Stream流
Posted 圆圆的球
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Stream流相关的知识,希望对你有一定的参考价值。
Stream流式编程思想
--洱涷
(1)什么是Stream
Stream是一种流,是一种抽象的处理数据的思想,这种编程方式将要处理的元素集合看作一种流,流在管道中传输,然后在管道的每一个节点上对流进行操作(去重,分组,过滤…),元素流在经过管道的操作后,最后由最终操作得到新的一个元素集合。
Stream是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象所形成的一个队列,Stream并不会去储存元素,而是按照需求所进行元素计算等操作
- 数据源流的来源可以是集合、数组、产生器generator等
- 聚合操作就是类似于SQL语句的操作,filter,map,reduce,find,match,sorted等。
和Collection操作不同,Stream还具有两个基础的特征:
-
Pipelining:中间的每一次操作返回的都是流对象的本身,这样多个操作就可以串联成一个管道。这样做可以对操作进行优化,比如延迟执行(laziness)和短路(short-circuiting)
延迟执行:Stream的很多操作都是延迟执行的,例如,“查找具有三个连续元音的第一 个字符串”
短路:传入一个谓词,返回值为Boolean,如果符合条件直接结束流,例如: findFirst(),只要找到第一个符合的,直接结束
-
内部迭代:以前对集合遍历都是通过Iterator或for-each的方式,显式的在集合外部进行迭代,这叫外部迭代,Stream提供了内部迭代的方式,通过访问者模式实现。
(2)生成流
- stream() − 为集合创建串行流。
- parallelStream() − 为集合创建并行流。
串行流就是按照顺序执行一直到结束,并行流就是把内容切成多个数据块,并且利用多个线程分别处理每个数据块的内容。Stream的API中声明可以通过parallel()和sequential()方法在并行流和串行流之间切换。
注意:使用并行流并不一定能提高效率,因为jvm对数据进行切片和切换线程也是需要时间的,所以数据量越小,串行流越快,数据量越大,并行流效率越高。
JDK1.8并行流使用的是fork/join框架进行并行操作。
fork/join框架:就是在必要的情况下,将一个大任务拆分成若干个小任务(拆到不可再拆),再将一个个小任务的结果进行join汇总
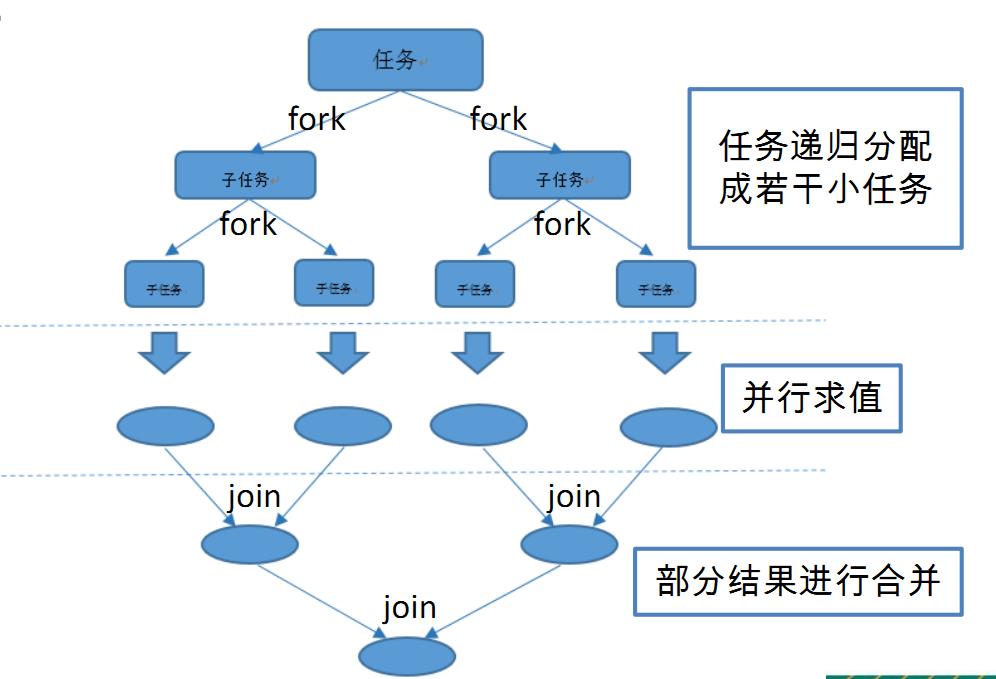
(3)stream流的各种方法
1. count、anyMatch、allMatch、noneMatch
count方法和list的size()一样,返回的都是这个集合流的元素的长度,不同的一点,流是集合的一个高级工厂,中间操作是工厂里的每一道工序,我们对这个流操作完后,可以进行元素的数量和。
anyMatch表示判断的条件里,只要有一个成功,就返回true。
allMatch表示判断的条件里,所有的都要成功才会返回true。
noneMatch表示判断的条件里,所有的都不是返回true
List<String> strs = Arrays.asList("a", "a", "a", "a", "b");
boolean aa = strs.stream().anyMatch(str -> str.equals("a"));
boolean bb = strs.stream().allMatch(str -> str.equals("a"));
boolean cc = strs.stream().noneMatch(str -> str.equals("a"));
long count = strs.stream().filter(str -> str.equals("a")).count();
System.out.println(aa);// TRUE
System.out.println(bb);// FALSE
System.out.println(cc);// FALSE
System.out.println(count);// 4
2. map、filter、flatMap
map方法:
这个方法传入了一个function函数式接口(定义了一个apply的抽象方法,接收一个泛型T对象,并且返回泛型R对象,我们在做基础数据处理的时候(eg: Integer i=0; Integer dd= i+1;),会对基础类型的包装类,进行拆箱的操作,转成基本类型,再做运算处理,拆箱和装箱,其实是非常消耗性能的,尤其是在大量数据运算的时候;这些特殊的Function函数式接口,根据不同的类型,避免了拆箱和装箱的操作,从而提高程序的运行效率)
function接口的应用例子:
Function<Integer, Integer> function1 = x -> x * 2;
System.out.println(function1.apply(4));// 8
Function<Integer, String> function2 = x -> x * 2 + "dd";
System.out.println(function2.apply(4));//8dd
Function<String, String> strFunction1 = (str) -> new String(str);
System.out.println(strFunction1.apply("aa"));//aa
Function<String, String> strFunction2 = String::new;
System.out.println(strFunction2.apply("bb"));//bb
