HiveSql&SparkSql —— 自定义UDFUDAFUDTF函数实战总结
Posted 扫地增
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HiveSql&SparkSql —— 自定义UDFUDAFUDTF函数实战总结相关的知识,希望对你有一定的参考价值。
文章目录
简介:
做数仓的小伙伴应该深有体会,我们在做复杂业务时经常遇到一些比较复杂的逻辑或者复杂的数据结构,它们无法使用
hive或者spark天然提供的函数进行解析,在这个时候我们就会想到如果可以自定义一个像hive、spark自身提供的函数对数据对处理那就方便多了,为此hive和spark使用UDF、UDAF、UDTF几种接口,供我们自定义函数解决此类问题,下面笔者以自身实践为基础对UDF、UDAF、UDTF函数进行简单的介绍。
使用场景
我们先来看下它们各自的定义:
UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等UDAF(User- Defined Aggregation Funcation),用户自定义聚合函数,类似在group by之后使用的sum,avg等UDTF(User-Defined Table-Generating Functions),用户自定义生成函数,有点像stream里面的flatMap
其实虽然我们将这三种函数放到一起,但是在Hive和Spark中对他们的支持是不一样的, Hive中是全部支持是这三种函数,但是Spark中其实是仅支持UDF和UDAF,而UDTF在spark中其实是完全使用了Hive的UDTF函数。那么我们来回顾下Hive中自定义函数的三种类型:
- 第一种:
UDF(User-Defined-Function)函数
一对一的关系,输入一个值经过函数以后输出一个值;
在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;- 第二种:
UDAF(User-Defined Aggregation Function)聚合函数
多对一的关系,输入多个值输出一个值,通常与groupBy联合使用;- 第三种:
UDTF(User-Defined Table-Generating Functions)函数
一对多的关系,输入一个值输出多个值(一行变为多行);
用户自定义生成函数,有点像flatMap;
既然说到两个框架对三个自定义函数的支持,那么我们就来简单了解spark几个版本对函数的支持变化:
| Spark版本 | Spark SQL UDF(Python,Java,Scala) | Spark SQL UDAF(Java、Scala) | Spark SQL UDF(R) | Hive UDF、UDAF、UDTF |
|---|---|---|---|---|
| 1.1 - 1.4 | ✔️ | ✔️ | ||
| 1.5 | ✔️ | experimental | ✔️ | |
| 1.6 | ✔️ | ✔️ | ✔️ | |
| 2.0 | ✔️ | ✔️ | ✔️ | ✔️ |
在SparkSQL中,目前仅仅支持UDF函数和UDAF函数:
UDF函数:一对一关系;UDAF函数:聚合函数,通常与group by 分组函数连用,多对一关系;由于SparkSQL数据分析有两种方式:DSL编程和SQL编程,所以定义UDF函数也有两种方式,不同方式可以在不同分析中使用。
UDF
spark UDF
源码:
我们从源码知道spark提供了23个UDF相关的接口。如下图所示:
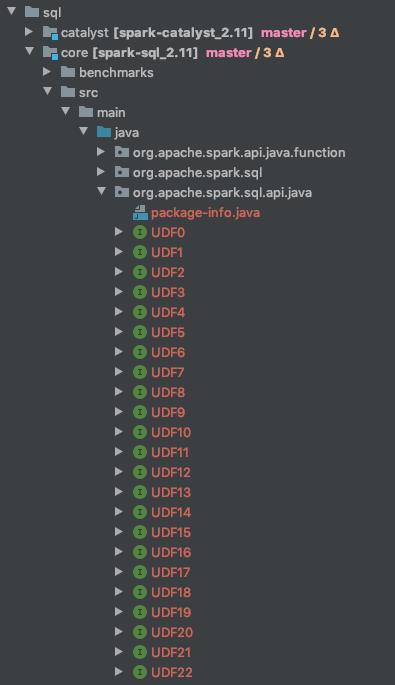
其实它们之间区别就与接口中定义参数的多少,这些udf能支持的传入的参数的个数从
[0,22]分别对应每个UDF函数。
为了方便大家了解,我们从源码中引入部分代码:
UDF0函数源码:
/**
* A Spark SQL UDF that has 0 arguments.
