一文搞定强大的爬虫数据解析工具-Xpath
Posted 尤尔小屋的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文搞定强大的爬虫数据解析工具-Xpath相关的知识,希望对你有一定的参考价值。
公众号:尤而小屋
作者:Peter
编辑:Peter
强大的Xpath
之前爬虫解析数据的时候,自己几乎都是用正则表达式。正则解析数据很强大,但是表达式写起来很麻烦,速度相对较慢。本文介绍的是如何快速入门一种数据解析工具:Xpath。
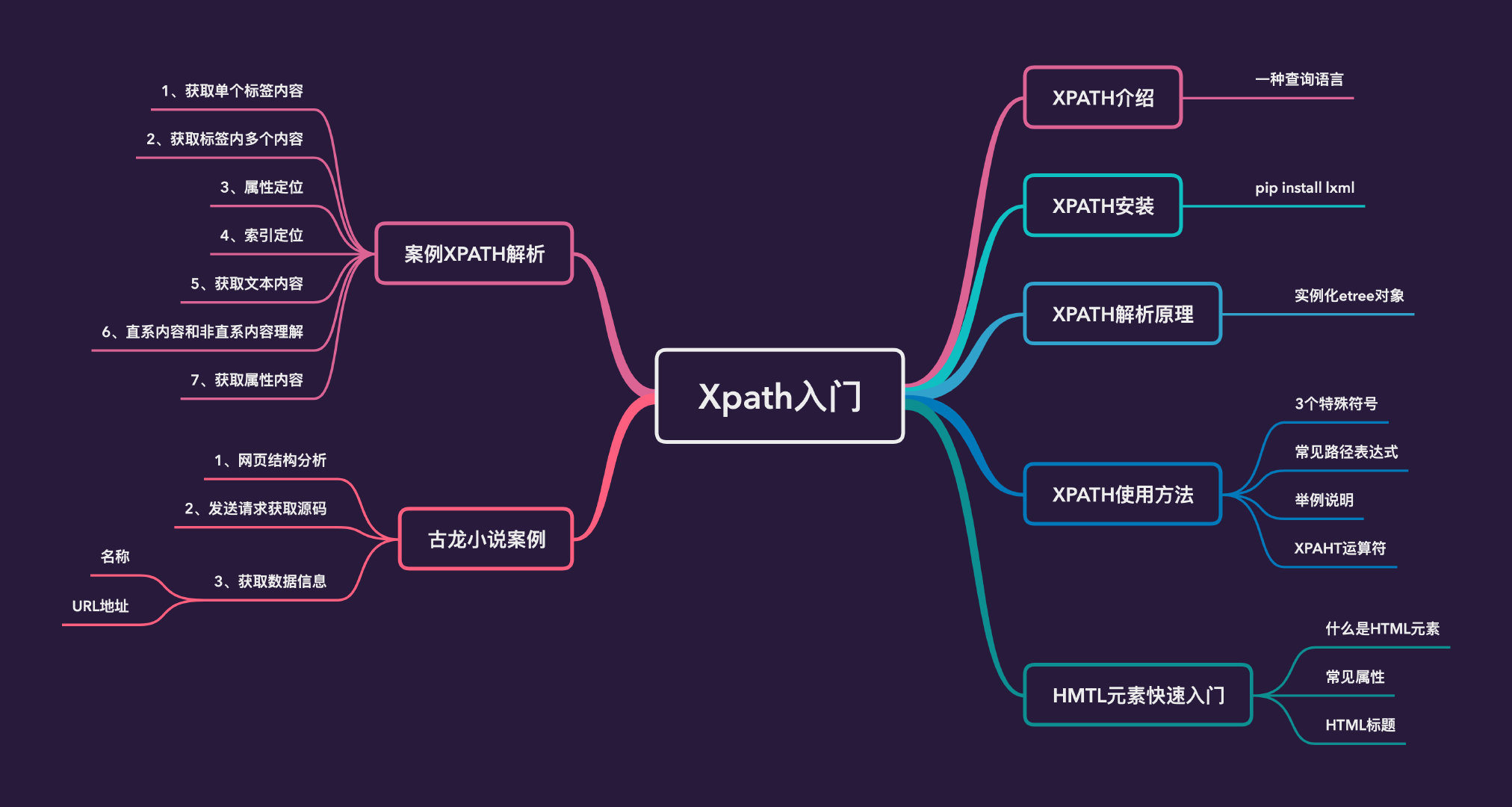
Xpath介绍
XPath (XML Path)是一门在 XML 文档中查找信息的语言。XPath 可用来在XML文档中对元素和属性进行遍历。
XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
- Xpath是一种查询语言
- 在XML(Extensible Markup Language)和html的树状结构中寻找节点
- XPATH是一种根据‘地址’来‘寻找人’的语言
快速入门网站:https://www.w3schools.com/xml/default.asp
Xpath安装
MacOS中安装非常的简单:
pip install lxml
Linux中的安装以Ubuntu为例:
sudo apt-get install python-lxml
Windows中的安装请自行百度,肯定会有教程的,就是过程相对会比较麻烦些。
如何检验安装是否成功?命令行中import lxml没有报错,即表示安装成功!

