一文入门XML之实例解析
Posted Python数据分析实例
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文入门XML之实例解析相关的知识,希望对你有一定的参考价值。
点击关注上方“Python数据分析实例”
设为“置顶或星标”,送达干货不错过
一、什么是 XML?
XML (eXtensible Markup Language)指可扩展标记语言,标准通用标记语言的子集,仅仅是纯文本,简称XML。
是一种用于标记电子文件使其具有结构性的标记语言。
是各种应用程序之间进行数据传输的最常用的工具。
XML 指可扩展标记语言(EXtensible Markup Language)
XML 是一种标记语言,很类似 html
XML 的设计宗旨是传输数据,而HTML做页面展示,显示数据
XML 标签没有被预定义。可自行定义标签。
XML 被设计为具有自我描述性。
XML 是 W3C 的推荐标准。
二、XML的用途?
xml被用于传输和存储数据及配置文件,应用于web开发。
三、XML的格式?
XML 树结构:形成了一种树结构,它从“根部”开始,然后扩展到“枝叶”。
XML 文档必须包含根元素,该元素是所有其他元素的父元素。
//1.声明信息,用户描述xml的版本和编码方式<?xml version="1.0" encoding="UTF-8?>
//2.根元素,有且仅有一个根元素,root
//3.xml大小写敏感
//4.标签成对,需要正确嵌套
//5.XML的属性值须加引号
什么是 XML 元素?
元素-由开始标签、元素内容和结束标签组成
XML 元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。
元素可包含其他元素、文本或者两者的混合物。元素也可以拥有属性。
XML 元素是可扩展,以携带更多的信息。以下为嵌套元素,表示记录多个参数。
<meter id="2" name="000000000002" conn="conn">
<function id="1" name="000000000002-1090" coding="01A10" error="192" sample_time="20210115175900">数据1</function>
< function id="2" name=”000000000002-xxxx” coding="XXX" error="XXX"sample_time="YYYYMMDDHHMMSS">数据2</function>
</meter>
XML 命名规则?
名称可以含字母、数字以及其他的字符
名称不能以数字或者标点符号开始
名称不能以字符 “xml”(或者 XML、Xml)开始
名称不能包含空格
XML 属性?
XML 元素可以在开始标签中包含属性,类似 HTML。
属性 (Attribute) 提供关于元素的附加信息。采集点编码name与数据无关,但是对需要处理这个元素的程序来说是关键标识,起到标识xml元素的作用,毕竟一般xml包中同元素名记录不止一条。
<meter id="1001" name="000000000001" conn="conn"> xxx</meter>XML 属性值必须加引号,单引号和双引号均可使用。
<meter name="000000000001">注释:如果属性值本身包含双引号,那么有必要使用单引号包围
使用属性的一些问题:
属性无法包含多重的值(元素可以)
属性无法描述树结构(元素可以)
属性不易扩展(为未来的变化)
尽量使用元素来描述数据。
有效的XML文档?
首先必须是格式良好的。使用DTD和XSD(XML Schema)定义约束,在此不作详细介绍。
四、一个 XML 文档实例
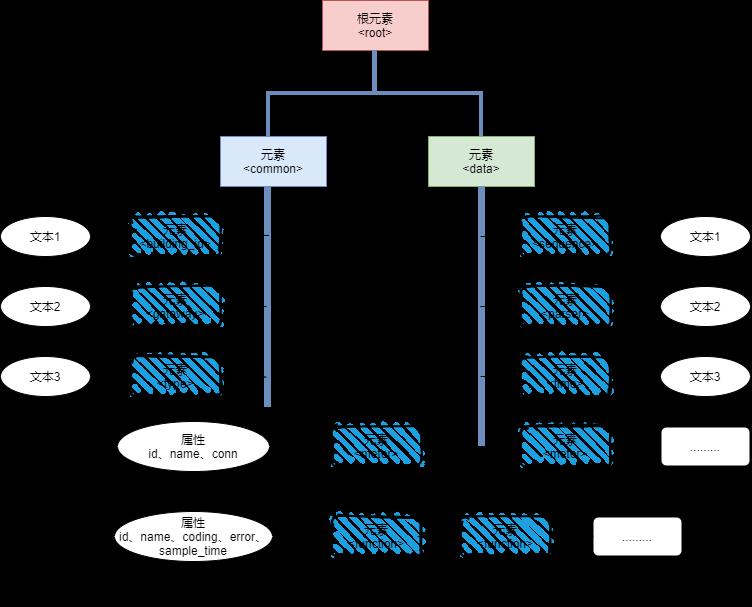
实例树结构如下图:
作图工具网址:https://app.diagrams.net/
例子中的根元素是 <root>。文档中的所有 <common> 元素、 <data> 元素都被包含在<root> 中。
<common> 元素有 3 个子元素:<building_id>、< gateway_id>、<type>。
<data> 元素有 5个子元素:<sequence>、< parser>、<time>、<meter>、<function>。
<?xml version="1.0" encoding="UTF-8"?> <!--声明:定义xml版本和编码信息-->
<root>
<!--通用部分--> 注释
<!--
building_id:建筑编号
gateway_id:采集器编号
type:远传数据包的类型,设置为“report” -->
<common>
<building_id>xxxxxx</building_id>
<gateway_id>01</gateway_id>
<type>report</type>
</common>
<!--能耗远传--> 注释
<!--操作类型:report:采集器定时上报的数据
元素有5种类型:
1、sequence元素:采集器向服务器发送数据的序号
2、parser元素:向服务器发送的数据是否经采集器解析过
3、time元素:数据采集时间
4、meter元素:计量装置的设备号,具有id、name属性,每个计量装置编号需不同
5、function元素:每个计量装置的具体采集功能,具有下列4种属性:
id属性:计量装置的数据采集功能编号(供多功能电能表使用)
name属性:为所属计量装置编号-采集参数编号,注意正向有功电能必须加后缀“-1090”
coding属性:能耗数据分类/分项编码
error属性:该功能出现错误的状态码,192表示没有错误,0表示计量装置离线
sample_time属性:采集时间-->
<data operation="report">
<sequence>25</sequence>
<parser>yes</parser>
<time>20210115180000</time>
<meter id="1001" name="000000000001" conn="conn">
<function id="1" name="000000000001-1090" coding="01A10" error="192" sample_time="20210115175909">数据1</function>
