架构小白都能理解的大型互联网架构演进过程
Posted 在路上的德尔菲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构小白都能理解的大型互联网架构演进过程相关的知识,希望对你有一定的参考价值。
前言
你刚刚搭建了你的网站,网上商城或社交网络,把它放在网上,事情进展顺利,每天有几百名访客通过你的网站,请求得到快速回复,订单立即处理,一切都很好运行。
但后来发生了一件可怕的事:你成功了!!
越来越多的用户涌入,数千,数万,每小时,每分钟,每秒……对你的业务来说,这对你的基础设施来说是个坏消息,因为现在,它需要扩展。即意味着它需要能够同时为更多的客户提供服务、随时随地提供服务、为全球用户提供服务。
如何扩容?
几年前,首先讨论“垂直”(scaling up )与“水平”(scaling out)扩展。 简而言之,垂直扩展意味着在更强大的计算机上运行,而水平扩展意味着并行运行许多进程。
今天,几乎没有人不再不假思索的垂直、水平扩展了,原因很简单:
-
若希望提高计算机的计算能力,那么意味着计算机成本会指数级增大
-
硬件会决定一台计算机计算能力的一个上限
-
多核CPU意味着即使是一台计算机也是可以并行计算的——那么为什么不从一开始就并行化呢?
但是需要的步骤是什么?
单个服务器和数据库
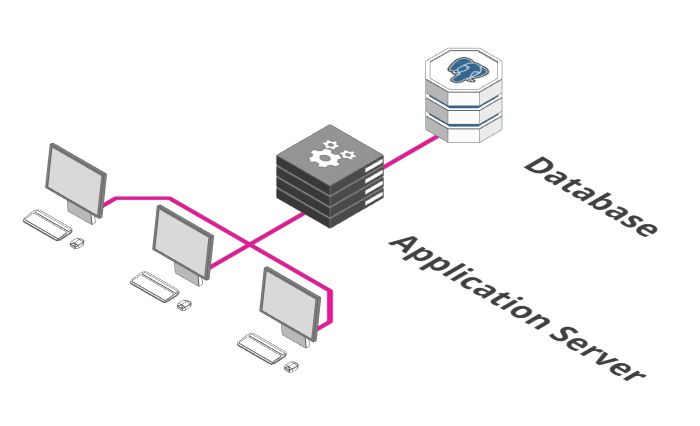
这可能是后端最初看起来的样子,有没有特别熟悉? 业务逻辑运行在单个应用服务器上,以及一个长期存储数据的数据库。 麻雀虽小五脏俱全,架构小巧简单,但是当需要满足更高要求的流量时,唯一方法是在更强大的计算机上运行它,因此不是很好。
添加反向代理
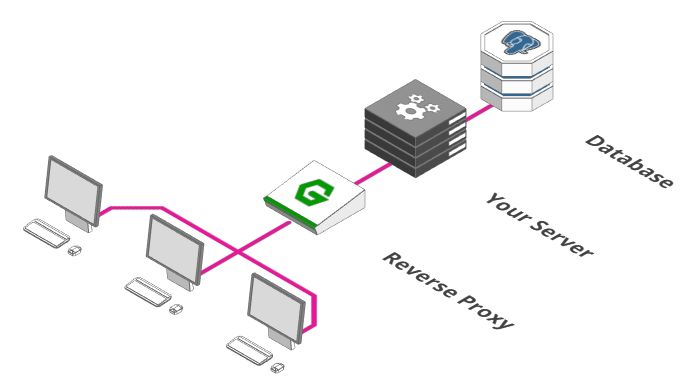
为更大规模架构的第一步是添加“反向代理”。可以把它想象成酒店,当然,可以让客人直接去他们的房间,但实际上,你需要的是一个前台小姐姐,如果房间已经有人入住,则直接告诉客人无法入住,而不是让他们继续前往房间。这正是反向代理所做的。
