XML解析入门(Java版)
Posted 码踏飞燕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XML解析入门(Java版)相关的知识,希望对你有一定的参考价值。
XML解析常见的方式有三种,这三种方式都是JDK原生支持的解析方式,分别是:
① DOM(Document Object Model)解析方式
② SAX(Simple API for XML)解析方式
③ 从JDK6.0版本开支持的StAX(Streaming API for XML)解析方式
01
DOM
DOM是基于树形结构的XML解析方式,它会将整个XML文档读入内存并构建一个DOM树,基于这棵树形结构对各个节点(Node)进行操作。
XML文档中的每个成分都是一个节点
整个文档是一个文档节点
每个XML标签对应一个元素节点
包含在XML标签中的文本是文本节点
每一个XML属性是一个属性节点
注释属于注释节点
02
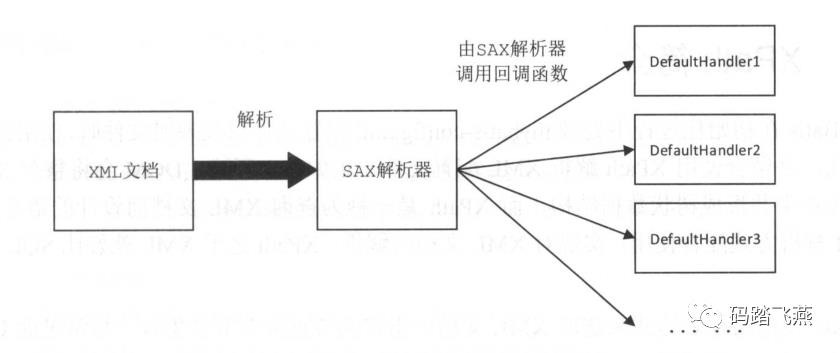
03
StAX
JAXP是JDK提供的一套用于解析XML的API,它很好地支持DOM和SAX解析方式,JAXP是JavaSE的一部分,它由javax.xml、org.w3c.dom、org.xml.sax包及其子包组成。从JDK6.0开始,JAXP开始支持SjAX解析方式。
StAX解析方式与SAX解析方式类似,也是把XML文档作为一个事件流进行处理,不同之处在于StAX采用的是“拉模式”,即应用程序通过调用解析器推进解析的流程。在StAX解析方式中应用程序控制着整个解析过程的推进,可以简化应用处理XML文档的代码,并且决定何时停止解析,而且StAX可以同时处理多个XML文档。
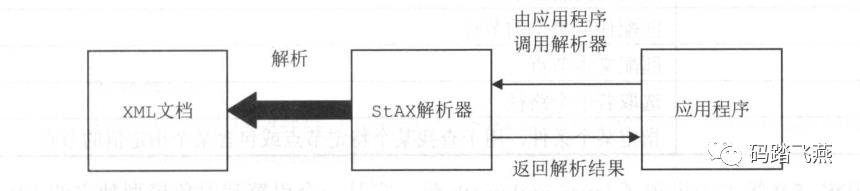
StAX包含两套处理XML文档的API,分别提供了不同程度的抽象:
① 基于指针的API,这是一种低层的API,效率高但是抽象程度较低。
② 基于迭代器的API,它允许应用程序把XML文档作为一系列事件对象来处理,效率略低但是抽象程度较高。
04
XPath入门
之所以要讲讲XPath,是因为XPath是DOM解析的不可或缺的工具。MyBatis在初始化过程中,会逐步解析配置XML和众多映射XML,使用的是DOM解析方式,并结合XPath。
DOM解析会将整个XML文档加载进内存形成一颗树形结构,而XPath是一种为查询XML文档而设计的语言,与DOM解析方式配合使用,实现对XML文档的解析。XPath于XML就好比SQL语句于mysql一样重要。
XPath使用路径表达式来选取XML文档中指定的节点或者节点集合,与常见的URL路径有些类似。
常用的XPath表达式:
| 表达式 |
含义 |
| nodename |
选取指定节点的所有子节点 |
| / |
从根节点选取指定节点 |
| // |
根据指定的表达式,在整个文档中选取匹配的节点,这里并不会考虑匹配节点在文档中的位置 |
| . |
选取当前节点 |
| .. |
选取当前节点的父节点 |
| @ |
选取属性 |
| * |
匹配任何元素节点 |
| @* |
匹配任何属性节点 |
| node() |
匹配任何类型的节点 |
| text() |
匹配文本节点 |
| | |
选取若干个路径 |
| [] |
指定某个条件,用于查找某个特定节点或包含某个指定值的节点 |
JDK 5.0推出了javax.xml.xpath包,它是一个引擎和对象模型独立的XPath库。下面就以一个XPath结合DOM解析方式的示例,会存在一个XML文件library.xml,里面定义了多本书籍的信息,还有一个DTD文件library.dtd,它是约束library.xml文件的规范,可以转场至 了解学习,若没有这份规范,程序会报错:
org.xml.sax.SAXParseException; systemId: file:.../test/library.xml; lineNumber: 13; columnNumber: 10; 文档根元素 "library" 必须匹配 DOCTYPE 根 "null"。这里先贴出XML文件和DTD文件,library.xml和library.dtd要放在同一目录下:
library.xml
<library><book year="2000" month="4"><title>西游记</title><author>吴承恩</author><publisher>中华书局</publisher><price>50.5</price></book><book year="2005" month="9"><title>红楼梦</title><author>曹雪芹</author><publisher>长江书局</publisher><price>78</price></book><book year="1995"><title>&default_book_name;</title><author>罗贯中</author><publisher>中华书局</publisher><price>78</price></book></library>
library.dtd
<!ELEMENT library (book+)><!ELEMENT book (title,author,publisher,price)><!ELEMENT title (#PCDATA)><!ELEMENT author (#PCDATA)><!ELEMENT publisher (#PCDATA)><!ELEMENT price (#PCDATA)><!ATTLIST book year CDATA #IMPLIED><!ATTLIST book month (1|2|3|4|5|6|7|8|9|10|11|12) "2"><!ENTITY default_book_name "三国演义">
再来编写XPath表达式:
查询所有书籍://book查找作者为 罗贯中 的所有图书://book[author='罗贯中']查找作者为 罗贯中 的所有图书的标题节点://book[author='罗贯中']/title查找作者为 罗贯中 的所有图书的标题文本://book[author='罗贯中']/title/text()
Java编程:
