不懂这些JVM知识,真不敢说是大数据开发!
Posted Flink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不懂这些JVM知识,真不敢说是大数据开发!相关的知识,希望对你有一定的参考价值。
大数据开发都要熟悉JVM
Hotspot虚拟机
简介
人机工程学
分代内存管理
调整分代内存空间
总体内存配置
新生代内存配置
Survivor内存配置
凌晨一点的说说
大数据开发都要熟悉JVM
JVM,相信大家都很熟悉。
这似乎是Java开发工程师的专利。
不过,
很多Java开发也只是停留在书本、理论的层面。
因为,可能很多传统的Java开发把程序部署在一台32GB的服务器上,
从来都没看过OOM,唯一一次OOM,还被运维一次性重启解决了。
但对于大数据开发,
每个人都应该熟悉JVM。
理由很简单:
-
Hadoop、Spark、Flink等都 运行在JVM上 -
大数据需要处理的 数据量更大,OOM太太太常见了
19年、20年,我面试了很多人。
每次几乎都会问一问JVM。
因为大家也都清楚,
主要是真正做到大一点规模的大数据项目,
不可能没有见过OOM异常,不调整JVM参数的。
我发现,
当我问到JVM,
大家对它的理解,仅仅是停留在了解大体的结构上。
更有甚者,
连每个结构的作用都说不清楚。
很多开发都有一颗学习JVM的心,
但大多都抓不住重点。
更多人的,都是把书买回来,随便翻了翻,然后扔回书柜里。
最后,千万不要忘了给书柜拍个照片。
学习JVM最重要的是:
-
理解JVM的内存结构 -
Class字节码与Class Loader -
理解JVM的各种GC算法、运行机制 -
理解每个JVM调优参数的意义
篇幅原因,我无法一次性把所有内容介绍完。
本次重点讲解JVM的内存结构与基本调参。
后续,我们再陆续完善其他内容。
[注] 本篇以目前应用最广泛的JDK 8为例子。
Hotspot虚拟机
简介
大家都在说JVM,
但提到JVM,就一定要说一说 HotSpot——Java HotSpot Performance Engin。
HotSpot就是Java虚拟机的一种实现。
历史
其实Sun从1999年,1.3版本发布的JDK就包含了HotSpot。
Java HotSpot虚拟机是Java SE的一个核心组件,我们经常所看到的class字节码,就是由它来执行的。
它是基于名为Longtalk的语言构建的,而最初是由一个名为Animorphic(LongView Technologies)的公司开发。
这个公司是由Sun的两位技术人员成立的。
他们基于Selt Virtual Machine开发了Longview虚拟机。
1997年,Sun收购了Animorphic。
Sun收购Animorphic之后,Sun决定为Java虚拟机编写一个新的JIT编译器。
新的编译器,产生了一个新的名称:HotSpot。
HotSpot用C++语言编写。
2007年,Sun估计它大概包含了25W行的源代码。
HotSpot能够在运行Java字节码时,会连续分析程序的性能,并找到经常执行的热点,然后进行优化。
HotSpot JVM在某些BenchMark测试中,比一些C和C++代码性能更好。
HotSpot提供了以下几个非常重要的组件:
-
Java ClassLoader -
Java字节码解释器 -
Client和Server虚拟机,它们针对各自的场景进行了优化 -
若干个GC -
一组运行时库
人机工程学
第一次看到官网上的人机工程学(Ergonomics)还蛮意外的!
因为之前听说的更多的是人体工程学这个名字。例如:座椅呀、鼠标等等。
其实是一回事。
这门科学是研究:
人和机器、环境相互作用并合理结合,使设计的机器和环境系统适合人的生理或心理等特点。
简单来说,
就是设计一样东西,让人身心愉悦。
Oracle官网在介绍HotSpot时,在开篇就提到了人机工程学,可以看出来,这一款JVM注重了用户的使用。
而不仅仅是面对“冰冷”的机器。
默认选择
HotSpot人机工程学体现在用户对JVM、GC调优过程。HotSpot JVM为GC、Heap大小、JIT提供了依赖于平台的默认配置。
Don't let me choose!
选择从来都是一件非常苦难的事情!