Xpath解析原理
- 实例化一个etree解析对象,且需要将解析的页面源码数据加载到对象中
- 调用xpath中的xpath解析方法结合着xpath表达式实现标签的定位和内容的捕获
如何实例化etree对象?
- 将本地的html文档中的源码数据加载到etree对象中:etree.parse(filePath)
- 将互联网上获取的源码数据加载到该对象中:etree.HTML(‘page_text’),其中page_text指的就是我们获取到的源码内容
Xpath使用方法
3个特殊符号
- /:表示从根节点开始解析,并且是单个层级,逐步定位
- //:表示多个层级,可以跳过其中的部分层级;也表示从任意位置开始定位
- .:一个点表示当前的节点
常见路径表达式
下面是常见的Xpath路径表达式:
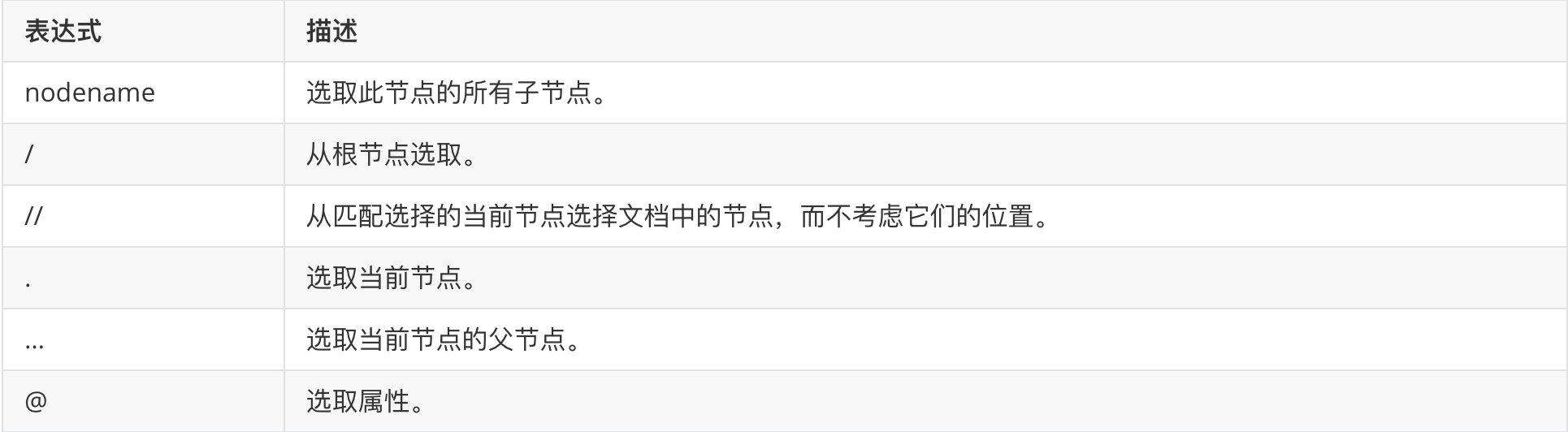
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
举例

| 表达式 | 说明 |
|---|---|
| books | 选取 books 元素的所有子节点 |
| /books | 选取根元素 bookstore |
| books//title | 选取属于 books 的子元素的所有 title 元素 |
| //price | 选取所有 price 元素 |
| books/book[3] | 选取属于 books 子元素的第3个 book 元素,索引从1开始 |
| /bookstore/book[price>55.0] | 选取所有单价大于55的 book 元素 |
| //@category | 选取所有名为 category 的属性 |
| /books/book/title/text() | 选取文档所有 title 值 |
Xpath运算符
在Xpath表达式式中是直接支持运算符的:

| Operator | Description | Example | Chinese |
|---|---|---|---|
| | | Computes two node-sets | //book | //cd | 合并两个结果 |
| + | Addition | 6 + 4 | 加 |
| - | Subtraction | 6 - 4 | 减 |
| * | Multiplication | 6 * 4 | 乘 |
| div | Division | 8 div 4 | 除 |
| = | Equal | price=9.80 | 等于 |
| != | Not equal | price!=9.80 | 不等于 |
| < | Less than | price<9.80 | 小于 |
| <= | Less than or equal to | price<=9.80 | 小于等于 |
| > | Greater than | price>9.80 | 大于 |
| >= | Greater than or equal to | price>=9.80 | 大于等于 |
| or | or | price=9.80 or price=9.70 | 或 |
| and | and | price>9.00 and price<9.90 | 且 |
| mod | Modulus (division remainder) | 5 mod 2 | 求余 |
HTML元素
HTML 元素指的是从开始标签(start tag)到结束标签(end tag)的所有代码。基本语法:
- HTML 元素以开始标签起始;HTML 元素以结束标签终止
- 元素的内容是开始标签与结束标签之间的内容
- 某些 HTML 元素具有空内容(empty content)
- 空元素在开始标签中进行关闭(以开始标签的结束而结束)
- 大多数 HTML 元素可拥有属性;属性推荐使用小写
关于空元素的使用:在开始标签中添加斜杠,比如<br />,是关闭空元素的正确方法,HTML、XHTML 和 XML 都接受这种方式。
常见属性

