数据在计算机中的表示
Posted badman250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据在计算机中的表示相关的知识,希望对你有一定的参考价值。
整数
整型在内存中以补码的形式存储,浮点数则没有补码之说,只需要规定指数与尾数。
主要有三个原因:1,使用补码可以将符号位和数值域统一处理;2,加法和减法可以统一处理(cpu只有加法器);3,补码与原码相互转换,运算过程相同的,不需要额外的硬件电路。
正数的补码和原码相同,负数的补码是将该数的绝对值的二进制形式按位取反再加1。
此外不同架构的计算机有不同的字节序,分为大端和小端存储。小端字节序存储:数据的低字节存到低地址处,高字节存到高地址处。大端字节序存储:数据的低字节存到高地址处,高字节存到低地址处。
浮点数表示法
浮点数,不采用补码表示,在计算机系统的发展过程中,业界曾经提出过许多种表达方法,比较典型的有浮点数(Floating Point Number)和定点数(Fixed Point Number)。定点数表达法的缺点就在于其形式过于僵硬,固定的小数点位置决定了固定位数的整数部分和小数部分,不利于同时表达特别大的数或者特别小的数。因此,最终绝大多数现代的计算机系统没有采纳,而是使用了的浮点数表达法。
20 世纪 80 年代(在没有制定 IEEE 754 标准之前),业界还没有一个统一的浮点数标准。很多计算机制造商根据自己的需要来设计自己的浮点数表示规则,以及浮点数的执行运算细节。另外,常常并不太关注运算的精确性,而把实现的速度和简易性看得比数字的精确性更重要,给代码的可移植性造成了重大的障碍。
1976 年,Intel 公司打算为其 8086 微处理器引进一种浮点数协处理器时,意识到作为芯片设计者的电子工程师和固体物理学家也许并不能通过数值分析来选择最合理的浮点数二进制格式。于是,他们邀请加州大学伯克利分校的 William Kahan 教授(数值分析家)来为 8087 浮点处理器(FPU)设计浮点数格式。William Kahan 教授又找来两个专家协助他,于是就有了 KCS 组合(Kahn、Coonan和Stone),并共同完成了 Intel 公司的浮点数格式设计。
由于Intel公司的KCS浮点数格式完成得如此出色,IEEE(Institute of Electrical and Electronics Engineers,电子电气工程师协会)决定采用一个非常接近 KCS 的方案作为 IEEE 的标准浮点格式。IEEE 于1985 年制订了二进制浮点运算标准 IEEE 754(IEEE Standard for Binary Floating-Point Arithmetic,ANSI/IEEE Std 754-1985),该标准限定指数的底为 2,并于同年被美国引用为 ANSI 标准。目前几乎所有的计算机都支持 IEEE 754 标准,大大地改善了科学应用程序的可移植性。
考虑到 IBM System/370 的影响,IEEE 于 1987 年推出了与底数无关的二进制浮点运算标准 IEEE 854,并于同年被美国引用为 ANSI 标准。1989 年,国际标准组织 IEC 批准 IEEE 754/854 为国际标准,标准号改为 IEC 60559。现在,几乎所有的浮点处理器完全或基本支持 IEC 60559。
IE754
IEEE 754 的单精度与双精度浮点格式总结

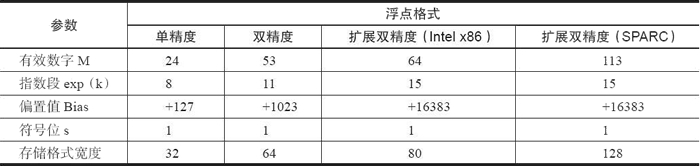
根据国际标准IEEE754,任意一个二进制浮点数V可以表示为下面的形式:
(-1)^S*M*2^E
- (-1)^S表示符号位,当S=0时,V为正数;当S=1时,V为负数。
- M表示有效数字,大于等于1,小于2。
- 2^E表示指数位。
对于32位的浮点数和64位浮点数的不同规定:
32位的浮点数,最高1位是符号位S,接着是8位的指数E,剩下的23位是有效数字M。
64位的浮点数,最高1位是符号位S,接着的11位是指数E,剩下的52位是有效数字M。
以下几点注意:
对于有效数字M,因为其值大于等于1而小于2,为了能够利用23位(52位)表示更多的数据,IEEE754规定保存M时默认这个数的第一位为1,所以只保存后面的部分(小数点后的位)。然后等到读取此数的时候,再把第一位的1加上去。
对于指数E,为了能够表示负数的指数,IEEE754规定,E的真实值必须再加上一个中间数,对于8位的E,这个中间数为127;对于11位的E,这个中间数是1023。
当E全为0时,读取该数字时有效数字M不再加上第一位的1,因为这是一个无限接近与0的数字,表示正负0;当E全为1的时候,若M全为0,则表示一个正负无穷大的数。
浮点表示案例
这个是一个非常有意思的实验,大家可以随便找台机器来测试一下,共两段代码可以直接编译。f1.c如下:
#include <iostream>
#include <string>
using namespace std;
int main() {
const float x=1.1;