Function<String, Emp> objFunction1 = (str) -> new Emp(str);
System.out.println(objFunction1.apply("cc").getName());//cc
Function<String, Emp> objFunction2 = Emp::new;
System.out.println(objFunction2.apply("dd").getName());//dd
这个接口接收一个泛型T,返回一个泛型R,表示调用这个方法后,可以改变返回的类型,操作如下:
Integer[] dd = { 1, 2, 3 };
Stream<Integer> stream = Arrays.stream(dd);
stream.map(str -> Integer.toString(str)).forEach(str -> {
System.out.println(str);// 1 ,2 ,3
System.out.println(str.getClass());// class java.lang.String
});
List<Emp> list = Arrays.asList(new Emp("a"), new Emp("b"), new Emp("c"));
list.stream().map(emp -> emp.getName()).forEach(str -> {
System.out.println(str);
});
filter方法:
这个方法传入了一个Predicate的函数接口(断言,与、或、非、比较),这个接口传入一个泛型T,做完操作后,返回一个Boolean值,filter的作用是返回boolean值为true的对象。
String[] dd = { "a", "b", "c" };
Stream<String> stream = Arrays.stream(dd);
stream.filter(str -> str.equals("a")).forEach(System.out::println);//返回字符串为a的值
flatMap方法:
这个接口和map一样,接收一个Function的函数式接口,不同的是,这个接口的第二个参数是一个Stream流,方法返回的也是一个泛型R,作用是将两个流变为为一个流返回:
String[] strs = { "aaa", "bbb", "ccc" };
Arrays.stream(strs).map(str -> str.split("")).forEach(System.out::println);// Ljava.lang.String;@53d8d10a
Arrays.stream(strs).map(str -> str.split("")).flatMap(Arrays::stream).forEach(System.out::println);// aaabbbccc
Arrays.stream(strs).map(str -> str.split("")).flatMap(str -> Arrays.stream(str)).forEach(System.out::println);// aaabbbccc
第一段输出代码里,我们先看map操作,通过上面对map的介绍,我们可以看到,map可以改变返回的Stream的泛型,str.split(""),根据空字符串分隔,返回的类型是一个数组,返回的流也是Stream<String[]>,而不是Stream;在第二段代码中,数组的流,经过map操作,返回Stream<String[]>后,再经过flatMap,把数组通过Arrays.stream变成一个新的流,再返回到原来的流里;这样,两个流就合并成一个流;第三段代码是第二段代码的另一种写法。
3. distinct、sorted、peek、limit、skip
//去重复
Stream<T> distinct();
//排序
Stream<T> sorted();
//根据属性排序
Stream<T> sorted(Comparator<? super T> comparator);
//对对象的属性进行操作
Stream<T> peek(Consumer<? super T> action);
//截断--取先maxSize个对象
Stream<T> limit(long maxSize);
//截断--忽略前N个对象
Stream<T> skip(long n);
例子如下:
public class TestJava8 {
public static List<Emp> list = new ArrayList<>();
static {
list.add(new Emp("xiaoHong1", 20, 1000.0));
list.add(new Emp("xiaoHong2", 25, 2000.0));
list.add(new Emp("xiaoHong3", 30, 3000.0));
list.add(new Emp("xiaoHong4", 35, 4000.0));
list.add(new Emp("xiaoHong5", 38, 5000.0));
list.add(new Emp("xiaoHong6", 45, 9000.0));
list.add(new Emp("xiaoHong7", 55, 10000.0));
list.add(new Emp("xiaoHong8", 42, 15000.0));
}
public static void println(Stream<Emp> stream) {
stream.forEach(emp -> {
System.out.println(String.format("名字:%s,年纪:%s,薪水:%s", emp.getName(), emp.getAge(), emp.getSalary()));
});
}
