图像识别基于OCR识别系统matlab源码
Posted 博主QQ2449341593
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别基于OCR识别系统matlab源码相关的知识,希望对你有一定的参考价值。
OCR技术概览
OCR(Optical Character Recognition ) 光学字符识别技术主要分为手写体识别和印刷体识别两类 , 印刷体识别比手写体识别要简单, 因为印刷体更规范, 字体来自于计算机字库, 尽管印刷过程中可能会发生不清晰\\粘连, 这些都可以通过一些"腐蚀"/"膨胀"图像处理技术还原, 但是手写体由于个体差异的存在, 还是非常难的.
从内容角度, 可以分为: 汉字, 英文, 数字和图画. 数字最简单, 英文次之, 汉字比较难.
开放API资源
谷歌OCR识别引擎: tesseract
百度OCR API:https://cloud.baidu.com/doc/OCR/OCR-API.html
腾讯 OCR:https://ai.qq.com/product/ocr.shtml#identify
阿里OCR: https://data.aliyun.com/product/ocr
OCR技术发展历程
早期字符模板匹配算法, 用实现定义的文字/数字模板滑动匹配图片上的字符, 直接给出识别结果. 这种方法简单,暴力, 直接.但是对于复杂场景的泛化能力很弱.
特征设计方法, 利用字符的图像特征进行特征提取, 例如结构特征, 笔画特征, 等等, 进行人工设计后, 提取文字特征, 送入SVM中做分类给出识别结果, 这种方法需要大量的人工特征设计, 而且当字体变化\\模糊等复杂条件下泛化能力同样不行.
深度学习, 特别是卷积神经网络给OCR识别提供了新的思路.
目前非常优秀的模型有哪些?
整体pipeline流程
这里说的pipeline流程不区分手写或者印刷体. 对于输入系统的文本, 例如一段文字的图片, 或者
预处理 --> 版面分析/行列切割 --> 字符识别 --> 后处理识别矫正
预处理: 文档图像可能是倾斜或者有污渍的, 需要进行角度矫正, 去噪
预处理
openCV轮廓检测+透视变换+ 二值化
轮廓提取: 适用于车牌, 身份证, 人民币, 书本, 发票一类的矩形且边界明显的物体矫正
直线探测矫正: 适用于文本类的矫正.
透视变换: cnn model(spatial transformer network, STN), 可以有效矫正文字的扭曲/翻转问题, 配准算法.STN可以有效地学习从一组点到对应点的变化关系, 可以作为一个组件和其他模型搭配使用.
版面分析
版面分析: 判断页面上文本的朝向, 做行和列的切割, 把文字按照行切割出来, 然后(按照列)切割出每一个文字
字符识别和后处理识别矫正: 文字识别算法模型进行识别, 通常是利用经典的CNN模型(例如vgg, lenet)作为backbone, 配合循环神经网络或者结合识别结果, 进行微调/上下图片关系分析, 连接, 重新送入模型识别, 提高识别正确率.
行列切割:
行列的切割可以用横向投影和纵向投影获得. 横向投影, 是将像素点的纵坐标(y)做histogram, 得到:
很显然, 从横向水平投影histgram可以很容易地区分出每一行文本. 纵向竖直投影histogram如下:
纵向投影没有横向那么分割"清晰". 这种情况主要发生在汉字中, 因为英语字母都是连通体, 不像中文的这种框架结构, 特别是左右结构的汉字, 很容易被模型识别为两个字.


可以说文字的分割对正确的识别非常重要, 甚至是至关重要. 基于深度神经网络的算法有: yolo/ssd/frcnn算法等.
字符识别
识别模型: 以CNN为基础, 嵌入其他网络, 例如循环网络等.
