ClickHouse安装使用Centos7环境
Posted handler-刘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse安装使用Centos7环境相关的知识,希望对你有一定的参考价值。
前言
列式存储数据库DBMS,比mysql等面向行的数据库有查询优势,同时又比同样属于面向列DBMS的更有效的节省空间(不适用固定大小存储数据),使用数据压缩后,可以传输更多,延迟小等。
提示:以下是本篇文章正文内容,下面案例可供参考
一、ClickHouse是什么?
Clickhouse由俄罗斯Yandex公司开源的数据库,专为OLAP而设计。 Yandex是俄罗斯最大的搜索引擎公司,官方宣称ClickHouse 日处理记录数”十亿级”。发布之初跑分要超过很多流行的商业MPP数据库软件,官方的性能测试显示比vertica快5倍,比GP快10倍。
官方中文文档:https://clickhouse.tech/docs/zh/
二、使用步骤
1.安装(RPM安装包 )
首先,您需要添加官方存储库
yum install yum-utils
rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64

查看可安装的软件包
yum list clickhouse*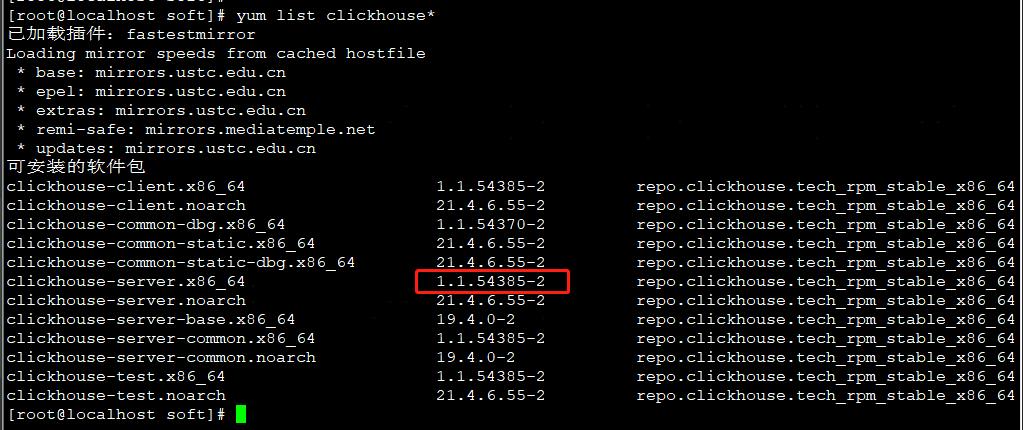
然后运行命令安装
// 全部安装
yum install clickhouse-*
// 只安装servcer 和 client
yum install clickhouse-server clickhouse-client配置目录权限 归属 clickhouse ,不能使用root运行
chown -R clickhouse:clickhouse /var/lib/clickhouse
chown -R clickhouse:clickhouse /var/log/clickhouse-server
chown -R clickhouse:clickhouse /etc/clickhouse-server
启动....
sudo -u clickhouse clickhouse-server --daemon --pid-file=/var/run/clickhouse-server/clickhouse-server.pid --config-file=/etc/clickhouse-server/config.xml
--daemon 标志我们要后台启动服务
--pid-file 指定服务启动后的进行文件路径
--config-file 指定服务启动的配置文件
sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml
调试命令:
sudo -u clickhouse clickhouse-server startClickHouse安装完成后会生成clickhouse-server和clickhouse-client两个目录,这个时候我们使用clickhouse-client去测试服务
clickhouse-client -h 127.0.0.1 --port 9000 --multiquery --query="show databases"
注意:--port指定的是tcp的端口
使用DBserver工具连接

2.clickhouse引擎

3.clickhouse函数
官方链接:https://clickhouse.tech/docs/zh/sql-reference/functions/string-functions/
----------------------------------------------------------------------------
----------------------------------------------------------------------------
---------------Clickhouse基础知识:函数学习----------------------------------
官址学习文档:https://clickhouse.tech/docs/zh/
----------------------------------------------------------------------------
----------------------------------------------------------------------------
----------------------------------------------------------------------------
-- DBeaver6.1.2操作快捷键:
-- 常用快捷键须知:(Ctrl + Shift + L 显示快捷键列表)
-- 1.删除光标所在行:Ctrl + D
-- 2.复制光标所在行:Ctrl + Alt + ↓
-- 3.移动光标所在行:Ctrl + Shift + ↑/↓
-- 4.缩小SQL编辑器的文本字体大小:Ctrl + -/+
-- 5.查找:Ctrl + F
-- 6.选中上或下的SQL执行语句:Alt + ↑/↓
-- 7.执行当前光标所在SQL语句(无论是否格式化过,前提是此SQL语句和上一条有空行或者上一条SQL语句有分号“;”隔开)
----------------------------------------------------------------------------
-- 零、检测函数类型(clickhouse中数据的类型)
SELECT toTypeName(0);-- UInt8(三位数为8)
SELECT toTypeName(-0);-- Int8
SELECT toTypeName(-343);-- Int16
SELECT toTypeName(12.43); -- Float64(默认浮点型的数据为64),所以一般在处理浮点型的数据的时候尽量转成toFloat32(12.43)
SELECT toTypeName(12.34343); -- Float64
SELECT toTypeName(toDateTime(1502396027)); -- DateTime
-- 一、算数函数
-->>>>>> 算数函数(数学上的计算)
--求和
SELECT plus(12, 21), plus(10, -10), plus(-10, -10);
--差值
SELECT minus(10, 5), minus(10, -10),minus(-10, -10);
--积
SELECT multiply(12, 2), multiply(12, -2), multiply(-12, -2);
--平均值
SELECT divide(12, 4), divide(10, 3), divide(2, 4), divide(-4, -2), divide(-4, 2), divide(-4.5, 3);
SELECT intDiv(10, 3), divide(10, 3); -- 3, 3.333(保留四位有效数字)
SELECT divide(10, 0), divide(-10, 0); -- 出现无穷大字符“ ∞ ”或“ -∞ ”
SELECT divide(0, 0); -- 特殊字符(类似乱码)
SELECT intDivOrZero(10, 0); -- 0
--求余数
SELECT modulo(10, 3); --1
SELECT modulo(10.5, 3); --1
--取反
SELECT negate(10), negate(-10); -- -10 10
--绝对值
SELECT abs(-10), abs(10);
--最大公约数
SELECT gcd(12, 24), gcd(-12, -24), gcd(-12, 24);
--最小公倍数
SELECT lcm(12, 24), lcm(-12, -24), lcm(-3, 4);
-- 二、比较函数
-->>>>>> 比较函数(始终返回0表示false 或 1表示true)
SELECT 12 == 12, 12 != 10, 12 == 132, 12 != 12, 12 <> 12;
SELECT equals(12, 12), notEquals(12, 10), equals(12, 10), notEquals(12,123);
SELECT greater(12, 10), greater(10, 12), greater(12, 12);-- 前者是否大于后者
SELECT greaterOrEquals(12,10), greaterOrEquals(12,12);-- 前者是否大于或等于后者
SELECT less(12, 21), less(12, 10), less(120, 120);-- 前者是否小于后者
SELECT lessOrEquals(12, 120), lessOrEquals(12, 12);-- 前世是否小于或等于或者
-- 三、逻辑函数
-->>>>>> 逻辑操作符(返回0表示false 或 1表示true)
SELECT 12==12 or 12!=10;
SELECT 12==12 and 12!=10;
SELECT not 12, not 0;
SELECT or(equals(12, 12), notEquals(12, 10)); --函数表示法:或
SELECT and(equals(12, 12), notEquals(12, 10));--函数表示法:且
SELECT not(12), not(0);
-- 四、类型转换函数
-->>>>>> 类型转换函数部分示例:
SELECT toInt8(12.3334343), toFloat32(10.001), toFloat64(1.000040);
SELECT toString(now());
SELECT now() AS now_local, toString(now(), 'Asia/Yekaterinburg') AS now_yekat;
SELECT now() AS now_local, toDate(now()), toDateTime(now()), toUnixTimestamp(now());
SELECT
'2016-06-15 23:00:00' AS timestamp,
CAST(timestamp AS DateTime) AS datetime,
CAST(timestamp AS Date) AS date,
CAST(timestamp, 'String') AS string,
CAST(timestamp, 'FixedString(22)') AS fixed_string;
WITH
toDate('2019-01-01') AS date,
INTERVAL 1 WEEK AS interval_week,
toIntervalWeek(1) AS interval_to_week,
toIntervalMonth(1) AS interval_to_month
SELECT
date + interval_week,
date + interval_to_week,
date + interval_to_month;
WITH
toDateTime('2019-01-01 12:10:10') as datetime,
INTERVAL 1 HOUR AS interval_hour,
toIntervalHour(1) as invterval_to_hour
SELECT
plus(datetime, interval_hour),
plus(datetime, invterval_to_hour);
-- 五、时间日期函数
--->>>>>> 时间日期函数
SELECT
toDateTime('2019-07-30 10:10:10') AS time,
-- 将DateTime转换成Unix时间戳
toUnixTimestamp(time) as unixTimestamp,
-- 保留 时-分-秒
toDate(time) as date_local,
toTime(time) as date_time,-- 将DateTime中的日期转换为一个固定的日期,同时保留时间部分。
-- 获取年份,月份,季度,小时,分钟,秒钟
toYear(time) as get_year,
toMonth(time) as get_month,
-- 一年分为四个季度。1(一季度:1-3),2(二季度:4-6),3(三季度:7-9),4(四季度:10-12)
toQuarter(time) as get_quarter,
toHour(time) as get_hour,
toMinute(time) as get_minute,
toSecond(time) as get_second,
-- 获取 DateTime中的当前日期是当前年份的第几天,当前月份的第几日,当前星期的周几
toDayOfYear(time) as "当前年份中的第几天",
toDayOfMonth(time) as "当前月份的第几天",
toDayOfWeek(time) as "星期",
toDate(time, 'Asia/Shanghai') AS date_shanghai,
