Java 黑科技——Serviceability Agent
Posted Qunar技术沙龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 黑科技——Serviceability Agent相关的知识,希望对你有一定的参考价值。
作者简介
潘志超
2017年加入去哪网机票事业部,负责国内售后、行程单相关业务以及机票订单实时同步 ES 平台,对 java 后端技术有浓厚兴趣,乐于刨根问底,从底层了解技术内幕,勇于探索和实践,并不断追求极致。
1 预期收获
掌握通过 SA 窥探 JVM 内部机制的方法
JVM 内存模型与执行引擎 & linux 进程内存布局
JVM oop/klass 二分模型
JIT 工作原理及源码分析
字节码指令执行流程源码分析
jmap、jstack 等底层实现
Java SA 工作原理
2 背景

微服务架构之下,伴随着业务高速迭代,系统数量和单个系统内代码数量急速膨胀,每一个系统都已经沦为或正在沦为一个个臃肿的胖子,系统内充斥着越来越多的无用代码,更有甚者整个系统都可以下线,而负责维护的开发同学却浑然不知。随着时间的推移,历史包袱越来越重,系统瘦身/系统下线的诉求越来越迫切,今年1024程序员节,公司举办的 hackathon大赛,“系统瘦身利器”作为大赛题目被提出,本人有幸作为出题人&评委参与了答辩过程,参与的4个团队给出的方案各有千秋,最后大奖被 qunar tc 代表队通过提出基于 Java SA 的解决方案,实现弯道超车,斩获冠军。
一句话概括最终胜出的的下线方案核心思路:基于 SA 获取 JVM 中的方法调用数据,实现零侵入业务系统获取可下线代码。Java SA 是如何做到的呢?其实现原理让我产生了浓厚的兴趣,探索的过程中发现网上的资料极少,也无详细官方文档,只能通过啃源码才能了解一二,过程中个人收获颇丰,谨以此文记录整个探索过程,希望对其他想了解 Java SA 的同学提供些帮助,同时通过对 SA 的使用,向大家介绍一个深入了解 JVM 内部运行时数据及内部实现机制的利器。以下内容为个人理解,如有描述不当之处,欢迎指出。
3 源码准备
3.1 源码与用途概述
HotSpot 项目主体是由 C++ 实现的,并伴有少量 C 代码和汇编代码。幸运的是 SA 及其他 Agent 由 Java 代码实现,这为我们阅读代码提供了便利,但追到底层还是避免不了啃 C++ 代码,本文涉及到的源码如下:
1、Java SA 所在 jar 名称:sa-jdi.jar,非标准 java api,需在 openjdk 上下载源码后关联 idea,源码位置:hotspot/agent/src/share/classes,maven 依赖:
<dependency><groupId>jdk</groupId><artifactId>sa-jdi</artifactId><version>1.8</version></dependency>
2、jmap、jstack 等 jdk 自带工具相关,源码位置:jdk/src/share/classes/sun/tools/
3、对象、类、方法在 JVM 中的表示相关,源码位置:hotspot/src/share/
4、进程及进程虚拟内存相关,源码位置:linux-2.6.0/include/linux/
3.2 源码下载
openjdk 源码下载:http://hg.openjdk.java.net/jdk8
linux 源码下载:https://mirrors.edge.kernel.org/pub/linux/kernel/v4.x/
4 Java SA 概述
翻译自 openjdk 和 usenix:
SA 全称 Serviceability Agent,是 HotSpot 工程师开发的一套可用于调试的 Sun 公司私有组件,通过 SA 可以在运行的 java 进程或 java core 文件中,获取 Java 对象和虚拟机内部数据结构。SA 是 hotSpot 虚拟机提供的若干进程间通信技术中的一个,另一个被我们高频使用的进程间通讯方式是 dynamic attach,两者的特点及区别如下:
| 执行机制 |
是否会对目标进程产生影响 |
jdk版本间差异 |
|
| SA |
直接读取目标进程的操作系统层面的内存数据 | 否 |
较大 |
| attach |
client/server 交互模型,与目标进程建立 socket 连接,目标进程处理后回传客户端 | 是 | 较小 |
SA 与 attach 及其他进程间通信技术最大的不同在于:不需要在目标 VM 中运行任何代码,SA 使用操作系统提供的符号查找和进程内存读取等原语实现。
要理解 SA,需要铺垫一些其他知识,包括:
1)JVM 内存模型及执行引擎 & linux 进程内存布局 2)JVM oop/klass 二分模型 3)JIT 即时编译机制
有趣的是,借助 SA 窥探 JVM 内存数据,又可以反过来帮我们更深入的了解这些知识的底层实现。
5 JVM 内存模型及执行引擎 & linux 进程内存布局
5.1 JVM 内存模型及执行引擎
图1为 JVM 内存模型和执行引擎,JVM 内存模型包含线程共享的堆、元数据空间以及线程独享的虚拟机栈、本地方法栈和程序计数器。执行方式包括解释执行和编译执行,执行过程中 JVM 会触发垃圾回收。

图1
该模型在不同的操作系统及 cpu 架构之上抽象出了更加普适的运行机制,以此达成了 java 语言的跨平台及语言本身最大程度的简单化。但鱼与熊掌不可兼得,JVM 隔离了 java 进程和操作系统,这在一定程度上为 java 程序员了解操作系统底层或硬件底层制造了障碍,本章的核心 Java SA 就是偏操作系统层面的内容,但是大可不必过度担忧,从 JVM 为语言的运行时提供支撑功能来看,虚拟机是 Java 语言的“系统程序”,但从本质上来说,它只是一个运行在操作系统上的普通应用程序而已。所以基于 JVM 运行的 java 程序的所有内存模型类型划分,归根揭底还是要落到 linxu 进程上。后续讨论以 linux 操作系统作为默认的操作系统。
5.2 linux 进程内存布局
在 linux 中,每个进程都被抽象为一个 c++ taskstruct 结构体,称为进程描述符(源码位置:linux-2.6.0/include/linux/sched.h),存储着进程的所有信息,mmstruct 是其中一个属性,管理着进程的所有内存信息,是今天我们要探讨的重点,以下为 mm_struct 结构体部分代码:
以下代码摘自:invocationCounter.hpp
struct mm_struct {struct vm_area_struct * mmap; //指向虚拟区间(VMA)的链表struct rb_root mm_rb; /* 指向vma组成的红黑树跟节点 *///start_code 可执行代码的起始地址//end_code 可执行代码的最后地址//start_data已初始化数据的起始地址//end_data已初始化数据的最后地址unsigned long start_code, end_code, start_data, end_data;//start_stack堆的起始位置//brk堆的当前的最后地址//用户堆栈的起始地址unsigned long start_brk, brk, start_stack;...