Faster RCNN
Faster RCNN做目标检测的关键步骤有哪些:
- 基础网络做特征提取
- 特征送入RPN做候选框提取
- 分类层对候选框内物体进行分类,回归层对候选框的(x,y,w,h)进行精细调整
Faster RCNN做文本检测感觉问题不大,但是从效果来看,仅套用Faster RCNN来做文本检测效果并不好,原因在于,文本有自己独有的特点,这种通用的文本检测框架并不能很好地解决文本的这些特点。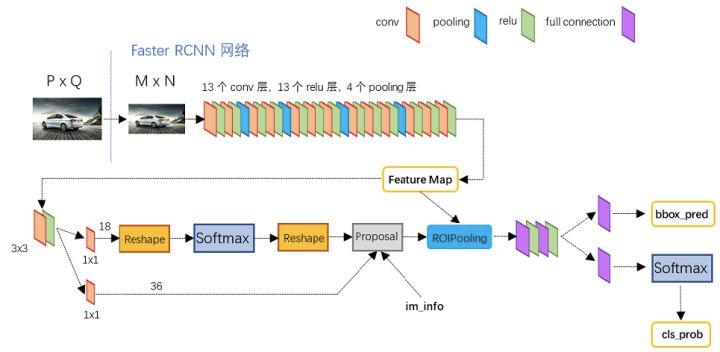
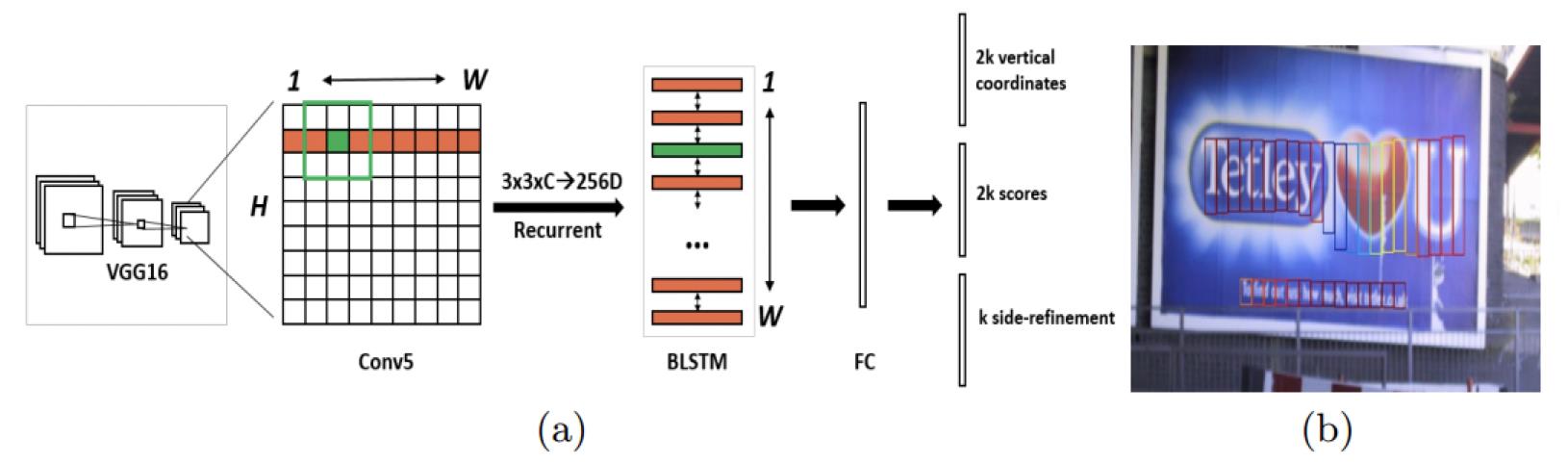
CTPN模型
2016年的detceting text in natural lmage with connectionist text proposal network一文提出了CTPN网络, 采用了一个以小的窄矩形检测框代替大检测框, 同时针对文字之间间隔的问题, 采用RNN对连续的小检测框的结果进行判断, 在CTPN中, 小检测框在文本上的移动就如同一个序列, CTPN的双向LSTM(BiLSTM)模型可以对当前检测框及其左右两边的小检测框建立联系, 可以有效地提高对于文本检测的精度.
