ES为什么那么牛——Elasticsearch存储解析
Posted 魏小言
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES为什么那么牛——Elasticsearch存储解析相关的知识,希望对你有一定的参考价值。
本文仅针对ES存储部分进行解析,其他部分请关注后续博文,欢迎技术交流!
Elasticsearch
监控全家桶 ELK/EFK,其中的 E 就是 ES(Elasticsearch)。Elasticsearch「开发语言 Java」最早于 2010 年 2 月发布,是一款分布式可扩展的实时检索分析组件。它不仅是一款文档型数据库,也是基于全文搜索引擎 Apache Lucene 之上的一款检索引擎。
Elasticsearch 架构
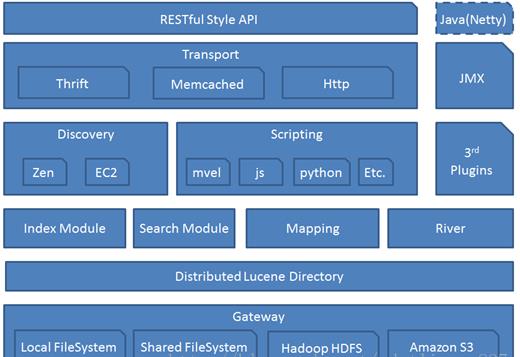
文档型数据库
从存储单元角度讲,和 Graphite 的原生存储 Whisper 一致,都属于文档型数据库,但存储机制及数据结构迥然不同。
在 Elasticsearch 中,每条数据是一个以 Json 格式序列化的文档。
{
"scene" : "wax",
"product" : "mainfeed",
"status": "200"
}
{
"scene" : "wax",
"product" : "mainfeed",
"status": "404"
}
{
"scene" : "wax",
"product" : "mainfeed",
"status": "502"
}
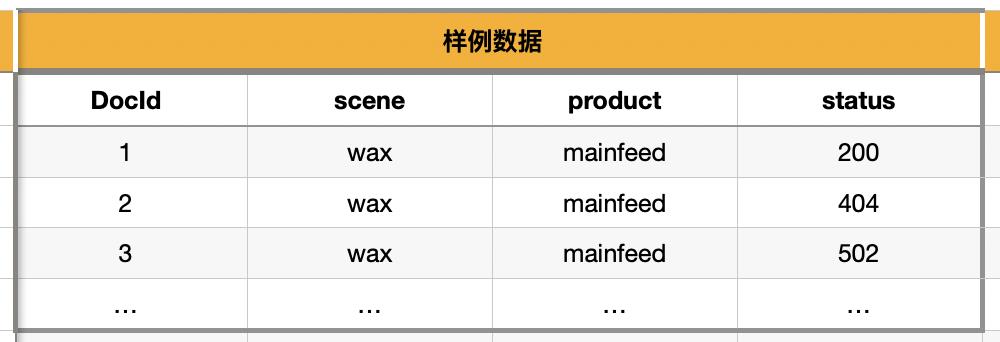
每个文档都归属于某个 Type,相互关联的多 Type 属于某个 Index。
类比于常见关系型数据库的话,对应关系:
Doc <=> Row;
Type <=> Table;
Index <=> DataBase;
每个数据项最终和索引关联,这样的关联关系设计的初衷就是为了,利用索引能够获得优秀的检索能力。
那么问题来了,检索能力优秀依赖的索引是怎样设计的呢/?
