真是绝了!这段被JVM动了手脚的代码!
Posted why技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了真是绝了!这段被JVM动了手脚的代码!相关的知识,希望对你有一定的参考价值。
写在前面
你好呀,我是why哥。
我点进去看了一下,发现文章中提到的问题真的很有意思。
于是决定转过来一下,分享给大家。
需要说明的是,在不改变原文章想要表达的东西的前提下,我对文章进行了稍微的调整。
比如排版、措辞和一些行文风格,然后充实了一点内容进来。
我们先看原文。
原文
最近在研究多线程,期间写了这么一段代码
public class MainTest {
public static AtomicInteger num = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Runnable runnable=()->{
for (int i = 0; i < 1000000000; i++) {
num.getAndAdd(1);
}
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
t1.start();
t2.start();
Thread.sleep(1000);
System.out.println("num = " + num);
}
}
开始,我是想用原子类去测试线程安全,毫无疑问 CAS 操作是安全的,但是由于这里计算很耗时所以我就让它休眠 1000ms。
然而奇妙的事情发生了,按照代码来看,主线程休眠 1000ms 后就会输出结果,但是实际情况确实主线程一直等待 t1,t2 执行结束才继续执行。
执行结果是这样的:
出于好奇心,我将休眠的时间调整到了100ms,再运行一下,这次运行就正常了,主线程并不会等待子线程运行结束之后在输出。

