论文泛读65面向开放域问题回答的神经猎犬的端到端培训
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读65面向开放域问题回答的神经猎犬的端到端培训相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《End-to-End Training of Neural Retrievers for Open-Domain Question Answering》
一、摘要
关于训练用于开放域问答(OpenQA)的神经检索器的最新工作采用了有监督和无监督的方法。但是,目前尚不清楚如何将无监督和有监督的方法最有效地用于神经检索器。在这项工作中,我们系统地研究了猎犬的预训练。我们首先提出一种使用反克洛什任务和掩盖显着跨度的无监督预训练方法,然后使用问题-问题对进行有监督的微调。与自然问题和TriviaQA数据集的前20名检索准确性相比,这种方法的绝对收益比以前的最佳结果高2个点。
我们还探索了两种在OpenQA模型中对阅读器和检索器组件进行端到端监督训练的方法。在第一种方法中,读者分别考虑每个检索到的文档,而在第二种方法中,读者将所有检索到的文档一起考虑。我们的实验证明了这些方法的有效性,因为我们获得了最新的结果。在“自然问题”数据集上,我们获得了前20名的检索精度为84,比最近的DPR模型提高了5点。此外,我们在答案提取上取得了良好的结果,比REALM和RAG等最新模型高出3分以上。我们进一步扩大了对大型模型的端到端培训,并显示了与较小模型相比性能的持续提高。
二、结论
在这项工作中,我们提出了一些方法来提高开放领域问答任务的双编码器检索器模型的准确性。我们证明了使用反向完形填空任务对检索器进行无监督的预训练,然后使用问题-上下文对进行有监督的训练,有助于提高检索精度。我们的实证分析进一步表明,在训练数据集规模相对较小的情况下,使用隐藏显著跨度的预训练方法比信通技术更有效。我们还提出了两种使用问答对对OpenQA系统进行端到端监督训练的方法。第一种方法是让读者分别考虑每一个检索到的文档,这种方法在提高检索准确性方面表现出色。第二种方法是读者将所有检索到的文档放在一起考虑,这种方法在答案抽取方面表现出色。通过端到端训练,我们超越了以前的最佳模型,并在基准数据集上的检索精度和答案提取方面取得了新的最先进的结果。
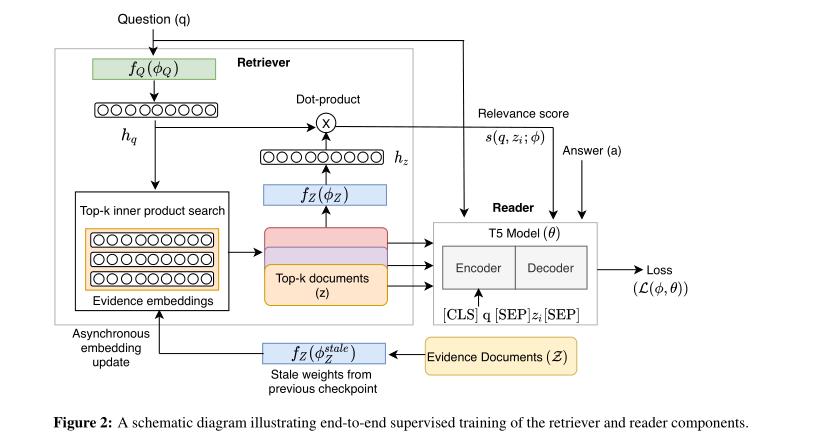
三、model
检索器和读取器组件:
以上是关于论文泛读65面向开放域问题回答的神经猎犬的端到端培训的主要内容,如果未能解决你的问题,请参考以下文章