| 属性 | 值 | 描述 |
|---|---|---|
| class | classname | 规定元素的类名(classname) |
| id | id | 规定元素的唯一 id |
| style | style_definition | 规定元素的行内样式(inline style) |
| title | text | 规定元素的额外信息(可在工具提示中显示) |
HTML标题
HTML中标题共有6级。
标题(Heading)是通过 <h1> - <h6> 等标签进行定义的。
<h1> 定义最大的标题,<h6> 定义最小的标题。
原数据
使用Xpath解析数据之前,我们需要先导入库,同时实例化一个etree对象:
# 导入库
from lxml import etree
# 实例化解析对象
tree = etree.parse("test.html")
tree
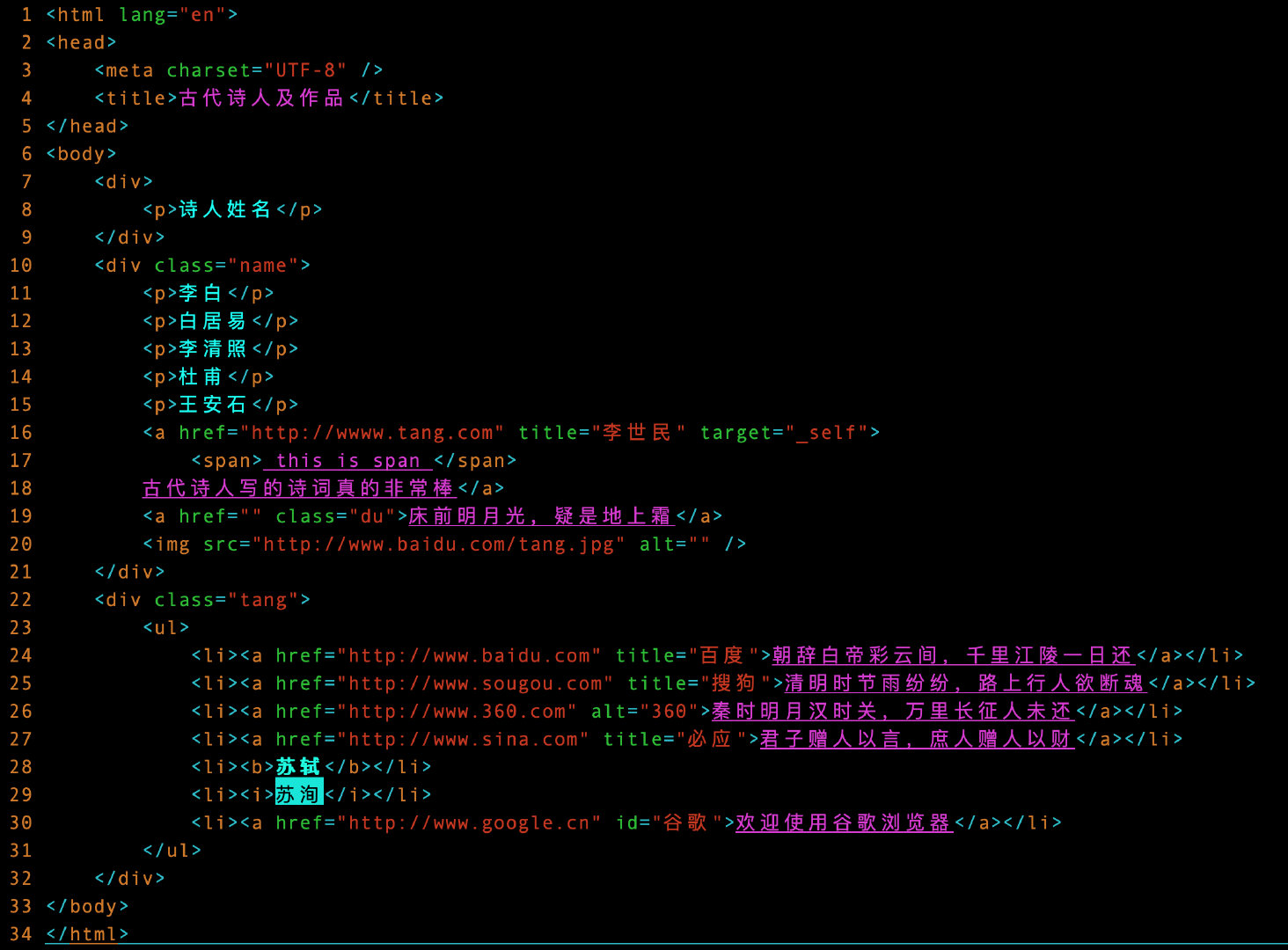
下面是待解析的原数据test.html:
1 <html lang="en">
2 <head>
3 <meta charset="UTF-8" />
4 <title>古代诗人及作品</title>
5 </head>
6 <body>
7 <div>
8 <p>诗人姓名</p>
9 </div>
10 <div class="name">
11 <p>李白</p>
12 <p>白居易</p>
13 <p>李清照</p>
14 <p>杜甫</p>
15 <p>王安石</p>
16 <a href="http://wwww.tang.com" title="李世民" target="_self">
17 <span> this is span </span>
18 古代诗人写的诗词真的非常棒</a>
19 <a href="" class="du">床前明月光,疑是地上霜</a>
20 <img src="http://www.baidu.com/tang.jpg" alt="" />
21 </div>
22 <div class="tang">
23 <ul>
24 <li><a href="http://www.baidu.com" title="百度">朝辞白帝彩云间,千里江陵一日还</a></li>
25 <li><a href="http://www.sougou.com" title="搜狗">清明时节雨纷纷,路上行人欲断魂</a></li>
26 <li><a href="http://www.360.com" alt="360">秦时明月汉时关,万里长征人未还</a></li>
27 <li><a href="http://www.sina.com" title="必应">君子赠人以言,庶人赠人以财</a></li>
28 <li><b>苏轼</b></li>
29 <li><i>苏洵</i></li>
30 <li><a href="http://www.google.cn" id="谷歌">欢迎使用谷歌浏览器</a></li>
31 </ul>
32 </div>
33 </body>
34 </html>
获取单个标签内容
比如想获取title标签中的内容:古代诗人及作品

title = tree.xpath("/html/head/title")
title

通过上面的结果发现:每个Xpath解析的结果都是一个列表
如果想取得标签中的文本内容,使用text():
# 从列表中提取相应内容
title = tree.xpath("/html/head/title/text()")[0] # 索引0表示取得第一个元素值
title