于是我猜测肯定有什么机制导致了这样的现象,难道是 CAS?
为了验证我将代码改造了一下(注释第5、11行,加入第6、12行):
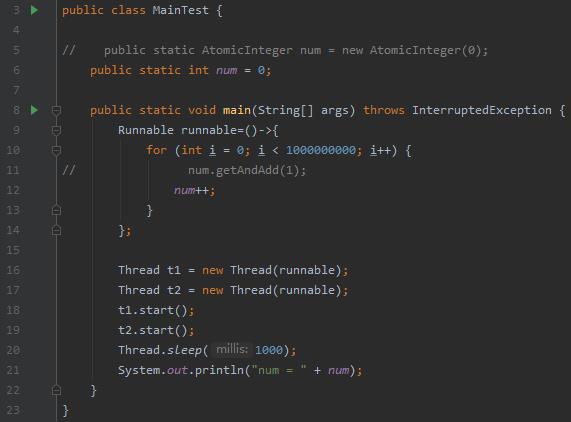
但是当我运行起来的那一刻我就想起来了:这肯定会直接输出的。
果然结果如我所料。
可见并不是cas引起的总线风暴问题。
有的朋友可能就会问了?
啥是总线风暴呀?
总线风暴:volatile 和CAS 的操作导致BUS总线缓存一致性流量激增所造成
那么...
根据原子类的设计,我只能将瞄头进一步对准 volatile 字段了。
于是乎第三版代码产生了,用 volatile 指定可见性,防止指令重排序,让 sum 的修改对所有线程都可见:
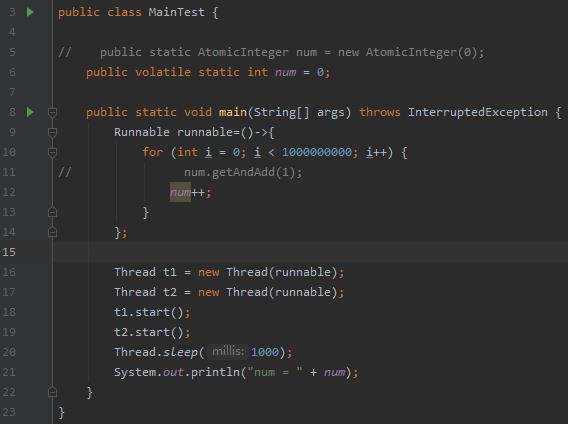
这一次没有失望。果然,通过 volatile 指定对线程的可见性之后, main 方法在 1000ms 以后并没有结束,深度睡眠问题又一次的复现了!
于是我想监控一下运行期间发生了什么,通过 jvisualvm 看一下:
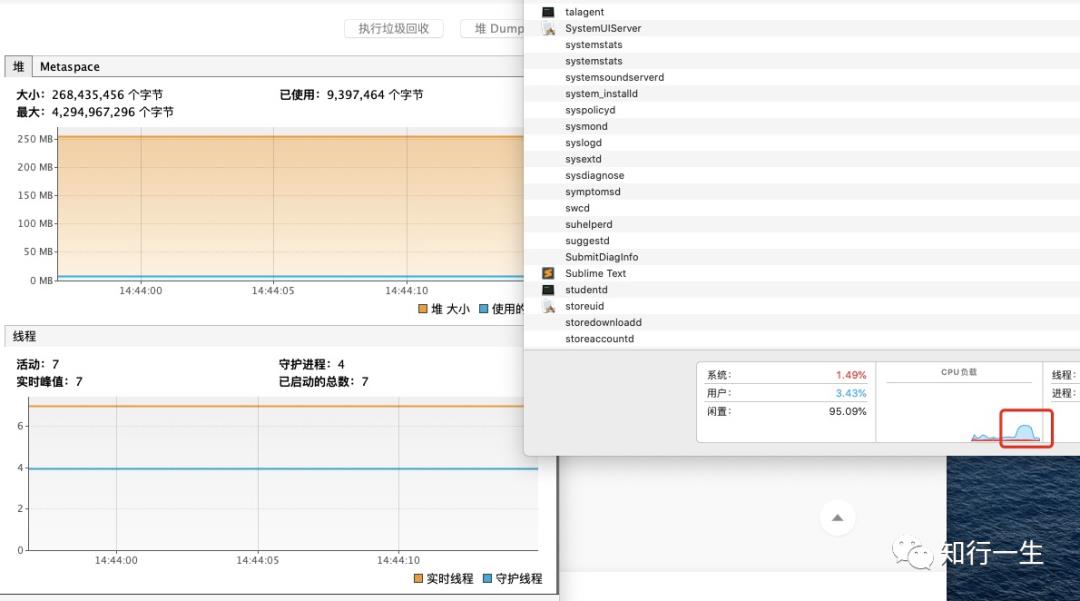
通过监控看到运行期间 CPU 十分繁忙,我电脑是 6 核 12 线程的,CPU 运行期间利用率在 20% 左右。
dump 下来,看了一下,里面有这么一段:
"VM Thread" os_prio=31 tid=0x00007fca6a018000 nid=0x4c03 runnable
"GC task thread#0 (ParallelGC)" os_prio=31 tid=0x00007fca6b009000 nid=0x1e07 runnable
"GC task thread#1 (ParallelGC)" os_prio=31 tid=0x00007fca69009000 nid=0x2203 runnable
"GC task thread#2 (ParallelGC)" os_prio=31 tid=0x00007fca6b009800 nid=0x2003 runnable
"GC task thread#3 (ParallelGC)" os_prio=31 tid=0x00007fca68009000 nid=0x2a03 runnable
"GC task thread#4 (ParallelGC)" os_prio=31 tid=0x00007fca6800d000 nid=0x2b03 runnable
"GC task thread#5 (ParallelGC)" os_prio=31 tid=0x00007fca6800e000 nid=0x2c03 runnable
"GC task thread#6 (ParallelGC)" os_prio=31 tid=0x00007fca6800e800 nid=0x2d03 runnable
"GC task thread#7 (ParallelGC)" os_prio=31 tid=0x00007fca6b00a000 nid=0x2e03 runnable
"GC task thread#8 (ParallelGC)" os_prio=31 tid=0x00007fca6800f000 nid=0x4f03 runnable
"GC task thread#9 (ParallelGC)" os_prio=31 tid=0x00007fca6b00a800 nid=0x4d03 runnable
"VM Periodic Task Thread" os_prio=31 tid=0x00007fca6a019000 nid=0xa703 waiting on condition
这...难道是...触发了 GC ???
怎么感觉越陷越深呢?代码中并没有频繁的创建对象,为何会引起 GC ?
这使我更加疑惑了。
百般无奈之下我只能去 stackoverflow 上提个 question 了:
https://stackoverflow.com/questions/67068057/the-main-thread-exceeds-the-set-sleep-time
在等待回答期间,我继续寻找答案。
期间看了这么一篇文章:
https://zhuanlan.zhihu.com/p/286110609

作者详细的介绍了由于 GC 导致的 STW 使得线程需要等待一段时间。
HotSpot 定位 GC Roots 时通过引入 Safepoint (安全点)来提高垃圾收集效率。
其中提到:
安全点位置的选取基本上是以“是否具有让程序长时间执行的特征”为标准进行选定的。 HotSpot会在所有方法的临返回之前,以及所有非counted loop的循环的回跳之前放置安全点。 “长时间执行”的最明显特征就是指令序列的复用,例如方法调用、循环跳转、异常跳转等都属于指令序列复用,所以只有具有这些功能的指令才会产生安全点。
而为什么把这些位置设置为jvm的安全点呢?
主要目的就是避免程序长时间无法进入 safepoint ,比如 JVM 在做 GC 之前要等所有的应用线程进入到安全点后 VM 线程才能分派 GC 任务。如果有线程一直没有进入到安全点,就会导致 GC 时 JVM 停顿时间延长。
毫无疑问我们程序中的循环是十分耗时的。
文章中还有提到安全区域用来解决线程处于 sleep 状态时无法相应虚拟机的终端请求,不能再走到安全的地方去中断挂起自己的问题。
更多的内容大家自己去看一下。
上面的作者的例子中是由于大量创建对象导致 GC 触发的 main 线程等待子线程到达安全点之后执行的效果。
显然和我的场景不完全一样,因为上面的例子中很显然我们是没有触发 GC 的。
但是隐隐约约之间又有着千丝万缕的联系。