由代码可知 linux 中进程内存布局如下:
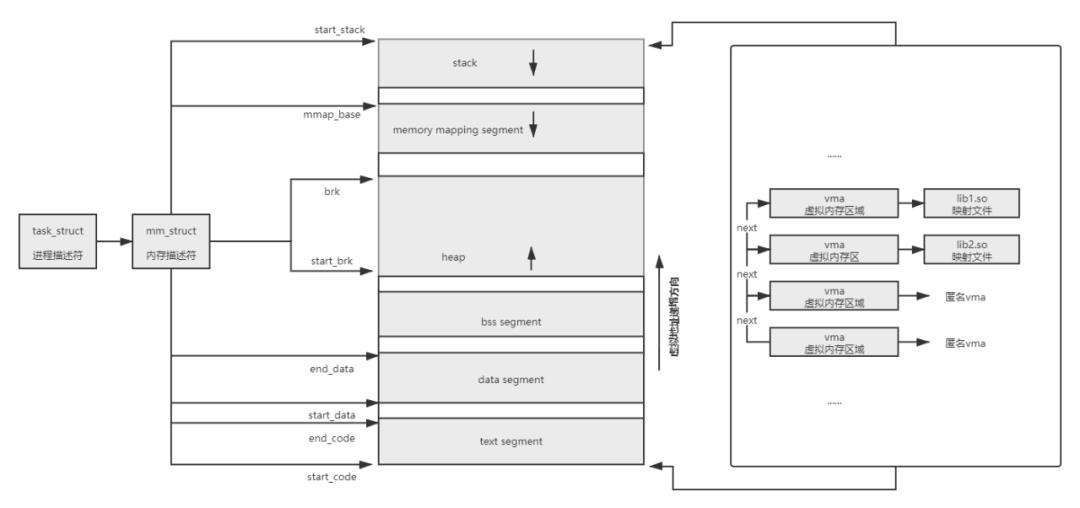
图2
其中包含:1)代码段 Text segment:存储可执行代码 2)数据段data segment:存储已初始化的全局静态变量 3)BSS 段:存储未初始化的全局静态变量 4)堆 heap:存储 malloc 分配内存后 new 出的对象,从下往上增长,可以在运行时动态扩展或收缩 5)栈 stack:存储方法调用上下文,通常较小,典型值为数8MB,从上往下增长 6)内存映射区:动态库、共享内存等映射物理空间的内存,该区域用于映射可执行文件用到的动态链接库
每一个内存区域都是由一个或多个虚拟内存访问区(vma)构成的,vma 使用两个数据结构存储:单向链表和红黑树中,以此达到快速访问的目的:注意(6)内存映射区,若当前进程依赖共享库,则系统会为这些共享库在内存映射区分配相应空间,并在程序装载时将其载入到该空间。java 中使用动态加载的方式加载 JVM 自己的链接共享库,核心链接共享库是 libjvm.so,SA 正式通过该链接共享库获取符号表中的全局变量,并以此为切入点获取 JVM 中的运行时数据的,后续"Java SA 运行机制"章节会详细介绍。
6 JVM oop/klass 二分模型
6.1 oop/klass 二分模型概述
java 世界中一切皆对象,Java SA 通过对目标进程内存数据建模,获取到运行时数据,要搞清楚 SA 就必须把对象在 JVM 中如何存储搞清楚,这里就引入了oop/klass 二分模型,为了更容易理解,我们以下面的一段代码为例:
package com.qunar.sa;/*** Date:Create at 2020/12/16 17:36* Description:目标进程代码,目的是观察类及对象内存分布,* 主要逻辑:* 1)创建一个Student对象,并调用setId设置id值* @author zhichao.pan*/public class TargetProcess {public static void main(String[] args) throws Exception{int id = 1;Student student = new Student();student.setId(id);//为方便通过SA观察结果,睡眠10000000Thread.sleep(10000000 * 1000);}static class Student{private static int type = 10;private