机器学习模型实例及其应用
Posted MirrorML
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习模型实例及其应用相关的知识,希望对你有一定的参考价值。
机器学习模型及其应用
本次以房价预测项目为例。
一、明确机器学习的目的
-
理解问题:了解数据集中每个变量特征的含义以及对最终目的的重要程度
-
理解主要特征:项目目的变量。在本次项目中主要特征为----房价
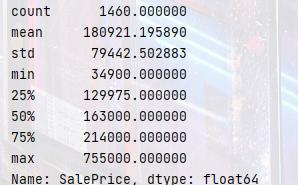
# 导入需要的模块 import pandas as pd import matplotlib.pyplot as plt import numpy as np # 用来绘图的,封装了matplot # 要注意的是一旦导入了seaborn, # matplotlib的默认作图风格就会被覆盖成seaborn的格式 import seaborn as sns from scipy import stats from scipy.stats import norm from sklearn.preprocessing import StandardScaler import warnings warnings.filterwarnings('ignore') data_train = pd.read_csv("../input/train.csv") data_train['SalePrice'].describe()
二、 数据集特征选取
1.箱线图
箱线图的判断方法
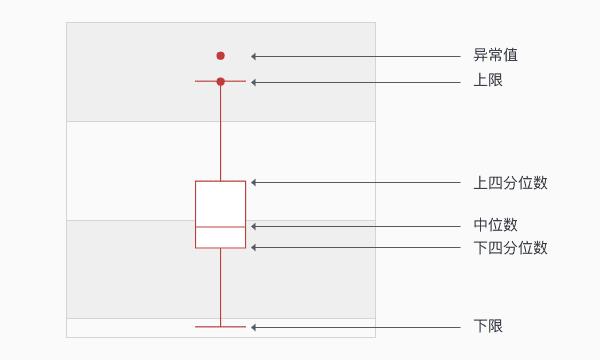
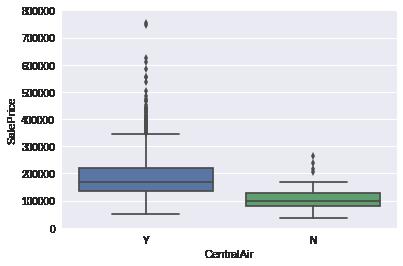
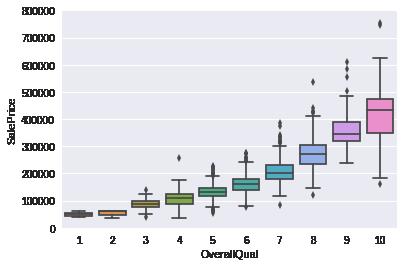
对每个特征与目的特征进行箱线图判断,一般选取特征量属性比较少的特征
# CentralAir
var = 'CentralAir'
data = pd.concat([data_train['SalePrice'], data_train[var]], axis=1)
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000)
plt.show()
# YearBuilt boxplot
var = 'YearBuilt'
data = pd.concat([data_train['SalePrice'], data_train[var]], axis=1)
f, ax = plt.subplots(figsize=(26, 12))
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000)
plt.show()
2.点线图
对每个特征与目的特征进行点线图判断,一般选取特征量属性比较多的特征
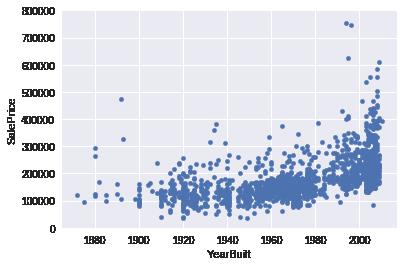
# YearBuilt scatter
var = 'YearBuilt'
