基于Solr,构建搜索引擎专栏· 高级篇
Posted Talking Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Solr,构建搜索引擎专栏· 高级篇相关的知识,希望对你有一定的参考价值。
相似搜索
这是一个相似检索的案例,这个案例是这样来实现的。首先创建solrserver对象,第二步创建SolrQuery对象solrQuery,这样来写:

这样我们就根据给定的id,确立了参照物,然后以这个参照物为准,找到其相似的记录。实现相似检索,也是通过对solrQuery的设置来完成的,具体参数设这如下:
 每一个参数的含义,上面的注释都有说明。图中的mlt指的是MoreLikeThis对象,封装了Lucene中的MoreLikeThis。有一点需要特别注意:在设置mlt的fl属性,也就是制定用作相似检索的字段的时候,在solr的schema.xml中所对应的每个字段都要将其TermVector这个属性添加上,并且设置为true。因为相似将所就是依照”关键词向量”的夹角余弦值来计算的,如果不设置这个属性为true,则solr无法完成相似将所功能。
每一个参数的含义,上面的注释都有说明。图中的mlt指的是MoreLikeThis对象,封装了Lucene中的MoreLikeThis。有一点需要特别注意:在设置mlt的fl属性,也就是制定用作相似检索的字段的时候,在solr的schema.xml中所对应的每个字段都要将其TermVector这个属性添加上,并且设置为true。因为相似将所就是依照”关键词向量”的夹角余弦值来计算的,如果不设置这个属性为true,则solr无法完成相似将所功能。
//获取响应对象responseQueryResponse response = solrserver.query(solrQuery);//获取相似结果NamedList<Object> moreLikeThis = (NamedList<Object>)response.getResponse().get("moreLikeThis");//从指定的模型或矩阵中,得到指定的元素(element)List<SolrDocument> docs = (List<SolrDocument>)moreLikeThis.getVal(0);
通过response对象的getResponse().get(“moreLikeThis”)到Object类型NameList对象moreLikeThis,这里第一次设计到NameList这个类,它的类结构是这样的:

可以看到他是org.apache.solr.common.util包中的类,是Object类型的。通过这个moreLikeThis的getVal()方法,就能得到<SolrDocument>类型的搜索结果,然后通过循环这个结果就得到了我们要的所有与参照Document相似的结果。

相似检索实现非常简单,主要是理解思想。
自动摘要
(1)检索的时候生成摘要是这样的:我们填入搜索关键字参数param,SolrQuery对象会根据这个参数找到关键词出现次数最多的那段文本,文本的长度也通过Fragsize()来设置,具体这样写:

这样我们就能够得到搜索时候生成的摘要了。
(2)在添加的时候生成摘要,是出于性能的考虑,只将一篇全文的摘要信息存放到索引库中,检索的时候只检索摘要信息,然后从数据库中找到其对应的数据记录,这样一来就大大减少了索引库的数据存储量,在数据量非常庞大的时候,就缩短了搜索的时间。查找了一些solr相关的文档,没有找到solr中提供有在添加时生成摘要信息的接口或方法(这个问题可以继续查阅,如果solr提供了这样的接口或方法,最好时候solr本身的接口或方法)。这里,采用这样的思路:我们还是利用solr在查询时生成摘要,然后将这个摘要返回,添加到对应的索引库中。具体这样实现:第一步:新添加一个索引库,这个库就是专门用来生成摘要的;第二步:在添加数据之前,先将全文添加到这个摘要的索引库中,然后通过对应的搜索方法截取我们所需长度的摘要,将这个生成的摘要返回;
第三步:在摘要库返回之后,将先前添加的全文删除掉,这样做是为了清空摘要库,而避数据过大时,摘要库的崩溃。 第四步:在页面上接收到返回的摘要,将其添加到对应的索引库中,这样就实现了在添加时生成摘要,也就是说再每篇文章对应的库中,只添加了文章的摘要,而搜索的全文内容要从数据库中获取。
高级搜索

这里前面一共是三个搜索条件选择框,没个选择框中都是这样的内容(这里只是一个案例,具体按搜索可以自行添加):
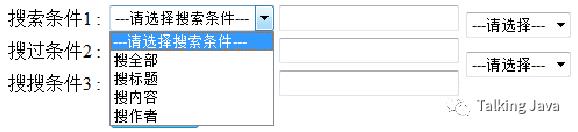
三个搜索条件框都相同,可以按标题、内容、作者、全部,这样来检索。相对应后边的三个文本框是用来输入搜索参数例如:param1、param2、param3的。注意看后边的两个下拉列表:
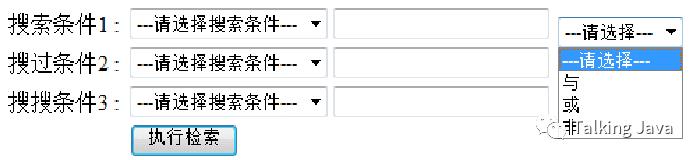
每一个下拉列表中都存在与、或、非3中逻辑选择,第一个下拉列表的值表示param1与param2之间的布尔关系,而第二个下拉列表中的值,表示第一个与第二个逻辑结果与param3的布尔关系。当我们执行提交的时候就进行相应的检索,这是一个最普通的高级,先做到这里,下面谈一下如何具体实现。首先来写页面,就是刚才看到的这个效果,这样来写:
<form action="advancedSearch2Action" method="post"><div id="1"><table><tr><td>搜索条件1 : </td><td><select name="s1"><option>---请选择搜索条件---</option><option value=" ">搜全部</option><option value="1">搜标题</option><option value="2">搜内容</option><option value="3">搜作者</option></select></td><td><input type="text" name="param1"/></td></tr><tr><td>搜过条件2 : </td><td><select name="s2"><option>---请选择搜索条件---</option><option value=" ">搜全部</option><option value="1">搜标题</option><option value="2">搜内容</option><option value="3">搜作者</option></select></td><td><input type="text" name="param2"/></td></tr><tr><td>搜搜条件3 : </td><td><select name="s3"><option>---请选择搜索条件---</option><option value=" ">搜全部</option><option value="1">搜标题</option><option value="2">搜内容</option><option value="3">搜作者</option></select></td><td><input type="text" name="param3"/></td></tr><tr><td></td><td><input type="submit" value="执行检索"/></td></tr></table></div><div id="2"><select id="s4" name="s4"><option value=" ">---请选择---</option><option value="1">与</option><option value="2">或</option><option value="3">非</option></select><br/><select id="s5" name="s5"><option value=" ">---请选择---</option><option value="1">与</option><option value="2">或</option><option value="3">非</option></select></div></form>
很简单的一个页面,器是就是五个下拉s1、s2、s3、s4、s5,三个文本框param1、param2、param3。这里小复习一下:<select></select>根据起属性name可以去到其子项<option></option>的值,这个值由<option>的value属性指定,如上边的代码。重点是Action,在写Action之前,要先了解Solr的查询语法:

了解了这些,就可以开始写Action了:

在Action中定义这样8个私有属性,分别对应5个下拉列表,和三个文本框,并生成其对应的getter/setter,在主方法execute()中这样写

//创建一个参数param:将用户搜索的参数合并到一起,统一传给SolrTool工具类进行搜索StringBuilder param = new StringBuilder();//第一层:根据第一个条件参数s1,确定第一个搜索参数param1switch(s1){case '1':param1 = "title:" + param1;break;case '2':param1 = "content:" + param1;break;case '3':param1 = "author:" + param1;break;default:param1 = "" + this.param1;}//第二层:根据第二个条件参数s2,确定第二个搜索参数param2switch(s2){case '1':param2 = "title:" + param2;break;case '2':param2 = "content:" + param2;break;case '3':param2 = "author:" + param2;break;default:param2 = this.param2;}//第三层:根据第三个条件参数s3,确定第三个搜索参数param3switch(s3){case '1':param3 = "title:" + param3;break;case '2':param3 = "content:" + param3;break;case '3':param3 = "author:" + param3;break;default:param3 = this.param3;}//第四层:确立前两个搜索参数(param1/param22)的逻辑关系switch(s4){case '1':param.append(param1).append(" " + "&&" + " ").append(param2);break;case '2':param.append(param1).append(" " + "||" + " ").append(param2); break;case '3':param.append(param1).append(" ").append("-").append(param2);break;default:log.info("未选中逻辑条件s4!");}//第五层:确定param1和param2运算结果与param3的关系switch(s5){case '1':param.append(" " + "&&" + " ").append(param3);break;case '2':param.append(" " + "||" + " ").append(param3);break;case '3':param.append(" ").append("-").append(param3);break;default:log.info("未选中逻辑条件s5!");}
这样一来,在Action中就能够按照用户在页面上的选择得得到相应的检索参数,例如:
用户在页面上这么填写:

当执行检索,最后的得到的检索参数param是这个样子的:
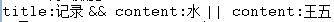
这个例子的意思就是:检索所有标题(title)中含有”记录”的文档集合,在此基础上检索内容(content)中含有”水”的文档记录,也就是将标题中虽然含有”记录”,但是内容中没有”水”的记录排除掉,再在其基础上”或”内容中含有”王五”的,综合以上条件得到相应的结果。这里只要明白一点,solr检索的时候用查询所有的方法就可以,我们是通过控制检索参数,来得到高级检索的结果集的。最好得到这样的结果:
 可以看到第2条记录中,标题含有”记录”,内容中含有”水”,并且高亮显示了,这样就得了我们所期待的结果。
可以看到第2条记录中,标题含有”记录”,内容中含有”水”,并且高亮显示了,这样就得了我们所期待的结果。
结果排序
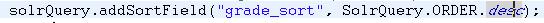
可以看到这个参数也是对SolrQuery对象的设置,在这个例子SolrQuery.ORDER.desc只的是按着grade_sort这个字段降序排列。在需求中常常会这样做:我们自己添加一个字段,然后按着这个字段来给文档排序,将这个字段作为一个分值,也就是文档打分功能了,这里需要注意的是,对于这个用于排序的field,有这样的要求:

除去以上两点之外,这个字段一般为int、float、double类型,这些我们都要在schema.xml中配置好。这里有一个案例:
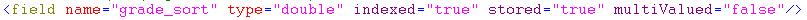
在这个案例中,我们自己添加的排序字段是double类型的,solr中的double类型是这
样的:
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>这样在solrj中,我们就可以这样来按着指定的字段进行排序:
扩展:在做了以上的打分排序之后,有时候需求会要求更高,例如:当文档的得分相
同时,也就是grade_sort字段的值相同,需要按文档添加日期排序,最新添加的文档
要先显示,先前添加的文档后显示。这时候这样来做,只需要在Solrj中再添加一句排
序代码就可以了:

这样一来,文档会先按照grade_sort字段进行排序,当grade_sort值相同的时候,就会
时间字段date来排序了。
本文为《基于Solr,构建搜索引擎专栏(三) • 高级篇》,后续会陆续推出更多高级篇章,谢谢观看,如果您感兴趣更多知识分享,也欢迎关注:Talking Java
以上是关于基于Solr,构建搜索引擎专栏· 高级篇的主要内容,如果未能解决你的问题,请参考以下文章