信也容器云揭秘04-K8S集群稳定性保障
Posted 拍码场
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了信也容器云揭秘04-K8S集群稳定性保障相关的知识,希望对你有一定的参考价值。
一、摘要
信也容器云平台基于Kubernetes和Docker开发,自2018年底上线以来,总共维护了8套k8s集群,生产接入超过850个应用,全环境实例数达到9000。作为一家金融科技公司,服务稳定性必然是逃不开的话题,本次分享就以集群部署、高可用控制器、监控智能化处理三个部分,为大家介绍容器云在稳定性保障方面的一些经验和思考。
二、集群部署
以生产环境为例,我们有两个机房,每个机房部署了两套K8S集群,同一机房的集群节点数相等。实例通过容器云平台发布,首先根据应用类型和重要程度选择部署的机房,然后均匀分布于机房内的各个集群,同一集群的实例由kube-scheduler均匀调度到各个节点。任何一个节点或者集群挂掉,其他节点和集群上的实例依旧正常运行,不会影响服务的可用性,最大程度的保障了物理上的高可用。部署架构图如下:
因为存在部分应用发单数实例的情况,这些实例不能绝对平均分配,长时间运行下来,会出现同一机房的某个集群实例数略大于另一个集群的现象,如果不加干涉,此集群实例数会越来越多,导致集群整体内存使用偏高,降低集群的稳定性,到后面更会因为集群内存不足而无法调度。
基于以上原因,我们开发了一个定时任务,通过Prometheus抓取集群的内存使用数据,判断出负载较低的集群,为该集群设置较高优先级。如此,下一轮的调度如果出现单数的情况,多出来的一个实例将调度到高优先级的集群。这里算法的基本逻辑为,先判断应用已有实例的集群分布情况,待发布的实例优先调度到已有实例数较少的集群,如果存在多个集群已有实例数相等,优先选择高优先级(负载低)的集群,此算法对多于两个集群的情况同样有效。生产实践下来,该措施使得各个集群的实例数和负载处在同一水平,最大化利用了集群资源,有效提高了集群稳定性。
三、高可用控制器
为满足不同的业务场景和发布模式,以及安全上的固定IP需求,信也容器云平台选择了以Pod为粒度进行实例部署,而没有使用常见的Deployment方式。由于K8S对单个Pod没有提供自愈机制,我们在容器云平台中使用Java自研了一个高可用控制器,容器和物理机宕机后实例会自动恢复。
在具体介绍高可用控制器之前,我们先来回顾一下就绪探针(Readiness Probe)的概念。就绪探针用于判断容器是否启动完成,即Pod的Condition是否为Ready,如果探测结果不成功,则会将Pod从Endpoint中移除,直至下次判断成功,再将Pod挂回到Endpoint上。
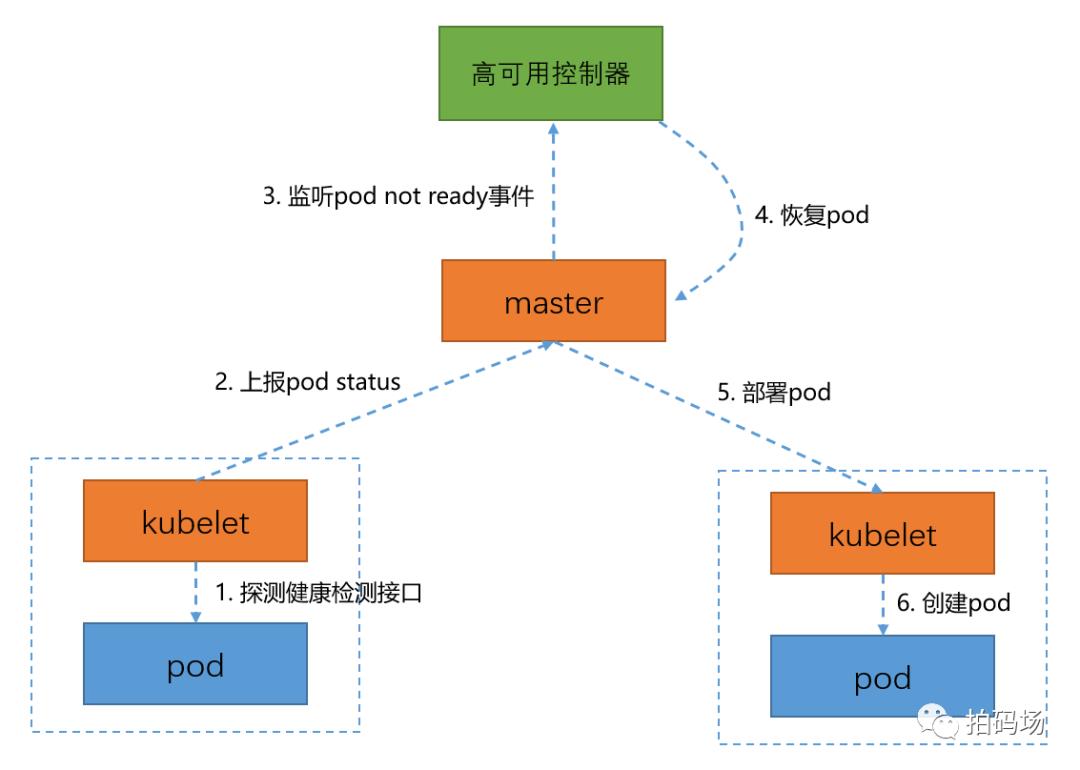
基于以上原理,我们在容器里添加了一个健康检测接口作为就绪探针,容器云平台监听Service下面的Endpoints事件,一旦发现Pod状态变为Not Ready,就会对Pod做一个删除和重新部署的操作,操作前后实例IP不变。如下图所示:
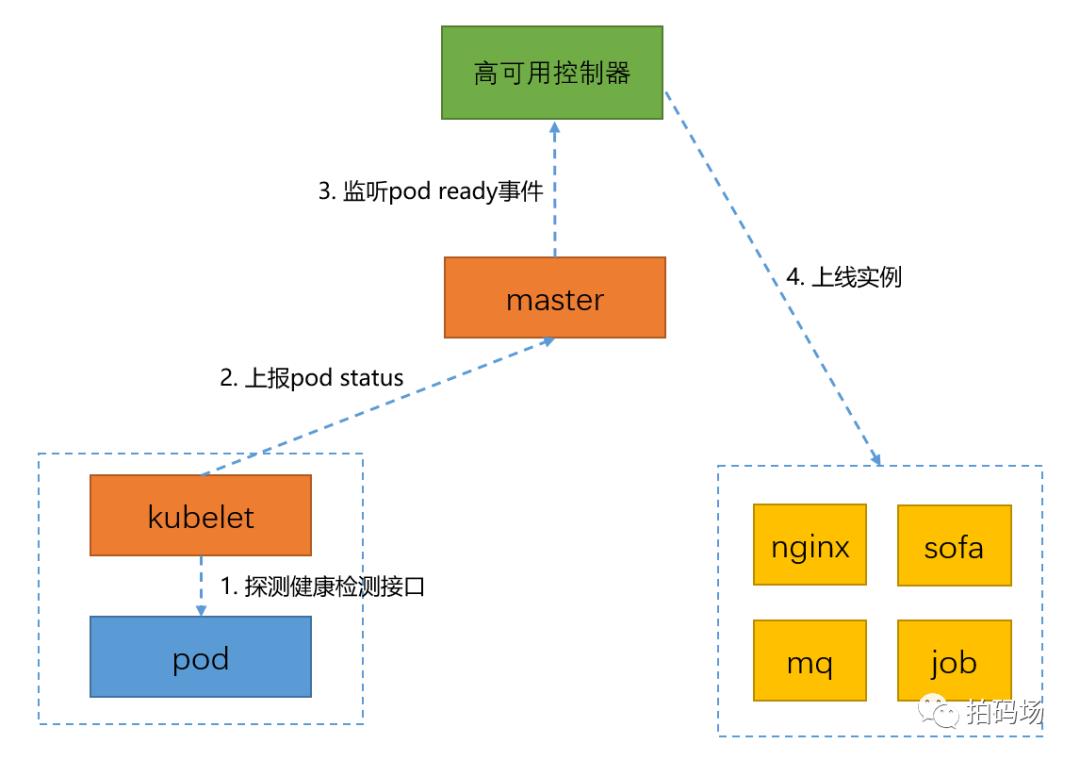
当高可用控制器检测到Pod状态变为Ready时,则会根据实例宕机前的流量状态做上线或忽略处理。如下图所示:
控制器对Endpoints采取监听和轮询两种方式,防止监听时出现异常,确保所有实例状态变更后得到处理。示例代码如下:
public void startEventTrigger() {Config config = new ConfigBuilder().withMasterUrl(apiServer).build();KubernetesClient client = new DefaultKubernetesClient(config);client.endpoints().watch(new Watcher<Endpoints>() {@Overridepublic void eventReceived(Action action, Endpoints endpoints) {for (EndpointSubset endpointSubset : endpoints.getSubsets()) {for (EndpointAddress endpointAddress : endpointSubset.getNotReadyAddresses()) {processNotReadyAddress(endpoints.getMetadata().getName(), endpointAddress);}for (EndpointAddress endpointAddress : endpointSubset.getAddresses()) {processReadyAddress(endpoints.getMetadata().getName(), endpointAddress);}}}@Overridepublic void onClose(KubernetesClientException e) {log.error("事件监听时与apiserver发生链接中断, err=" + e.getMessage(), e);}});}public void startEventPolling() {Config config = new ConfigBuilder().withMasterUrl(apiServer).build();KubernetesClient client = new DefaultKubernetesClient(config);ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);scheduler.scheduleAtFixedRate(() -> {EndpointsList endpointsList = client.endpoints().list();for (Endpoints endpoints : endpointsList.getItems()) {for (EndpointSubset endpointSubset : endpoints.getSubsets()) {for (EndpointAddress endpointAddress : endpointSubset.getNotReadyAddresses()) {processNotReadyAddress(endpoints.getMetadata().getName(), endpointAddress);}for (EndpointAddress endpointAddress : endpointSubset.getAddresses()) {processReadyAddress(endpoints.getMetadata().getName(), endpointAddress);}}}}, 120, 120, TimeUnit.SECONDS);}
根据上面的代码可以发现,我们对Not Ready事件的处理放在了processNotReadyAddress方法中,而对Ready事件的处理则放到了processReadyAddress方法里,这两个方法包含了较多的忽略逻辑,如实例有其他任务正在执行,实例处在静默期(用户刚操作完实例),应用未开启高可用,一段时间内的重复事件,等等,具体细节就不在此处展开了。