int id;public void setId(int id) {this.id = id;}void JITTest1(){System.out.println(this.id);}void JITTest2(){System.out.println(this.id);}void JITTest3(){System.out.println(this.id);}}}
student.setId(id); 执行完成后,JVM 中会创建以下两个 C++对象:1)Klass 对象:如果当前类是首次加载,会创建一个 InstanceKlass,包括常量池、字段、方法等,保存在原空间。
2)OopDesc 对象:创建一个 instanceOopDesc 对象,其中包含指向对应(1)中创建的 Klass 对象的指针,该对象保存在堆区,而当前对象的指针保存在栈区。
以上两个对象在 JMM 中的表示如下图:
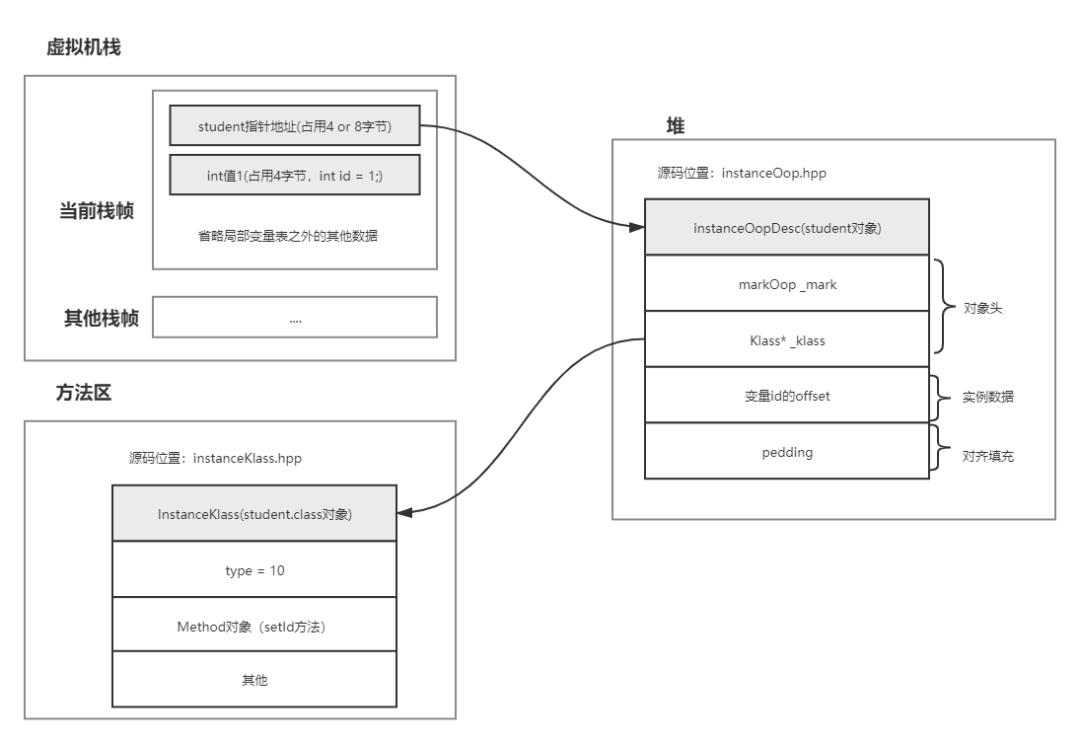
volatile markOop _mark; //对象头中的mark worldunion _metadata { //类指针,当JVM工作在64位机器且开启指针压缩之后,则使用的指针为压缩指针Klass* _klass;narrowKlass _compressed_klass;} _metadata;// field addresses in oopvoid* field_base(int offset) const; //实例数据基础方法,每个field在oop中都有一个对应的偏移量(offset),oop通过该偏移量得到该field的地址,再根据地址得到具体数据。...
6.2 基于 SA 窥探类和对象数据(可视化工具方式)
jdk 提供了两种通过 SA 访问数据的方式:可视化工具和代码方式,此处简要说明如何使用可视化工具,观察 JVM 运行时类和对象数据,接下来的章节:JIT 即时编译机制部分,会介绍第二种,即:如何通过代码获取数据。
以以上代码为例,执行 TargetProcess 的 main 方法,获取进程 pid,然后执行:
E:jdk8u261injava -cp E:jdk8u261libsa-jdi.jar sun.jvm.hotspot.HSDB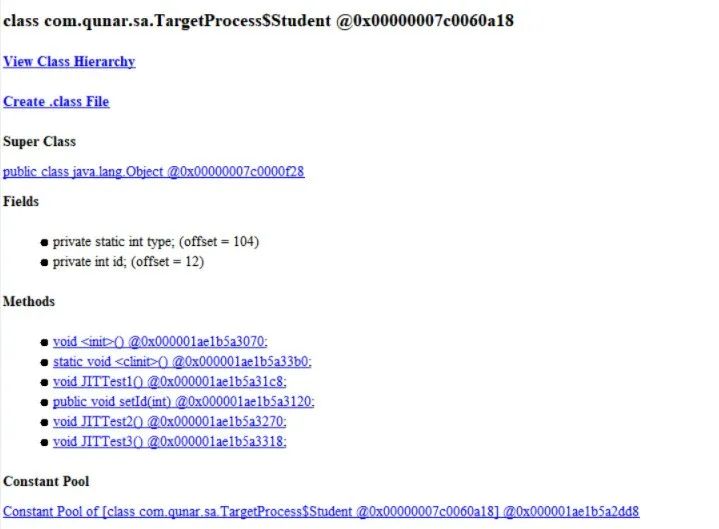

7 JIT 即时编译机制
背景部分说到过我们通过 SA 获取 JVM 中的方法调用数据,从而判断代码是否可下线。有两个问题需要搞清楚:
(1)JVM 为什么会统计方法调用信息?