seglink 模型
VPR2017的一篇spotlight论文《Detecting Oriented Text in Natural Images by Linking Segments》介绍以一种可以检测任意角度文本的检测算法,我们一般称这个算法为SegLink,这篇论文既融入CTPN小尺度候选框的思路又加入了SSD算法的思路,达到了当时自然场景下文本检测state-of-art的效果。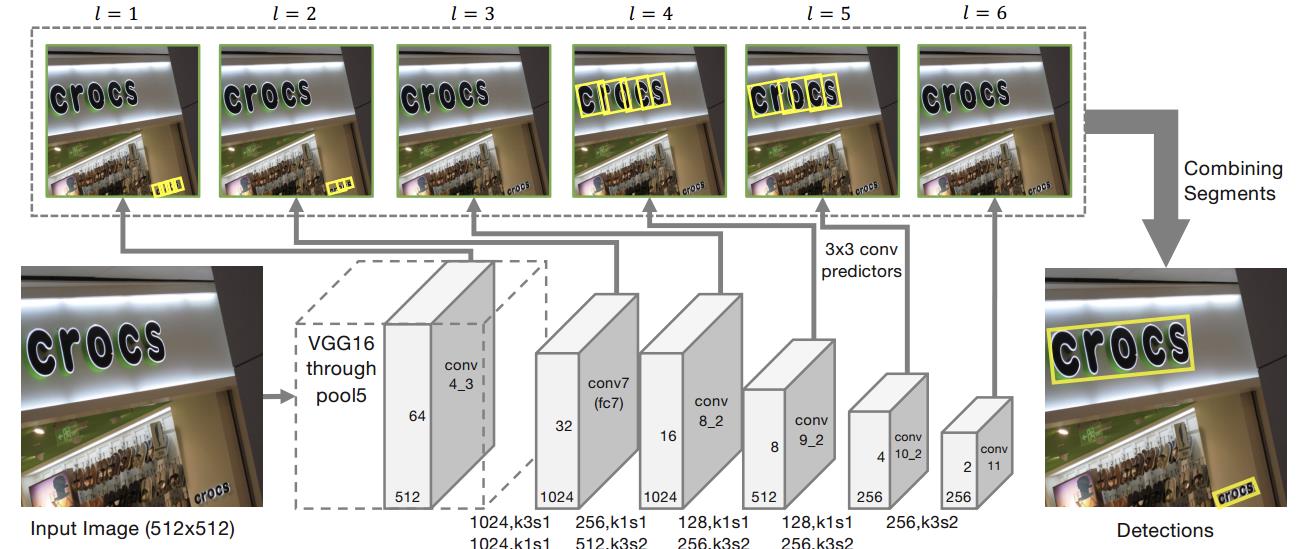
- 主干网络是沿用了SSD网络结构,并修改修改了最后的Pooling层,将其改为卷积层.具体来说:首先用VGG16作为base
net,并将VGG16的最后两个全连接层改成卷积层.接着增加一些额外的卷积层,用于提取更深的特征,最后的修改SSD的Pooling层,将其改为卷积层 - 提取不同层的feature map,文中提取了conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11.这里其实操作还是和SSD网络一样
- 对不同层的feature map使用3*3的卷积层产生最终的输出(包括segment和link),不同特征层输出的维度是不一样的,因为除了conv4_3层外,其它层存在跨层的link.这里segment是text的带方向bbox信息(它可能是个单词,也可能是几个字符,总之是文本行的部分),link是不同bbox的连接信息(文章将其也增加到网络中自动学习).
- 然后通过融合规则,将segment的box信息和link信息进行融合,得到最终的文本行.