*/
@InterfaceStability.Stable
public interface UDF0<R> extends Serializable {
R call() throws Exception;
}
UDF1函数源码:
/**
* A Spark SQL UDF that has 1 arguments.
*/
@InterfaceStability.Stable
public interface UDF1<T1, R> extends Serializable {
R call(T1 t1) throws Exception;
}
UDF2函数源码:
/**
* A Spark SQL UDF that has 2 arguments.
*/
@InterfaceStability.Stable
public interface UDF2<T1, T2, R> extends Serializable {
R call(T1 t1, T2 t2) throws Exception;
}
UDF22函数源码:
/**
* A Spark SQL UDF that has 22 arguments.
*/
@InterfaceStability.Stable
public interface UDF22<T1, T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13, T14, T15, T16, T17, T18, T19, T20, T21, T22, R> extends Serializable {
R call(T1 t1, T2 t2, T3 t3, T4 t4, T5 t5, T6 t6, T7 t7, T8 t8, T9 t9, T10 t10, T11 t11, T12 t12, T13 t13, T14 t14, T15 t15, T16 t16, T17 t17, T18 t18, T19 t19, T20 t20, T21 t21, T22 t22) throws Exception;
}
由源码我们可以看到我们在使用时需要明确好两点来选择不同UDF:
1、需要传入参数的个数。
2、需要返回值类型。
语法:
使用SparkSession中udf方法定义和注册函数,在SQL中使用,使用如下方式定义:
sparkSession.udf.register(
"udfName", //自定义函数的名称
(UDF1<Long, Double>) (parameter) -> parameter*0.2, // 匿名函数
DataTypes.DoubleType //返回值的类型
);
其中
register()该注册函数的参数解释如下:
- 第一个参数
udfName就是你的udf的名字。- 第二个参数中的
parameter就是传入的UDF的参数。- 第三个参数就是处理完的返回的数据类型。
注:特别说明的
UDF1<Long,Double>中的Long表示传入的参数的数据类型,Double表示返回的参数的数据类型,这个必须与上面提到的注册函数的第三个参数保持一致。
实现方法:
自定义
udf的方式有两种:
SQLContext.udf.register(),SQL方式。- 创建
UserDefinedFunction,DSL方式。
案例
将小写数据转换为大写:
//TODO:通过sparkSession进行UDF的注册,将我们的小写转换成大写
//1.SQL方式:
sparkSession.udf.register("smallToBigger", new UDF1[String,String]() {
@throws[Exception]
override def call(t1: String): String = {
t1.toUpperCase()
}
}, DataTypes.StringType)
//2.DSL方式:
val smallToBigger: UserDefinedFunction = udf((str: String) => t1.toUpperCase())
//使用UDF函数
sparkSession.sql("select line, smallToBigger(line) as biggerLine from small_table").show()
Hive UDF
实现步骤
1.继承
org.apache.hadoop.hive.ql.exec.UDF
2.实现evaluate方法 注意:该方法必须有返回值,可以为null。
3.将jar包上传到hdfs /xx/xx/udf/hive-udf.jar将jar包重命名为hive-udf.jar
4.在集群的客户端,打开hive shell执行命令:
CREATE [TEMPORARY] FUNCTION json_array_string AS
'org.myfunctions.udf.JsonArrayUDF'
USING JAR 'hdfs:///xx/xx/udf/hive-udf.jar';
案例:
这里仅提供代码,详细步骤参照上面即可。
package com.aiyunxiao.bigdata.udf;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.slf4j.Logger;
public class JsonArrayUDF extends UDF {
private Logger LOG = org.slf4j.LoggerFactory.getLogger(JsonArrayUDF.class);
/**
* 1. Implement one or more methods named "evaluate" which will be called by Hive.
*
* 2. "evaluate" should never be a void method. However it can return "null" if needed.