(2)统计的调用信息准确吗?
第一个问题:JVM 为什么会统计方法调用信息?应该很容易猜到,JVM 使用方法调用统计,将部分高频执行的代码编译为本地机器码,实现 JIT 编译,而想搞清楚第二个问题却没有那么容易,必须深入分析 JIT 执行机制才能知其所以然。
7.1 方法调用信息存储
方法调用信息存储与上文说的 oop/klass 二分模型中的 Klass 息息相关,Klass 中包含了所有类相关信息,而类中包含方法,所以自然也包含了方法调用统计信息,涉及的源码文件、类及变量如下,感兴趣可以直接查看源码。
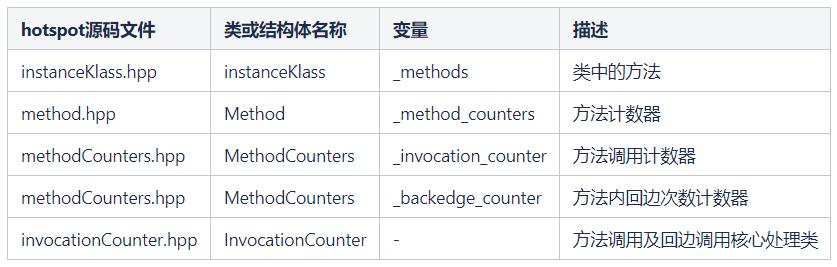
7.2 热编译触发
JVM 为了提高程序执行效率,会在运行时动态执行热编译,将部分高频执行的代码编译为本地机器码。触发方式有以下两类:
(1)方法调用计数器触发:如果方法调用统计达到编译阈值,则对该方法执行编译,这种编译是一个异步的过程,它允许程序在代码正在编译时继续通过解释方式执行,编译完成后将生成的机器码存入 code cache,后面的调用可直接使用。这种编译方式叫做标准编译。
(2)回边计数器触发:在字节码中遇到控制流向后跳转的字节码指令称为”回边“,如 for、while 等。一个方法内回边操作发生时,回边计数器都会自增和自检。回边计数器计数超出其自身阈值时,当前方法获得被编译资格。编译发生时 JVM 仍然通过解释方式执行循环体,编译完成后,下一次循环迭代则会执行新编译的代码。这种编译方式叫做 OSR(栈上替换)。
7.3 热度衰减
现在我们来探讨下本节开始的第二个问题:jvm 统计的方法调用次数准确吗?我们先给出结论:方法调用计数器统计的并不是方法被调用的绝对次数。
当超过一定的时间限度,如果方法的调用次数仍然不足以触发编译,该方法的调用计数就会被减少一半,这个过程称为方法调用计数器热度衰减,而这段时间就称为此方法统计的半衰周期。那么问题来了,既然方法调用计数器统计的并非方法调用的绝对次数,我们还能不能通过判断调用次数为0,从而做出该方法可下线的判断呢?源码面前无秘密。
以下代码摘自:invocationCounter.hpp
代码片段1:private: // bit no: |31 3| 2 | 1 0 |unsigned int _counter; // format: [count|carry|state]enum State {wait_for_nothing, // do nothing when count() > limit()wait_for_compile, // introduce nmethod when count() > limit()number_of_states // must be <= state_limit};代码片段2:inline void InvocationCounter::decay() {//热度衰减int c = count();int new_count = c >> 1;// prevent from going to zero, to distinguish from never-executed methodsif (c > 0 && new_count == 0) new_count = 1;set(state(), new_count);}
代码片段1解析:
每一个方法都会对应一个方法调用计数器,为了尽可能节省内存空间,JVM 中将 counter、carry、state 三个字段用一个32位 int 类型数据表示,如代码所示,其中:
counter:第3-31位表示方法调用计数,每次方法调用+1,超过半衰周期未触发编译则数据减半,触发编译后调用 reset 方法重置 InvocationCounter 所有数据。
carry:第2位表示当前方法是否已被编译,方法调用计数器达到阈值并触发编译动作后,carry 被设置为1,表示该方法已被编译。
state:第0位和第1位表示超出阈值时的处理,枚举值如源码中 enum State,waitfornothing 表示方法调用次数超过阈值后不触发编译,waitforcompile 表示方法调用次数超过阈值后触发编译。
代码片段2解析:
通过将调用次数做移位运算,实现热度减半,减半之后的数据如等于0则将调用次数设置为1,以此来区分从未执行的方法。
再回头看下我们要解决的问题,虽然调用次数并不准确,但已执行过的方法不可能为0,通过这种方式可以达到判断代码是否可下线的目的。
7.4 回边计数器统计原理
下面通过一段代码,分析回边计数器如何统计,并以此讲清楚 jvm 执行机制。代码如下:
public class TestSum{public static void main(String[] args) {int sum = 0;for(int i=0 ; i< 100; i++){sum += i;}}}
java 代码-TestSum.java:
先执行 javac TestSum.java 将源码转换为字节码,然后执行 javap -v -l TestSum.class 查看生成的字节码内容,结果如下:
public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=3, args_size=10: iconst_0 将常量0放到栈顶1: istore_1 将栈顶的int变量放到本地变量表中索引为1的位置,即将0赋值给sum2: iconst_0 将常量0放到栈顶3: istore_2 将栈顶的int变量放到本地变量表中索引为2的位置,即将0赋值给i4: iload_2 将本地变量表中索引为2的变量放到栈顶,即将i=1放入栈顶5: bipush 100 将byte类型100放到栈顶7: if_icmpge 20 会比较栈顶的两个值,如果变量i>=100时会跳转到偏移量是20的指令处,否则继续执行下一条字节码10: iload_1 将本地变量表中索引为1的变量放到栈顶,即将sum放入栈顶11: iload_2 将本地变量表中索引为2的变量放到栈顶,即将i放入栈顶12: iadd 将栈顶两个元素求和,将结果放入栈顶,即sum+i放入栈顶13: istore_1 将栈顶的int变量放到本地变量表中索引为1的位置,即将sum+i赋值给sum14: iinc 2, 1 将本地变量中索引为2的变量自增1,即变量i的自增17: goto 4 跳转到偏移量是4的指令处20: return 方法返回
从上述字节码分析可知,for 循环是通过 goto 指令实现跳转的,下面通过 bytecodeInterpreter 字节码解释器来分析 goto 字节码指令如何实现。
