里我们不是显示一个解码器,而是为每个时间步骤显示它的一个副本。这样我们就可以看到每个时间步长的输入和输出。
数学公式
在Seq2Seq中,给定一个源序列(消息) X = \\mathbf{X}= X= ( x 1 , x 2 , … , x T ) \\left(x_{1}, x_{2}, \\ldots, x_{T}\\right) (x1,x2,…,xT) 和一个目标序列(响应) Y = \\mathbf{Y}= Y= ( y 1 , y 2 , … , y T ′ ) \\left(y_{1}, y_{2}, \\ldots, y_{T^{\\prime}}\\right) (y1,y2,…,yT′), 模型在 X \\mathbf{X} X条件下使 Y \\mathbf{Y} Y 的生成概率最大化: p ( y 1 , … , y T ′ ∣ x 1 , … , x T ) p\\left(y_{1}, \\ldots, y_{T^{\\prime}} \\mid x_{1}, \\ldots, x_{T}\\right) p(y1,…,yT′∣x1,…,xT).
具体来说,Seq2Seq是一个编码器-解码器结构。编码器逐字读取
X
\\mathbf{X}
X,并通过RNN将其表示为上下文向量
c
\\mathbf{c}
c,然后以
c
\\mathbf{c}
c为输入,估计
Y
\\mathbf{Y}
Y的生成概率。Seq2Seq的目标函数可以写成
p
(
y
1
,
…
,
y
T
′
∣
x
1
,
…
,
x
T
)
=
p
(
y
1
∣
c
)
∏
t
=
2
T
′
p
(
y
t
∣
c
,
y
1
,
…
,
y
t
−
1
)
p\\left(y_{1}, \\ldots, y_{T^{\\prime}} \\mid x_{1}, \\ldots, x_{T}\\right)=p\\left(y_{1} \\mid \\mathbf{c}\\right) \\prod_{t=2}^{T^{\\prime}} p\\left(y_{t} \\mid \\mathbf{c}, y_{1}, \\ldots, y_{t-1}\\right)
p(y1,…,yT′∣x1,…,xT)=p(y1∣c)t=2∏T′p(yt∣c,y1,…,yt−1)
编码器RNN计算上下文向量
c
\\mathbf{c}
c :
h
t
=
f
(
x
t
,
h
t
−
1
)
c
=
h
T
\\mathbf{h}_{t}=f\\left(x_{t}, \\mathbf{h}_{t-1}\\right) \\\\ \\mathbf{c}=\\mathbf{h}_{T}
ht=f(xt,ht−1)c=hT
其中
h
t
\\mathbf{h}_{t}
ht是
t
t
t时刻的隐藏状态,
f
f
f是一个非线性转换,它可以是LSTM或GRU。在本工作中,我们使用GRU实现
f
f
f
z
=
σ
(
W
z
x
t
+
U
z
h
t
−
1
)
r
=
σ
(
W
r
x
t
+
U
r
h
t
−
1
)
s
=
tanh
(
W
s
x
t
+
U
s
(
h
t
−
1
∘
r
)
)
h
t
=
(
1
−
z
)
∘
s
+
z
∘
h
t
−
1
\\begin{array}{l} \\mathbf{z}=\\sigma\\left(\\mathbf{W}^{z} \\mathbf{x}_{t}+\\mathbf{U}^{z} \\mathbf{h}_{t-1}\\right) \\\\ \\mathbf{r}=\\sigma\\left(\\mathbf{W}^{r} \\mathbf{x}_{t}+\\mathbf{U}^{r} \\mathbf{h}_{t-1}\\right) \\\\ \\mathbf{s}=\\tanh \\left(\\mathbf{W}^{s} \\mathbf{x}_{t}+\\mathbf{U}^{s}\\left(\\mathbf{h}_{t-1} \\circ \\mathbf{r}\\right)\\right) \\\\ \\mathbf{h}_{t}=(1-\\mathbf{z}) \\circ \\mathbf{s}+\\mathbf{z} \\circ \\mathbf{h}_{t-1} \\end{array}
z=σ(Wzxt+Uzht−1)r=σ(Wrxt+Urht−1)s=tanh(Wsxt+Us(ht−1∘r))ht=(1−z)∘s+z∘h