需要注意的是,processNotReadyAddress方法里有一段重要的特殊逻辑,由于Kubelet停止后也会产生Not Ready事件,所以我们会再次调用Pod的健康检测接口,防止因为Kubelet停止造成的误迁移。当二次检测失败之后,我们才对Pod做删除和重新部署操作。
这套高可用机制已在生产环境完成了多次实例、物理机宕机的自动恢复,表现良好,有效保障了集群的稳定运行。
四、监控智能化处理
上面的高可用控制器应用场景主要是实例、物理机宕机,这是一种事后处理方式,或者说是一种补救行为,那么有没有一种方式能让我们事前感知到实例的异常从而在实例宕机前进行相应的处理呢?答案是有的,监控智能化处理,容器云平台联合谛听调用链监控平台、实时数据Flink计算平台共同完成了这一目标。架构如下:
简单介绍一下上图的流程,用户首先需要在谛听调用链监控平台配置应用的监控告警规则,监控的类型很多,涵盖了JVM监控、异常接口调用、主机监控、错误码、数据库指标等,规则可以配置多条,根据监控类型可以配置为堆内存使用量大于一定值、每分钟异常数超过一定值等复杂组合,同时很重要的一点,配置智能触发行为,让容器重启或者下线。
接下来谛听通过Cat、Prometheus等工具从应用的容器中获取实时的监控数据,并将数据写入公司的Kafka集群,由实时数据团队的Flink计算平台消费数据进行实时运算,如果运算结果满足用户配置的监控告警规则,则将一个事件写入kafka集群,消息被广播给谛听和容器云平台,谛听负责发送告警,容器云平台负责实例的重启和下线。
容器云示例代码如下,实例的处理逻辑在processDitingEvent方法里:
public void startDitingEventListener() {Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);props.put(ConsumerConfig.GROUP_ID_CONFIG, "stargate");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());Consumer<String, String> ditingEventConsumer = new KafkaConsumer<>(props);ditingEventConsumer.subscribe(Collections.singletonList("diting_alerts"));ExecutorService ditingEventExecutor = Executors.newFixedThreadPool(1);ditingEventExecutor.submit(() -> {while (true) {ConsumerRecords<String, String> records = ditingEventConsumer.poll(1000);for (ConsumerRecord<String, String> record : records) {processDitingEvent(record.value());}}});}
通过监控智能化处理机制,实例一旦出现异常,用户马上就能收到告警,同时实例做下线或重启操作,提前规避风险,大大提高了服务的稳定性。
五、结语
很高兴为大家带来这次分享,相信通过上面对集群部署、高可用控制器、监控智能化处理的介绍,大家对信也容器云平台的稳定性保障机制有了一定的了解。在这里打个小广告,信也容器云技术揭秘系列持续更新中,想了解更多容器云技术的小伙伴可以翻看一下历史文章,祝大家收货满满。
六、回馈社区
https://github.com/ppdaicorp
大家感兴趣的话可以扫描下方二维码加入微信群进行交流。
作者介绍
小明,信也科技基础架构研发工程师,容器云团队成员。
以上是关于信也容器云揭秘04-K8S集群稳定性保障的主要内容,如果未能解决你的问题,请参考以下文章