机器学习之集成学习
Posted MirrorML
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之集成学习相关的知识,希望对你有一定的参考价值。
机器学习之集成学习
集成学习
基本概念
集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。
集成学习模型的输出代表模型的输出结果。

集成学习的一般结构为:先产生一组“个体学习器”,再用某种策略将它们结合起来。集成中只包含同种类型的个体学习器,称为同质,当中的个体学习器亦称为“基学习器”,相应的算法称为“基学习算法”。集成中包含不同类型的个体学习器,称为“异质”,当中的个体学习器称为“组建学习器”。
要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有多样性,即个体学习器间具有差异。

根据个体学习器的生成方式,目前的集成学习方法大致可以分为两类:
- 个体学习器间存在强依赖关系、必须串行生成的序列化方法,代表为Boosting。
- 个体学习器间不存在强依赖关系、可同时生成的并行化方法,代表为Bagging和随机森林。
常用集成学习框架
Bagging
Bagging是bootstrap aggregating的简写。
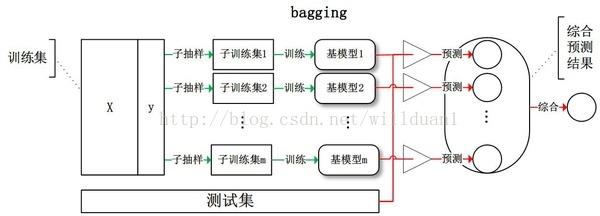
Bootstrap
有放回抽样的一种方法,保证构建数据集时的多样性,目的为了得到统计量的分布以及置信区间。
随机森林
随机森林是bagging的一个特化进阶版,所谓的特化是因为随机森林的弱学习器都是决策树。所谓的进阶是随机森林在bagging的样本随机采样基础上,又加上了特征的随机选择,其基本思想没有脱离bagging的范畴。
Boosting
其主要思想是将弱分类器组装成一个强分类器。在PAC(probably approximately correct,概率近似正确)学习框架下,则一定可以将弱分类器组装成一个强分类器。