代理只是一个接收和转发请求的过程,那么为何叫做“反向代理”?通常,这些请求会从我们的服务器发送到互联网。但是,这一次,请求来自互联网,需要路由到我们的服务器,所以我们称之为“反向代理”。而我们想看看更大的真实的世界,我们需要“正向代理”。
反向代理可以实现的功能:
-
运行状态检查,可确保我们的后端服务器仍在运行
-
路由请求,将请求转发到正确的服务器端点
-
身份验证,确保用户有资格访问服务器
-
防火墙,确保用户只能访问我们允许访问的网络
引入负载均衡
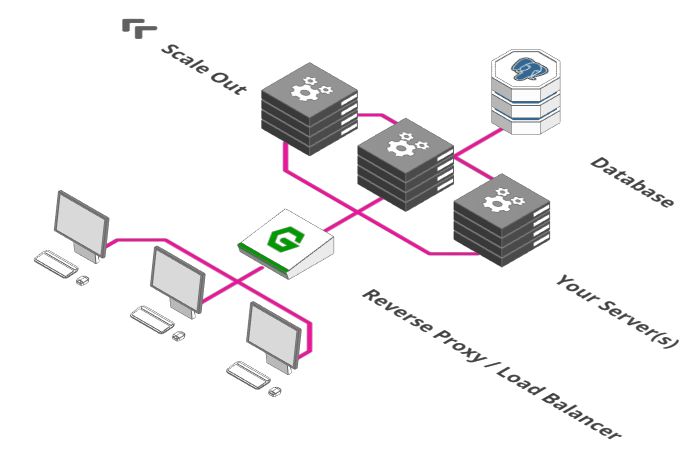
大多数“反向代理”还有另外一个功能——充当负载均衡器。 负载均衡是一个简单的概念:想象一下,一百个用户已准备好在一分钟内在你的网站在线付款。但是很遗憾,付款服务器只能同时处理50笔付款。 如何解决? 只需一次运行两个付款服务器。
负载均衡的工作就在将传入的付款请求分流到两个服务器中。 比如A用户请求分流到到第一个服务器上,B用户请求分流到第二台服务器上,C用户请求分流到第一个服务器上,依此类推。其实还有不同的负载均衡方式,比如随机,Hash值以及设置服务器权值等。
那么如果有500个用户想立刻付款,你会怎么做? 确切地说,可以扩展到十个支付服务器,并将它们连接到负载均衡器,以给它们分配传入的请求。
增加数据库
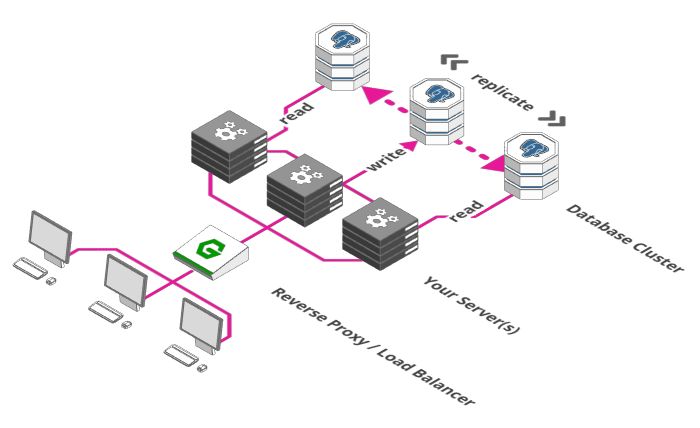
使用负载均衡器可以让我们在多个服务器之间分流。但你能发现问题吗? 虽然我们可以利用数十,数百甚至数千台服务器来处理我们的请求,但它们存储和检索的数据都来自同一数据库。
那么我们不能以同样的方式扩展数据库吗? 不幸的是,这里存在数据一致性的问题。我们系统都需要他们使用的数据是一致的。不一致的数据会导致各种问题,比如数据库A中插入了订单,但是数据库B中没有插入订单,此时数据库A宕机了,订单就消失了,又比如订单被多次执行等等,那么我们如何在确保一致性的同时扩展我们的数据库呢?