终于在 5 小时候我终于等到了 stackoverflow 的回答。这个回答惊艳到了我,不多bb,马上分享一下解惑大佬的说法:
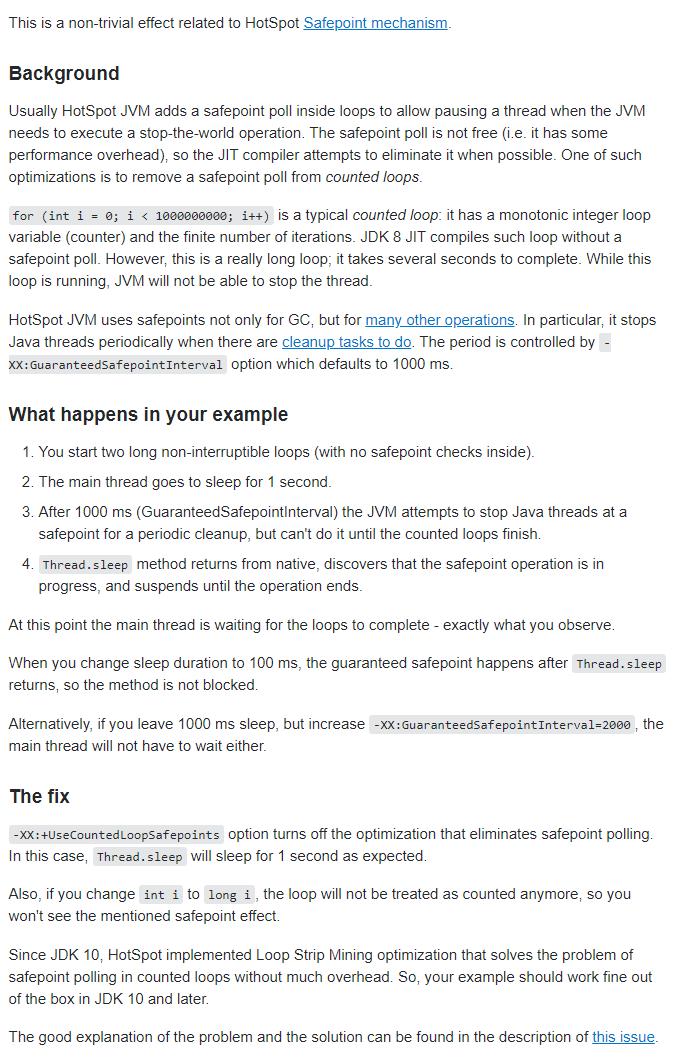
作者的回答从背景,到我写的实例产生的问题,以及具体的解决方案一一道来。
我用大白话给大家简单的翻译一下:
说白了,这是 HotSpot 安全点机制。
先说背景(Background)
通常,HotSpot JVM 会在循环中添加一个safepoint 轮询,以便在 JVM 需要执行 stop the world 操作时暂停线程。
safepoint 轮询不是免费的(也就是说,它有一些性能开销)。
因此 JIT 编译器会在可能的情况下尝试消除它。
其中一个优化是从 counted loops中删除 safepoint 轮询。
那么什么是 counted loops 呢?
你程序里面的 for(int i=0;i<1000000000;i++ 是一个典型的 counted loops:
就是有明确的循环计数器变量,而且该变量有明确的起始值、终止值、步进长度的循环
当我们使用 JDK8 JIT 编译这样的循环时没有 safepoint 轮询。
但是,这是一个非常长的循环,长到需要几秒钟才能完成,所以当这个循环运行时,JVM将无法停止线程。
HotSpot JVM不仅在 GC 的时候使用 safepoints,还有许多其他操作也使用 safepoints。
特别是当有清理任务要做时,它会周期性地停止 Java 线程。
周期由 -XX:GuaranteedSafepointInterval 选项控制,该选项默认为 1000ms。