这里解释下 bytecodeInterpreter 字节码解释器,hotspot 实现了两种解释器,即:模板解释器(TemplateInterpreter)和 C++字节码解释器(CppInterpreter、BytecodeInterpreter),其中模板解释器(TemplateInterpreter)是 hotspot 使用的默认解释器,使用汇编语言实现,而 C++字节码解释器使用 C++语言实现,后者为我们阅读源码提供了极大的便利,简单的说 TemplateInterpreter 是将 BytecodeInterpreter 字节码的执行语句从 c/c++代码换成汇编代码而来的。相较模板解释器,字节码解释器的可读性更好。所以我选择通过后者讲清楚回边计数器如何做计数统计。
以下代码摘自:bytecodeInterpreter.cpp
代码片段1:CASE(_goto):{int16_t offset = (int16_t)Bytes::get_Java_u2(pc + 1);address branch_pc = pc;UPDATE_PC(offset);DO_BACKEDGE_CHECKS(offset, branch_pc);CONTINUE;}代码片段2:#define DO_BACKEDGE_CHECKS(skip, branch_pc)...mcs->backedge_counter()->increment(); 回边统计数+1if (do_OSR) do_OSR = mcs->backedge_counter()->reached_InvocationLimit(); 判断是否到达回边技术编译阈值if (do_OSR) {nmethod* osr_nmethod;OSR_REQUEST(osr_nmethod, branch_pc); 达到阈值则执行提交OSR编译请求if (osr_nmethod != NULL && osr_nmethod->osr_entry_bci() != InvalidOSREntryBci) {intptr_t* buf = SharedRuntime::OSR_migration_begin(THREAD);istate->set_msg(do_osr);istate->set_osr_buf((address)buf);istate->set_osr_entry(osr_nmethod->osr_entry());return;}}...}
7.5 基于 SA 窥探 JIT 相关数据(代码方式)
我们来看下通过写代码的方式,如何借助 SA 机制观测 JIT 相关数据,包括调用信息及已被 JIT 编译的方法信息,代码及注释如下(篇幅问题,代码不规范,目的是说明核心逻辑):
目标进程代码:
package com.qunar.sa;/*** Date:Create at 2020/12/16 17:36* Description:目标进程代码,目的是观察方法调用情况* 主要逻辑:* 1)创建一个Student对象,并调用setId设置id值* 2)对测试的三个方法执行100、1000、10000次的调用* @author zhichao.pan*/public class TargetProcess {public static void main(String[] args) throws Exception{int id = 1;Student student = new Student();student.setId(id);for (int i = 0; i < 100; i++){student.JITTest1();}for (int i = 0; i < 1000; i++){student.JITTest2();}for (int i = 0; i < 100000; i++){student.JITTest3();}//为方便通过SA观察结果,睡眠10000000Thread.sleep(10000000 * 1000);}static class Student{private static int type = 10;private int id;public void setId(int id) {this.id = id;}void JITTest1(){System.out.println(this.id);}void JITTest2(){System.out.println(this.id);}void JITTest3(){System.out.println(this.id);}}}
package com.qunar.sa;......省略import部分代码/*** Date:Create at 2020/12/16 17:36* Description:目标进程代码,目的是观察对象内存分布* 主要逻辑:* 1)创建一个Student对象,并调用setId设置id值* 2)对测试的三个方法执行100、1000、10000次的调用** @author zhichao.pan*/public class SAProcess {public static void main(String[] args) throws ParseException {int pid = 20408 ;HotSpotAgent agent = new HotSpotAgent();//对目标进程执行SAagent.attach(pid);try {final Set<MethodDefinition> methodResult = new HashSet<>();VM.getVM().getSystemDictionary().allClassesDo(new InvocationCounterVisitor(methodResult));System.out.println("SA遍历方法执行信息:" + JacksonSupport.toJson(methodResult));final Set<MethodDefinition> compiledMethodResult = new HashSet<>();VM.getVM().getCodeCache().iterate(new CompiledMethodVisitor(compiledMethodResult));System.out.println("SA遍历热编译数据:" + JacksonSupport.toJson(compiledMethodResult));} finally {//释放SAagent.detach();}}//SA获取方法调用数据static class