const float z=1.123;
float y=x;
for(int j=0;j<90000000;j++)
{
y*=x;
y/=z;
y+=0.1f;
y-=0.1f;
}
return 0;
}
f2.c代码如下:
#include <iostream>
#include <string>
using namespace std;
int main() {
const float x=1.1;
const float z=1.123;
float y=x;
for(int j=0;j<90000000;j++)
{
y*=x;
y/=z;
y+=0;
y-=0;
}
return 0;
}
运行发现f1和f2相差巨大。
# time ./f1
real 0m1.866s
user 0m1.867s
sys 0m0.001s
# time ./f2
real 0m13.904s
user 0m13.910s
sys 0m0.000s
上面两段代码的唯一差别就是第一段代码中y+=0.1f,而第二段代码中是y+=0。由于y会先加后减同样一个数值,照理说这两段代码的作用和效率应该是完全一样的。但是y+=0的那段代码比y+=0.1f足足慢了7倍。我们来看下浮点表示。
以数值5.2为例,先不考虑指数部分,先单纯的将十进制数改写成二进制(32位为例)。 整数部分很简单,5.即101.。小数部分相当于拆成是2^-1一直到2^-N的和。例如: 0.2 = 0.125+0.0625+0.007825+0.00390625即2^-3+2^-4+2^-7+2^-8....,也即.00110011001100110011。然后规格化,在有了一串二进制101.00110011001100110011。原理很简单就是保证小数点前只有一个bit。于是我们就得到了以下表示:1.0100110011001100110011 * 2^2。接下来就是要把bit填充到三个组成部分中去了。最后一步进行填充指数部分(Exponent)。之前说过需要以127作为偏移量调整。因此2的2次方,指数部分偏移成2+127即129,表示成10000001填入。 整数部分除了简单的填入外,需要特别解释的地方是1.010011中的整数部分1在填充时被舍去了。因为规格化后的数值整部分总是为1。
在了解完浮点数的表达以后,不难看出浮点数的精度和指数范围有很大关系。最低不能低过2^-7-1最高不能高过2^8-1(剔除了指数部分全0和全1的特殊情况)。如果超出表达范围那么不得不舍弃末尾的那些小数,称为overflow和underflow。当我们要表示一个:1.00001111*2^-7的超小数值的时候就无法用规格化数值表示,当多次做低精度浮点数舍弃的后,就会出现除数为0的exception,导致异常。精度失准严重起来可以带来重大灾难。
例如,1991 年 2 月 25 日,MIM-104 爱国者导弹电池失去作用,使其无法在沙特阿拉伯宰赫兰拦截来袭的飞毛腿导弹,导致美国陆军第 14 军需分队的 28 名士兵死亡。
于是乎就出现了Denormalized Number(称非规格化浮点)。他和规格浮点的区别在于,规格浮点约定小数点前一位默认是1。而非规格浮点约定小数点前一位可以为0,这样小数精度就相当于多了最多2^22范围。
但精度的提升是有代价的。由于CPU硬件只支持或者默认对一个32bit的二进制使用规格化解码。如果需要支持32bit非规格数值的转码和计算的话,需要额外的编码标识,也就是需要额外的硬件或者软件层面的支持。一般来说,由软件对非规格化浮点数进行处理将带来极大的性能损失,而由硬件处理的情况会稍好一些,但在多数现代处理器上这样的操作仍是缓慢的。极端情况下,规格化浮点数操作可能比硬件支持的非规格化浮点数操作快100倍。
回到实验部分,由于浮点数表示范围有限,精度受限于指数和底数部分的长度,超过精度的小数部分将会被舍弃(underflow)。为了表示更高精度的浮点数,出现了非规格化浮点数,但是计算成本非常高。
实验中通过几十上百次的循环后,y中存放的数值无限接近于零。CPU将他表示为精度更高的非规格化浮点。而当y+0.1f时为了保留跟重要的底数部分,之后无限接近0(也即y之前存的数值)被舍弃,当y-0.1f后,y又退化为了规格化浮点数,所以每次y*x和y/z时,CPU都执行的是规划化浮点运算。而当y+0,由于加上0值后的y仍然可以被表示为非规格化浮点,因此后面的循环运算中CPU会使用非规格浮点计算,效率就大大降低了。
其实程序内部也是有办法控制非规范化浮点的使用的。在相关程序的上下文中加上fesetenv(FE_DFL_DISABLE_SSE_DENORMS_ENV);可以迫使CPU放弃使用非规范化浮点计算,提高性能。或者编译时候加上参数: -ffast-math。
g++ -o f2 f2.c -ffast-math
# time ./f2
real 0m1.079s
user 0m1.079s
sys 0m0.001s
以上是关于数据在计算机中的表示的主要内容,如果未能解决你的问题,请参考以下文章