大家吃中饭点餐的时候就知道了!:)
这些默认选项未必能够匹配各种不同的应用程序,
但我们仅需要调整非常少的参数即可。
所以,
大家将来开发的应用也可以参考下JVM的人机工程学,
别搞那么多的配置、那么多的参数。
让所有的事情更容易被使用、被复用、被运维。
就大数据来说,
引入过多的组件就是不符合人机工程学的。:)
而针对服务器类型定义为:
-
2个或者更多的处理器 -
2GB或者更多的内存
服务器类型的默认选项为:
-
围绕吞吐量的GC -
初始Heap的大小为 1/64,最大为1GB -
最大Heap的大小为 1/4,最大为1GB -
适合服务器上运行的JIT
基于行为的优化
说到优化,传统的方式就是:
调参,跑应用,调参,如此反复。
而HotSpot JVM基于行为的调整,会根据应用程序的运行行为来调整自己的结构大小。
例如:设定某个目标(最大GC暂停时间、吞吐量),让JVM自动根据程序运行行为调整。
分代内存管理
在开发应用程序时,内存管理是一项复杂的工作。
开发过C、C++的同学,应该更清楚。
有的时候,特别是处理大数据量的应用,垃圾回收(GC)将会成为瓶颈。
当我们要处理复杂的事情时,我们首先应该想到的是:
结构化
例如:后端开发中经典的三层架构、数仓分层、七层协议、甚至到一个类、结构体、表的创建。
通过结构化,我们将很多复杂的问题,加以抽象,变成更容易处理的结构。
如果我们把JVM的所有内存都装到一个特别乱的池子里面,
但有大量不断发生改变的内存需要管理时,
你能想象它会乱成什么样吗?
——是的!最终它会把整个内存搞成一摊屎。
分代回收
JVM的内存有明确的划分,和清晰的边界。
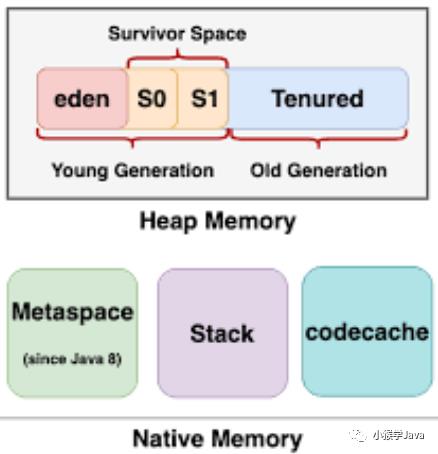
而我们大部分最关注的就是:HeapMemory。
HotSpot依然对HeapMemory进一步结构化,分层了:新生代、老年代。
这种划分,使得分代垃圾回收成为可能。
分代垃圾回收,并不仅仅检查每个存活的对象,它根据大量经验,最大程度地减少垃圾回收的工作。
而这个经验就是:大部分对象只需要存活很短的时间。有图为证:
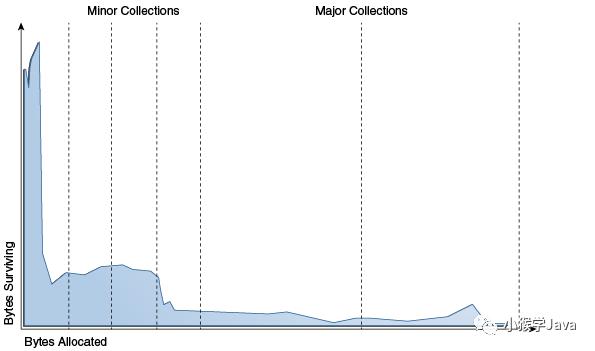
我们可以看到,最左边的峰值分布,就表示了大量的对象存活的时间非常短暂。
垃圾回收不是每时每刻都在回收,而是当某个代满了的时候,启动回收。
而根据上图,大量的对象都出生在新生代,而且很快死在那里。
所以,Minor GC经常发生。
而一些一直在新生代存活的对象,将被移动到老年代。
只有当老年代满了之后,才启动Major GC。Major GC要比Minor GC时间更长,因为它涉及的对象往往很多。
大家感受到了吗?