EAST模型
seglink这种先做分割再合并的思路,增大了文本检测精度的损失和时间的消耗,CVPR2017有一篇文章提出了一个能优雅且简洁地完成多角度文本检测,这个算法叫做EAST,论文为《EAST: An Efficient and Accurate Scene Text Detector》。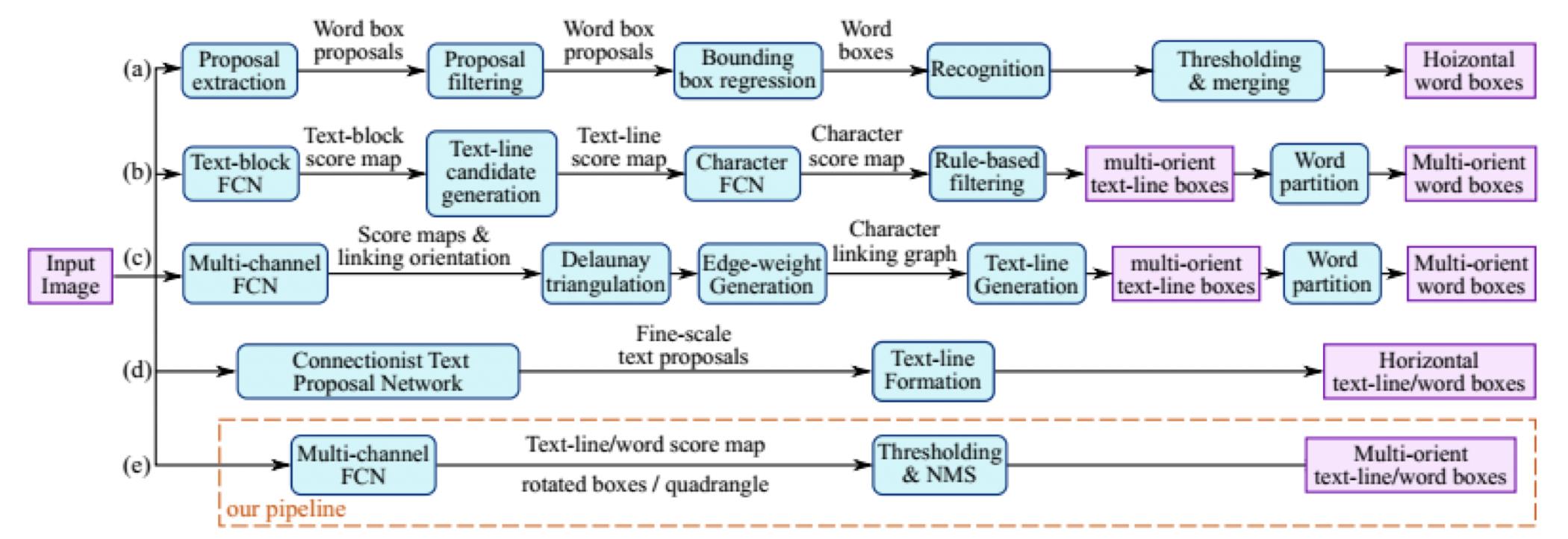
EAST网络分为特征提取层+特征融合层+输出层三大部分。
- 特征提取层: backbone采取PVANet来做特征提取,接下来送入卷积层,而且后面的卷积层的尺寸依次递减(size变为上一层的一半),而且卷积核的数量依次递增(是前一层的2倍)。抽取不同level的feature map,这样可以得到不同尺度的特征图,目的是解决文本行尺度变换剧烈的问题,size大的层可用于预测小的文本行,size小的层可用于预测大的文本行。
- 特征合并层,将抽取的特征进行merge.这里合并的规则采用了U-net的方法,合并规则:从特征提取网络的顶部特征按照相应的规则向下进行合并,这里描述可能不太好理解,具体参见下述的网络结构图。
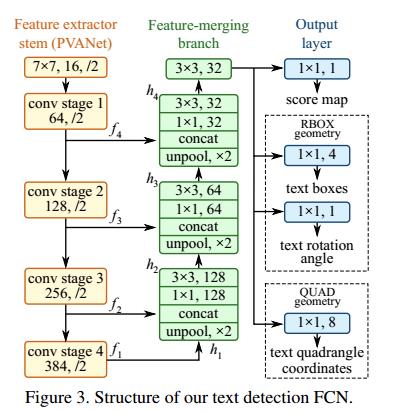
- 网络输出层:网络的最终输出有5大部分,他们分别是:
- score map:一个参数,表示这个预测框的置信度;
- text boxes: 4个参数,(x,y,w,h),跟普通目标检测任务的bounding box参数一样,表示一个物体的位置;
- text rotation angle: 1个参数,表示text boxe的旋转角度;
- text quadrangle coordinates:8个参数,表示任意四边形的四个顶点坐标,即(x1,y1),(x2,y2),(x3,y3),(x4,y4)。
所以从整体看来,EAST就是借助FCN架构直接回归出文本行的(x,y,w,h,θ)+置信度+四边形的四个坐标.