toDateTime(time, 'Asia/Shanghai') AS time_shanghai,
-- 得到当前年份的第一天,当前月份的第一天,当前季度的第一天,当前日期的开始时刻
toStartOfYear(time),
toStartOfMonth(time),
toStartOfQuarter(time),
toStartOfDay(time) AS cur_start_daytime,
toStartOfHour(time) as cur_start_hour,
toStartOfMinute(time) AS cur_start_minute,
-- 从过去的某个固定的时间开始,以此得到当前指定的日期的编号
toRelativeYearNum(time),
toRelativeQuarterNum(time);
SELECT
toDateTime('2019-07-30 14:27:30') as time,
toISOYear(time) AS iso_year,
toISOWeek(time) AS iso_week,
now() AS cur_dateTime1, -- 返回当前时间yyyy-MM-dd HH:mm:ss
today() AS cur_dateTime2, -- 其功能与'toDate(now())'相同
yesterday() AS yesterday, -- 当前日期的上一天
-- timeSlot(1) AS timeSlot_1, -- 出现异常!!将时间向前取整半小时
toDate(time) as getY_M_d;
-- 目前只有这三种格式,没有什么toYYYY(),toYYYddmm()之类的函数,不要想当然。
SELECT
now() as nowTime,
-- 将Date或DateTime转换为包含年份和月份编号的UInt32类型的数字(YYYY * 100 + MM)
toYYYYMMDDhhmmss(nowTime),
toYYYYMMDD(nowTime),
toYYYYMM(nowTime);
-- formatDateTime(Time, Format[,Timezone])函数引用
SELECT
now() as now_time,
toDateTime('2019-07-31 18:20:30') AS def_datetime,
formatDateTime(now_time, '%D') AS now_time_day_month_year,-- 07/30/19
-- toDateTime('2019-07-31 18:20:30', 'Asia/Shanghai') AS def_datetime1, -- 指定时区
formatDateTime(def_datetime, '%Y') AS def_datetime_year, -- 2019(指定日期为2019年)
formatDateTime(def_datetime, '%y') AS def_datetime_year_litter, -- 19(指定日期为19年,Year, last two digits (00-99),本世纪的第19年)
formatDateTime(def_datetime, '%H') AS hour24, -- 18 下午六点
formatDateTime(def_datetime, '%I') AS hour12, -- 06下午六点
formatDateTime(def_datetime, '%p') AS PMorAM, -- 指定时间是上午还是下午
formatDateTime(def_datetime, '%w') AS def_datetime_get_curWeek,-- 3(指定日期为星期三)
formatDateTime(def_datetime, '%F') AS def_datetime_get_date,-- 2019-07-31
formatDateTime(def_datetime, '%T') AS def_datetime_get_time,-- 18:20:30
formatDateTime(def_datetime, '%M') AS def_datetime_get_minute,-- 20(得到指定事件的“分”,minute (00-59))
formatDateTime(def_datetime, '%S') AS def_datetime_get_second;-- 30(得到指定事件的“秒”,second (00-59))
-- 1.跳转到之后的日期函数
-- 第一种,日期格式(指定日期,需注意时区的问题)
WITH
toDate('2019-09-09') AS date,
toDateTime('2019-09-09 00:00:00') AS date_time
SELECT
addYears(date, 1) AS add_years_with_date,
addYears(date_time, 0) AS add_years_with_date_time;
-- 第二种,日期格式(当前,本地时间)
WITH
toDate(now()) as date,
toDateTime(now()) as date_time
SELECT
now() as now_time,-- 当前时间
addYears(date, 1) AS add_years_with_date,-- 之后1年
addYears(date_time, 1) AS add_years_with_date_time,
addMonths(date, 1) AS add_months_with_date,-- 之后1月
addMonths(date_time, 1) AS add_months_with_date_time,
addWeeks(date, 1) AS add_weeks_with_date,--之后1周
addWeeks(date_time, 1) AS add_weeks_with_date_time,
addDays(date, 1) AS add_days_with_date,-- 之后1天
addDays(date_time, 1) AS add_days_with_date_time,
addHours(date_time, 1) AS add_hours_with_date_time,--之后1小时
addMinutes(date_time, 1) AS add_minutes_with_date_time,--之后1分中
addSeconds(date_time, 10) AS add_seconds_with_date_time,-- 之后10秒钟
addQuarters(date, 1) AS add_quarters_with_date, -- 之后1个季度
addQuarters(date_time, 1) AS add_quarters_with_date_time;
-- 2.跳转到当前日期之前的函数(函数将Date/DateTime减去一段时间间隔,然后返回Date/DateTime)
WITH
toDate(now()) as date,
toDateTime(now()) as date_time
SELECT
subtractYears(date, 1) AS subtract_years_with_date,
subtractYears(date_time, 1) AS subtract_years_with_date_time,
subtractQuarters(date, 1) AS subtract_Quarters_with_date,
subtractQuarters(date_time, 1) AS subtract_Quarters_with_date_time,
subtractMonths(date, 1) AS subtract_Months_with_date,
subtractMonths(date_time, 1) AS subtract_Months_with_date_time,
subtractWeeks(date, 1) AS subtract_Weeks_with_date,
subtractWeeks(date_time, 1) AS subtract_Weeks_with_date_time,
subtractDays(date, 1) AS subtract_Days_with_date,
subtractDays(date_time, 1) AS subtract_Days_with_date_time,
subtractHours(date_time, 1) AS subtract_Hours_with_date_time,
subtractMinutes(date_time, 1) AS subtract_Minutes_with_date_time,
subtractSeconds(date_time, 1) AS subtract_Seconds_with_date_time;
SELECT toDate('2019-07-31', 'Asia/GuangZhou') as date_guangzhou;
SELECT toDate('2019-07-31'), toDate('2019-07-31', 'Asia/Beijing') as date_beijing;
-- 亚洲只能加载上海的timezone???
SELECT toDateTime('2019-07-31 10:10:10', 'Asia/Shanghai') as date_shanghai;
-- 计算连个时刻在不同时间单位下的差值
-- 第一种:指定时间计算差值示例
WITH
toDateTime('2019-07-30 10:10:10', 'Asia/Shanghai') as date_shanghai_one,
toDateTime('2020-10-31 11:20:30', 'Asia/Shanghai') as date_shanghai_two
SELECT
dateDiff('year', date_shanghai_one, date_shanghai_two) as diff_years,
dateDiff('month', date_shanghai_one, date_shanghai_two) as diff_months,
dateDiff('week', date_shanghai_one, date_shanghai_two) as diff_week,
dateDiff('day', date_shanghai_one, date_shanghai_two) as diff_days,
dateDiff('hour', date_shanghai_one, date_shanghai_two) as diff_hours,
dateDiff('minute', date_shanghai_one, date_shanghai_two) as diff_minutes,
dateDiff('second', date_shanghai_one, date_shanghai_two) as diff_seconds;
-- 第二种:本地当前时间示例
WITH
now() as date_time
SELECT
dateDiff('year', date_time, addYears(date_time, 1)) as diff_years,
dateDiff('month', date_time, addMonths(date_time, 2)) as diff_months,
dateDiff('week', date_time, addWeeks(date_time, 3)) as diff_week,
dateDiff('day', date_time, addDays(date_time, 3)) as diff_days,
dateDiff('hour', date_time, addHours(date_time, 3)) as diff_hours,
dateDiff('minute', date_time, addMinutes(date_time, 30)) as diff_minutes,
dateDiff('second', date_time, addSeconds(date_time, 35)) as diff_seconds;
-- timeSlot(StartTime, Duration, [,Size])
-- 它返回一个时间数组,其中包括从从“StartTime”开始到“StartTime + Duration 秒”内的所有符合“size”(以秒为单位)步长的时间点
-- 作用:搜索在相应会话中综合浏览量是非常有用的。
SELECT
timeSlots(toDateTime('2012-01-01 12:20:00'), toUInt32(600)) as dateTimeArray,
dateTimeArray[0] as arr_index_0, -- no result.
dateTimeArray[1] as arr_index_1, -- 2012-01-01 20:00:00
dateTimeArray[2] as arr_index_2, -- 2012-01-01 20:30:00
dateTimeArray[3] as arr_index_3, -- no result.
dateTimeArray[4] as arr_index_4; -- no result.