这就是前面提到的HotSpot的人机工程学——基于行为的优化。
而且,人机工程学还会根据应用程序处理的数据集,自适应地选择垃圾收集器。
当GC成为瓶颈时,我们很有可能需要自定义堆大小、各个代的大小。
虽然大部分时候,它不常见。
JVM堆结构

整个JVM堆结构分为:
-
新生代 -
终生代
新生代包含:
-
伊甸园(Eden 1x) -
幸存区(Survior 2x)——其中有一个Survior总是空的,用于复制存活的对象。而如果足够「老」,就会复制到终生代。
我们来看一下Hadoop YARN NodeManager的JVM堆使用情况吧。执行以下命令:
jmap -heap 2326
Heap Usage:
PS Young Generation
Eden Space:
capacity = 132644864 (126.5MB)
used = 65971984 (62.91578674316406MB)
free = 66672880 (63.58421325683594MB)
49.73579979696764% used
From Space:
capacity = 11010048 (10.5MB)
used = 7724912 (7.3670501708984375MB)
free = 3285136 (3.1329498291015625MB)
70.16238257998512% used
To Space:
capacity = 11010048 (10.5MB)
used = 0 (0.0MB)
free = 11010048 (10.5MB)
0.0% used
PS Old Generation
capacity = 69206016 (66.0MB)
used = 9695800 (9.246635437011719MB)
free = 59510216 (56.75336456298828MB)
14.010053692441998% used
通过jmap可以看到新生代的容量为:126MB,使用了62MB。From为:10MB。老年代为66MB。
应用场景驱动性能
我们定义一个指标——吞吐量。
此处的吞吐量是没有进行GC的时间和总时间的占比。
当HotSpot发生Full GC时,会暂停JVM。也就是,我们常说的——Stop all the world!
而不同的应用场景对GC有不同的性能要求。
例如:当前用Java开发的是一个运行在Tomcat中的Web应用。
针对这种类型的应用,它更关注的是吞吐量。
偶尔发生Full GC可能是可容忍的。
因为,如果耗时不会很长,用户从自身找原因:
-
是不是我网络卡了一下? -
是不是有人在下游戏?
但如果我们用Java开发了一个GUI应用,
用户一定会很不爽。
你要敢多来几次,用户就要卸载了。
所以,我们配置分代的内存要结合应用场景来权衡。
-
把年轻代配置得很大,可以让吞吐量最大化。但这将会在GC时,需要更多的暂停时间。 -
把年轻代配置得小一点,可以减少GC卡顿的时间,但会降低吞吐量。
JVM内存优化,没有银弹!它取决于应用程序。
调整分代内存空间
总体内存配置
JVM调整的最多的就是Heap的几个参数。
当然,能够调参是建立在熟悉JVM Heap结构的基础上。
下面这张图是Oracle官方原版。
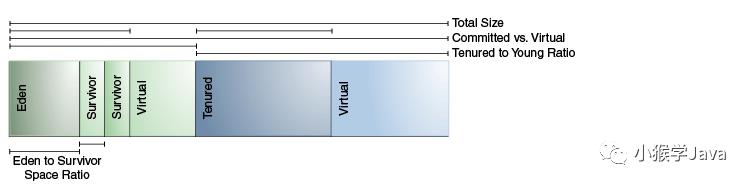
我们经常指定的-Xmx,指定的是保留空间的大小。
HotSpot并不会虚拟机启动时,就把所有的内存分配好。
所以,上图,Oracle把没有使用的空间标记为虚拟。
后面,我拿Hive的 Thrift Server JVM进程来作测试。
为了方便观察,我只保留了最重要的参数配置。
[hive@node1 bin]$ jps
3082 Jps
2860 RunJar
[hive@node1 bin]$ ps aux | grep 2860
hive 2860 14.2 2.5 2006876 260368 pts/0 Sl+ 23:26 0:07 /opt/jdk1.8.0_181/bin/java -Xmx256m hive.aux.jars.path=file:///opt/hive/lib/accumulo-core-1.7.3.jar,....file:///opt/hive/lib/zstd-jni-1.3.2-2.jar
可以看到Hive Thrift Server设置了Xmx为 256MB。
堆的大小和总的可用内存有关。
请记住:HotSpot人机工程学基于行为的优化!堆内存绝不是一直固定不变的!
