Pytorch:YOLO-v5目标检测(下)
Posted Z|Star
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch:YOLO-v5目标检测(下)相关的知识,希望对你有一定的参考价值。
上篇内容介绍了如何配置YOLO-v5环境,并利用coco128数据集进行训练。本篇内容就来使用自己制作的数据集。
1.数据集标注
使用工具:LabelIMG
LabelIMG是用pyqt5编写的标注工具,界面比较简单,下载之后双击exe就可以直接使用。
(软件可在微信公众号“我有一计”中,回复“标注”获取)
软件界面:
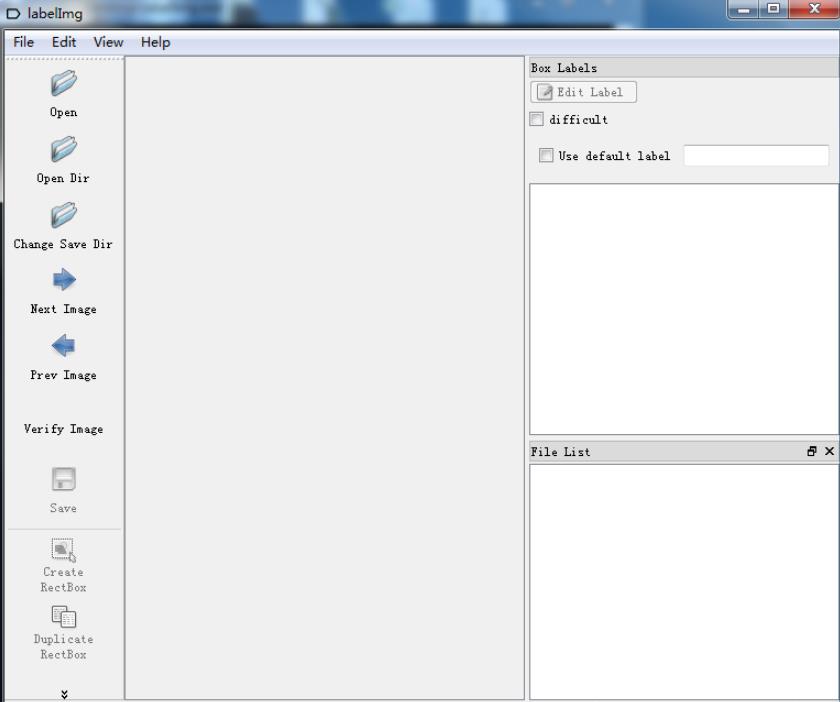
open是打开单个文件
opendir是打开文件夹
change Save Dir是修改标注存储路径
下面是一些操作的快捷键:
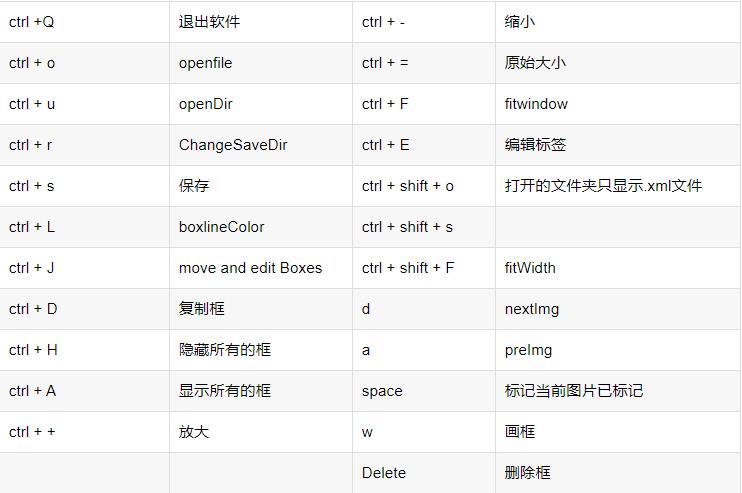
比较常用的是
w:标注,d:下一张,ctrl+S保存,熟练运用这三个键,效率还是不错的。
标注好之后,会在保存的文件夹下找到xml文件。
<annotation>
<folder>green</folder>
<filename>1.jpg</filename>
<path>E:\\traffic_ligth\\green\\1.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>224</width>
<height>224</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>green</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>135</xmin>
<ymin>4</ymin>
<xmax>148</xmax>
<ymax>19</ymax>
</bndbox>
</object>
</annotation>
其中object即为标注的对象,name为标签名
2.数据转换
标注完之后,我们已经获得了xml文件,然而这并不是yolo数据集的理想格式。
先来看看coco128的label.txt
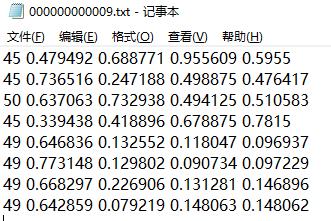
每一行代表一个框,有五个数据构成
第一个是类别标号(从0开始)
第二个是box的中心点x坐标
第三个是box的中心点y坐标
第四个是box的宽width
第五个是box的高height