-- toUInt32(600) 表示之后间距20秒的时刻
SELECT
timeSlots(now(), toUInt32(600), 20) as dateTimeArray, -- 类似于:引用地址
dateTimeArray[0] as arr_index_0, -- no result.为什么?
dateTimeArray[1] as arr_index_1,
dateTimeArray[2] as arr_index_2,
dateTimeArray[3] as arr_index_3,
dateTimeArray[4] as arr_index_4,
dateTimeArray[5] as arr_index_5;
-- 指定时间为基准,之后每个元素增加20秒
SELECT
timeSlots(toDateTime('2012-01-01 12:20:00'), toUInt32(600), 20) as cur_dateTimeArray, -- 类似于:引用地址
cur_dateTimeArray[0] as arr_index_0, -- no result.为什么?
cur_dateTimeArray[1] as arr_index_1, -- 2012-01-01 20:20:00
cur_dateTimeArray[2] as arr_index_2, -- 2012-01-01 20:20:20
cur_dateTimeArray[3] as arr_index_3, -- 2012-01-01 20:20:40
cur_dateTimeArray[4] as arr_index_4, -- 2012-01-01 20:21:00
cur_dateTimeArray[5] as arr_index_5; -- 2012-01-01 20:21:20
-- 六、字符串函数
--->>>>>> 字符串函数:
SELECT
length('hello world') as str_length, -- 按照Unicode编码计算长度“你好”的长度为6
empty('hello world'),-- 判断字符串是否为空,空为1,非空为0
notEmpty('hello world'),
lengthUTF8('hello world'), -- 按照实际字符计算长度“你好”为2
char_length('hello world'), -- 同 lengthUTF8()
character_length('hello world'), -- 同 lengthUTF8(),
lower('abcd123--'),--字母全部小写(将字符串中的ASCII转换为小写。)
upper('abcd123--'),--字母全部大写(将字符串中的ASCII转换为大写。)
lowerUTF8('abcd123-/*\\8asd-\\\\'), -- abcd123-/*8asd-\\
upperUTF8('abcd123--'), -- ABCD123--
isValidUTF8('abcd123--/*\\*'); --检查字符串是否为有效的UTF-8编码,是则返回1,否则返回0。
SELECT notEmpty(''), notEmpty(NULL), notEmpty('he'); -- 0,空,1
SELECT toValidUTF8('\\x61\\xF0\\x80\\x80\\x80b');
-- reverseUTF8():以Unicode字符为单位反转UTF-8编码的字符串。如果字符串不是UTF-8编码,则可能获取到一个非预期的结果(不会抛出异常)
SELECT reverse('abcdefg'), reverseUTF8('abcdefg');
-- 2.字符串维度自定义安排
SELECT format('{1} {0} {1}', 'World', 'Hello'); -- 输出:Hello World Hello
SELECT format('{0} {0} {1} {1}', 'one', 'two'); -- 输出:one one two two
SELECT format('{} {}', 'Hello', 'World'); -- 输出:Hello World
-- 3.字符串拼接 concat(s1,s2,s3,...)
SELECT concat('Hello',' ','World', '!');-- Hello World!
-- 与concat相同,区别在于,你需要保证concat(s1, s2, s3) -> s4是单射的,它将用于GROUP BY的优化。
SELECT concatAssumeInjective('Hello',' ','World', '!');-- Hello World!
-- 4.字符串截取:substring(s, offset, length), mid(s, offset, length), substr(s, offset, length)
-- 以字节为单位截取指定位置字符串,返回以‘offset’位置为开头,长度为‘length’的子串。‘offset’从1开始(与标准SQL相同)。‘offset’和‘length’参数必须是常量。
SELECT
substring('abcdefg', 1, 3),-- abc
substring('你好,世界', 1, 3),-- 你
substringUTF8('你好,世界', 1, 3); -- 你好,
-- 5.字符串拼接:appendTrailingCharIfAbsent(s, c)
-- 如果‘s’字符串非空并且末尾不包含‘c’字符,则将‘c’字符附加到末尾。
SELECT
appendTrailingCharIfAbsent('good','c'), -- goodc
appendTrailingCharIfAbsent('goodccc','c'); -- goodccc
-- 6.字符串编码转换:convertCharset(s, from, to) 返回从‘from’中的编码转换为‘to’中的编码的字符串‘s’。
SELECT
convertCharset('hello', 'UTF8','Unicode'),-- ��h
convertCharset('hello', 'Unicode', 'UTF8'),-- 桥汬�
convertCharset('hello', 'Unicode', 'ASCII'),--
convertCharset('hello', 'ascii', 'ascii'),--hello
convertCharset('hello', 'UTF8','UTF8');-- hello
SELECT
base64Encode('username+password'),-- dXNlcm5hbWUrcGFzc3dvcmQ=
base64Decode('dXNlcm5hbWUrcGFzc3dvcmQ='), -- username+password
-- 使用base64将字符串解码成原始字符串。但如果出现错误,将返回空字符串。
tryBase64Decode('dXNlcm5hbWUrcGFzc3dvcmQ=');
-- 7.判断字符串是否已什么结尾或结束,返回1:true,0:flase
-- endsWith(s, suffix) 返回是否以指定的后缀结尾。如果字符串以指定的后缀结束,则返回1,否则返回0
-- startWith(s, prefix) 返回是否以指定的前缀开头。如果字符串以指定的前缀开头,则返回1,否则返回0。
SELECT
endsWith('string','g'),
startsWith('string', 'str'); -- 1 true
-- 8.删除左侧空白字符
-- trimLeft(s) 返回一个字符串,用于删除左侧的空白字符
-- trimRight(s) 返回一个字符串,用于删除右侧的空白字符
-- trimBoth(s) 返回一个字符串,用于删除左侧和右侧的空白字符
SELECT
trimLeft(' sdfdgs'), -- sdfdgs
trimRight('abcd '), -- abcd
trimBoth(' abcd '); -- abcd
-- 七、字符串搜索函数
--->>>>>> 字符串搜索函数
-- pasition(haystack, needle), 显示needle在haystack的第一个出现的位置。
SELECT
POSITION('2121stringstrstrstrstr','str') AS positionSearch, -- 5
POSITION('你好,hello,12323-你好,你,好sdfd*dg', '你,好'),-- 31
positionUTF8('n12你好','你好') AS positionUTF8,-- 4
positionCaseInsensitive('ABCDCDEFABCD','bc') AS positionCaseInsensitive, --2
locate('hellohellohellohello','ello'); -- 2
-- multiSearchAllPositions(haystack, [needle1, needle2, ..., needlen])
-- 注意:在所有multiSearch*函数中,由于实现规范,needles的数量应小于2^8。
-- 函数返回一个数组,其中包含所有匹配needlei的位置
SELECT
multiSearchAllPositions('goodnamegoodnamegoodhellohihihi', ['dn', 'good']) as multiSearch,-- [4,1]
multiSearchAllPositionsCaseInsensitive('nameSsdfagpSSDFDFetgfderef', ['SS','fa']) as multiCaseInsensitive,
multiSearchAllPositionsUTF8('nameSsdfazz轴功率gpSSDFDFetgfderef', ['Ss','fa', 'zz轴']) AS multiSearchUTF8,
multiSearchAllPositionsCaseInsensitiveUTF8('nameSsdfazz轴功率gpSSDFDFetgfderef', ['Ss','fa', 'zz轴']) AS multiCaseInsensitiveUTF8;
-- 检查字符串是否与pattern正则表达式匹配。pattern可以是一个任意的re2正则表达式。 re2正则表达式的语法比Perl正则表达式的语法存在更多限制。
-- match(haystack, pattern) 匹配到了则返回1,否则返回0
SELECT
match('1232434sadgaDDFSrefds', '[0-9a-zA-Z]'), -- 存在匹配的字符,返回1
match('1232321', '[a-z]'); -- 不存在匹配的字符,返回0
-- 与match相同,但如果所有正则表达式都不匹配,则返回0;如果任何模式匹配,则返回1。它使用hyperscan库。对于在字符串中搜索子字符串的模式,最好使用“multisearchany”,因为它更高效。
-- multiMatchAny(haystack, [pattern1, pattern2, ..., patternn])
-- 注意:任何haystack字符串的长度必须小于232字节,否则抛出异常。这种限制是因为hyperscan API而产生的。
