Python+selenium 模拟网页点击爬虫车辆定位系统
Posted 微信公众号:您好啊数模君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python+selenium 模拟网页点击爬虫车辆定位系统相关的知识,希望对你有一定的参考价值。
在上一篇文章《Python教程—模拟网页点击》讲解了简单的登录过程,本次讲一下完整的selenium爬虫,依然针对车辆定位系统这类网址,这类网址有个特点就是需要点击触发才能获取动态数据,反应时间看网速,也容易漏掉部分数据,并且访问元素在列表中,不能直接使用Copy Xpath的路径,需要先访问列表块,再去访问其中的元素,甚至还有要先访问列表图块才能对其中的元素进行访问。
一般网页版客户端不好用还不得不用,本文分享的内容希望能帮助同行解放双手,一个是无浏览器页面,一个是有浏览器页面,可以看下具体效果。
主要的库有selenium和time,其中keys主要使用其中的回车功能
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time将数据保存至csv中,csv比xlsx读写数据速率更快,并且以当前时间作为文件名,需要用到额外的库有
import csv
import datetime设置time.sleep()等待点击或读取数据,数据窗口弹出快慢不定,那么我们可以将
time.sleep(1) #加载等待
driver.find_element_by_xpath("").click()#点击
time.sleep(1) #加载等待
driver.find_element_by_xpath("").text#读取文本替换为智能等待语句
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,""))).click()#点击
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,""))).text#读取文本在这之前需要调用功能
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait然而WebDriverWait有个缺陷,一些特定的按钮的路径加载出来了,但点击链接还未加载完,因此,在点击特定的按钮时可以结合
time.sleep()、find_element_by_xpath("").click()点击并读取文本,例如
time.sleep(0.5) #加载等待
driver.find_element_by_xpath("").click() #点击窗口退出按钮
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,""))).click()
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,""))).text以下为主要步骤:
创建网页窗口,这里采用的是google浏览器
opt = webdriver.ChromeOptions() #创建浏览
#opt.set_headless() #无窗口模式
#driver.maximize_window() #最大化窗口
driver = webdriver.Chrome(options=opt) #创建浏览器对象
print("正在打开网页")
driver.get('http://') #打开网页一般的打开网页的审查元素,用小箭头点击目标区域查看对应代码块,右键Copy Xpath复制路径,这里无列表块可以直接使用Copy Xpath的路径访问
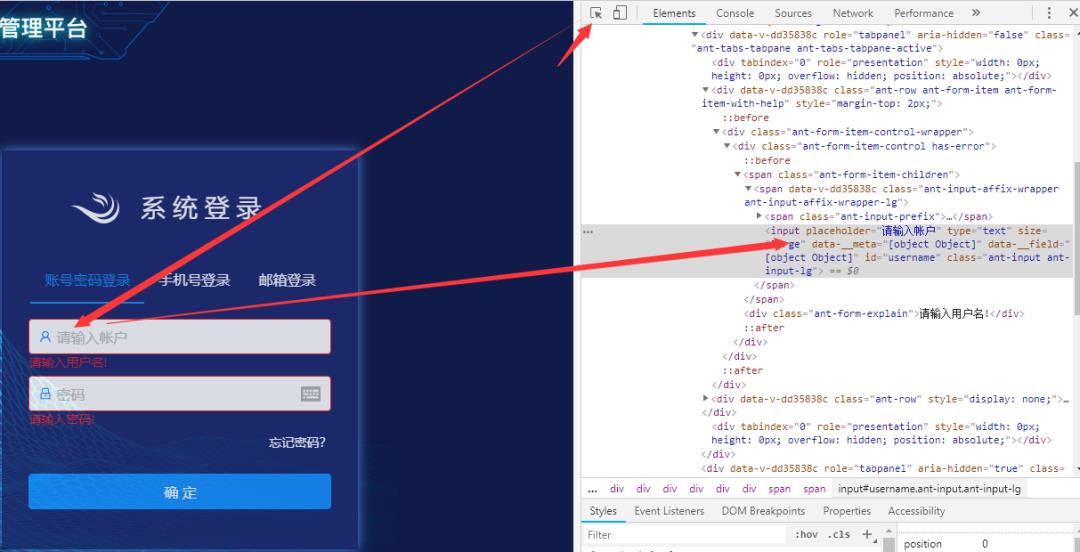
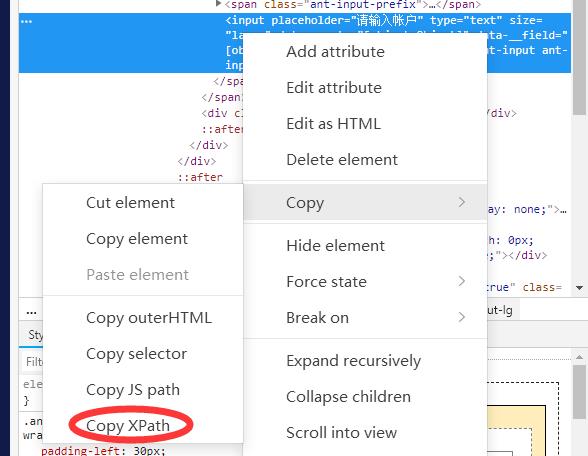
可以通过find_element_by_xpath根据相应xpath路径找到填写区域,使用send_keys进行填写
time.sleep(1) #加载等待
print("正在填写账号")
# 填入账号
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/form/div[2]/div[3]/div[1]/div[2]/div/div/span/span/input")
# 清空原有内容
elem.clear()
# 填入账号
elem.send_keys("")点击登录按钮,同样的Copy Xpath路径
time.sleep(1) #加载等待
print("正在登录")
