论文泛读100利用多模式信息有助于中文拼写检查
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读100利用多模式信息有助于中文拼写检查相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking》
一、摘要
中文拼写检查(CSC)旨在检测和纠正用户生成的中文文本的错误字符。大多数中文拼写错误在语义,语音或图形上均被误用。先前的尝试注意到了这种现象,并尝试将相似性用于此任务。但是,这些方法使用启发式方法或手工制作的混淆集来预测正确的字符。在本文中,我们直接利用汉字的多模式信息,提出了一种中文拼写检查器,称为ReaLiSe。实现模型通过(1)捕获输入字符的语义,语音和图形信息,以及(2)有选择地混合这些模式中的信息以预测正确的输出来解决CSC任务。
二、结论
在本文中,我们提出了一个名为REALISE的中文拼写检查模型。由于汉语中的拼写错误通常在语义、语音或图形上与正确的字符相似,REALISE利用文本、听觉和视觉形式的信息来检测和纠正错误。REALISE模型使用定制的语义、语音和图形编码器捕获这些形式的信息。此外,还提出了一种选择性模态融合机制来控制这些模态的信息流。SIGHAN基准测试表明,所提出的REALISE比仅使用文本信息的基准模型有大幅度的提高,这验证了利用听觉和视觉信息有助于中文拼写检查任务。
三、模型结构
不仅需要上下文文本信息,还需要字符本身的语音和图形信息。
首先使用多个编码器从文本、声音和视觉形式中获取有价值的信息。然后,我们开发了一个选择性模态融合模块来获得上下文感知的多模态表示。最后,输出层预测错误纠正的概率。
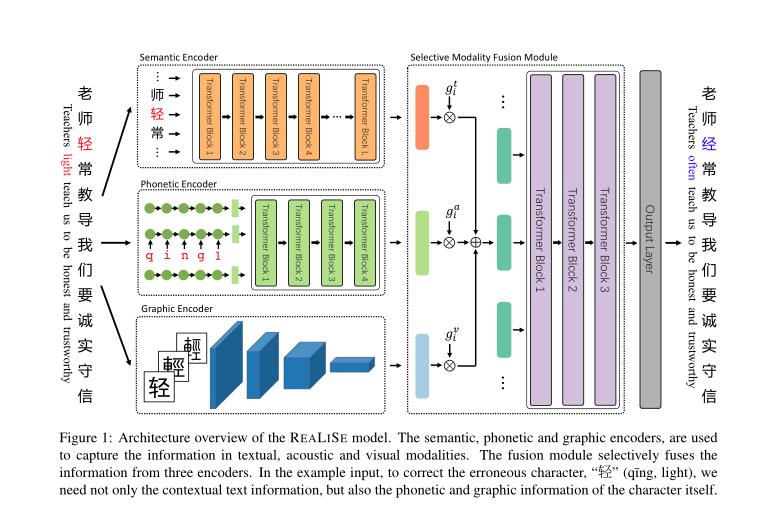
- 语义编码器
- 语音编码器
- 图形编码器
具体的实验结果:
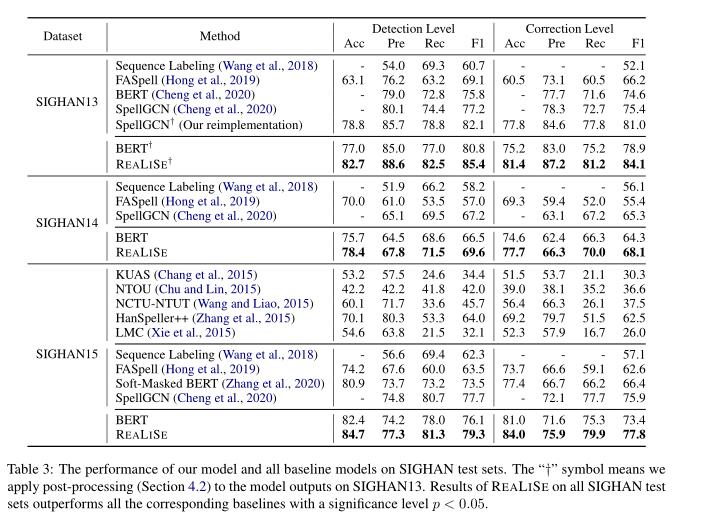
分为检测和纠错两个level,在检测级别,当且仅当句子中的所有拼写错误都被成功检测到时,句子才被认为是正确的。在纠正级别,模型不仅要检测到错误字符,还要将所有错误字符纠正到正确的字符。
以上是关于论文泛读100利用多模式信息有助于中文拼写检查的主要内容,如果未能解决你的问题,请参考以下文章