-- 多个正则表达式对原始字符进行匹配,如若只有一个正则表达式匹配上了则返回1,否则返回0
SELECT
multiMatchAny('abcABC',['[0-9]','[a-zA-Z]']) AS multiMatchAnyOne, -- 1
multiMatchAny('123abcABC',['[0-9]','[a-zA-Z]']) AS multiMatchAnyTwo, --1
-- 与multiMatchAny相同,但返回与haystack匹配的任何内容的索引位置。
multiMatchAnyIndex('123abcABC', ['[0-9]','[a-zA-Z]']) as multiMatchAnyIndex; --2
-- 模糊匹配:like()函数,注意大写敏感。
-- % 表示任何字节数(包括零字符)
-- _ 表示任何一个字节
SELECT
'hello' LIKE '%h%' as LIKE_UP, -- 1
'hello' like 'he' AS like_low, -- 0
'hello' not like 'he' AS not_like, -- 1
'hello' like '%he%' AS like_litter, -- 1
like('adgadgadfa1232', '_12_') AS like_func,
like('sdfasdfasd', '[a-z]') AS like_func2, -- 0
notLike('1232423', '[a-zA-Z]') AS not_like_func; -- 1
-- 使用字符串截取字符串:extract(haystack, pattern)
-- 使用正则表达式截取字符串。如果‘haystack’与‘pattern’不匹配,则返回空字符串。如果正则表达式中不包含子模式,它将获取与整个正则表达式匹配的子串。否则,它将获取与第一个子模式匹配的子串。
SELECT
extractAll('hellogoodaimantIdeaIDEAfasd123232', '[0-9]'), -- ['1','2','3','2','3','2']
extractAll('12323dSDFRE', '[A-Z]'),-- ['S','D','F','R','E']
extract('helloclickhouse', '[a-z]');-- h
-- ngramSearch(haystack, needle)
-- 基于4-gram计算haystack和needle之间的距离:计算两个4-gram集合之间的对称差异,并用它们的基数和对其进行归一化。
-- 返回0到1之间的任何浮点数 -- 越接近0则表示越多的字符串彼此相似。
-- 如果常量的needle或haystack超过32KB,函数将抛出异常。如果非常量的haystack或needle字符串超过32Kb,则距离始终为1。
SELECT
ngramDistance('hello123456789','123') AS ngramDistance,
ngramDistanceCaseInsensitive('hello123456789','123') AS ngramDistanceCaseInsensitive,
ngramDistanceUTF8('hello123456789','123') AS ngramDistanceUTF8,
ngramDistanceCaseInsensitiveUTF8('hello123456789','123') AS ngramDistanceCaseInsensitiveUTF8;
-- 注意:对于UTF-8,我们使用3-gram。所有这些都不是完全公平的n-gram距离。
-- 我们使用2字节哈希来散列n-gram,然后计算这些哈希表之间的(非)对称差异 - 可能会发生冲突。
-- 对于UTF-8不区分大小写的格式,我们不使用公平的tolower函数
-- 我们将每个Unicode字符字节的第5位(从零开始)和字节的第一位归零
-- 这适用于拉丁语,主要用于所有西里尔字母。
--八、字符串替换函数
--->>>>>> 字符串替换函数
-- 替换匹配到的字符串
-- replaceOne(haystack, pattern, replacement)
-- 用‘replacement’子串替换‘haystack’中与‘pattern’子串第一个匹配的匹配项(如果存在)。 ‘pattern’和‘replacement’必须是常量。
-- replaceAll(haystack, pattern, replacement), replace(haystack, pattern, replacement)
-- 用‘replacement’子串替换‘haystack’中出现的所有‘pattern’子串。
SELECT
replaceOne('hed1234544', '4', '*') AS replaceOne,-- hed123*544
replaceRegexpOne('hed1234544', '4', '*') AS replaceRegexpOne,-- hed123*544
replace('hed1234544', '4', '*') AS replace, -- hed123*5**
replaceAll('hed1234544', '4', '*') AS replaceAll;-- hed123*5**
-- 实例:2019-07-31 改变成 07/31/2019
SELECT
toDate(now()) AS now_date,
replaceRegexpOne(toString(now_date), '(\\\\d{4})-(\\\\d{2})-(\\\\d{2})', '\\\\2/\\\\3/\\\\1') AS format_date;
-- 示例:赋值字符串10次
SELECT replaceRegexpOne('Hello, World!', '.*', '\\\\0\\\\0\\\\0\\\\0\\\\0\\\\0\\\\0\\\\0\\\\0\\\\0') AS res;
-- replaceRegexpAll(haystack, pattern, replacement)
-- 与replaceRegexpOne相同,但会替换所有出现的匹配项。例如:
SELECT replaceRegexpAll('hello,world!', '.', '\\\\0\\\\0') as res; -- hheelllloo,,wwoorrlldd!!
SELECT replaceRegexpAll('hello o o, world.', ' ', '*') as res; -- hello*o*o,*world.
-- 函数:regexpQuoteMeta(s) 该函数用于在字符串中的某些预定义字符之前添加反斜杠。
-- 预定义字符:'0','\\','|','(',')','^','$','。','[',']','?','* ','+','{',':',' - '。
-- 这个实现与re2 :: RE2 :: QuoteMeta略有不同。它以\\0而不是\\x00转义零字节,它只转义所需的字符
---- 简言之,就是不处理转义字符,一般如果没有用的这个函数,都会有转义的情况出现。
SELECT regexpQuoteMeta('\\\\\\\\|[]{}+_-=@!~`&^*%$#'); -- \\\\\\\\\\|\\[\\]\\{}\\+_\\-=@!~`&\\^\\*%\\$#
SELECT toString('\\\\\\\\'); -- \\\\
--九、条件函数
--->>>>>> 条件函数
-- 1. if(cond, then, else)函数:类似于三元操作符。
-- 中文字符使用双引号,英文字符可不使用引号也可使用当引号或双引号,根据具体情况而定。
-- 如果cond != 0则返回then,如果cond = 0则返回else。 cond必须是UInt8类型,then和else必须存在最低的共同类型。
-- 注意:then和else可以是NULL
SELECT
12 > 10 ? 'desc' : 'asc' AS "三元操作符",
if(12 > 10, 'desc' , 'asc') AS "if()函数",
if(12 > 10, NULL, NULL);
-- 2. multiIf(cond_1, then_1, cond_2, then_2...else)
-- 允许您在查询中更紧凑地编写CASE运算符。类似于java中的switch语法(可以接受2n+1个参数)
SELECT multiIf(1,'one',2,'two',3,'three','not this index');-- 关联case条件表达式
--十、数学函数
--->>>>>> 数学函数
SELECT
1 * e() AS E,
1 * pi() AS PI,
sqrt(25) AS sqrt_25, --接受一个数值类型的参数并返回它的平方根。
cbrt(27) AS cbrt_27, --接受一个数值类型的参数并返回它的立方根。
exp(10), --接受一个数值类型的参数并返回它的指数
exp10(10), --接受一个数值类型的参数并返回它的10的x次幂。
log(10) AS LOG,
log2(10) AS LOG2, --接受一个数值类型的参数并返回它的底2对数。
ln(e()) AS LOG10; --接受一个数值类型的参数并返回它的自然对数
-- 示例:三西格玛准则
SELECT erf(3 / sqrt(2)); -- 0.997
SELECT
sin(90), -- 返回x的三角正弦值。
cos(90), -- 返回x的三角余弦值。
tan(90), -- 返回x的三角正切值
acos(0), -- 返回x的反三角余弦值。
asin(1), -- 返回x的反三角正弦值。
atan(45); -- 返回x的反三角正切值。
-- pow(x, y), power(x, y) 接受x和y两个参数。返回x的y次方。
SELECT
pow(2, 3), -- 2的三次方
pow(3, 2); -- 3的平方
SELECT
intExp2(4), --2^4 接受一个数值类型的参数并返回它的2的x次幂(UInt64)。
intExp10(2);--10^2 接受一个数值类型的参数并返回它的10的x次幂(UInt64)。
-- 十一、取整函数
--->>>>>> 取整函数
-- 1.向下取整:floor(x[,N])
SELECT
floor(toFloat32(12.08098), 2), -- 12.08
floor(toFloat32(12.2323), 2), -- 12.23
floor(toFloat32(12.89788), -1), -- 10
floor(toFloat32(12.09590), 3), -- 12.095 (注意:如果按照正常的四舍五入,则应该是12.096,为什么呢?)
floor(toFloat32(12.0987), 3),-- 12.098
floor(10, 2); -- 10
-- 2.四舍五入:round(expression [, decimal_places])
-- 如果decimal_places=0,则取整数;
-- 如果>0,则将值舍入小数点右侧;
-- 如果<0,则将小数点左侧的值四舍五入。
SELECT
round(toFloat32(12.1234), 3),
round(toFloat32(12.0025), 3), -- 12.002(注意:为什么不是12.003呢?)