其他方法
基于语义分割的思路做文本检测的、基于角点检测做文本检测、各种方法混合的文本检测.
字符识别
主流模型分为两种: attention OCR(= cnn+ rnn+ attention) 或者CRNN(= cnn+rnn+CTC ) . 这两大方法的主要区别在于最后的输出层,attention OCR采用的是attention机制, CRNN对齐采用的是CTC算法.
二、源代码
clc
clear all
close all
Symbols =['0' '1' '2' '3' '4' '5' '6' '7' '8' '9' '-'];
P3 = [];
Result = [];
path = 'C:\\Users\\lenovo\\Desktop\\23149049ocr\\'; % working Path
ext = '_bold.bmp'; %Train Data Files Extension name
P = zeros(16,12,11);
% Read 0-9 digits data
for i = 0: 9
file = [path,char(48 + i) , ext]; % char(48) => '0'
P(:,:,i + 1) = imread(file);
P3 = [P3,P(:,:,i + 1)'];
end
% imshow(P(:,:,1));
i = i + 1;
% read other symbols
file = [path,'dash' , ext];
P(:,:,i + 1) = imread(file);
P3 = [P3,P(:,:,i + 1)'];
% figure
% for i = 1:11
% subplot( 11, 1, i );
% imshow( P(:,:,i) );
% end
P1 = reshape(P3, 12 * 16, 11);
T = zeros(11,11);
for i = 1:11
T(i,i) = 1;
end
[R,Q] = size(P1);
[S2,Q] = size(T);
S1 = 25;
net = newff(minmax(P1),[S1 S1 S2],{'logsig' 'logsig','logsig'},'traingdx');
net.performFcn = 'sse';
net.trainParam.goal = 0.05;
net.trainParam.show = 100;
net.trainParam.epochs = 5000;
net.trainParam.mc = 0.95;
[net,tr] = train(net,P1,T);
sept2 = []; %character segment start-end pos
Test1 =[];
file = [path,'test_bold2.bmp'];
a = imread(file);
figure;
subplot(3,24,1:24);
imshow(a);
j =1;
seg1 = a;
b = sum(seg1) ; % character segment, if the vertical projection is zero, means the space between characters.