获取标签内的多个内容
比如我们想获取div标签的内容,原数据中有3对div标签,结果是列表中含有3个元素:
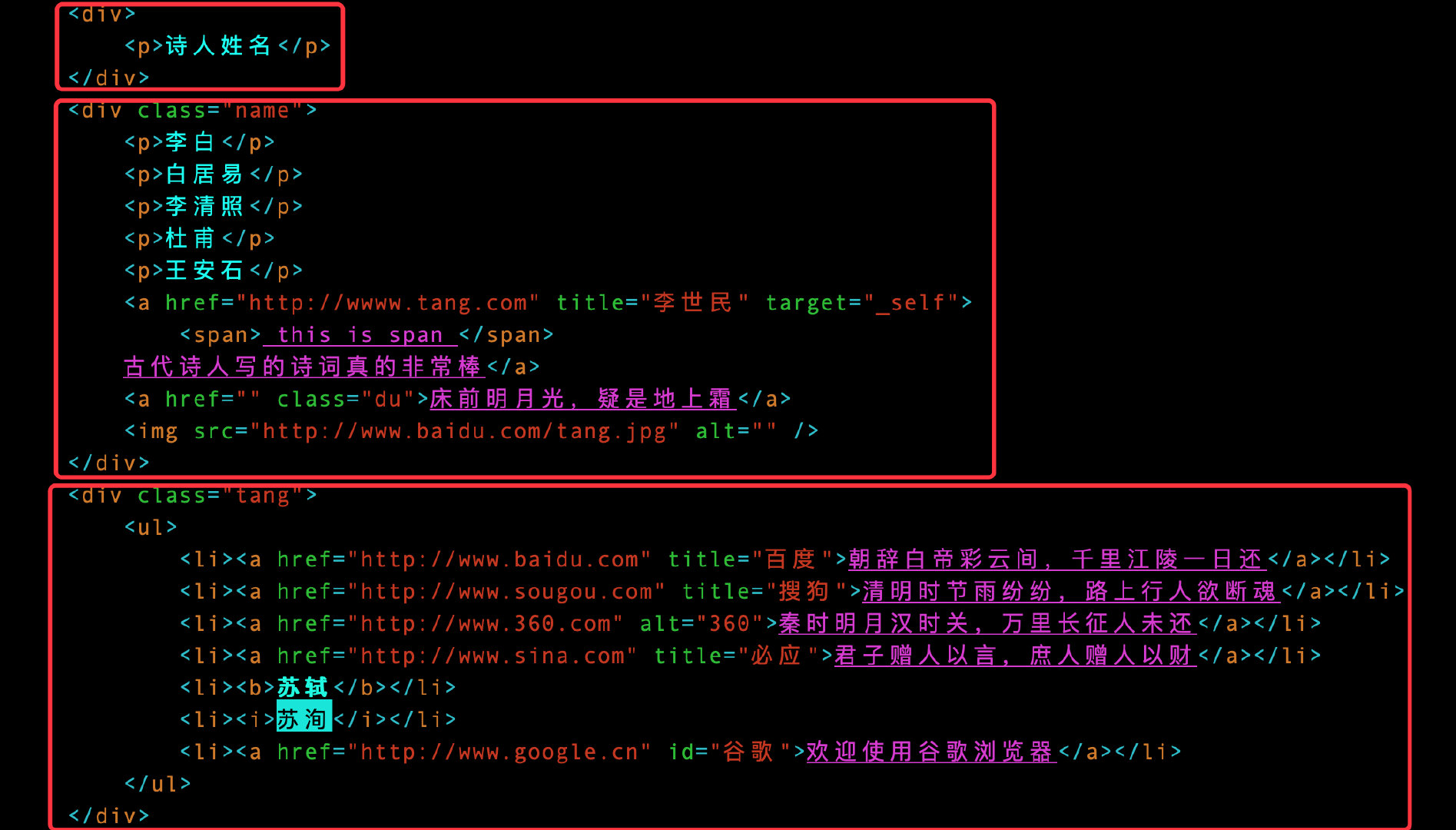
1、使用单斜线/:表示根节点html开始定位,表示的是一个层级
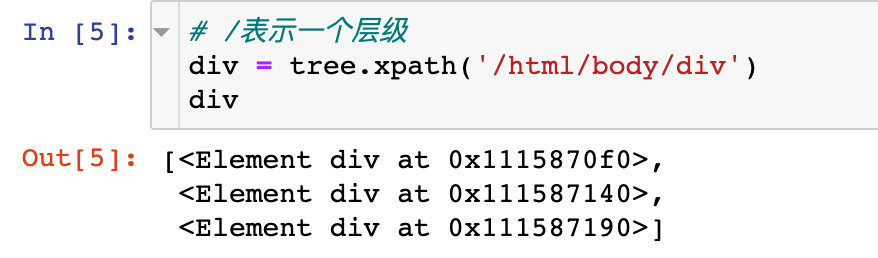
2、中间使用双斜线//:表示跳过中间的层级,表示的是多个层级
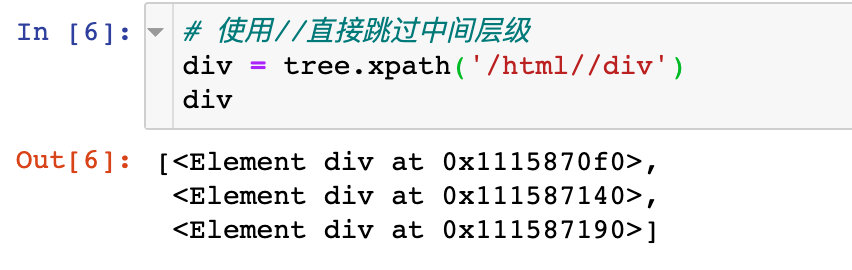
3、开头部位使用双斜线//:表示从任意位置开始