InvocationCounterVisitor implements SystemDictionary.ClassVisitor {private final Set<MethodDefinition> result;public InvocationCounterVisitor(Set<MethodDefinition> result) {this.result = result;}@Overridepublic void visit(Klass klass) {final String klassName = klass.getName().asString();//类全限定名if (klassName.contains("Student")) { //此处只关注目标进程的Student类final MethodArray methods = ((InstanceKlass) klass).getMethods();//该类下的方法for (int i = 0; i < methods.length(); i++) {final Method method = methods.at(i);long invocationCount = method.getInvocationCount(); //遍历获取执行次出//这个操作很关键,上面介绍过这个点:_counter包括三部分:// 第3-31位表示执行次数,第2位表示是否已被编译1为编译,第0位和第1位表示超出阈值时的处理,默认情况为01即超出阈值执行编译// 右移三位的目的是统计出执行次数信息invocationCount = invocationCount >> 3;result.add(new MethodDefinition(klassName, method.getName().asString(),method.getSignature().asString(),invocationCount));}}}}//SA获取已被JIT编译的类及方法信息static class CompiledMethodVisitor implements CodeCacheVisitor {private final Set<MethodDefinition> result;@Overridepublic void visit(CodeBlob codeBlob) {//codeBlob为jit编译后的代码在内存中的对象表示final NMethod nMethod = codeBlob.asNMethodOrNull();if(nMethod == null ) return;final Method method = nMethod.getMethod();final String className = method.getMethodHolder().getName().asString();//类名final String name = method.getName().asString();//方法名final String signature = method.getSignature().asString();//方法参数long invocationCount = method.getInvocationCount();//调用次数//右移三位的目的同InvocationCounterVisitorinvocationCount = invocationCount >> 3;if(className.contains("Student")){result.add(new MethodDefinition(StringUtils.replace(className, "/", "."), name,SignatureUtils.convertToSourceType(signature), invocationCount));}}@Overridepublic void epilogue() {}public CompiledMethodVisitor(Set<MethodDefinition> result) {this.result = result;}@Overridepublic void prologue(Address address, Address address1) {}}static class MethodDefinition {public String className;//类名public String methodName;//方法名public String parameters;//方法参数public long invocationCount;//方法调用次数public MethodDefinition(String className, String methodName, String parameters, long invocationCount) {this.className = className;this.methodName = methodName;this.parameters = parameters;this.invocationCount = invocationCount;}}}
SA遍历方法执行信息:[{"className":"com/qunar/sa/TargetProcess$Student","methodName":"<init>","parameters":"()V","invocationCount":1},{"className":"com/qunar/sa/TargetProcess$Student","methodName":"JITTest1","parameters":"()V","invocationCount":100},{"className":"com/qunar/sa/TargetProcess$Student","methodName":"JITTest3","parameters":"()V","invocationCount":275},{"className":"com/qunar/sa/TargetProcess$Student","methodName":"JITTest2","parameters":"()V","invocationCount":512},{"className":"com/qunar/sa/TargetProcess$Student","methodName":"setId","parameters":"(I)V","invocationCount":1}]SA遍历热编译数据:[{"className":"com.qunar.sa.TargetProcess$Student","methodName":"JITTest3","parameters":"","invocationCount":275},{"className":"com.qunar.sa.TargetProcess$Student","methodName":"JITTest2","parameters":"","invocationCount":512}]