*/
// CREATE FUNCTION udf_name as 'org.myfunctions...' USING JAR 'hdfs:///xx/xx/udf/hive-udf.jar';
public String evaluate(String str){
try {
JSONArray jsonArray = JSON.parseArray(str);
StringBuilder sb = new StringBuilder();
for (Object o : jsonArray) {
sb.append(JSON.toJSONString(o)).append("||");
}
return sb.substring(0,sb.length()-2);
}catch (Exception e){
//LOG.error(e.getMessage());
return null;
}
}
}
UDAF
UDAF简介
UDAF(User Defined Aggregate Function),即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出,聚合函数是接受一组(一般是多行)输入然后产生一个输出,即将一组的值想办法聚合一下。- 关于
UDAF的一个误区
我们可能下意识的认为UDAF是需要和group by一起使用的,实际上UDAF可以跟group by一起使用,也可以不跟group by一起使用,这个其实比较好理解,联想到mysql中的max、min等函数,可以:
select min(a) from table group by b;
表示根据b字段分组,然后求每个分组的最小值,这时候的分组有很多个,使用这个函数对每个分组进行处理,也可以:
select min(a) from table;
这种情况可以将整张表看做是一个分组,然后在这个分组(实际上就是一整张表)中求最小值。所以
聚合函数实际上是对分组做处理,而不关心分组中记录的具体数量。
Spark UDAF(User Defined Aggregate Function)
Spark UDAF 实现方法:
Spark实现UDAF有两个办法,如下:
1.继承UserDefinedAggregateFunction
2.继承Aggregator。
Spark UDAF 实现步骤:
使用继承
UserDefinedAggregateFunction实现UDAF的步骤:
- 自定义类继承
UserDefinedAggregateFunction,对每个阶段方法做实现- 在
spark中注册UDAF,为其绑定一个名字- 然后就可以在
sql语句中使用上面绑定的名字调用
案例:
我们写一个计算学生平均分值的UDAF例子方便大家理解
继承UserDefinedAggregateFunction:
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
/** *
*
* @author Saodiseng
* @date 2021/5/22 6:25 下午 周六
* @jdk jdk1.8.0
* @version 1.0
* **/
object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction {
// 聚合函数的输入数据结构
override def inputSchema: StructType = StructType(StructField("input", DoubleType) :: Nil)
// 缓存区数据结构
override def bufferSchema: StructType = StructType(StructField("sum", DoubleType) :: StructField("count", LongType) :: Nil)
// 聚合函数返回值数据结构
override def dataType: DataType = DoubleType
// 聚合函数是否是幂等的,即相同输入是否总是能得到相同输出
override def deterministic: Boolean = true
// 初始化缓冲区
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0.0
buffer(1) = 0L
}
// 给聚合函数传入一条新数据进行处理
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (input.isNullAt(0)) return
buffer(0) = buffer.getDouble(0) + input.getDouble(0)
buffer(1) = buffer.getLong(1) + 1
}
// 合并聚合函数缓冲区
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getDouble(0) + buffer2.getDouble(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 计算最终结果
override def evaluate(buffer: Row): Any = buffer.getDouble(0) / buffer.getLong(1)
}
然后注册并使用它:
import org.apache.spark.sql.SparkSession
object SparkSqlUDAFDemo_001 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("StudentScoreAvg").getOrCreate()
spark.read.json("metastore_db/tmp/score").createOrReplaceTempView("student_score")
spark.udf.register("s_avg", AverageUserDefinedAggregateFunction)
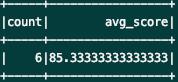
// 将整张表看做是一个分组对求所有人的平均年龄
spark.sql("select count(1) as count, s_avg(age) as avg_score from student_score").show()
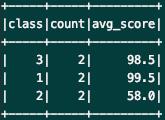
// 按照性别分组求平均
spark.sql("select class, count(1) as count, s_avg(score) as avg_score from student_score group by class").show()
spark.close()
}
}
使用到的数据集:
{"student_id": 1001, "student_name": "xiaoming", "class": "2", "sex": "woman", "score": 56.5}
{"student_id": 1002, "student_name": "xiaoqiang", "class": "2", "sex": "woman", "score": 59.5}
{"student_id": 1003, "student_name": "qunqun", "class": "1", "sex": "man", "score": 100}