# 登录按钮并单击
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/form/div[5]/div/div/span/button").click()部分网页客户端登陆后网页数据需要一定时间加载,可以设置久一点等待时间
网页中的列表类似于,其中红框是需要点击的区域
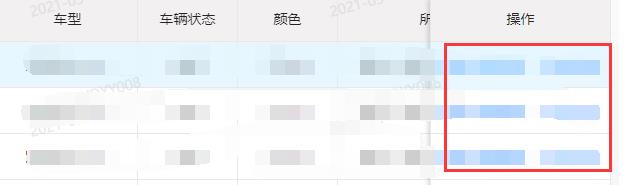
下方有页码块,页码块也可以直接通过Copy Xpath路径访问
对于访问列表元素的路径,给一个公式
//div[@class='']/.....怎么完善代码,在Elements中找到列表图块和需要点击的元素位置并分别Copy Xpath
/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/div/div/div[2]/div[2]/div
/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/div/div/div[2]/div[2]/div/table/tbody/tr[1]/td/span/a[1]
这里注意列表图块需要选择带有px的代码行

这个列表名称为ant-table-body-inner,然后看元素与列表图块多出了一些路径
/table/tbody/tr[1]/td/span/a[1]
因此我们可以完善元素位置路径
//div[@class='ant-table-body-inner']/table/tbody/tr[1]/td/span/a[1]列表中还需要依次访问其他元素,这里可以改成加循环的格式,其中i指的是第i个元素
//div[@class='ant-table-body-inner']/table/tbody/tr["+str(i)+"]/td/span/a[1]点击元素完整命令行,使用click点击
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body-inner']/table/tbody/tr["+str(i)+"]/td/span/a[1]"))).click()#点击列表中的元素点击后会弹出新的窗口,同样的,先定位新窗图块,在定位其中数据的位置,然后通过text直接读出文本,例如
result=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body']/table/tbody/tr["+str(i)+"]/td[3]"))).text对于列表图块来说,其中的元素个数不会变动,但对于页码图块,其中元素的个数会发生改变,主要在开始几页和结尾几页
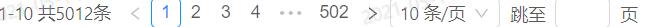


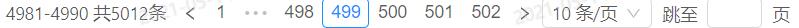

简单粗暴的方式就是设置几个if条件语句,下面采用的是填页码翻页的形式,当然也是为了避免中途网络延迟导致未加载报错,方便重新运行程序接着上次页码继续执行
kk=1 #从第几页开始
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[11]/div[2]/input")
elem.clear()
elem.send_keys(str(kk-1))
elem.send_keys(Keys.ENTER)
R=[]
for K in range(kk,503):#采用输入页码形式翻页
time.sleep(0.5)
if K<5:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[11]/div[2]/input")
if K==5:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[12]/div[2]/input")
if K>5 and K<500:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[13]/div[2]/input")
if K==500:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[12]/div[2]/input")
if K>500:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[11]/div[2]/input")
elem.clear()
elem.send_keys(str(K))
elem.send_keys(Keys.ENTER)
time.sleep(0.5)上面是笨办法,其实可以直接定位向右图标位置并点击
driver.find_element_by_link_text("图标: right").click()#点击如果是有"下一页"字符,就改成