属性定位
使用属性定位的时候直接在标签后面跟上[@属性名="属性值"]:
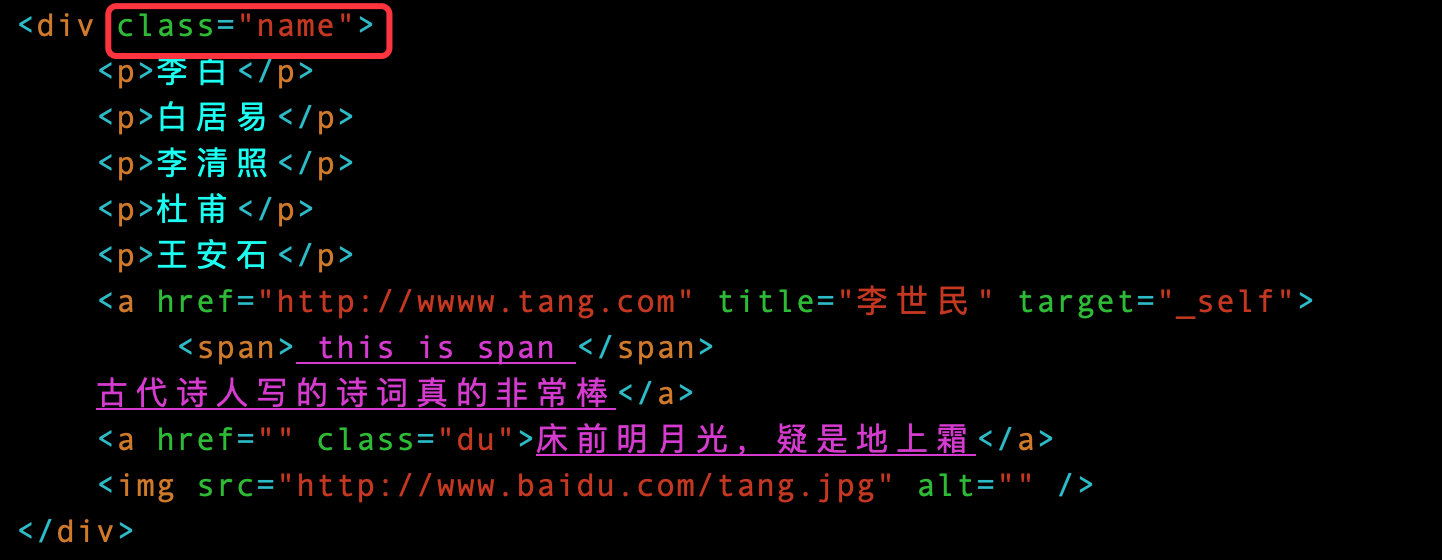
name = tree.xpath('//div[@class="name"]') # 定位class属性,值为name
name

索引定位
Xpath中索引是从1开始,和python中的索引从0开始是不同的。比如想定位div标签下class属性(值为name)下的全部p标签:5对p标签,结果应该是5个元素

# 获取全部数据
index = tree.xpath('//div[@class="name"]/p')
index
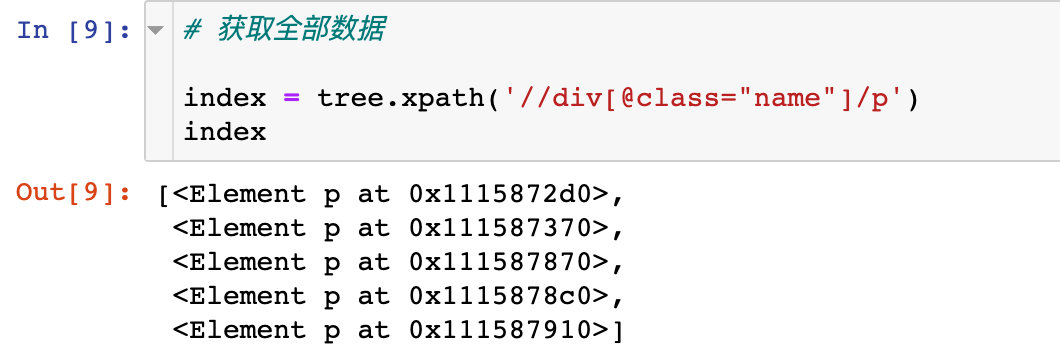
如果我们想获取其中的第3个p标签:
# 获取单个指定数据:索引从1开始
index = tree.xpath('//div[@class="name"]/p[3]') # 索引从1开始
index

获取文本内容
第一种方法:text()方法
1、获取具体某个标签下面的元素:
# 1、/:单个层级
class_text = tree.xpath('//div[@class="tang"]/ul/li/b/text()')
class_text
# 2、//:多个层级
class_text = tree.xpath('//div[@class="tang"]//b/text()')
class_text