data = pd.concat([data_train['SalePrice'], data_train[var]], axis=1)
data.plot.scatter(x=var, y="SalePrice", ylim=(0, 800000))
plt.show()
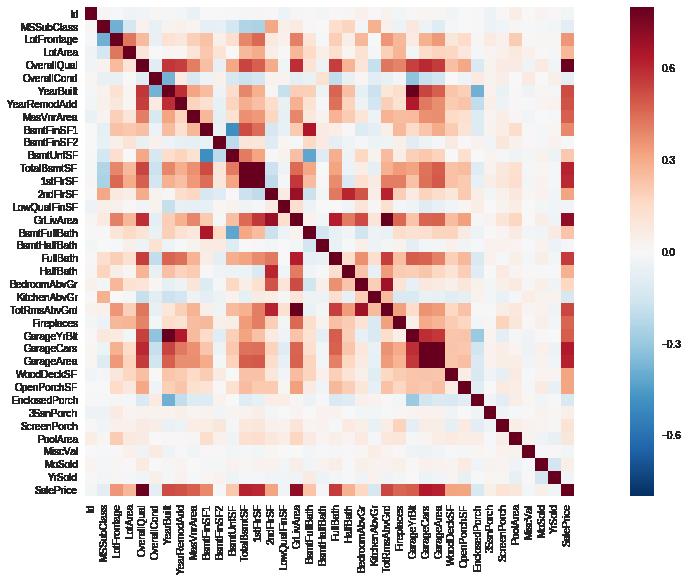
3.关系矩阵
得到各个特征之间的关系矩阵(correlation matrix)
corrmat = data_train.corr()
f, ax = plt.subplots(figsize=(20, 9))
sns.heatmap(corrmat, vmax=0.8, square=True)
plt.show()
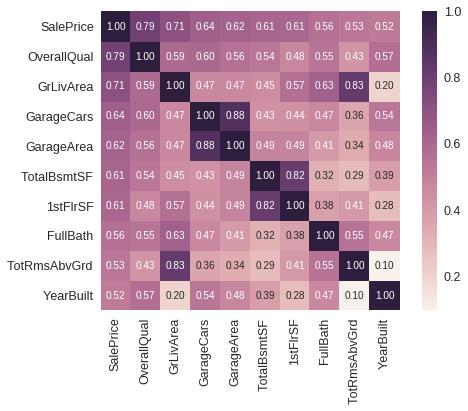
目的变量的关系矩阵
k = 10 # 关系矩阵中将显示10个特征
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(data_train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, \\
square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
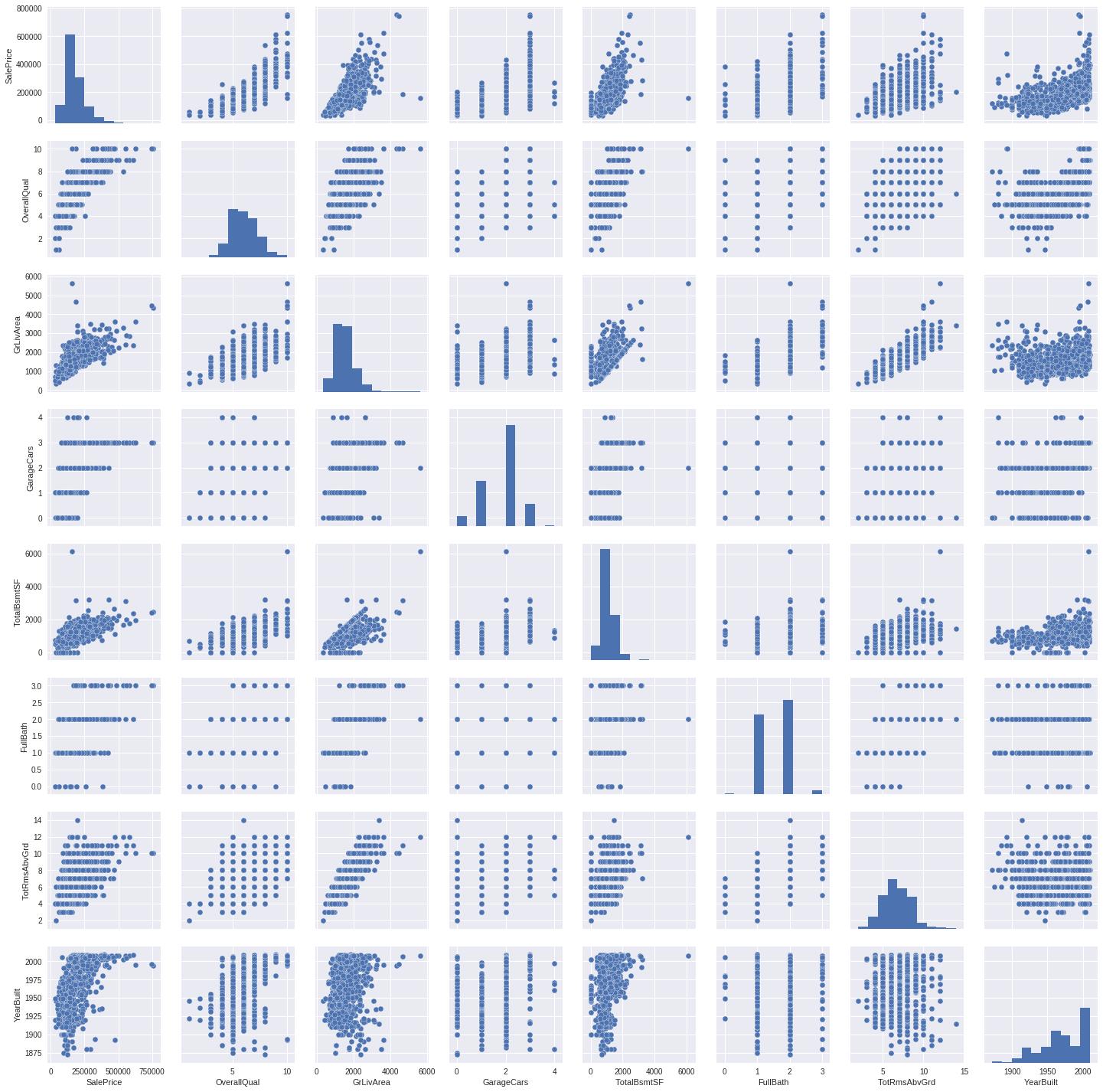
关系点图
sns.set()
cols = ['SalePrice','OverallQual','GrLivArea', 'GarageCars','TotalBsmtSF', 'FullBath', 'TotRmsAbvGrd', 'YearBuilt']
sns.pairplot(data_train[cols], size = 2.5)
plt.show()
三、数据预处理
1.数据处理
数据集中数据一般存在问题,通常采用三种策略
-
不采用策略
-
标准化
from sklearn import preprocessing #使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化 X_scaled=preprocessing.scale(X) #使用sklearn.preprocessing.StandardScaler类,使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。 x_scaled = preprocessing.StandardScaler().fit_transform(x) y_scaled = preprocessing.StandardScaler().fit_transform(y.reshape(-1,1)) -
正则化
from sklearn import preprocessing #使用preprocessing.normalize()函数对指定数据进行转换 X_normalized = preprocessing.normalize(X, norm='l2') #使用processing.Normalizer()类实现对训练集和测试集的拟合和转换 normalizer = preprocessing.Normalizer().fit(X)