public static void main(String[] args) {
// 对数组流,先过滤重复,在排序,再控制台输出 1,2,3
Arrays.asList(3, 1, 2, 1).stream().distinct().sorted().forEach(str -> {
System.out.println(str);
});
// 对list里的emp对象,取出薪水,并对薪水进行排序,然后输出薪水的内容,map操作,改变了Strenm的泛型对象
list.stream().map(emp -> emp.getSalary()).sorted().forEach(salary -> {
System.out.println(salary);
});
// 根据emp的属性name,进行排序
println(list.stream().sorted(Comparator.comparing(Emp::getName)));
// 给年纪大于30岁的人,薪水提升1.5倍,并输出结果
Stream<Emp> stream = list.stream().filter(emp -> {
return emp.getAge() > 30;
}).peek(emp -> {
emp.setSalary(emp.getSalary() * 1.5);
});
println(stream);
// 数字从1开始迭代(无限流),下一个数字,是上个数字+1,忽略前5个 ,并且只取10个数字
// 原本1-无限,忽略前5个,就是1-5数字,不要,从6开始,截取10个,就是6-15
Stream.iterate(1, x -> ++x).skip(5).limit(10).forEach(System.out::println);
}
public static class Emp {
private String name;
private Integer age;
private Double salary;
public Emp(String name, Integer age, Double salary) {
super();
this.name = name;
this.age = age;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
}
}
4. forEachOrdered和forEach
这两个函数都是对于集合的流,进行遍历操作,是属于内部迭代,传入一个Consumer的函数式接口(这个接口,接收一个泛型的参数T,然后调用accept,对这个参数做一系列的操作,没有返回值,可以理解为理解Consumer,消费者,主要是对入参做一些列的操作,在stream里,主要是用于forEach)
List<String> strs = Arrays.asList("a", "b", "c");
strs.stream().forEachOrdered(System.out::print);//abc
System.out.println();
strs.stream().forEach(System.out::print);//abc
System.out.println();
strs.parallelStream().forEachOrdered(System.out::print);//abc
System.out.println();
strs.parallelStream().forEach(System.out::print);//bca
前两个操作是Stream的串行流,后两个是Stream的并行流,可以看出在并行流的情况下如果对遍历的结果的顺序有严格要求的话,可以使用forEachOrdered
5. toArray操作
该方法没有传参,返回Object[],在具体实现中也是调用了
public final <A> A[] toArray(IntFunction<A[]> generator)
重载的toArray的实现,传入了一个Object的数据
具体使用:
List<String> strs = Arrays.asList("a", "b", "c");
String[] dd = strs.stream().toArray(str -> new String[strs.size()]);
String[] dd1 = strs.stream().toArray(String[]::new);
Object[] obj = strs.stream().toArray();
String[] dd2 = strs.toArray(new String[strs.size()]);
Object[] obj1 = strs.toArray();
可以看到,前三个,是调用的stream的toArray的函数,以及一些用法,后面的两个,是直接调用的List接口的toArray函数,List接口里的。
6. min、max、findFirst、findAny
min和max传入的是一个Comparator,这个是一个对比接口,那么返回就是根据比较的结果,取到的集合里面,最大的值,和最小的值;
findFirst和findAny,对这个集合的流,做一系列的中间操作后,可以调用findFirst,返回集合的第一个对象,findAny返回这个集合中,取到的任何一个对象;通过这样的描述,我们也可以知道,在串行的流中,findAny和findFirst返回的,都是第一个对象;而在并行的流中,findAny返回的是最快处理完的那个线程的数据,所以说,在并行操作中,对数据没有顺序上的要求,那么findAny的效率会比findFirst要快的
List<String> strs = Arrays.asList("d", "b", "a", "c", "a");
Optional<String> min = strs.stream().min(Comparator.comparing(Function.identity()));