driver.find_element_by_link_text("下一页").click()#点击其他的细节代码,比如文本处理、条件,就根据自己想要的结果去完善
完整代码(已删掉账号密码网址)
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import csv
import datetime
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
opt = webdriver.ChromeOptions() #创建浏览
opt.set_headless() #无窗口模式
#driver.maximize_window() #最大化窗口
driver = webdriver.Chrome(options=opt) #创建浏览器对象
print("正在打开网页")
driver.get('') #打开网页
time.sleep(1) #加载等待
print("正在填写账号")
# 查找账号填写位置
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/form/div[2]/div[3]/div[1]/div[2]/div/div/span/span/input")
# 清空原有内容
elem.clear()
# 填入账号
elem.send_keys("")
time.sleep(1) #加载等待
print("正在填写密码")
# 查找密码填写位置
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/form/div[3]/div/div/span/span/input")
# 清空原有内容
elem.clear()
# 填入密码
elem.send_keys("")
time.sleep(1) #加载等待
print("正在登录")
# 登录按钮并单击
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/form/div[5]/div/div/span/button").click()
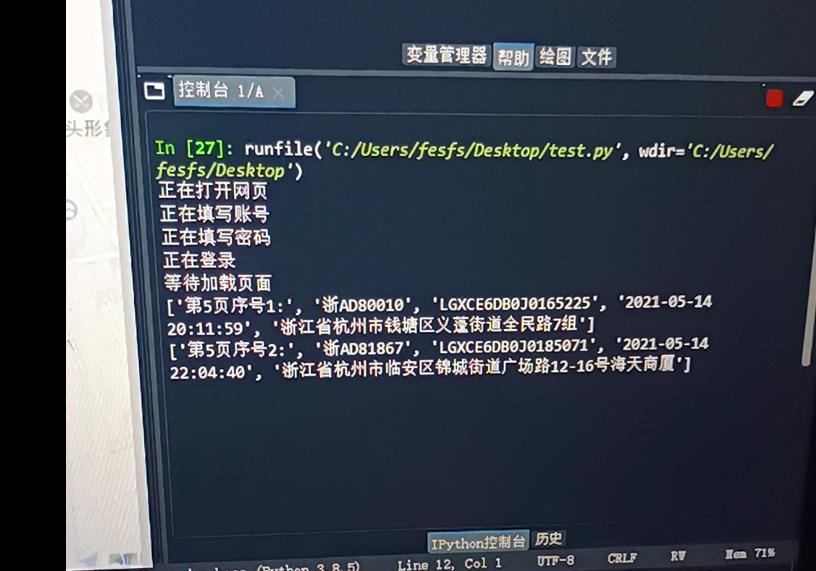
print("等待加载页面")
time.sleep(5) #加载等待
wenjian=datetime.datetime.now().strftime('%Y-%m-%d-%H%M%S') #以开始时间作为数据导出的表格文件名
wenjian=wenjian+'.csv'
kk=1 #从第几页开始
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[11]/div[2]/input")
elem.clear()
elem.send_keys(str(kk-1))
elem.send_keys(Keys.ENTER)
R=[]
for K in range(kk,503):#采用输入页码形式翻页
time.sleep(0.5)
if K<5:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[11]/div[2]/input")
if K==5:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[12]/div[2]/input")
if K>5 and K<500:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[13]/div[2]/input")
if K==500:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[12]/div[2]/input")
if K>500:
elem = driver.find_element_by_xpath("/html/body/div[1]/div/div/div[2]/div/div/div/div/div/div/div/ul/li[11]/div[2]/input")
elem.clear()
elem.send_keys(str(K))
elem.send_keys(Keys.ENTER)
time.sleep(0.5)
if K<502:
for i in range(1,11):
#if K==186 and i==9:#该位置的对象数据缺失,直接越过即可
# continue
#if K==318 and i==8:#该位置的对象数据缺失,直接越过即可