索引结构
针对上述的 Case,会建立如下索引结构:
{
"httpCode":{
"properties":{
"scene":{
"type":"keyword"
},
"product":{
"type":"keyword"
},
"status":{
"type":"keyword"
}
}
}
}
Elasticsearch 会根据这个索引结构建立倒排索引,如下:
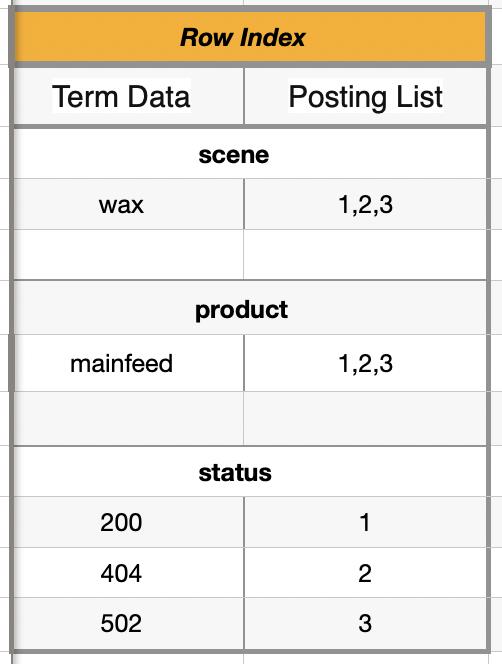
Flasticsearch 会对每个列进行转换,形成一个映射表 Row Index。当我们进行查找“status=200“的时候,会根据 Row Data 全表便利查找“status”,之后同样找到“200”的 Posting List,从而定位到目标数据的文档 ID,进行 I/O 操作。
大家看到这里,我们需要思考一下,上述过程存在些性能问题:
操作的时间复杂度和存储占用率,都会随数据规模的膨胀而线性增长;
当数据规模极大时,性能存在问题。
时间复杂度
1、当 Term Data 数量规模极大时,全表遍历的时间复杂度为 N,并非最优!
了解数据结构的同学知道,场景下查找算法中最佳的是对数据进行排序之后,使用二分查找,时间复杂度可为 LogN。「Hash 算法不适合做索引<不支持顺序、联合、冲突等原因,收藏关注博主,后续开贴讲解,本文不做讲解>,不符合设定,故排除」
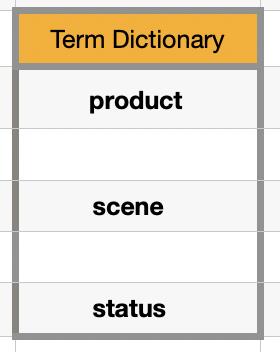
故对 Term 进行排序,构成 Term Dictionary 结构,进行读取优化。
这样就是最优了嘛/?
不,这样的时间复杂度和关系型数据库 mysql 中的索引 B+树一致 LogN,且都是在磁盘中 I/O,平均一次磁盘的随机读操作耗时在 10ms 左右;所以为了减少 I/O 操作,充分利用内存的速度优势,把 Term 关系放置在内存中,目标位置定位由内存完成。
这样问题又来了,内存虽然速度完胜,但空间大小是被动的,怎么把随数据规模线性增长的 Term 放置在内存中呢/?
Elasticsearch 引入了 Term Index。Term Index 是 Term 的索引,通俗的讲,就是字典中查找汉字用的首字母目录。道理是这样,举个例子:
要找“言”字,首先找 Y,之后在找 A,最后找到 N 的位置,那么就完成检索。
按照这个道理,如果 Term 全部都是英文单词,那么我们只需包含 26 个字母的 Tire 树就行了,所需存储空间大大缩小。
Term Index 这棵树不会包含所有的 Term,它包含的是 Term 的一些前缀。通过 Term Index 可以快速地定位到 Term Dictionary 的某个 offset,然后从这个位置再往后顺序查找。
检索速度完胜关系型数据库 Mysql。
2、Posting List 为有序数组,数据结构满足最优算法<二分、跳表…>,无需额外进行调整
空间复杂度
1、Term Data/Index 空间复杂度会随数据规模线性增长!
内存中的 Term Index 使用 FST 压缩技术(搜索 Lucene Finite State Transducers) Term Index 的尺寸可以只有所有 Term 的尺寸的几十分之一,使得用内存缓存整个 Term Index 变成可能。
磁盘中的 Term Data 以分 block 的方式保存的,一个 block 内部利用公共前缀压缩,比如都是 S 开头的单词就可以把 Abc… 省去。这样 Term Dictionary 可以比 b-tree 更节约磁盘空间。
2、Posting List 为数组空间复杂度会随数据规模线性增长!