堆的总大小由以下几个参数决定:
-
-XX:MinHeapFreeRatio = <minimum> 默认为:40 -
堆的可用空间如果低于40%,那么会就开始扩展Heap空间 -
-XX:MaxHeapFreeRatio = <maximum>,默认为:70 -
堆的可用空间如果高于70%,那么会开始收缩Heap空间 -
-Xms:<min>,默认为:6M -
初始分配堆内存空间。 -
-Xmx: <max>,计算得到。 -
最大可用堆空间
使用 jmap -heap 进程ID 查看下Hive Thrift Server的JVM参数配置:
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 268435456 (256.0MB)
运行在服务器上的JVM,通常默认的堆空间是很小的。要将内存空间调大一些。
另外,如果JVM处理器增加,也应增加内存,提高并行处理效率。
新生代内存配置
新生代的内存越大,发生Minor GC发生的次数就越少。
而因为受限于总内存空间,
新生代内存空间越大,老年代的内存空间就越小。
所以,要调整的话,得检查JVM对象的生命周期分布情况。
默认情况下,新生代的大小有参数:NewRatio控制。
例如:设置 -XX:NewRatio=3,表示新生代和老年代的占比为 1:3。
我们再次使用jmap -heap查看Hive Thrift Server的JVM内存配置:
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 268435456 (256.0MB)
# 与Xms对应
NewSize = 53477376 (51.0MB)
# 与Xmx对应
MaxNewSize = 89128960 (85.0MB)
OldSize = 108003328 (103.0MB)
# 新生代与老年代占比 1:2
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Survivor内存配置
上面jmap的输出中,可以看到,SurvivorRatio为8,即与Survivor与Eden的比例为——1:8。就是,它是Eden的1/8。
掐指一算,大约是5MB左右,而Eden,大约在45MB左右。
可以参考下:
-
先确定最大堆大小(Xmx) -
根据应用程序场景,配置新生代Ratio -
如果处理器较多,可以进一步增大新生代的空间,提高并行处理的效率。
凌晨一点的说说
归!
翻了翻自己写的文章,
已经悄然过去3个月。
这3个月,发生了很多事情。
人生总是会有在不少路口,要我们做出艰难决定。
离开帝都那一天,
我彻夜辗转,我不知道我将会面对的是什么。
变!
这3个月,有人告诉我,你应该这样做,你应该那样做。
而我从来没有动摇,
仍然坚持做自己的事。
以前,我总是说,要做好一份工作、一件事情需要有情怀。不能在意眼前的得失。
但大家想想,
我们身边的所有事情都在变,
把所有的时间和精力都放在不断变化的事情,有时候并不是特别明智。
冷!
我早已经习惯了,
但你鼓足了劲,想要拼命往前冲,想要做出些不一样的事情。
但总是有人冷不丁泼你一盆冷水,
对于工作,我一直都是一种自我实现的状态。
不去尝试,终究输的是我们。
因为我们被环境改变,
然后我们感叹无奈。
负!
临近35岁,
天天有人不断在唱衰程序员、唱衰开发。
天天有人不断在抱怨自己的过程背景不好、出身不好。
天天有人不断说教你应该跟他们一样,工作嘛!
但大家有没有真的愿意停下来想想,
现在做的事情,难道就只是打工、赚钱嘛?
不!
我和我的老领导一直都认同一个事情——我们做一件事情,先得感动自己!
我拒绝码农的称号!因为从来没有人告诉我码农的文化。
而其实,世界上只要有圈子的地方就会有文化!
技术世界能够教会我们太多的东西,
我们真的用心去感受了吗?
还是只是把它当做一份谋生的手段?
我!
这就是我,我干嘛要服老?
这就是我,用一年又一年地积累着点点滴滴。
这就是我,我有自己对待技术、工作的态度。
这就是我,十多年了,从未止步。
这就是我,把技术信仰、文化当成自己的精神食粮。
这就是我,就是愿意折腾,喜欢折腾。
这就是我,Be myself!
参考文献:
[1] https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/
[2] https://en.wikipedia.org/wiki/HotSpot_(virtual_machine)
[3] https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%9B%A0%E5%B7%A5%E7%A8%8B%E5%AD%A6
以上是关于不懂这些JVM知识,真不敢说是大数据开发!的主要内容,如果未能解决你的问题,请参考以下文章