b(find(b < 1) ) = 0;
c = find(b == 0);
d= find(b > 0);
e = find(c > d(1));
sept2 = [];
for k = 1:size(e,2) -1 % delete repeated zero position
if( c(e(k + 1)) - c(e(k)) > 1)
sept2 = [sept2, c(e( k ))];
sept2 = [sept2, c(e(k + 1))];
end
end
%figure
sept2 = [1, sept2];
chCount = size(sept2);
for k = 1: chCount(2) -1
Test1 = [];
tmp = zeros(16,1);
z = a(:,sept2(k)+1: sept2( k+1 ));
t1 = size(z);
if(t1(2)> 2)
tt1 = size(z);
% if( tt1(2) < 11)
% z = [z,tmp];
% end
tt1 = size(z);
% if( tt1(2) < 11)
% z = [tmp,z,tmp];
% end
z2 = imresize(z,[16,12],'bilinear');
% z2 = ~z2;
% z2 = ~z2;
% z2 = double(z2);
% z2 = imnoise(z2,'salt & pepper', 0.4);
z2 = ~z2;
z2 = ~z2;
subplot(3,24,24+k);
imshow(z2);
z2 =z2';
z3 = reshape(z2,16 * 12,1);
Test1 = [Test1,z3];
%figure;
%imshow(z2);
%title('TRUE');
% end三、运行结果

四、备注
完整代码或者仿真咨询添加QQ1575304183
二、源代码
clc
clear all
close all
Symbols =['0' '1' '2' '3' '4' '5' '6' '7' '8' '9' '-'];
P3 = [];
Result = [];
path = 'C:\\Users\\lenovo\\Desktop\\23149049ocr\\'; % working Path
ext = '_bold.bmp'; %Train Data Files Extension name
P = zeros(16,12,11);
% Read 0-9 digits data
for i = 0: 9
file = [path,char(48 + i) , ext]; % char(48) => '0'
P(:,:,i + 1) = imread(file);
P3 = [P3,P(:,:,i + 1)'];
end
% imshow(P(:,:,1));
i = i + 1;
% read other symbols
file = [path,'dash' , ext];
P(:,:,i + 1) = imread(file);
P3 = [P3,P(:,:,i + 1)'];
% figure
% for i = 1:11
% subplot( 11, 1, i );
% imshow( P(:,:,i) );
% end
P1 = reshape(P3, 12 * 16, 11);
T = zeros(11,11);
for i = 1:11
T(i,i) = 1;
end
[R,Q] = size(P1);
[S2,Q] = size(T);
S1 = 25;
net = newff(minmax(P1),[S1 S1 S2],{'logsig' 'logsig','logsig'},'traingdx');
net.performFcn = 'sse';
net.trainParam.goal = 0.05;
net.trainParam.show = 100;
net.trainParam.epochs = 5000;
net.trainParam.mc = 0.95;
[net,tr] = train(net,P1,T);
sept2 = []; %character segment start-end pos
Test1 =[];
file = [path,'test_bold2.bmp'];
a = imread(file);
figure;
subplot(3,24,1:24);
imshow(a);
j =1;
seg1 = a;
b = sum(seg1) ; % character segment, if the vertical projection is zero, means the space between characters.
b(find(b < 1) ) = 0;
c = find(b == 0);
d= find(b > 0);
e = find(c > d(1));
sept2 = [];
for k = 1:size(e,2) -1 % delete repeated zero position
if( c(e(k + 1)) - c(e(k)) > 1)
sept2 = [sept2, c(e( k ))];
sept2 = [sept2, c(e(k + 1))];
end
end
%figure
sept2 = [1, sept2];
chCount = size(sept2);
for k = 1: chCount(2) -1
Test1 = [];
tmp = zeros(16,1);
z = a(:,sept2(k)+1: sept2( k+1 ));
t1 = size(z);
if(t1(2)> 2)
tt1 = size(z);
% if( tt1(2) < 11)
% z = [z,tmp];
% end
tt1 = size(z);
% if( tt1(2) < 11)
% z = [tmp,z,tmp];
% end
z2 = imresize(z,[16,12],'bilinear');
% z2 = ~z2;
% z2 = ~z2;
% z2 = double(z2);
% z2 = imnoise(z2,'salt & pepper', 0.4);
z2 = ~z2;
z2 = ~z2;
subplot(3,24,24+k);
imshow(z2);
z2 =z2';
z3 = reshape(z2,16 * 12,1);
Test1 = [Test1,z3];
%figure;
%imshow(z2);
%title('TRUE');
% end三、运行结果
四、备注
完整代码或者仿真咨询添加QQ1575304183
以上是关于图像识别基于OCR识别系统matlab源码的主要内容,如果未能解决你的问题,请参考以下文章