由以上执行结果可以反过来验证上面对 JIT 运行机制的分析,如:
1)int 型数据_counter 包括三部分,第3-31位表示执行次数,第2位表示是否已被编译1为编译,第0位和第1位表示超出阈值时的处理,默认情况为01即超出阈值执行编译,我们需要通过将 _counter 右移三位才能获取方法调用次数。
2)短时间内小于编译阈值的调用次数是准确的,如以上代码对 JITTest1 的调用
3)JVM 中的方法统计并非准确的调用次数,两个原因导致统计不准确:
触发 JIT 之后解释执行转换为编译执行,不再进行方法统计。
方法次数存在热度衰减机制。
8 jmap、jstack 等 Tools 工具实现原理
其实,Java SA 离我们并不遥远,你是否用过 jmap、jstack、jinfo 等 jdk 自带的命令行工具?如果是那你可能已经在使用 Java SA 了,为什么说可能,是因为 jmap 等工具内置两种实现方式:attach 方式和 SA 方式。下面以 jmap 为例通过源码来分析如何选择这两种机制:
以下代码摘自:jdk/src/share/classes/sun/tools/jmap/JMap.java
/** This class is the main class for the JMap utility. It parses its arguments* and decides if the command should be satisfied using the VM attach mechanism* or an SA tool. At this time the only option that uses the VM attach mechanism* is the -dump option to get a heap dump of a running application. All other* options are mapped to SA tools.*/public class JMap {// Options handled by the attach mechanismprivate static String HISTO_OPTION = "-histo";private static String LIVE_HISTO_OPTION = "-histo:live";private static String DUMP_OPTION_PREFIX = "-dump:";// These options imply the use of a SA toolprivate static String SA_TOOL_OPTIONS ="-heap|-heap:format=b|-clstats|-finalizerinfo";// The -F (force) option is currently not passed through to SAprivate static String FORCE_SA_OPTION = "-F";
当参数带有-F 或-heap|-heap:format=b|-clstats|-finalizerinfo 时使用 Java SA 获取数据,参数带有-histo、-histo:live、-dump:时通过 attach 机制获取数据。这两种方式都是 hotspot JVM 为我们提供的进程间通信方式,实现机制却大相径庭。
8.1 attach 方式
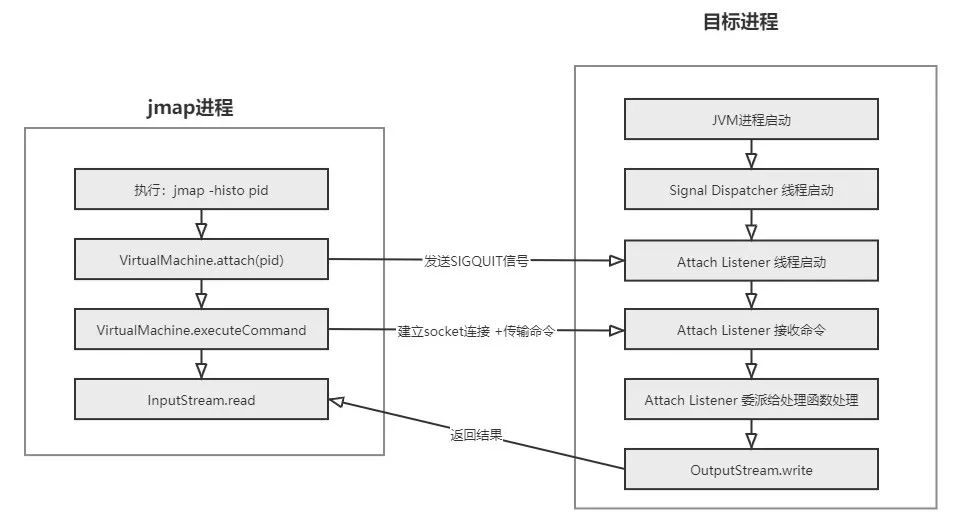
采用“协作”模型,目标 JVM 启动时会启动 Signal Dispatcher 守护线程,jmap 命令执行时底层调用了 com.sun.tools.attach.VirtualMachine.attach(pid),jmap 进程会发出 SIGQUIT 信号,Signal Dispatcher 线程收到信号后就会创建 Attach Listener 线程,后续 jmap 进程继续执行com.sun.tools.attach.VirtualMachine.executeCommand,此时两个进程建立 socket 连接,jmap 进程发送命令(对于 jmap -histo 发送的命令为:"inspectheap"),Attach Listener 线程接受该命令并委派给对应的函数执行处理,处理完成后通过 socket 写回,jmap 进程读取后展示到控制台。整体交互流程如下:
8.2 SA 方式
SA 机制不需要与进程互动,通过直接分析目标进程的内存布局获取目标 JVM 进程的运行时对象数据,jmap -heap 的调用流程如下:

下一个章节会围绕 SA 做详细分析。
9 Java SA 运行机制
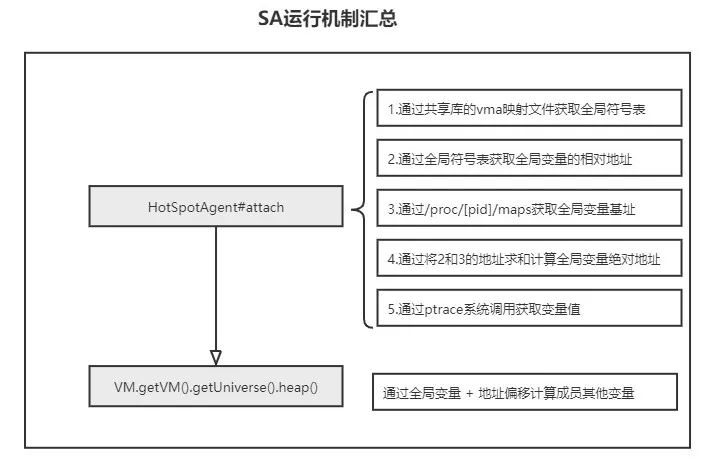
9.1 SA 获取数据步骤
本小节通过一个运行的 pid 为11063的 Java 进程来探索 Java SA 底层运行机制,通过 Java SA 获取数据主要包括以下步骤:
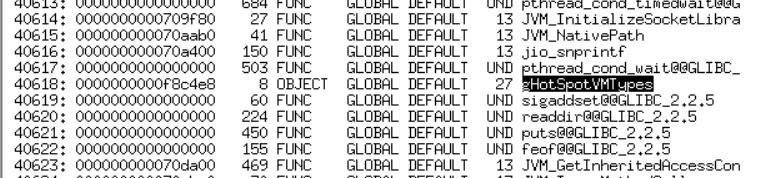
1)一个 java 进程运行时会通过动态加载的方式加载 JVM 自己的动态共享库,JVM 的核心链接共享库是 libjvm.so,共享库使用 ELF 格式,运行时内核会把 ELF 加载到用户空间,其中就包含该共享库提供的符号表,符号表中记录了这个模块定义的可以提供给其他模块引用的全局符号。我们可以使用 linux 提供的 readelf 命令获取符号表,执行的命令及输出如下:
命令:
readelf -s /home/q/java/jdk1.8.0_60/jre/lib/amd64/server/libJVM.so|less
命令:sudo cat /proc/11063/maps |grep libJVM.so|less