所有数据都需要经过归一化处理。
于是可以通过编程,将所有的xml转化为txt
import os
import xml.etree.ElementTree as ET
dirpath = r'./yellow' # 原来存放xml文件的目录
newdir = r'./yellowlabels' # 修改label后形成的txt目录
label_youwant = 1
if not os.path.exists(newdir):
os.makedirs(newdir)
dict_info = {'smoke': 0} # 有几个 属性 填写几个
for fp in os.listdir(dirpath):
if fp.endswith('.xml'):
root = ET.parse(os.path.join(dirpath, fp)).getroot()
xmin, ymin, xmax, ymax = 0, 0, 0, 0
sz = root.find('size')
width = float(sz[0].text)
height = float(sz[1].text)
filename = root.find('filename').text
for child in root.findall('object'): # 找到图片中的所有框
sub = child.find('bndbox') # 找到框的标注值并进行读取
label = child.find('name').text
label_ = dict_info.get(label)
if label_:
label_ = label_
else:
label_ = 0
xmin = float(sub[0].text)
ymin = float(sub[1].text)
xmax = float(sub[2].text)
ymax = float(sub[3].text)
try: # 转换成yolov3的标签格式,需要归一化到(0-1)的范围内
x_center = (xmin + xmax) / (2 * width)
x_center = '%.6f' % x_center
y_center = (ymin + ymax) / (2 * height)
y_center = '%.6f' % y_center
w = (xmax - xmin) / width
w = '%.6f' % w
h = (ymax - ymin) / height
h = '%.6f' % h
except ZeroDivisionError:
print(filename, '的 width有问题')
with open(os.path.join(newdir, fp.split('.xml')[0] + '.txt'), 'a+') as f:
f.write(' '.join([str(label_youwant), str(x_center), str(y_center), str(w), str(h) + '\\n']))
print('ok')
除了输入和输出之外,label_youwant = 1用来修改第一个分类标签,由于每次在新图标注时,分类标签都默认为0,因此我这里在转换的时候手动修改。(如果有更好的方法也可以在评论区留言)
转换完之后,还需要批量修改文件名,每个图片的名称都必须和相应的txt名称对应。
我使用下面的程序进行批量修改
# -*- coding:utf8 -*-
import os
path = 'green/'
filelist = os.listdir(path)
number = 65
for item in filelist:
#print('item name is ',item)
if item.endswith('.jpg'):
src = os.path.join(os.path.abspath(path), item)
dst = os.path.join(os.path.abspath(path), str(number) + '.jpg')
number += 1
try:
os.rename(src, dst)
print('rename from %s to %s' % (src, dst))
except:
continue
修改完成之后,将数据集整理好放在和之前coco128同样的位置,并在data文件夹下创建新的配置文件,我命名为light.yaml
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../mydataset/images/train/
val: ../mydataset/images/train/
# number of classes 类别数
nc: 3
# class names 类别列表
names: ['red','yellow','green']
由于我数据量比较小,训练集和验证集不进行划分,使用同一组进行训练。
3.开始训练
完成上面这些步骤之后,就可以开始进行训练。
在train.py文件里修改–data,之后开始训练。
运行时,出现报错
'gbk' codec can't decode byte 0xb0 in position 208: illegal multibyte sequen
原因是用上面方法制作的txt文件是utf-8编码的,而程序打开文件则是用gbk解码,因此发生错误。
这时只需要修改第63行的程序段
with open(opt.data, encoding='utf-8') as f:
指定解码为utf-8即可。
我按照默认的300次进行训练,几十分钟,训练完成。
4.开始检测
在detect.py中,修改weights
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp16/weights/best.pt', help='model.pt path(s)')
导入测试图片,可以查看到效果。

我采用的数据集目标过于靠近边界,因此标签不能完全显示,但仍然能够判别出来是能成功识别到红灯red。
我们也可以在程序的第116行添加
print(names[c])
即可打印出图片中所有类别的信息,以便做进一步处理。

5.参考资料
以上是关于Pytorch:YOLO-v5目标检测(下)的主要内容,如果未能解决你的问题,请参考以下文章