<function id="2"name=”000000000001-xxxx” coding="XXX" error="XXX"sample_time="YYYYMMDDHHMMSS">数据2</function>
</meter>
<meter id="2" name="000000000002" conn="conn">
<function id="1" name="000000000002-1090" coding="01A10" error="192" sample_time="20210115175900">数据1</function>
< function id="2" name=”000000000002-xxxx” coding="XXX" error="XXX"sample_time="YYYYMMDDHHMMSS">数据2</function>
</meter>
</data>
</root>
五、xml解析技术(读写操作)
Python有非常非常多的工具来处理 XML。常见的xml解析技术:
1、DOM解析
官方提供的解析方式,基于xml树解析。
2、SAX解析
基于事件的解析,适用于数据量较大的XML.
3、ET解析
xml.etree.ElementTree模块,简称ET。无须加载整个文档到内存,轻量级API,本次以它来演示解析过程。
4、DOM4J解析
第三方,开源免费,是JDOM的升级版,使用接口。
5、lxml解析并结合XPath提取元素
可参考以往推文:
读取xml文件
import pandas as pd
import xml.etree.ElementTree as ET
pd.set_option("expand_frame_repr",False)
def read_xml(xmlFileName):
with open(xmlFileName, 'r') as xml_file:
#读取数据,以树结构存储
tree = ET.parse(xml_file)
# 提取树根节点
root = tree.getroot()
# 返回DataFrame数据
return pd.DataFrame(list(iter_records(root))).T
def iter_records(root): #生成器方法,每次调用返回一对值,直到循环结束
'''
解析所有记录
'''
for data in root.iter(tag='data'):
# 保存字典
temp_dict = {}
# 遍历所有字段
for meter in data:
for function in meter:
temp_dict[function.attrib['name']] = function.text
# 生成值
yield temp_dict
# XML数据源路径
r_filenameXML = r'..data.xml'
#解析数据
xml_read = read_xml(r_filenameXML)
xml_read.to_excel(r".. est.xlsx")
print(xml_read.head(20))
找到感兴趣的元素?
Element 对象有一个 iter 方法可以对子结点进行深度优先遍历。ElementTree 对象也有 iter 方法来提供便利。
<common> 元素、 <data> 元素都被包含在<root> 中,如果我们仅对<data> 元素
内数据感兴趣,遍历所有的元素,然后 iter 方法接受一个标签名字,然后只遍历指定标签的元素。
for data in root.iter(tag='data'):
一个更加有效的办法是使用 XPath 支持。
可参考推文:
Element 有一些关于寻找的方法可以接受 XPath 作为参数。find 返回第一个匹配的子元素, findall 以列表的形式返回所有匹配的子元素, iterfind 为所有匹配项提供迭代器。这些方法在 ElementTree 里面也有。
创建XML文件
以下简单演示创建xml数据包
当然实际更复杂一点,XML 文档经常有一个对应的数据库,其中的字段会对应 XML 文档中的元素。一般使用数据库的名称规则来命名 XML 文档中的元素。从数据库获取数据,根据表结构特点,提取处理相关数据插入到xml文件的指定位置,打包成xml包。
w_filenameXML =r'.Desktop est est.xml'
def write_xml(xmlFileName, data):
# 以写入打开文件
with open(xmlFileName, 'w') as xmlFile:
# 写入头部
xmlFile.write('<?xml version="1.0" encoding="UTF-8"?>
')
xmlFile.write('<root>
')
# 写数据
xmlFile.write('
'.join(data.apply(xml_encode, axis=1)))
# 写尾部
xmlFile.write('
</root>')
def xml_encode(row):
# 标记data节点开始标签
xmlItem = ['<data>']
# 给行中每个字段加固定xml格式
for field in row.index:
xmlItem.append('<meter name="{0}">{1}</meter>'.format(field, row[field]))
# 标记data节点结束标签
xmlItem.append('</data>')
# 返回字符串
return '
'.join(xmlItem)
# 写入xml格式文件
write_xml(w_filenameXML, xml_read)最后数据创建完成后,为保证数据的安全,还需加密处理才能通过网络远程传输。
参考:https://www.w3school.com.cn/xml/xml_elements.asp
这是一个能学到技术的公众号,欢迎关注 Python数据分析实例
长按二维码,关注我的公众号 微信改版,快快设为 星标 吧⭐
记得点在看哦 以上是关于一文入门XML之实例解析的主要内容,如果未能解决你的问题,请参考以下文章