2、某个标签下面的多个内容
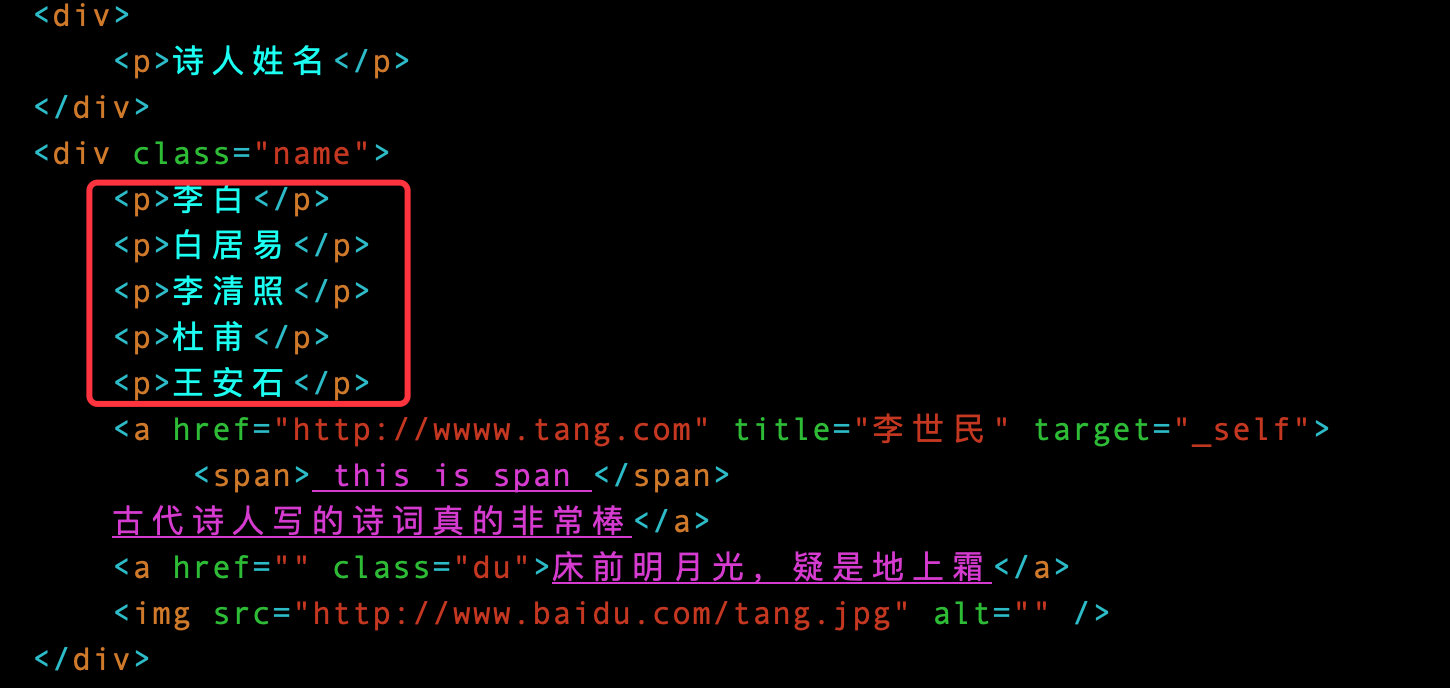
比如想获取p标签下面的全部内容:
# 获取全部数据
p_text = tree.xpath('//div[@class="name"]/p/text()')
p_text

比如想获取第3个p标签下面的内容:
# 获取第3个标签内容
p_text = tree.xpath('//div[@class="name"]/p[3]/text()')
p_text

如果是先获取p标签中的全部内容,结果是列表,再使用python索引获取,注意索引为2:

非标签直系内容的获取:

标签直系内容的获取:结果为空,直系的li标签中没有任何内容

如果想获取li标签的全部内容,可以将下面的a、b、i标签合并起来,使用竖线|
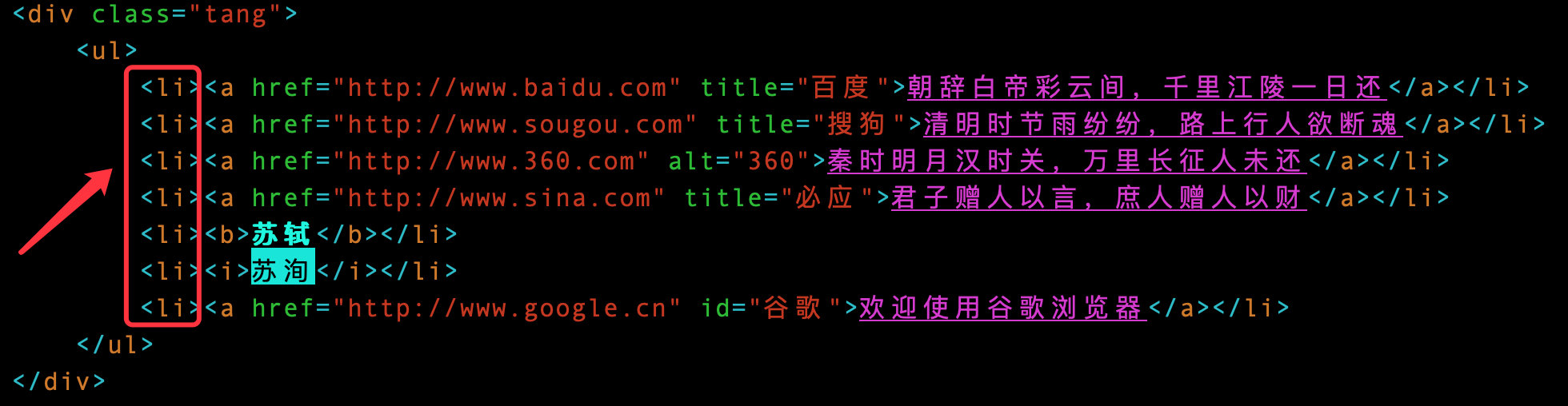
# 同时获取li标签下面a/b/i标签的内容,相当于是li标签全部的内容
abi_text = tree.xpath('//div[@class="tang"]//li/a/text() | //div[@class="tang"]//li/b/text() | //div[@class="tang"]//li/i/text()')
abi_text