# continue
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body-inner']/table/tbody/tr["+str(i)+"]/td/span/a[1]"))).click()#点击列表中的元素
time.sleep(0.5) #加载等待
result=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body']/table/tbody/tr["+str(i)+"]/td[3]"))).text
result1=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body']/table/tbody/tr["+str(i)+"]/td[2]"))).text
result2=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-drawer-content-wrapper']/div/div/div[2]/div/div[1]/div/div[2]/div/div[2]/div/div[2]/div/div[1]/div[2]"))).text
result3=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-drawer-content-wrapper']/div/div/div[2]/div/div[1]/div/div[2]/div/div[2]/div/div[1]/div/div/div[2]"))).text
while result3=='' or result2=='': #如果第一次未读取到信息,则进行二次读取
driver.find_element_by_xpath("//div[@class='ant-drawer-content-wrapper']/div/div/div[1]/button/i").click() #点击窗口退出按钮
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body-inner']/table/tbody/tr["+str(i)+"]/td/span/a[1]"))).click()#点击列表中的元素
time.sleep(1.5) #加载等待
result=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body']/table/tbody/tr["+str(i)+"]/td[3]"))).text
result1=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body']/table/tbody/tr["+str(i)+"]/td[2]"))).text
result2=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-drawer-content-wrapper']/div/div/div[2]/div/div[1]/div/div[2]/div/div[2]/div/div[2]/div/div[1]/div[2]"))).text
result3=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-drawer-content-wrapper']/div/div/div[2]/div/div[1]/div/div[2]/div/div[2]/div/div[1]/div/div/div[2]"))).text
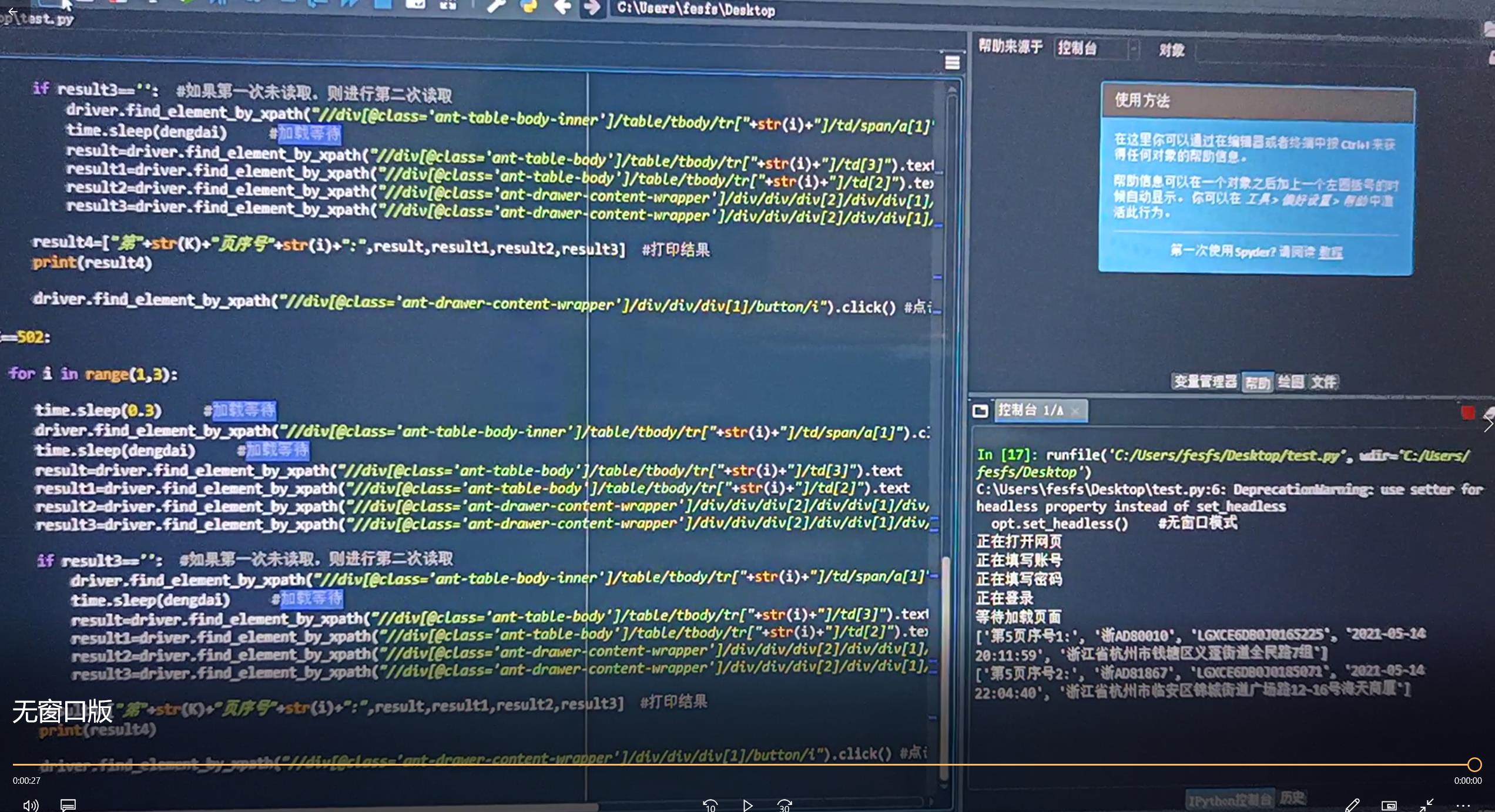
result4=["第"+str(K)+"页序号"+str(i)+":",result,result1,result2,result3] #打印结果
R.append(result4)
#print(result4)
time.sleep(0.5) #加载等待
driver.find_element_by_xpath("//div[@class='ant-drawer-content-wrapper']/div/div/div[1]/button/i").click() #点击窗口退出按钮
print('正在爬取'+str(K)+'页'+str(i)+'行')
with open(wenjian,'w',encoding='utf-8',newline='') as fp:
writer = csv.writer(fp)
writer.writerows(R) #写入数据
if K==502:
for i in range(1,3):