{"student_id": 1004, "student_name": "lulu", "class": "1", "sex": "man", "score": 99}
{"student_id": 1005, "student_name": "xiaolong", "class": "3", "sex": "man", "score": 99}
{"student_id": 1006, "student_name": "luting", "class": "3", "sex": "man", "score": 98}
运营结果:
继承Aggregator
还有另一种方式就是继承Aggregator这个类,优点是可以带类型:
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders}
/**
* 计算平均值
*/
object AverageAggregator extends Aggregator[User, Average, Double] {
// 初始化buffer
override def zero: Average = Average(0.0, 0L)
// 处理一条新的记录
override def reduce(b: Average, a: User): Average = {
b.sum += a.score
b.count += 1L
b
}
// 合并聚合buffer
override def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// 减少中间数据传输
override def finish(reduction: Average): Double = reduction.sum / reduction.count
override def bufferEncoder: Encoder[Average] = Encoders.product
// 最终输出结果的类型
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
/**
* 计算平均值过程中使用的Buffer
*
* @param sum
* @param count
*/
case class Average(var sum: Double, var count: Long) {
}
case class User(student_id: Long, student_name: String, sex: String, score: Double) {
}
调用:
import org.apache.spark.sql.SparkSession
object AverageAggregatorDemo_001 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("StudentScoreAvg").getOrCreate()
import spark.implicits._
val user = spark.read.json("metastore_db/tmp/score").as[User]
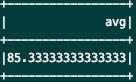
user.select(AverageAggregator.toColumn.name("avg")).show()
}
}
运行结果:
Hive UDAF(User Defined Aggregate Function)
Hive UDAF 实现步骤:
Hive UDAF实现方式一:
UDAF其实已经过时,但这里我们也进行简单介绍:
想要实现自定义UDAF需要使用以下两类:
import org.apache.hadoop.hive.ql.exec.UDAFimport org.apache.hadoop.hive.ql.exec.UDAFEvaluator步骤:
- 1、函数类需要继承
UDAF类,计算类Evaluator实现UDAFEvaluator接口- 2、
Evaluator需要实现UDAFEvaluator的init、iterate、terminatePartial、merge、terminate这几个函数。
a)init函数实现接口UDAFEvaluator的init函数。
b)iterate接收传入的参数,并进行内部的迭代。其返回类型为boolean。
c)terminatePartial无参数,其为iterate函数遍历结束后,返回遍历得到的数据,terminatePartial类似于hadoop的Combiner。
d)merge接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean。
e)terminate返回最终的聚集函数结果。
Hive UDAF 方式一示例:
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
/***
* @author Saodiseng
* @date 2021/5/24 11:00 上午 周一
* @jdk jdk1.8.0
* @version 1.0
***/
public class Avg extends UDAF {
/**
* 定义静态内部类AvgState
*/
public static class AvgState {
private long mCount;
private double mSum;
}
public static class AvgEvaluator implements UDAFEvaluator {
//初始化AvgState对象
AvgState state;
//创建AvgEvaluator无参构造函数
public AvgEvaluator(){
super();
state = new AvgState();
init();
}
/**
* init函数类似于构造函数,用于UDAF的初始化
*/
@Override
public void init() {
//设置mCount初始值
state.mCount = 0;
//设置mSum初始值
state.mSum = 0;
}
/**
* iterate接收传入的参数,并进行内部的轮转。其返回类型为boolean
* @param o
* @return
*/
public boolean iterate(Double o) {
if (o != null) {
state.mSum += o;
state.mCount++;
}
return true;
}
/**
* terminatePartial无参数,其为iterate函数遍历结束后,返回轮转数据,
* terminatePartial类似于hadoop的Combiner
* @return
*/
public AvgState terminatePartial() {
// combiner
return state.mCount == 0 ? null : state;
}
/**
* merge接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean
* @param
* @return
*/
public boolean merge(AvgState avgState) {
if (avgState != null) {
stat以上是关于HiveSql&SparkSql —— 自定义UDFUDAFUDTF函数实战总结的主要内容,如果未能解决你的问题,请参考以下文章