直系和非直系理解

取属性内容
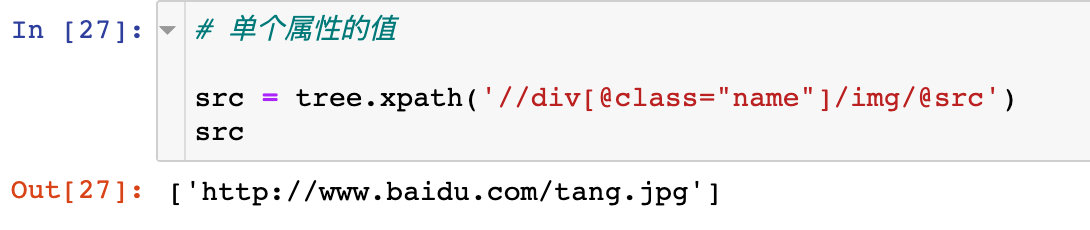
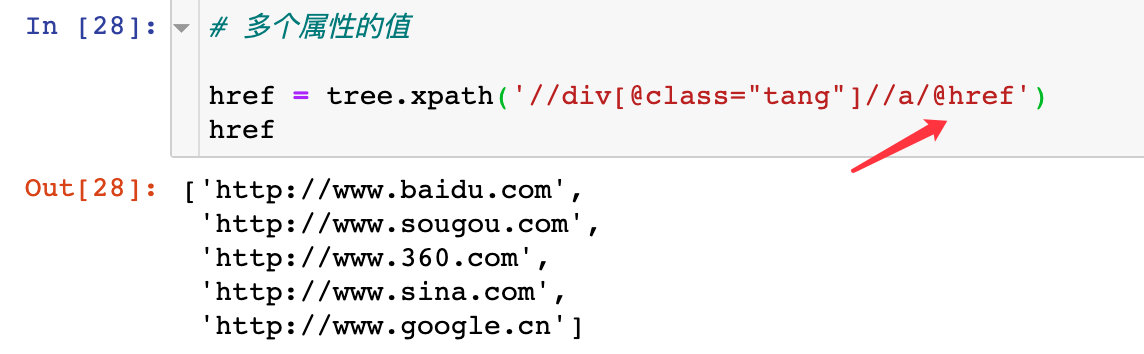
如果想获取属性的值,在最后的表达式中加上:@+属性名,即可取出相应属性的值
1、获取单个属性的值

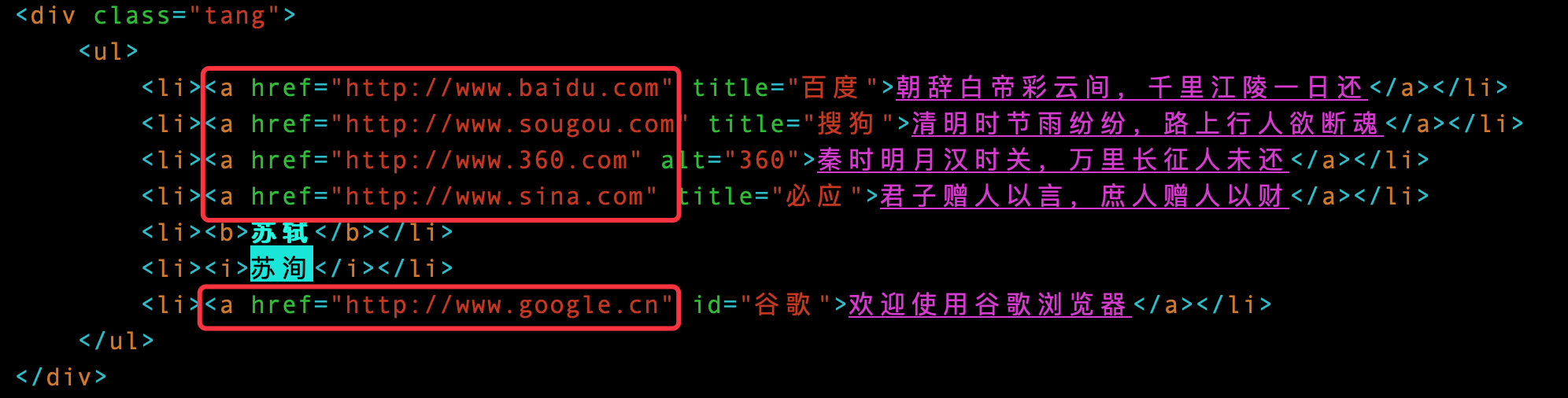
2、获取属性的多个值
总结
在这里对Xpath的使用总结下:
- //:表示获取标签非直系内容,有跨越层级
- /:表示只获取标签的直系内容,不跨越层级
- 如果索引是在Xpath表达式中,索引从1开始;如果从Xpath表达式中获取到列表数据后,再使用python索引取数,索引从0开始
实战
利用XPATH来爬取小说网站上古龙的全部小说名称(name)和URL地址(url),古龙简介:
本名熊耀华,江西人;台湾淡江英专(即淡江大学前身)毕业(一说肄业)。少年时期便嗜读古今武侠小说及西洋文学作品,一般多以为他是受到吉川英治、大小仲马、海明威、杰克伦敦、史坦贝克小说乃至尼采、沙特等西洋哲学的影响启迪。 (古龙自己也说过“我喜欢从近代日本及西洋小说‘偷招’。”) 故能日新又新,後来居上,且别开武侠小说新境界。
网页数据分析
爬取的信息在这个网站上:https://www.kanunu8.com/zj/10867.html

当我们点击具体某个小说,比如“绝代双骄”就可以进去该小说的具体信息中:

通过查看网页的源码,我们发现名称和URL地址全部在下面的标签中:
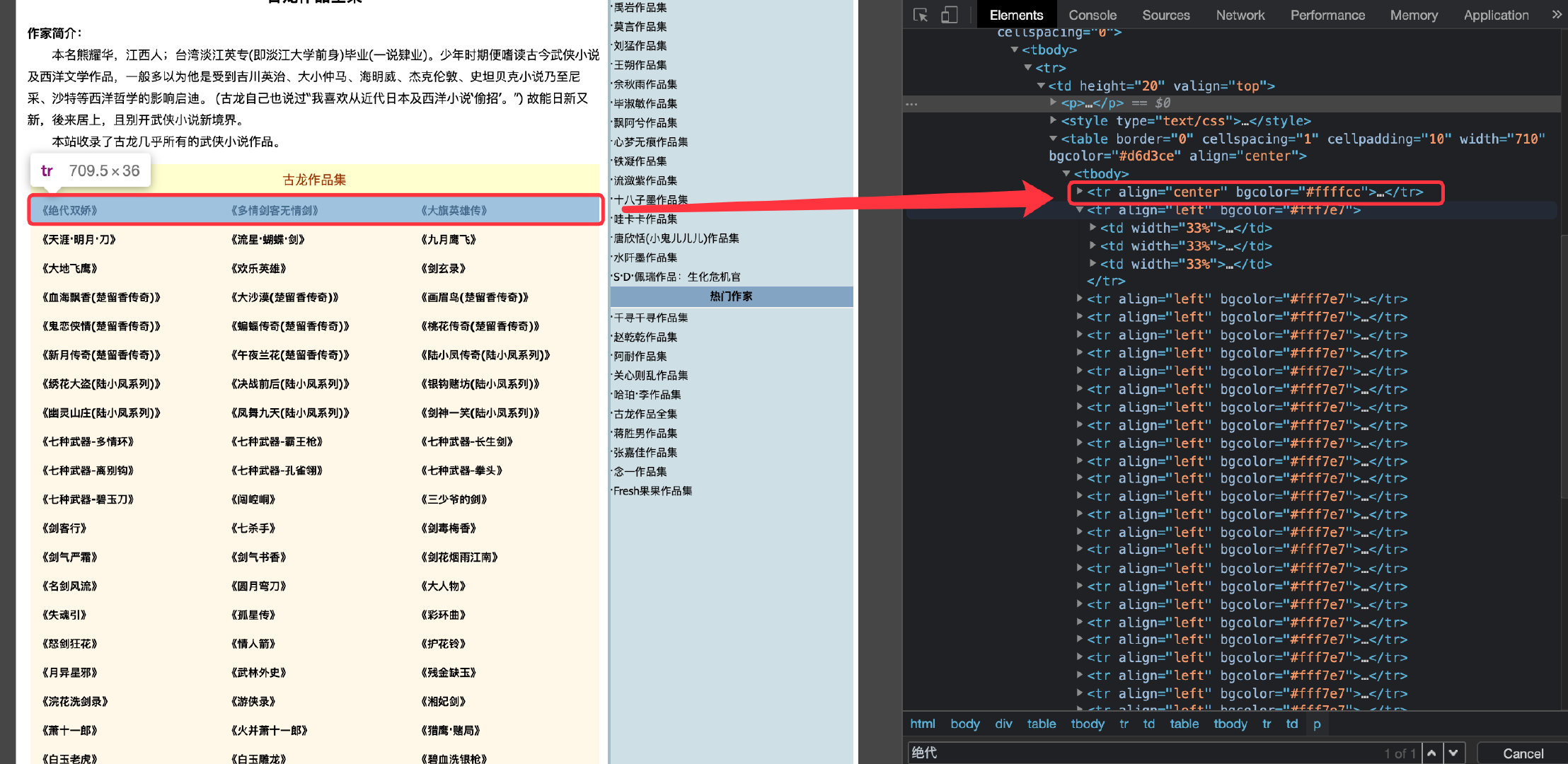
每个tr标签下面有3个td标签,代表3个小说,一个td包含地址和名称
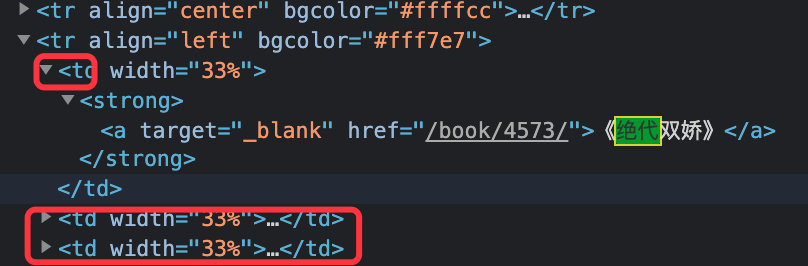
获取网页源码
发送网页请求获取到源码
import requests
from lxml import etree
import pandas as pd
url = 'https://www.kanunu8.com/zj/10867.html'
headers = {'user-agent': '请求头'}
response = requests.get(url = url,headers = headers)
result = response.content.decode('gbk') # 该网页需要通过gbk编码来解析数据
result

获取信息
1、获取每个小说的专属链接地址
tree = etree.HTML(result)
href_list = tree.xpath('//tbody/tr//a/@href') # 指定属性的信息
href_list[:5]

2、获取每个小说的名称
name_list = tree.xpath('//tbody/tr//a/text()') # 指定标签下面的全部内容
name_list[:5]

3、生成数据帧DataFrame
# 生成古龙小说的地址和名称
gulong = pd.DataFrame({
"name":name_list,
"url":href_list
})
gulong

4、完善URL地址
实际上每个小说的URL地址是有一个前缀的,比如绝代双骄的完整地址:https://www.kanunu8.com/book/4573/
gulong['url'] = 'https://www.kanunu8.com/book' + gulong['url'] # 加上公共前缀
gulong
# 导出为excel文件
gulong.to_excel("gulong.xlsx",index=False)

以上是关于一文搞定强大的爬虫数据解析工具-Xpath的主要内容,如果未能解决你的问题,请参考以下文章