Optional<String> max = strs.stream().max((o1, o2) -> o1.compareTo(o2));
System.out.println(String.format("min:%s; max:%s", min.get(), max.get()));// min:a; max:d
Optional<String> aa = strs.stream().filter(str -> !str.equals("a")).findFirst();
Optional<String> bb = strs.stream().filter(str -> !str.equals("a")).findAny();
Optional<String> aa1 = strs.parallelStream().filter(str -> !str.equals("a")).findFirst();
Optional<String> bb1 = strs.parallelStream().filter(str -> !str.equals("a")).findAny();
System.out.println(aa.get() + "===" + bb.get());// d===d
System.out.println(aa1.get() + "===" + bb1.get());// d===b or d===c
7. reduce操作
reduce是一种归约操作,将流归约成一个值的操作,用函数式编程的术语来说叫做折叠
常用于集合中元素的累加,例子如下:
List<Integer> numList = Arrays.asList(1,2,3,4,5);
int result = numList.stream().reduce((a,b) -> a + b ).get();
System.out.println(result);
代码实现了对numList中的元素累加。lambada表达式的a参数是表达式的执行结果的缓存,也就是表达式这一次的执行结果会被作为下一次执行的参数,而第二个参数b则是依次为stream中每个元素。如果表达式是第一次被执行,a则是stream中的第一个元素。
在表达式中假如打印参数的代码,打印出来的内容如下:
a=1,b=2
a=3,b=3
a=6,b=4
a=10,b=5
8. collect操作
操作如下:
public class TestJava8 {
public static List<Emp> list = new ArrayList<>();
static {
list.add(new Emp("上海", "小名", 17));
list.add(new Emp("北京", "小红", 18));
list.add(new Emp("深圳", "小蓝", 19));
list.add(new Emp("广州", "小灰", 20));
list.add(new Emp("杭州", "小黄", 21));
list.add(new Emp("贵阳", "小白", 22));
}
@Test
public void test1() {
// 转list
List<String> names = list.stream().map(emp -> emp.getName()).collect(Collectors.toList());
// 转set
Set<String> address = list.stream().map(emp -> emp.getName()).collect(Collectors.toSet());
// 转map,需要指定key和value,Function.identity()表示当前的Emp对象本身
Map<String, Emp> map = list.stream().collect(Collectors.toMap(Emp::getName, Function.identity()));
// 计算元素中的个数
Long count = list.stream().collect(Collectors.counting());
// 数据求和 summingInt summingLong,summingDouble
Integer sumAges = list.stream().collect(Collectors.summingInt(Emp::getAge));
// 平均值 averagingInt,averagingDouble,averagingLong
Double aveAges = list.stream().collect(Collectors.averagingInt(Emp::getAge));
// 综合处理的,求最大值,最小值,平均值,求和操作
// summarizingInt,summarizingLong,summarizingDouble
IntSummaryStatistics intSummary = list.stream().collect(Collectors.summarizingInt(Emp::getAge));
System.out.println(intSummary.getAverage());// 19.5
System.out.println(intSummary.getMax());// 22
System.out.println(intSummary.getMin());// 17
System.out.println(intSummary.getSum());// 117
// 连接字符串,当然也可以使用重载的方法,加上一些前缀,后缀和中间分隔符
String strEmp = list.stream以上是关于Stream流的主要内容,如果未能解决你的问题,请参考以下文章