-- round函数只会最多保留三位有效数字
round(toFloat32(12.0025), 4), -- 12.002
round(toFloat32(12.0025002323), 100); -- 12.003
-- 示例:
SELECT
round(toFloat32(10 / 3)), -- 3
round(toFloat32(10 / 3), 2), -- 3.33
round(toFloat32(10.000/3), 3), -- 3.333
round(toFloat32(10.000/3), 6); -- 3.333
-- roundToExp2() 接受一个数字。如果数字小于1,则返回0。否则,它将数字向下舍入到最接近的(整个非负)2的x次幂。
SELECT
roundToExp2(12.0129), -- 8 = 2^3
roundToExp2(toFloat32(0.01)); -- 0.008
-- 3.向上取整:ceil(x[, N]) 或者 ceiling(x[, N])
SELECT
ceil(12.34343, 3), -- 12.344
ceil(toFloat64(12.34343), 3), -- 12.344
ceil(toFloat32(12.34343), 3), -- 12.344
ceil(12.0011, 3); -- 12.002
---十二、数组函数
--->>>>>> 数组函数
-- 1.数组非空判断相关函数(真为1,假为0)
SELECT empty([]), empty([1,2,3]), notEmpty([1,2,3]), notEmpty([]);
-- 2.数组长度 length() 返回数组中的元素个数。 结果类型是UInt64。 该函数也适用于字符串。
SELECT
-- length(), -- 出现异常
-- length([true, false]), -- 异常
-- length([1,2,,4]), --出现异常!
length([]), -- 0
length(['a','b','c']), -- 3
length([1,2,3]); -- 3
-- 3.扩展判断非空的部分函数如下:不接受任何参数并返回适当类型的空数组
SELECT
emptyArrayUInt8(), -- UInt8的空数组
emptyArrayUInt16(),
emptyArrayUInt32(),
emptyArrayUInt64(),
emptyArrayDate(),
emptyArrayDateTime(),
emptyArrayInt8(),
emptyArrayInt16(),
emptyArrayInt32(),
emptyArrayInt64();
-- 接受一个空数组并返回一个仅包含一个默认值元素的数组。(以下是部分示例)
SELECT
emptyArrayToSingle(emptyArrayInt32()), -- 0
emptyArrayToSingle(emptyArrayUInt32()), -- 0
emptyArrayToSingle(emptyArrayDate()), -- 0002-11-30
emptyArrayToSingle(emptyArrayDateTime()); --0002-11-30 08:00:00
-- 4.生成一个含有N个元素的数组,元素从0开始增长,步长尾1.
-- range(N) 返回从0到N-1的数字数组。 以防万一,如果在数据块中创建总长度超过100,000,000个元素的数组,则抛出异常
SELECT
range(10), -- [0,1,2,3,4,5,6,7,8,9]
range(2), -- [0,1]
-- range(5.5), -- 出现异常,N为Int8的数据类型,正整数
-- range(-10), -- 出现异常,DB::Exception: Illegal type Int8 of argument of function range
range(1); -- 0
-- 5.新建一个数组的函数:array(x1,……) 类似于 直接[x1,……]
-- 注意:新建数组的每个元素的数据类型需保持一致性。
SELECT
array(1,2,2,3,4) AS "array()函数",
-- [1,'hello',3], -- 出现异常,DB::Exception: There is no supertype for types UInt8, String, UInt8 because some of them are String/FixedString and some of them are not (version 19.10.1.5 (official build))
[1,2,3,4] AS "[ ]";
-- 6.合并N个数组 arrayConcat(arrays) 合并参数中传递的所有数组。跟java的数组差不多的合并,不会自动去重,不会自动排序
SELECT
arrayConcat(array(1,2),array(2,3),array(4,5)), -- [1,2,2,3,4,5](第一种情况)
arrayConcat(array(1,1),array(2,2),array(3,3)), -- [1,1,2,2,3,3]
-- arrayConcat(array(1,2),['a','c'],array(3,3)), -- 出现异常,不能将不同类型的数组进行合并
arrayConcat(array(1,1),[2,3],array(4,5)); -- [1,1,2,3,4,5]
-- 7.从数组arr中获取索引为“n”的元素。
-- n必须是任何整数类型。 数组中的索引从一开始。 支持负索引。在这种情况下,它选择从末尾开始编号的相应元素。例如,arr [-1]是数组中的最后一项。
-- 如果索引超出数组的边界,则返回默认值(数字为0,字符串为空字符串等).
SELECT
arrayElement(array(10,20,3), 1), -- 10
arrayElement(array(1,20,3), 2), -- 20
arrayElement(array(1,2,30), 3), -- 30
arrayElement(array(10,20,3), 0), -- 0
arrayElement(array(10,20,3), -3), -- 10
arrayElement(array(10,20,3), -2), -- 20
arrayElement(array(10,20,3), -1);-- 3
-- 8.检查在数组中是否含有此元素。has(arr, elem) 包含此元素则返回1,否则返回0
-- has() 检查'arr'数组是否具有'elem'元素。 如果元素不在数组中,则返回0;如果在,则返回1。
-- hasAny(arr1, arr2) 返回1表示arr1和arr2存在交集。否则返回0.
--注意:特殊的定义:
-- ① “NULL”作为数组中的元素值进行处理。
-- ② 忽略两个数组中的元素值的顺序
-- hasAll(set, subset) 检查一个数组是否是另一个数组的子集。返回1,表示set包含subset中所有的元素
-- set – 具有一组元素的任何类型的数组。
-- subset – 任何类型的数组,其元素应该被测试为set的子集。
-- 注意:特殊的定义:
-- ① 空数组是任何数组的子集。
-- ② “NULL”作为数组中的元素值进行处理。
-- ③ 忽略两个数组中的元素值的顺序。
SELECT
has([1,2,3], 2), -- 1
has(array(1,2,3),2), -- 1
has([1,2,NULL], NULL), -- 1 (注意:null值的处理)
-- has([], 2), -- 出现异常,DB::Exception: Types of array and 2nd argument of function has must be identical up to nullability or numeric types or Enum and numeric type. Passed: Array(Nothing) and UInt8
has([1,2], 3); -- 0
SELECT
hasAll([], []), -- 1
hasAll([1,NULL,NULL], [NULL]), -- 1
hasAll([1,2,3], [1,2]), -- 1
hasAll([1,2,2,3], [2]), -- 1
hasAll(array(1,2,2,3), [2]), -- 1
hasAll([1,2,3], [4,5]); -- 0
-- 多重数组(如下的二维数组)。
SELECT hasAll([[1, 2], [3, 4]], [[1, 2], [3, 5]]); -- 0
SELECT
hasAny(array(1,2,3), array(1)), -- 1
hasAny(array(1,2,3), array(1,4,56,80)), -- 1
-- []与array()是一样的含义,本质上是一直的。只不过[]更加简便而已。
hasAny(array(), array()), -- 0
hasAny([],[]), -- 0
hasAny([1],[]), -- 0
-- 空数组跟null不是一样的对象
hasAny([1,NULL],[]), -- 0
hasAny([1,NULL],[NULL,2]); -- 1
-- 9.返回数组指定元素的索引
-- indexOf(arr, x) 返回数组中第一个‘x’元素的索引(从1开始),如果‘x’元素不存在在数组中,则返回0。
SELECT indexOf(['one','two','three'], 'one'); -- 1
SELECT indexOf([1, 2, 4], 4); -- 3
SELECT
indexOf(['one','two','three'], 'one'), -- 1
indexOf(['one',NULL,NULL], NULL),-- 1返回第一个找到的元素的索引位置
indexOf([1, 2, 4], 4); -- 3
-- 数组元素的以第一个和最后一个元素。
SELECT length([12,3,4,4,4]);