7f4dfc945000-7f4dfd603000 r-xp 00000000 fc:07 1183253 /home/q/java/jdk1.8.0_60/jre/lib/amd64/server/libJVM.so7f4dfd603000-7f4dfd802000 ---p 00cbe000 fc:07 1183253 /home/q/java/jdk1.8.0_60/jre/lib/amd64/server/libJVM.so7f4dfd802000-7f4dfd8da000 rw-p 00cbd000 fc:07 1183253 /home/q/java/jdk1.8.0_60/jre/lib/amd64/server/libJVM.so
vma 数据结构如下:以下代码摘自:/include/linux/mm.h
struct vm_area_struct {struct mm_struct * vm_mm; /* 属于地址空间 */unsigned long vm_start; /* 开始地址(虚拟) */unsigned long vm_end; /* 结束地址(虚拟)*/struct vm_area_struct *vm_next;/* linked list of VM areas per task, sorted by address */pgprvm_page_ot; /* Access permissions of this VMA. */unsigned long vm_flags; /* Flags, listed below. */... 此处省略部分源码struct file * vm_file; /* 该vma映射的文件 */};
5)JVM 主要用 C++ 实现,其中的类多种多样、种类繁多,要实现进程间通讯,一个不得不考虑的问题就是:如何将如此众多的 C++ 类使用通用的数据结构在内存中表示出来,进而通过 SA 机制读取后转换为 Java 对象,解释这个问题就不得不提两个极其重要的 C++ 结构体:VMStructEntry 和 VMTypeEntry,和一个极其重要的 C++ 类:VMStructs,上述问题正是通过这两个结构体巧妙的解决的,代码位于:hotspot/src/share/vm/runtime/vmStructs.hpp
示例代码:class SystemDictionary {// Hashtable holding loaded classes.static Dictionary* _dictionary;VMStructEntry和VMTypeEntry结构体中的注释以上面示例代码作为分析对象:typedef struct {const char* typeName; // 当前变量所属的类名称,如SystemDictionaryconst char* fieldName; // 当前变量名称,如_dictionaryconst char* typeString; // 当前变量类型名称,如Dictionaryint32_t isStatic; // 当前变量是否为静态变量,如 是uint64_t offset; // 当前变量在所属对象的偏移量,仅用于非静态变量,下方示例代码中该字段无意义void* address; // 当前变量所在的虚拟地址,仅用于静态变量,如 0000000000f8c4e8为该变量所在的绝对地址} VMStructEntry;typedef struct {const char* typeName; // 当前类型类名称,如SystemDictionaryconst char* superclassName; // 当前类型父类名称,如果没有父类,则为nullint32_t isOopType; // 当前类型是否是否是一个对象类型int32_t isIntegerType; // 当前类型是否是否是一个Integer类型int32_t isUnsigned; // 当前类型如果是一个Integer类型,是否无符号数uint64_t size; // 当前类型占用字节数} VMTypeEntry;
使用 VMTypeEntry 和 VMStructEntry 的代码 在hotspot/src/share/vm/runtime/vmStructs.cpp 中,部分核心注释及代码如下:
注释1:// NOTE: there is an interdependency between this file and// HotSpotTypeDataBase.java, which parses the type strings.注释2:// This list enumerates all of the fields the serviceability agent// needs to know about.代码:static_field(SystemDictionary, _dictionary, Dictionary*)...
hotspot 实现中的 vmStructs.cpp 和 Java SA 中的 sun.JVM.hotspot.HotSpotTypeDataBase 互相依赖,vmStructs.cpp 列出了所有可以通过 Java SA api 获取到的 JVM 数据,获取方法就是调用 HotSpotTypeDataBase 中的方法,依然以上面 SystemDictionary 部分的示例代码为例,使用 Java SA 获取 JVM 中_dictionary 对象的代码如下:
private static synchronized void initialize(TypeDataBase db) {//db即为sun.JVM.hotspot.HotSpotTypeDataBaseType type = db.lookupType("SystemDictionary");dictionaryField = type.getAddressField("_dictionary");
9.2 SA 数据获取步骤总结
参考文献
usenix 对 Java SA 的介绍:https://static.usenix.org/event/JVM01/fullpapers/russell/russellhtml/
openjdk 对 Java SA 的介绍:http://openjdk.java.net/groups/hotspot/docs/Serviceability.html
读取动态链接共享库文件中的符号表:https://blog.csdn.net/raintungli/article/details/7289639
END
以上是关于Java 黑科技——Serviceability Agent的主要内容,如果未能解决你的问题,请参考以下文章
Android简易音乐重构MVVM Java版-新增歌曲播放界面+状态栏黑科技(十七)
Android简易音乐重构MVVM Java版-新增歌曲播放界面+状态栏黑科技(十七)