我们能做的第一件事就是把它分成多个部分,一部分专门负责接收数据并存储到数据库(写数据),其他部分负责检索存储的数据(读数据),此方案称为主从设置。 一般来说服务器从数据库读取的频率比写入数据库的频率更高。 这个解决方案的好处是保证了一致性,因为数据只被写入单个主数据库,并从主数据库向其他从数据库传输数据。
缺点是我们仍然只有一个写数据库,这对于中小型Web项目来说没问题,但是如果你想构建类似Weibo这样大型应用,则不应该这样做,我们将在后面章节中继续研究如何扩展数据库。
微服务
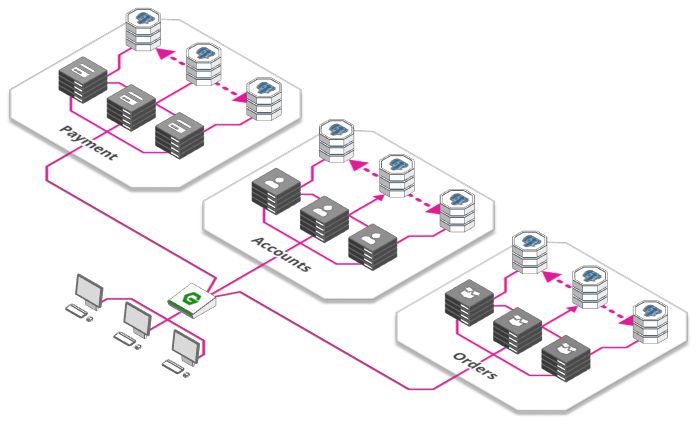
到目前为止,我们让一台服务器可以处理所有的业务:处理付款,订单,库存,服务网站,管理用户帐户等。
这样很好,因为单个服务器意味着更低的复杂性,但随着规模的增加,事情开始变得复杂和低效:
-
开发团队随着应用程序的发展而扩大,但随着越来越多的开发人员在同一台服务器上工作,他们可能影响到彼此。
-
只有一台服务器就意味着每当我们想要上线新版本时,必须完成所有工作。考虑一种情况,当一个团队希望发布更新时,但另一个团队只完成了一半的工作,因为相互依赖,不能及时上线。
解决这些挑战的方案是通过使用当今非常热门的架构模式——微服务。这个想法其实很简单,将服务器分解为各个不同的功能单元,并将它们单独部署且又相互连接。比如一部分服务器专门处理订单业务,另一部分服务器专门处理用户业务,这有很多好处:
-
每项服务都可以单独扩展,使我们能够更好地适应需求
-
开发团队可以独立工作,每个团队只负责自己的微服务生命周期(创建,部署,更新等)
-
每个微服务器中,可以根据自己的数据量来增添或减少数据库数量
缓存
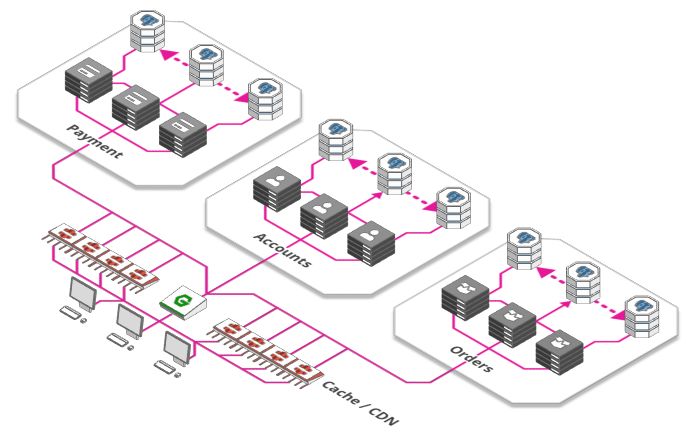
什么比提高工作效率更好? 那就是根本不需要工作!(嘻嘻~) 我们的网络应用程序的很大一部分由静态资产组成,比如图像,javascript和css文件,某些产品的预渲染登陆页面等等。
我们不需要在每次请求中重新计算或重新提供这些资源,而是使用“缓存” ,即一个小型存储器,只需记住最后操作后的结果,并将其交给需要此资源的人,而无需请求后端服务器和底层数据库。
缓存的一个非常大应用叫做“内容交付网络”或简称CDN(Content Delivery Network)--遍布全球的巨大缓存,即可以快速向我们提供所需内容,而不是每次都将请求发送到全球服务器中然后再回传内容。我们就明白了为什么点开网页中视频可以快速而且清晰播放,正是因为这些视频早已存放在离你最近的CDN中了。
消息队列
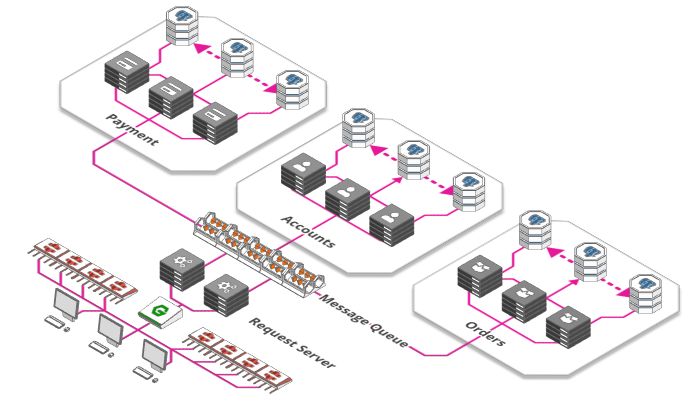
你去过学校食堂吗?每个打饭窗口是平行的,即有多个窗口可同时打饭,但似乎永远不能立即为每位学生服务,结果,排起了队伍,队列就形成了。