那么在你的代码示例中发生了什么事情呢(What happens in your example)?
1.你启动了两个长的、不间断的循环(内部没有安全点检查)。 2.主线程进入睡眠状态 1 秒钟。 3.在1000 ms(GuaranteedSafepointInterval)之后,JVM尝试在安全点停止,以便Java线程进行定期清理,但是直到计数循环完成后才能执行此操作。 5.Thread.sleep 方法从 native 返回,发现安全点操作正在进行中,于是把自己挂起,直到操作结束。
所以,从你的角度看起来、你观察到的就是:主线程正在等待循环完成。
如果你想要保留 1000ms 的睡眠代码,那么就增加 JVM 参数 -XX:GuaranteedSafepointInterval=2000,则主线程也不必等待。
接下来我们聊聊修复的事儿。(The fix)
-XX:+UseCountedLoopSafepoints 选项可以关闭安全点轮询的优化。
在这种情况下,程序会按照你的预期去执行。
另外,如果你将 int i 更改为 long i ,循环将不再被视为 counted loop,因此你将不会看到前面说的 safepoint 导致的现象。
自从 JDK10 以来,HotSpot 实现 Loop Strip Mining 优化,解决了在 counted loop 中安全点轮询的问题,而且没有太多开销。
因此,在 JDK10 和更高版本中,你的程序将会按照预期的执行。
对于这个问题和解决办法还有更好的解释,可以在这个问题的描述中找到:
https://bugs.openjdk.java.net/browse/JDK-8223051
至此,疑惑解除,简而言之就是一句话:
当 sleep 1000ms 的时候,jvm 尝试在安全点停止 Java 线程以进行定期清理,此时安全点需要一直等待子线程都执行结束后才能继续执行。
其他案例分享
上面就是原文的全部内容。
但是当why哥看到这篇文章的时候,其实电光火石之间,我想到了《深入理解Java虚拟机(第三版)》里面的一个案例。

而周叔叔的这个案例是借鉴的这个链接:
https://juejin.cn/post/6844903878765314061
你可以直接看这个链接内容。我也把第三版 5.2.8 小节搬过来,给大家看看。看完之后,你就知道了,其实他们说的是一回事,案例如下:
有一个比较大的承担公共计算任务的离线 HBase 集群,运行在 JDK 8 上,使用 G1 收集器。
每天都有大量的 MapReduce 或 Spark 离线分析任务对其进行访问,同时有很多其他在线集群 Replication 过来的数据写入。
因为集群读写压力较大,而离线分析任务对延迟又不会特别敏感,所以将 -XX:MaxGCPauseMillis(最大暂停时间)参数设置到了 500ms。
不过运行一段时间后发现垃圾收集的停顿经常达到 3 秒以上,而且实际垃圾收集器进行回收的动作就只占其中的几百毫秒。