2.数据集划分
一般采用8、2划分
from sklearn.model_selection import train_test_split
X_train,X_test, y_train, y_test = train_test_split(x_scaled, y_scaled, test_size=0.33, random_state=42)
四、模型选取及其训练
sklearn集成了大部分的机器学习模型,我们只需求进行模型选择和训练调参,一般采用多个模型进行训练比较结果
#随机森林
from sklearn.ensemble import RandomForestRegressor
#支持向量机和贝叶斯线性回归
from sklearn import linear_model,svm,gaussian_process
clfs = {
'svm':svm.SVR(),
'RandomForestRegressor':RandomForestRegressor(n_estimators=400),
'BayesianRidge':linear_model.BayesianRidge()
}
for clf in clfs:
#模型.fit()训练
clfs[clf].fit(X_train, y_train)
#模型.predict()预测
y_pred = clfs[clf].predict(X_test)
print(clf + " cost:" + str(np.sum(y_pred-y_test)/len(y_pred)) )
五、模型评估
使用评估指数来进行模型评估
回归问题的常用评估指数为:MSE 、MAE、RMSE、R2
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
mse = mean_squared_error(y_test,predictions)
mae = mean_absolute_error(y_test,predictions)
rmse = math.sqrt(mse)
r2_score = r2_score(y_test,predictions)
print("mse:",mse)
print("mae:",mae)
print("Rmse:",rmse)
print("r2:",r2_score)
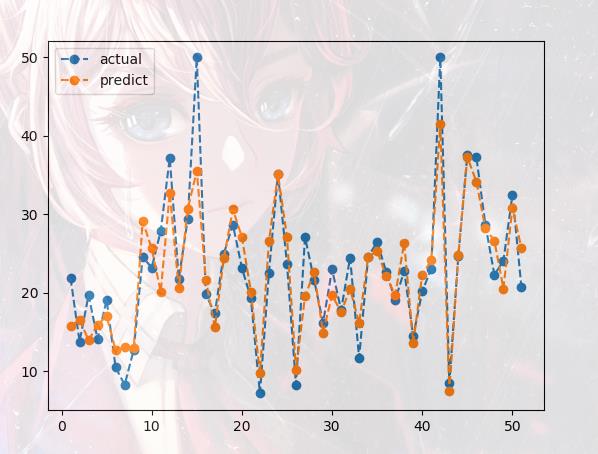
如果我们想要查看真实与预测的对比。我们需要绘制对比图线
import matplotlib.pyplot as plt
temp = [i for i in range(1,52)]
plt.plot(temp,y_test,'o--',label = "actual")
plt.plot(temp,predictions,'o--',label = "predict")
plt.legend()
plt.show()
六、参考
kaggle入门项目https://www.kaggle.com/marsggbo/kaggle
以上是关于机器学习模型实例及其应用的主要内容,如果未能解决你的问题,请参考以下文章