相同的概念用于大型Web应用中,比如每分钟都有成千上万的照片上传到weibo,每个图像都需要处理,调整大小,分析和标记,这是一个耗时的过程。 因此,在接收图像服务器完成以上所有步骤前,不要让用户一直等待,而是告诉用户上传成功。服务器“慢慢”做三件任务:
-
存储未处理的原始图像。
-
为照片添加了各种操作,比如缩放,滤镜,水印,照片是否公开等。
-
确认上传。
这些任务会被服务器接收,每个服务器只完成其中一个任务,比如服务器A存储未处理的原始图像,服务器B处理照片缩放和添加水印,直到处理完所有任务。管理这些任务的系统称为“消息队列”。 使用这样的队列有许多优点:
-
解耦任务和处理器。 有时需要处理很多图像,有时只需处理少量图像。有时很多处理器都可用,有时可能只有几个处理器处于可用状态。在流量较大时,通过简单地将任务添加到队列中而不是直接处理它们,确保系统保持响应并且不会丢失任务,也就是削峰。
-
它允许我们按需扩容,提高系统伸缩性。当很多用户一定时间内上传大量图像时,且启动更多处理器需要时间,这时可能造成系统崩溃,这时通过将任务添加到队列中,我们可以推迟配置额外容量来处理它们。
-
消息持久化,即使系统出现故障,也不会漏掉消息
好吧,如果我们按照上面的所有步骤操作,我们的系统现在已准备好迎接大量的流量。 但是,如果我们想要变大,我们能做什么? 好吧,还有一些选择:
分片,分片
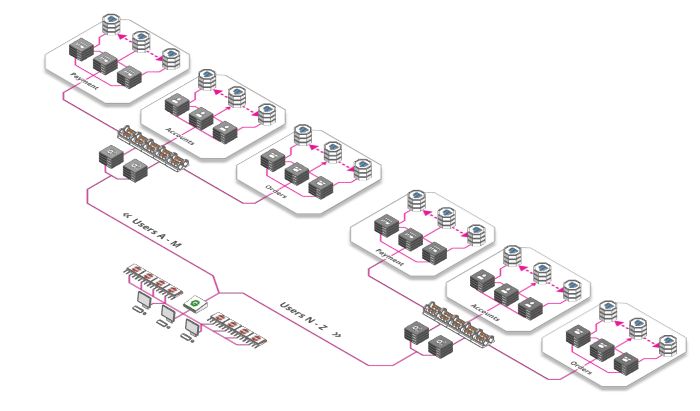
通过将系统切分成不同的单元,每一单元只负责特定的部分,使得并行化处理需求。究竟是什么意思呢? 它实际上非常简单,比如存储数亿用户QQ资料,可以按照123456789首数字切分,1开头的QQ号信息专门存储在一个服务器A中,2开头的QQ号的信息专门储存在另一个服务器B中,以此类推,那么操作服务器A与操作服务器B是并行的。
分片规则不一定基于数字,也可以基于其他的因素,例如,用户姓名,用户年龄,家乡等等。 可以根据需要以不同的方式切分服务器,数据库。
DNS
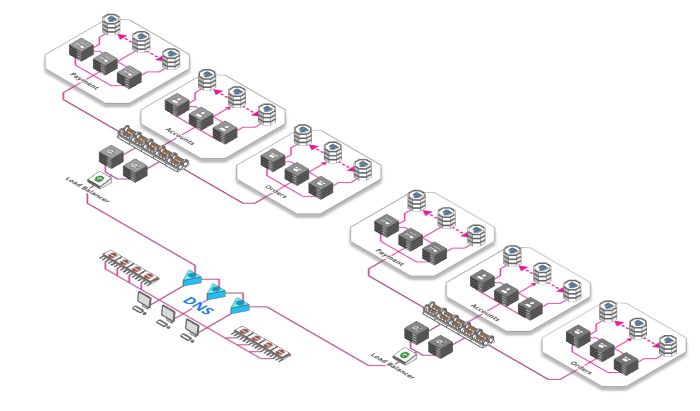
单个负载均衡器性能有限,即使购买一些功能非常强大(且价格极其昂贵)的硬件负载均衡器,但它们性能也存在硬性限制。
幸运的是,有一个全球性分布且非常稳定的层,可用于在流量到达我们的负载均衡器之前对流量进行平衡。该层叫做“域名系统” 或简称DNS(Domain Name System)。 假如我们输入www.baidu.com会映射到IP“143.204.47.77”,下一次输入可能映射到“143.204.47.78”。此DNS允许我们为每个域名指定多个IP,每个IP都会指定到不同的负载均衡器上。
以上是关于架构小白都能理解的大型互联网架构演进过程的主要内容,如果未能解决你的问题,请参考以下文章