日志显示这次垃圾收集一共花费了 0.14 秒,但其中用户线程却足足停顿了有 2.26 秒,两者差距已经远远超出了正常的 TTSP(Time To Safepoint)耗时的范畴。
分析:先加入参数 -XX:+PrintSafepointStatistics 和 -XX:PrintSafepointStatisticsCount=1 去查看安全点日志,具体如下所示:
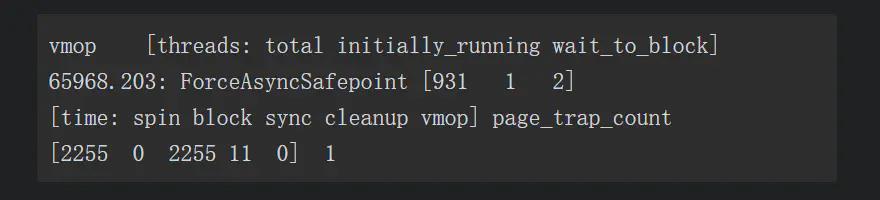
日志显示当前虚拟机的操作(VM Operation,VMOP)是等待所有用户线程进入到安全点,但是有两个线程特别慢,导致发生了很长时间的自旋等待。
日志中的 2255 毫秒自旋(Spin)时间就是指由于部分线程已经走到了安全点,但还有一些特别慢的线程并没有到,所以垃圾收集线程无法开始工作,只能空转(自旋)等待。
怎么解决这个问题呢?
第一步是把这两个特别慢的线程给找出来,添加 -XX:+SafepointTimeout 和 -XX:SafepointTimeoutDelay=2000 两个参数,让虚拟机在等到线程进入安全点的时间超过 2000 毫秒时就认定为超时,这样就会输出导致问题的线程名称,得到的日志如下所示:
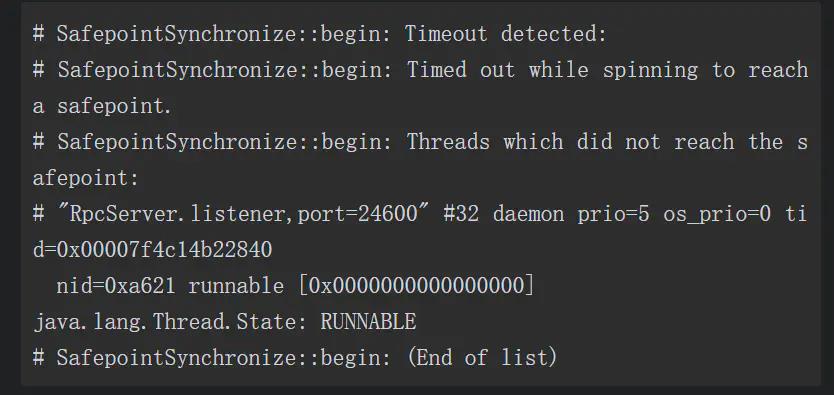
从错误日志中顺利得到了导致问题的线程名称为“RpcServer.listener,port=24600”。
我们已经知道安全点是以“是否具有让程序长时间执行的特征”为原则进行选定的。
所以方法调用、循环跳转、异常跳转这些位置都可能会设置有安全点,但是HotSpot虚拟机为了避免安全点过多带来过重的负担,对循环还有一项优化措施,认为循环次数较少的话,执行时间应该也不会太长,所以使用int类型或范围更小的数据类型作为索引值的循环默认是不会被放置安全点的。
这种循环被称为可数循环(Counted Loop)。
相对应地,使用 long 或者范围更大的数据类型作为索引值的循环就被称为不可数循环(Uncounted Loop),将会被放置安全点。
通常情况下这个优化措施是可行的,但循环执行的时间不单单是由其次数决定,如果循环体单次执行就特别慢,那即使是可数循环也可能会耗费很多的时间。
HotSpot原本提供了-XX:+UseCountedLoopSafepoints 参数去强制在可数循环中也放置安全点,不过这个参数在 JDK 8 下有 Bug,有导致虚拟机崩溃的风险,所以就不得不找到 RpcServer 线程里面的缓慢代码来进行修改。
最终查明导致这个问题是 HBase 中一个连接超时清理的函数,由于集群会有多个 MapReduce 或 Spark 任务进行访问,而每个任务又会同时起多个 Mapper/Reducer/Executer,其每一个都会作为一个 HBase 的客户端,这就导致了同时连接的数量会非常多。
更为关键的是,清理连接的索引值就是 int 类型,所以这是一个可数循环,HotSpot不会在循环中插入安全点。
当垃圾收集发生时,如果 RpcServer 的 Listener 线程刚好执行到该函数里的可数循环时,则必须等待循环全部跑完才能进入安全点,此时其他线程也必须一起等着,所以从现象上看就是长时间的停顿。
找到了问题,解决起来就非常简单了,把循环索引的数据类型从 int 改为 long 即可。
但如果不具备安全点和垃圾收集的知识,这种问题是很难处理的。
why哥说
怎么样,看完之后是不是感觉有点意思啊?
至少对于安全点、安全区域这些概念有了稍微深入的理解吧?
然后我问你几个问题:
原作者的原文里面的代码是截图,我专门打出来给你文本。那么你有没有粘出来跑一下?
我跑了。
有没有按照文章对应的改一下代码?
我改了。
有没有把前面说的 JVM 参数都设置进去,对比一下设置前后的差异?
我设置了。
文章中提到的几个链接,你有没有想着找个时间打开看看?
我都看了。
stackoverflow 上那个回答问题的哥们说“在 JDK10 和更高版本中没有这个问题了”,你验证了没?
我用 JDK 15 验证了。

......

哦,对了,你知道为什么我一看到原文的案例的时候就想起了第三版书里面的案例吗?

左边是第二版,右边是第三版。
因为这个案例是新加的,于是我当时特别看了一下,又找到原文去瞅了一眼,于是印象有点深刻。
你看,就是这种这么冷门的东西,看起来学了没卵用的东西,有的时候就是能出奇效。
比如,此时此刻的用途,其实就是我拿来装一下逼而已。
所以,人,没事还是得多读书。书上看到的东西,装逼的时候用一下,能起到点睛之笔的作用。
好了,就这样,收工。
以上是关于真是绝了!这段被JVM动了手脚的代码!的主要内容,如果未能解决你的问题,请参考以下文章