SELECT array(12,22,31)[1];
WITH
[23,43,565,2,32,34] AS arr
SELECT
arr[1], -- 去除数组中的第一个元素
arr[length(arr)]; -- 提取元素中的最后一个元素
-- 10.计算数组中包含指定元素的个数
-- countEqual(arr, x) 返回数组中等于x的元素的个数。相当于arrayCount(elem - > elem = x,arr)。
-- 注意:null值将作为单独的元素值处理。
SELECT
countEqual([1, 2, 2, 2, 3, 4], 2), -- 3
countEqual([1, 2, NULL, NULL], NULL); -- 2
-- 11.arrayEnumerate(arr) 返回 Array [1, 2, 3, ..., length (arr) ] 此功能通常与ARRAY JOIN一起使用。它允许在应用ARRAY JOIN后为每个数组计算一次。
SELECT arrayEnumerate([1,20,20,3]); -- [1,2,3,4]
SELECT arrayEnumerate(array(11,20,13)); -- [1,2,3]
SELECT arrayEnumerate(array(11,20,13,NULL)); -- [1,2,3,4] 注意:null也算是一个元素。
--arrayEnumerateUniq(arr) 返回与源数组大小相同的数组,其中每个元素表示与其下标对应的源数组元素在源数组中出现的次数
SELECT arrayEnumerateUniq([1,1,2,2]); -- [1,2]
-- 12.删除数组的元素
-- arrayPopBack(array) 删除数组array的最后一项
SELECT arrayPopBack(array(1,2,3,0)) AS res; -- [1,2,3]
-- arrayPopFront(array) 从数组中删除第一项
SELECT arrayPopFront(array(0,1,2,3)) AS res; -- [1,2,3]
-- 13.添加数组的元素 arrayPushFront(array, single_value) single_value是单个值
SELECT arrayPushBack([1,2,3], 0) AS res; -- [1,2,3,0]
SELECT arrayPushFront([1,2,3], 0) AS res; -- [0,1,2,3]
-- 14.更改数组的长度 arrayResize(arr, size[, extender])
-- 如果arr的长度 > size,则会对arr截取size的长度;
-- 如果arr的长度 < size,则其余位置用对应数据类型的默认值填充。
-- 注意:extender含义是扩展元素的值。如果没有指定extender,则默认按照对应的数据类型的默认值进行赋值。否则按照extender进行填充。
SELECT arrayResize([1,2,3], 5); -- [1,2,3,0,0]
SELECT arrayResize([1,2,3], 2); -- [1,2]
SELECT arrayResize([1,2,3], 3); -- [1,2,3]
--↓↓↓ RuntimeException: Parse exception: ByteFragment{[[[1,2],[3,4],[5,6],[],[]]], start=0, len=25}
SELECT arrayResize([array(1,2),array(3,4),array(5,6)], 5);
SELECT arrayResize([1,2,3], 5, 12); -- [1,2,3,12,12]
SELECT arrayResize(['one','two','three'], 5); -- ['one','two','three','','']
SELECT arrayResize(['one','two','three'], 5, 'default'); -- ['one','two','three','default','default']
-- 15.截取数组的部分元素,得到一个新的子数组
-- arraySlice(array, offset[, length])
-- 解释:
-- array: 数组,
-- offset – 数组的偏移。正值表示左侧的偏移量,负值表示右侧的缩进值。数组下标从1开始。
-- length - 子数组的长度。如果指定负值,则该函数返回[offset,array_length - length。如果省略该值,则该函数返回[offset,the_end_of_array]。
SELECT
arraySlice([1,2,3,4,5,6], 0, 3), -- 无返回值
arraySlice([1,2,NULL,5,6], 1, 3), -- [1,2,0]
arraySlice(['one','two',NULL], 1, 3), -- ['one','two','']
arraySlice([1,2,3,4,5,6], 1, 3); -- [1,2,3]
-- 16.数组排序:arraySort([func,] arr, ……)
-- 注意:如果在字符串数组中,''和NULL是需要特别对待的,''需要放在最前面,而NULL则是按顺序存放到最后的。
-- arraySort是高阶函数。您可以将lambda函数作为第一个参数传递给它。在这种情况下,排序顺序由lambda函数的调用结果决定。
SELECT
arraySort(['a','',NULL,'c','b']) AS hasNullempty1, --['','a','b','c',''] (第一个是'',最后一个''起始是NULL)
arraySort(array('ac','ab','bc','ad',NULL)) AS hasNull, -- ['ab','ac','ad','bc','']
arraySort(array('ac','','ab',NULL,'bc','ad',NULL)) AS hasNullempty2, -- ['','ab','ac','ad','bc','','']
arraySort([5,4,3,2,1]) AS numSorted,-- [1,2,3,4,5] (数字排序)
arraySort(['ca','bb','ac']) AS strSorted;-- ['ac','bb','ca'] (字符串排序)
SELECT
arraySort([NULL, 1, 3, NULL, 2]) AS sortedArr, -- [1,2,3,0,0]
arrayReverse(sortedArr) AS reverseSortdArr;-- [0,0,3,2,1]
-- 下面这种排序的实质,正数转成负数,再在数学上比较升序排序。
SELECT arraySort(x -> -x, [1,2,3]) as res; -- [3,2,1] 降序:(高阶函数用法)
SELECT arraySort((x) -> -x, [1,2,3]) as res; -- [3,2,1] 降序:(高阶函数用法)
SELECT arraySort(x -> x, [5,4,3,1,2,3]) as res; -- [1,2,3,3,4,5] 升序:(高阶函数用法)
SELECT arraySort((x) -> x, [5,4,3,1,2,3]) as res; -- [1,2,3,3,4,5] 升序:(高阶函数用法)
-- arraySort(lambda, arr1, arr2)
SELECT arraySort((x, y) -> y, ['hello', 'world'], [2, 1]) as res; -- ['world','hello']
SELECT arraySort((x, y) -> -y, [0, 1, 2], [1, 2, 3]) as res; -- [2,1,0]
-- 再次提醒:NULL, NaN, Inf的排序顺序:
-- 含义:
-- -Inf 是数组中的第一个。
-- NULL 是数组中的最后一个。
-- NaN 在NULL的前面。
-- Inf 在NaN的前面。
-- 出现异常:RuntimeException: Parse exception:
-- ByteFragment{[[-inf,-4,1,2,3,inf,nan,nan,NULL,NULL]], start=0, len=37}
SELECT arraySort([1, nan, 2, NULL, 3, nan, -4, NULL, inf, -inf]);
-- 17.数组翻转:arrayReverse([func,] arr, ……)
-- 如果是NULL的话在排序的过程中,根据数组的数据类型进行默认值填充。
SELECT
arrayReverse(array('a','b','c',NULL)) AS hasOneNull, -- ['','c','b','a']
arrayReverse(array('ac','ab','bc','ad',NULL)) AS hasNull, -- ['','ad','bc','ab','ac']
--网格视图: ['[NULL]','ad','bc','','ab','[NULL]','','ac'];文本视图 :['','ad','bc','','ab','','','ac']
arrayReverse(array('ac','',NULL,'ab','','bc','ad',NULL)) AS hasNullEmpty,
arrayReverse(array(NULL, 3, NULL, 2, 1)),-- [1,2,0,3,0]
arrayReverse([1,2,3,4]);-- [4,3,2,1]
-- 18.数组排序并翻转:arraySort([func,] arr, ...)
SELECT arrayReverseSort([1, 3, 3, 0]); -- [3,3,1,0]
SELECT arrayReverseSort(['hello', 'world', '!']); -- ['world','hello','!']