对 Druid 和倒排索引了解到同学,可能想到用 Bitmap 来压缩存储体积<0/1 标识数据有无>,如下:
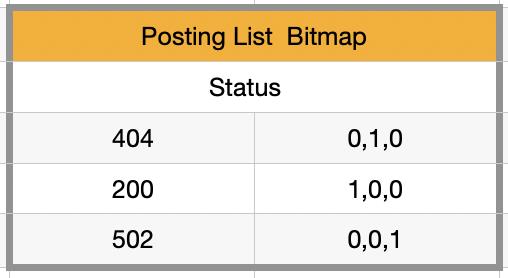
但这种压缩方式只是在数据类型上进行了简化,复杂度依旧是线性。Elasticsearch 引入了 Roaring Bitmap结构,对数据膨胀做了结构性的优化。
将划分为 2^16 个桶,每一个桶有一个 Container 来存放一个数值 k 的低 16 位;
在存储和查询数值的时候,我们将一个数值 k 划分为高 16 位(k % 2^16)和低 16 位(k mod 2^16)〈即转化为 16 进制之后,对半拆,前部分为高 16 位,后部分为低 16 位〉,取高 16 位找到对应的桶,然后在低 16 位存放在相应的 Container 中;
RBM Container 使用两种容器结构:
Array Container 和 Bitmap Container。
Array Container 存放稀疏的数据,Bitmap Container 存放稠密的数据。
即,若一个 Container 里面的 Integer 数量小于 4096,就用 Short 类型的有序数组来存储值。若大于 4096,就用 Bitmap 来存储值。
那么问题又来了,为啥要分为 2^16 个桶/?
2^16 是 2 字节能容纳的最大量。在 32-bit 的范围 ([0, n))内,有十亿级规模数据,转化为二进制拆分两部分,一部分为 16bit,即 2 字节,short 类型。
为什么要用 4096 做不同 Container 的分割呢/?
假设在 bitmap container 中,16bit,可容纳 2^16 =65536 个数值,65536/8=8192byte~=8kb;
若用 short 类型存储,8192b/2b=4096byte;
也就是,当数值小于 4096 时,用 short 更省空间,根本不需要开个 8kb 的 bitmap contrainer。
Q&A
1、Elasticsearch 每个数据项是一个文档,当数据项量级膨胀时,跟随的文档数量及相应的 I/O 也会增加,怎么搞下这个问题呢/?是不是存在瓶颈/?
常见的压缩存储时间序列的方式是压缩。
一种是把多个数据点合并成一行
Opentsdb 支持海量数据就是定期把多行数据合并成一行。
另一种把多个数据点聚合为单点
Graphite 支持高精度数据通过某种规则聚合为低精度「这里的精度指时序粒度」,降低存储、I/O 成本。
Elasticsearch 提供这样一个嵌套文件的机制,可以把一段时间隔内的文档数据打包嵌套至一个文档内;且 Elasticsearch 支持分布式部署,亿级数据量轻轻松松。
具体瓶颈的话,不是在磁盘存储的部分「磁盘从来不是什么瓶颈,除非超出部门预算…」
而是内存的部分,由于 FST( Finite State Transducer),在海量数据下,Elasticsearch 依赖于 Java 的 JVM,内存堆会爆炸…
2、如何解决Elasticsearch内存不足的痛点呢/?
请关注后续博文!
3、在做监控系统时,必须是ELK/EFK套餐吗/?如何进行技术选型呢/?
请关注后续博文!
附录
思索一件事的时候,走进去后记得出来回头再看看,实在不行退两步再看……
以上是关于ES为什么那么牛——Elasticsearch存储解析的主要内容,如果未能解决你的问题,请参考以下文章