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body-inner']/table/tbody/tr["+str(i)+"]/td/span/a[1]"))).click()#点击列表中的元素
time.sleep(0.5) #加载等待
result=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body']/table/tbody/tr["+str(i)+"]/td[3]"))).text
result1=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body']/table/tbody/tr["+str(i)+"]/td[2]"))).text
result2=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-drawer-content-wrapper']/div/div/div[2]/div/div[1]/div/div[2]/div/div[2]/div/div[2]/div/div[1]/div[2]"))).text
result3=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-drawer-content-wrapper']/div/div/div[2]/div/div[1]/div/div[2]/div/div[2]/div/div[1]/div/div/div[2]"))).text
while result3=='' or result2=='': #如果第一次未读取信息,则进行二次读取
driver.find_element_by_xpath("//div[@class='ant-drawer-content-wrapper']/div/div/div[1]/button/i").click() #点击窗口退出按钮
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body-inner']/table/tbody/tr["+str(i)+"]/td/span/a[1]"))).click()#点击列表中的元素
time.sleep(1.5) #加载等待
result=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body']/table/tbody/tr["+str(i)+"]/td[3]"))).text
result1=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-table-body']/table/tbody/tr["+str(i)+"]/td[2]"))).text
result2=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-drawer-content-wrapper']/div/div/div[2]/div/div[1]/div/div[2]/div/div[2]/div/div[2]/div/div[1]/div[2]"))).text
result3=WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//div[@class='ant-drawer-content-wrapper']/div/div/div[2]/div/div[1]/div/div[2]/div/div[2]/div/div[1]/div/div/div[2]"))).text
result4=["第"+str(K)+"页序号"+str(i)+":",result,result1,result2,result3] #打印结果
R.append(result4)
#print(result4)
time.sleep(0.5) #加载等待
driver.find_element_by_xpath("//div[@class='ant-drawer-content-wrapper']/div/div/div[1]/button/i").click() #点击窗口退出按钮
print('正在爬取'+str(K)+'页'+str(i)+'行')
with open(wenjian,'w',encoding='utf-8',newline='') as fp:
writer = csv.writer(fp)
writer.writerows(R) #写入数据
以上是关于Python+selenium 模拟网页点击爬虫车辆定位系统的主要内容,如果未能解决你的问题,请参考以下文章