--RuntimeException: Parse exception: ByteFragment{[[inf,3,2,1,-4,-inf,nan,nan,NULL,NULL]], start=0, len=37}
SELECT arrayReverseSort([1, nan, 2, NULL, 3, nan, -4, NULL, inf, -inf]) as res;-- [inf,3,2,1,-4,-inf,nan,nan,NULL,NULL]
-- 下面的执行顺序为:
-- 1.首先,根据lambda函数的调用结果对源数组([1, 2, 3])进行排序。 结果是[3, 2, 1]。
-- 2.反转上一步获得的数组。 所以,最终的结果是[1, 2, 3]。
SELECT arrayReverseSort((x) -> -x, [1, 2, 3]) as res; -- [1,2,3]
SELECT arrayReverseSort((x) -> x, [1, 2, 3]) as res; -- [1,2,3]
-- 下面的执行顺序为:
-- 1.首先,根据lambda函数的调用结果对源数组(['hello','world'])进行排序。 其中,在第二个数组([2,1])中定义了源数组中相应元素的排序键。 所以,排序结果['world','hello']。
-- 2.反转上一步骤中获得的排序数组。 所以,最终的结果是['hello','world']。
SELECT arrayReverseSort((x, y) -> y, ['hello', 'world'], [2, 1]) as res;-- ['hello','world']
SELECT arrayReverseSort((x, y) -> -y, ['hello', 'world'], [2, 1]) as res;-- ['world','hello']
SELECT arrayReverseSort((x, y) -> x, ['hello', 'world'], [2, 1]) as res;-- ['world','hello']
--出现异常:Illegal type String of argument
--SELECT arrayReverseSort((x, y) -> -x, ['hello', 'world'], [2, 1]) as res;
SELECT arrayReverseSort((x, y) -> x, ['hello', 'world'], [1, 2]) as res;-- ['world','hello']
-- 19.统计数组中不重复元素的个数。arrayUniq(arr,……)
-- ① 如果传递一个参数,则计算数组中不同元素的数量。
-- ② 如果传递了多个参数,则它计算多个数组中相应位置的不同元素元组的数量
SELECT
arrayUniq([1,2,3]), -- 3
arrayUniq([1,2,2,2,3]); -- 3
SELECT
arrayUniq([1,2,3],[2,3,4]),
arrayUniq([1,2,2],[1,3,3]);
-- 20.数组的特殊功能:arrayJoin(arr) 这是一个非常有用的函数。
-- 解释:此函数将数组作为参数,并将该行在结果集中复制数组元素个数
SELECT arrayJoin([1, 2, 3] AS src) AS dst, 'Hello', src;
-- 每个元素扩大两倍;
SELECT arrayJoin([1,2,3]) * 2;
SELECT arrayJoin([-1,-2,0,1,2]) * 2;
--出现异常: Illegal types Array(UInt8) and Array(UInt8) of arguments of function multiply
--SELECT multiply(array(1,2,3), 2);
SELECT multiply(arrayJoin([-1,-2,0,1,2]), 2);
-- 每个元素缩小两倍
SELECT arrayJoin([-4,-2,0,2,4]) / 2;
SELECT divide(arrayJoin([-4,-2,0,2,4]) , 2);
-- 21.arrayDifference(arr)
-- 返回一个数组,其中包含所有相邻元素对之间的差值
SELECT arrayDifference([1,2,3,4]);-- [0,1,1,1]
SELECT arrayDifference([1,3,10,50]);-- [0,2,7,40]
-- 22. arrayDistinct(arr)返回一个包含所有数组中不同元素的数组.
-- 类似于java的Set集合,对list集合进行去重。
SELECT arrayDistinct(array(1,2,3,4,4,4)); -- [1,2,3,4]
SELECT arrayDistinct([1,2,2,3,4,2,2,5,4,5]); -- [1,2,3,4,5]
SELECT arrayDistinct(array(0,1,NULL,3,4,4,4)); -- [0,1,3,4]
-- 数组去重统计元素个数
SELECT uniq(arrayJoin([1,2,3,6,3])); -- 4 表示数组去重后元素的个数
SELECT uniqArray([1,2,3,4,1,2,3,4]); -- 4 表示数组去重后元素的个数
-- 数组元素累计
SELECT sumArray([1,2,3,4,5]);-- 15
SELECT sum(arraySum([1,2,3,4,5])); -- 15
-- 23. arrayEnumerateDense(arr) 返回与源数组大小相同的数组,指示每个元素首次出现在源数组中的位置
SELECT
arrayEnumerateDense([10,20,20,10,30]) AS numArrEnumDense,-- [1,2,2,1,3]
-- [1,1,2,3,4,1,3,5,5]
arrayEnumerateDense([10,10,2,12,3,10,12,NULL,NULL]) as arrEnumDenseHasNull,
-- [1,2,1,1,2,3]
arrayEnumerateDense([10,20,10,10,20,30]) AS arrEnumDese2;
-- 24. arrayIntersect(arr,……) 返回所有数组元素的交集。
-- 如果arr的数目只有一个,则返回它本身;如果有多个数组,则返回所有数组中元素的交集。
SELECT
-- 注意:最后得到的数组元素的顺序。(有什么影响吗?)
arrayIntersect(['one','two'],['one','two','three']) as uniStrArr1, -- ['two','one']
arrayIntersect(['aaa','bbb'],['bbb','aaa','three']) as uniStrArr2, -- ['bbb','aaa']
arrayIntersect([1,2],[1,2,3]) as uniArr1, -- [1,2]
arrayIntersect([1,2],[1,2,3],[2,3,4],[2,3,4]) as uniArr2; -- 2
SELECT
arrayIntersect([1,2], [3,4]), -- []
arrayIntersect([1,2]);-- [1,2]
-- 25.arrayReduce(agg_func, arr1, ...)
-- agg_func 为聚合函数,传入到数组当中。
-- 将聚合函数应用于数组并返回其结果.如果聚合函数具有多个参数,则此函数可应用于相同大小的多个数组。
SELECT
arrayReduce('max', [1,2,3]) AS minNum,--最大值 3
arrayReduce('min', [1,2,3]) AS maxNum,--最小值 1
arrayReduce('sum', [1,2,3]) AS sumNum;--求和 6
-- 十三、 字符串查分合并函数
--->>>>>> 字符串拆分合并函数
-- 1.splitByChar(separator, s) 将字符串以‘separator’拆分成多个子串。
-- ‘separator’必须为仅包含一个字符的字符串常量。 返回拆分后的子串的数组。
-- 如果分隔符出现在字符串的开头或结尾,或者如果有多个连续的分隔符,则将在对应位置填充空的子串。
SELECT splitByChar(',', 'hello,world!'); -- ['hello','world!']
--下面异常:Illegal separator for function splitByChar. Must be exactly one byte.
--SELECT splitByChar('or', 'hello,world!');
-- 2.splitByString(separator, s)
-- 与上面相同,但它使用多个字符的字符串作为分隔符。 该字符串必须为非空
SELECT splitByString('or','goodorniceorgreat'); -- ['good','nice','great']
-- 3.alphaTokens(s) 从范围a-z和A-Z中选择连续字节的子字符串。返回子字符串数组
SELECT alphaTokens('abca1abc'); -- ['abca','abc']
SELECT alphaTokens('abc1232abc2wer3rtty'); -- ['abc','abc','wer','rtty']
-- 4.数组元素合并函数:arrayStringConcat(arr[, sparator])
-- 使用separator将数组中列出的字符串拼接起来。
-- ‘separator’是一个可选参数:一个常量字符串,默认情况下设置为空字符串。 返回拼接后的字符串
SELECT arrayStringConcat([1,2,3], '-'); -- 出现异常,要求数组必须是字符串string类型的元素
SELECT arrayStringConcat(['one','two','three']); -- onetwothree
SELECT arrayStringConcat(['one','two','three'], '-'); -- one-two-three
SELECT arrayStringConcat(['one','two','three',''], '-');-- one-two-three- 注意:NULL不能存在arr中
--十四、位操作符
--->>>>>> 位操作符
--位操作函数适用于UInt8,UInt16,UInt32,UInt64,Int8,Int16,Int32,Int64,Float32或Float64中的任何类型。
--结果类型是一个整数,其位数等于其参数的最大位。
--如果至少有一个参数为有符数字,则结果为有符数字。如果参数是浮点数,则将其强制转换为Int64。
SELECT
bitAnd(1,0), -- 0
bitAnd(1,1), -- 1
bitAnd(1,2), -- 0
bitAnd(-1,0), -- 0
bitAnd(-1,-2), -- -2
bitAnd(-10,-1), -- -10
bitOr(1,2), -- 3
bitOr(1,0), -- 1
bitOr(2,0), -- 2
bitOr(0,2); -- 2
SELECT bitXor(1, 2), bitXor(20, 15), bitNot(2);-- 3 27 253
--十五、Hash函数:可以用于将元素不可逆的伪随机打乱。
-- 注意:伪随机!