Stacking
Stacking方法是指训练一个模型用于组合其他各个模型。首先我们先训练多个不同的模型,然后把之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。理论上,Stacking可以表示上面提到的两种Ensemble方法,只要我们采用合适的模型组合策略即可。但在实际中,我们通常使用logistic回归作为组合策略。
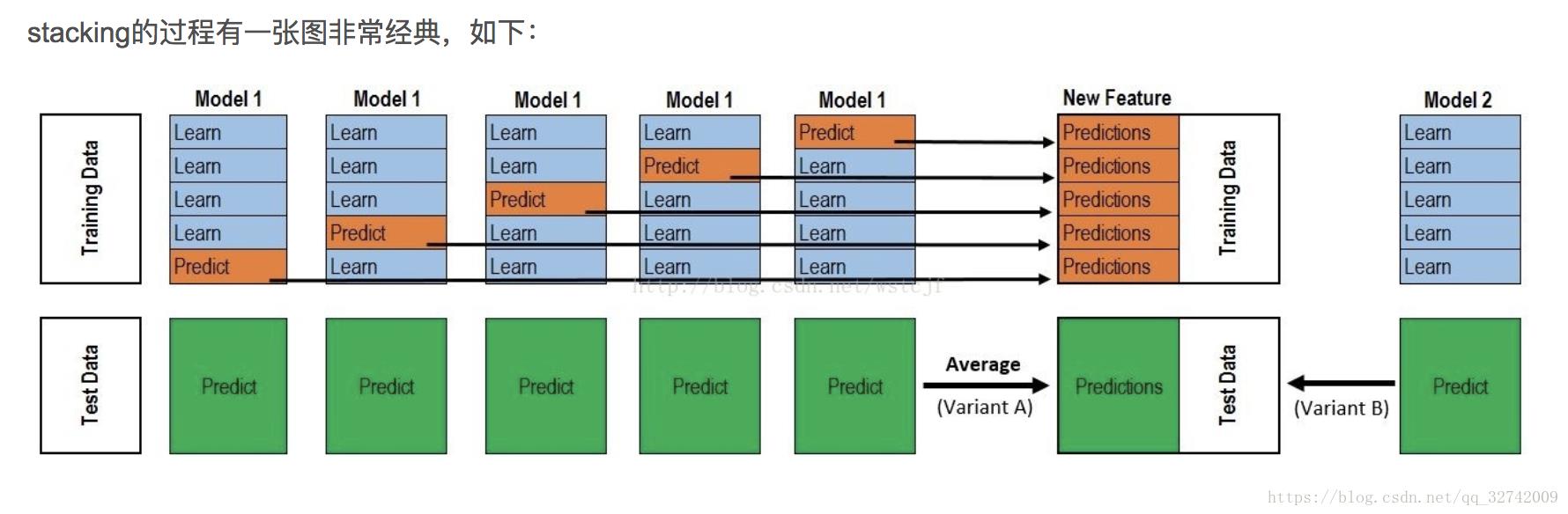
# Stacking是一种集成学习框架,由基学习器和元学习器组成。训练过程如下:
# 首先将原始数据划分为训练集和测试集,然后将训练集进行K-Fold交叉验证。将基学习器对K-Fold交叉验证
# 过程中的测试集进行预测,然后重新构建特征空间作为元学习器(第二层学习器)的输入,元学习器对测试集的输出
# 作为Stacking模型的整体预测结果。
# Stacking框架训练过程如下:
import numpy as np
from sklearn.svm import SVR
from sklearn.datasets import load_boston
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
import os
import pickle as pk
def DT_train_save(X_train,Y_train):
if not os.path.exists("model/DT"):
os.makedirs("model/DT")
print(X_train.shape)
# DT_train_save是决策树基学习器的训练过程
print("决策树基学习器开始训练...")
# 定义决策树学习器
DT_learner = DecisionTreeRegressor()
# K-Fold交叉验证过程
sub_data_train = np.zeros(shape=(X_train.shape[0],1))
print("==========")
print(sub_data_train.shape)
sub_data_test = np.zeros(shape=(X_test.shape[0],5))
for i,(train_index,test_index) in enumerate(kf.split(X_train)):
print(train_index)
print("第",i,"轮开始训练")
x_train = X_train[train_index]
y_train = Y_train[train_index]
x_test = X_train[test_index]
y_test = Y_train[test_index]
DT_learner.fit(x_train,y_train)
with open("model/DT/model" + str(i) + ".pkl","wb")as f:
pk.dump(DT_learner,f)
predictions = DT_learner.predict(x_test)
print("==================")
print(predictions.shape)
sub_data_train[test_index] = predictions.reshape(-1,1)
# 对原始数据进行预测(X_test)
y_predict = DT_learner.predict(X_test)
sub_data_test[:,i] = y_predict
data_train[:,0] = sub_data_train.reshape(1,-1)
data_test[:,0] = np.mean(sub_data_test,axis=1)
def SVM_train_save(X_train,Y_train):
if not os.path.exists("model/SVM"):
os.makedirs("model/SVM")
# SVM_train_save是支持向量机基学习器的训练过程
print("开始训练支持向量机基学习器:")
# 定义一个支持向量机学习器
svm_learner = SVR()
# 定义两个零矩阵来保存K-Fold交叉验证过程中的结果
sub_data_train = np.zeros(shape=(X_train.shape[0],1))
sub_data_test = np.zeros(shape=(X_test.shape[0],5))
for i,(train_index,test_index) in enumerate(kf.split(X_train)):
x_train = X_train[train_index]
y_train = Y_train[train_index]
x_test = X_train[test_index]
# 使用训练集和测试集训练svm基学习器
svm_learner.fit(x_train,y_train)
with open("model/SVM/model" + str(i) + ".pkl","wb") as f:
pk.dump(svm_learner,f)
predictions = svm_learner.predict(x_test)
sub_data_train[test_index] = predictions.reshape(-1,1)
y_predict = svm_learner.predict(X_test)
sub_data_test[:,i] = y_predict
data_train[:,1] = sub_data_train.reshape(1,-1)
data_test[:,1] = np.mean(sub_data_test,axis=1)
def Linear_train_save():
# Linear是线性回归基学习器的训练过程
# 定义线性回归基学习器
if not os.path.exists("model/LR"):
os.makedirs("model/LR")
print("开始训练线性回归元学习器:")
meta_model = LinearRegression()
meta_model.fit(data_train,Y_train)
with open("model/LR/mdoel.pkl","wb")as f:
pk.dump(meta_model,f)
y_predict = meta_model.predict(data_test)
mse = mean_squared_error(Y_test,y_predict)
mae = mean_absolute_error(Y_test,y_predict)
score = r2_score(Y_test,y_predict)
print("mse:",mse)
print("mae:",mae)
print("r2:",score)
temp = [i for i in range(Y_test.shape[0])]
plt.plot(temp,y_predict,"o--",label = "predict")
plt.plot(temp,Y_test,"o--",label = "actual")
plt.show()
if __name__ == '__main__':
data = load_boston()
x = data["data"]
y = data["target"]
# 对数据集进行划分为训练集和测试集
kf = KFold(n_splits=5, shuffle=True, random_state=42)
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(x,y,test_size=0.1,shuffle=True)
# data_train:基学习器训练完成后对K-Fold交叉验证过程中测试集拼接矩阵。
# data_train和data_test 第一维度跟X_train,x_test第一维一致,第二维度为基学习器个数。
data_train = np.zeros(shape=(X_train.shape[0],2))
data_test = np.zeros(shape=(X_test.shape[0],2))
# 定义基学习器训练过程
# 决策树训练过程
DT_train_save(X_train,Y_train)
# 支持向量机训练过程
SVM_train_save(X_train,Y_train)
# 次级学习器训练过程
Linear_train_save()
参考
David_Hdw的博客https://blog.csdn.net/perfect1t/article/details/83684995
理想几岁的博客 https://www.cnblogs.com/zongfa/p/9304353.html
以上是关于机器学习之集成学习的主要内容,如果未能解决你的问题,请参考以下文章