import org.junit.Test;import org.w3c.dom.Document;import org.w3c.dom.NodeList;import org.xml.sax.ErrorHandler;import org.xml.sax.SAXException;import org.xml.sax.SAXParseException;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import javax.xml.xpath.*;import java.io.IOException;/*** <p>XPath UT</p>** @author fuqinqin3* @version 1.0* @date 2021/2/4 10:37*/public class XPathTest {@Testpublic void test() throws ParserConfigurationException, IOException, SAXException, XPathExpressionException {DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();// 开启验证documentBuilderFactory.setValidating(true);documentBuilderFactory.setNamespaceAware(false);documentBuilderFactory.setIgnoringComments(true);documentBuilderFactory.setIgnoringElementContentWhitespace(false);documentBuilderFactory.setCoalescing(false);documentBuilderFactory.setExpandEntityReferences(true);// 创建DocumentBuilderDocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();// 设置异常处理对象documentBuilder.setErrorHandler(new ErrorHandler() {@Overridepublic void warning(SAXParseException exception) throws SAXException {System.out.println("warning: " + exception.getMessage());throw exception;}@Overridepublic void error(SAXParseException exception) throws SAXException {System.out.println("error: " + exception.getMessage());throw exception;}@Overridepublic void fatalError(SAXParseException exception) throws SAXException {System.out.println("fatalError: " + exception.getMessage());throw exception;}});// 将文档加载进一个Document对象中Document document = documentBuilder.parse("src/test/resources/mybatis/test/library.xml");// 构建XPathFactoryXPathFactory xPathFactory = XPathFactory.newInstance();// 创建XPath对象XPath xPath = xPathFactory.newXPath();System.out.println("查询作者为罗贯中的图书标题:");// 编译XPath表达式XPathExpression xPathExpression = xPath.compile("//book[author='罗贯中']/title/text()");// 通过XPAth表达式得到结果,第一个参数制定了XPath表达式进行查询的上下文节点,也就是指定节点下查找符合XPath的节点,// 本例中的上下文节点是整个文档;第二个参数制定了XPath表达式的返回类型Object result1 = xPathExpression.evaluate(document, XPathConstants.NODESET);NodeList nodeList = (NodeList) result1;for (int i = 0; i < nodeList.getLength(); i++) {System.out.println(" " + nodeList.item(i).getNodeValue());}System.out.println("查询1997年之后的图书的标题:");NodeList result2 = (NodeList) xPath.evaluate("//book[@year>1997]/title/text()", document, XPathConstants.NODESET);for (int i = 0; i < result2.getLength(); i++) {System.out.println(" " + result2.item(i).getNodeValue());}System.out.println("查询1997年之后的图书的属性和标题:");NodeList result3 = (NodeList) xPath.evaluate("//book[@year>1997]/@*|//book[@year>1997]/title/text()", document, XPathConstants.NODESET);for (int i = 0; i < result3.getLength(); i++) {System.out.println(" " + result3.item(i).getNodeValue());}}}
执行结果:
查询作者为罗贯中的图书标题:三国演义查询1997年之后的图书的标题:西游记红楼梦查询1997年之后的图书的属性和标题:42000西游记92005红楼梦
注意:
① XPathExpression.evaluate()方法的第二个参数,它指定了XPath表达式查找的结果类型,在XPathCOnstants类中提供了 nodeset,boolean,number,string 和 Node 五种类型。
② 如果XPath表达式只使用一次,可以跳过编译步骤直接调用XPath对象的evaluate()方法进行查询,但是如果同一个XPath表达式要重复执行多次,建议还是先执行编译,这样性能会好一些。类似于正则表达式Patten的用法。


曾梦想仗剑走天涯
看一看世界的繁华
年少的心总有些轻狂
如今你四海为家
以上是关于XML解析入门(Java版)的主要内容,如果未能解决你的问题,请参考以下文章