SELECT
-- 计算字符串的MD5值。( 如果您不需要一定使用MD5,请使用‘sipHash64’函数。)
halfMD5('HELLO WORLD!'),
halfMD5(12);
SELECT
MD5('drew-zero,78967');
SELECT
-- 为任何类型的整数计算32位的哈希。 这是相对高效的非加密Hash函数
intHash32(1221232132132) AS intHash32,
-- 推荐:从任何类型的整数计算64位哈希码。 它的工作速度比intHash32函数快。
intHash64(1221232132132) AS intHash64,
-- 计算任意数量字符串的CityHash64或使用特定实现的Hash函数计算任意数量其他类型的Hash。
cityHash64('username') AS cityHash64,
-- 1.使用sha1或者sha224加密的话,只能用于字符串
-- 2.字符串 需使用单引号。
SHA1('1232131') AS sha1,
SHA224('1232131') AS sha224,
SHA256('DREW-ZERO') AS sha256;
-- URLHash(url[, N]) 一种快速的非加密哈希函数,用于规范化的从URL获得的字符串
-- 从一个字符串计算一个哈希,如果结尾存在尾随符号/,?或#则忽略。 URLHash(s,N)
-- 计算URL层次结构中字符串到N级别的哈希值,如果末尾存在尾随符号/,?或#则忽略。 URL的层级与URLHierarchy中的层级相同
-- 用处:此函数被用于Yandex.Metrica。
SELECT
URLHash('www.baidu.com'), -- 11390370829909720855
URLHash('www.baidu.com', 0), -- 11390370829909720855
--
URLHash('www.baidu.com', 1); -- 11160318154034397263
-- farmHash64(s) 计算字符串的FarmHash64。 接受一个String类型的参数。返回UInt64。
SELECT farmHash64('www.runoob.com'); -- 6668483584160323388
-- javaHash(s) 计算字符串的JavaHash。 接受一个String类型的参数。返回Int32。
SELECT javaHash('www.baidu.com'); -- 270263191
-- hiveHash(s) 计算字符串的HiveHash。 接受一个String类型的参数。返回Int32。 与JavaHash相同,但不会返回负数
SELECT hiveHash('www.baidu.com'); -- 270263191
--十六、随机函数
--->>>>>> 随机函数
-- 解释:随机函数使用非加密方式生成【伪随机】数字。
-- ① 所有随机函数都只接受一个参数或不接受任何参数。
-- ② 您可以向它传递任何类型的参数,但传递的参数将不会使用在任何随机数生成过程中。
-- ③ 此参数的唯一目的是防止公共子表达式消除,以便在相同的查询中使用相同的随机函数生成不同的随机数
-- rand() 函数:返回一个UInt32类型的随机数字,所有UInt32类型的数字被生成的概率均相等。
-- rand64() 函数:返回一个UInt64类型的随机数字,所有UInt64类型的数字被生成的概率均相等。
-- randConstant() 函数:返回一个UInt32类型的随机数字,该函数不同之处在于仅为每个数据块参数一个随机数。
SELECT
rand(), -- 1751687411
rand(10), -- 1124981728
rand64(),
rand64(10),
randConstant(),
randConstant();
-- 十七、编码函数:
-- hex(), unhex(), UUIDStringToNum(str), UUIDNumToString(str),bitmaskToList(num) ...
-- 1.hex函数编码
SELECT
-- 68656C6C6F20776F726C64212C68656C6C6F20636C69636B686F757365
hex('hello world!,hello clickhouse') AS hexStr,
hex(now()) AS hexDatetime, -- 5D414BA2
hex(toDate(now())) AS hexDate; --46BC
-- 2.接受包含36个字符的字符串,格式为“123e4567-e89b-12d3-a456-426655440000”,并将其转化为FixedString(16)返回
SELECT UUIDStringToNum('123e4567-e89b-12d3-a456-426655440000');
-- 3. 接受一个整数。返回一个UInt64类型数组,其中包含一组2的幂列表,其列表中的所有值相加等于这个整数。数组中的数字按升序排列。
-- bitmaskToArray(num)
SELECT bitmaskToArray(10); -- [2,8]
SELECT bitmaskToArray(100); -- [4,32,64]
-- 4.接受一个整数。返回一个字符串,其中包含一组2的幂列表,其列表中的所有值相加等于这个整数。列表使用逗号分割,按升序排列。
-- bitmaskToList(num)
SELECT bitmaskToList(10); -- 2,8
SELECT bitmaskToList(100); -- 4,32,64
SELECT bitmaskToList(0); -- '' 空字符串
--十八、UUID函数
--->>>>>> UUID函数
-- 1.generateUUIDv4() 返回 UUID类型的值。
SELECT generateUUIDv4() as randomUUID; -- 随机生成一个UUIDv4的字符串(b6940dfe-0dc9-4788-bac7-319d13235a2e)
SELECT replaceAll(toString(generateUUIDv4()), '-', '') AS replaceUUID; -- 9d1947ea4fcf450da5391feb6142cab6
-- 2.toUUID(s) 将string类型的值 转换成UUID类型的值
SELECT toUUID('61f0c404-5cb3-11e7-907b-a6006ad3dba0') AS uuid;
-- 3.接受一个String类型的值,其中包含36个字符且格式为xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx,
-- 将其转换为UUID的数值并以FixedString(16)将其返回。
SELECT
'612f3c40-5d3b-217e-707b-6a546a3d7b29' AS uuid, -- 612f3c40-5d3b-217e-707b-6a546a3d7b29
UUIDStringToNum(uuid) AS bytes; --a/<@];!~p{jTj={)
-- 4. UUIDNumToString() 接受一个FixedString(16)类型的值,返回其对应的String表现形式。
SELECT 'a/<@];!~p{jTj={)' AS bytes,
UUIDNumToString(toFixedString(bytes, 16)) AS uuid;
--- 二十、 URL函数:所有这些功能都不遵循RFC。它们被最大程度简化以提高性能。
--- 什么事RFC?
---- Request For Comments(RFC),是一系列以编号排定的文件。文件收集了有关互联网相关信息,以及UNIX和互联网社区的软件文件。
-- 1. 截取函数:如果URL中没有要截取的内容则返回空字符串。
SELECT protocol('http://www.baidu.com');-- http
SELECT protocol('https://www.baidu.com');-- https
SELECT protocol('www.baidu.com');-- ''
-- 获取域名。
SELECT domain('http://www.baidu.com'); -- www.baidu.com
SELECT domain('https://www.google.com.cn'); -- www.google.com.cn
-- 返回域名并删除第一个‘www.’
SELECT domainWithoutWWW('http://www.baidu.com');-- baidu.com
SELECT domainWithoutWWW('www.baidu.com');-- ''
-- 返回顶级域名。例如:.ru
SELECT topLevelDomain('http://www.runoob.com.cn'); -- cn
SELECT topLevelDomain('https://www.huse.edn'); -- edu
-- 返回“第一个有效子域名”
-- 如果顶级域名为‘com’,‘net’,‘org’或者‘co’则第一个有效子域名为二级域名。否则则返回三级域名
SELECT firstSignificantSubdomain('https://news.yandex.com.tr/'); -- yandex
-- 返回包含顶级域名与第一个有效子域名之间的内容(参阅上面内容)
SELECT cutToFirstSignificantSubdomain('https://news.yandex.com.tr/'); -- yandex.com.tr
-- 返回URL路径
SELECT path('https://blog.csdn.net/u012111465/article/details/85250030');-- /u012111465/article/details/85250030
-- 与上面相同,但包括请求参数和fragment。
SELECT pathFull('https://clickhouse.yandex/#quick-start'); -- /#quick-start
-- 返回请求参数。例如:page=1&lr=213。请求参数不包含问号已经# 以及# 之后所有的内容。
SELECT queryString('http://www.baidu.com/?page=1&lr=234'); -- page=1&lr=234 (根据?确定)
SELECT queryString('http://www.baidu.com/page=1&lr=234'); -- ''
-- 返回URL的fragment标识。fragment不包含#。
SELECT fragment('https://clickhouse.yandex/#quick-start'); -- quick-start
-- 返回请求参数和fragment标识。例如:page=1#29390。
SELECT queryStringAndFragment('https://www.baidu.com/s?ie=utf-8&rsv_sug7=100#ei-ai'); -- ie=utf-8&rsv_sug7=100#ei-ai
-- 2. 删除URL中的部分内容 (如果URL中不包含指定的部分,则URL不变。)
SELECT cutWWW('www.baidu.com');-- www.baidu.com
SELECT cutWWW('https://www.baidu.com');-- www.baidu.com
SELECT cutWWW('https://www.baidu.com');-- www.baidu.com
-- 删除请求参数
SELECT cutQueryString('http://www.baidu.com/1?page=1'); -- http://www.baidu.com/1
-- 删除fragment标识。#同样也会被删除。
SELECT cutFragment('http://www.baidu.com/#quick-demo'); -- http://www.baidu.com/
-- 删除请求参数以及fragment标识。问号以及#也会被删除。
SELECT cutQueryStringAndFragment('http://www.baidu.com/1?page=23#we'); -- http://www.baidu.com/1
-- cutURLParameter(URL, name) 删除URL中名称为‘name’的参数。下面例子中的参数是:&之后,resv,name
SELECT cutURLParameter('http://www.baidu.com/1?page=1#erre&resv=23&name=user','resv');
--二十一、IP函数
--二十二、条件函数
SELECT IF(12 > 10 , 12, 20);
SELECT 12 > 10 ? 12 : 10;
SELECT if(greater(12, 以上是关于ClickHouse安装使用Centos7环境的主要内容,如果未能解决你的问题,请参考以下文章
20210810-基于CentOS7/Linux Grafana 集成 Prometheus并实现对ClickHouse监控